
基于优势决策的神经机制解码方法研究
2019-06-11 08:48李鹏,李俊
网络安全与数据管理 2019年6期
李 鹏,李 俊
(中国科学技术大学 信息科学技术学院,安徽 合肥 230026)
0 引言
人类的各种行为由脑部神经决定,探索神经激活模式和行为之间的关系是神经科学领域的一个重要课题。随着功能性磁共振成像(functional Magnetic Resonance Imaging,fMRI)技术[1]的成熟,脑内神经活动数据的获取精度和速度都在提升。现代神经认知研究多通过分析fMRI数据和行为数据的联系,确认行为背后的神经机制。
传统的研究中,广义线性模型(Generalized Linear Model,GLM)[2]被广为应用。广义线性模型是单变量分析的统计分析方法,其特点为将目标区域内多个体素的信号数据取平均,再利用模型进行解码。此方法的优点在于模型解释性好,数据处理简单,但是,模型获取的体素数据信号波动互相抵消,对于模型解码能力有约束。随着计算机的发展和机器学习理论的完善,基于机器学习分类算法的多特征分类方法被应用到神经机制的解码工作中[3-4]。多变量模型考虑到多个体素数据,对多体素共同控制行为解码效果好[5],且多变量模型考虑到每个体素,不会忽略对行为有控制作用但激活不明显的体素,激活数据完整性高[6]。
本文主要研究适用于在爱荷华博弈任务的解码方法。通过分析仿真数据,对比单变量分析和多体素模式分析(Multi-Voxel Pattern Analysis,MVPA)[7]效果,对比不同分类算法下多体素分类模型效果,最后,确认最适用于优势决策任务的解码方法。
1 实验材料与方法
1.1 仿真实验理论
体素水平上的研究表明,脑神经的波动主要来源有三个层次[2,8]:被试水平,不同被试对相同刺激的神经激活不同;体素水平,不同体素对相同刺激的神经激活不同;试验水平,不同试验变量导致的神经激活不同。故仿真实验中,当给定被试s,给定试验t,给定体素v,激活是试验变量在三个水平上产生固定和随机偏移的结合。这些固定和随机的影响可以被一个三水平混合模型模拟出来[9],亦为本文仿真实验数据生成的理论基础。
1.2 数据生成
仿真实验设计中,数据生成的试验变量为二类:优势和劣势,体现在试验水平,令其为Xpts,取值为0或1;令Atvs为生成数据的值,其模拟产生来源于三个水平的波动。
(1)被试水平的波动:
(1)
其中,0、P分别代表未施加刺激和施加刺激的状态;γ0、γp分别代表受到刺激和未受到刺激被试的响应,γ0、γp取常量值;e0s、eps分别代表被试在刺激下的随机波动,其中每个被试的方差固定,且不同被试间方差不同,代表着被试水平的波动。
(2)体素水平的波动:
(2)
其中,β0s、βps由式(1)定义可得;e0vs、epvs分别代表刺激状态下和非刺激状态下产生的随机波动,满足均值为0、方差为固定值τ0、τp的高斯分布,其中每个体素的方差固定且不同,代表着体素水平的波动。
(3)试验水平的波动:
(3)
其中,α0vs、αpvs由式(2)可得;Xpts代表着试验变量,取值为1或0,对应刺激的有无;etvs为满足均值为0、方差为固定值σ2的高斯分布,方差随着试验不同而不同,代表着试验水平的波动。
结合式(1)~式(3),可推出Atvs的表达式如式(4)所示:
Atvs=γ0+e0s+e0vs+Xptsγp+Xptseps+Xptsepvs+etvs
(4)
其中,γ0、γp分别代表无刺激和有刺激的试验变量对被试产生的影响,为固定值;e0s、eps、e0vs、epvs、etvs分别代表不同试验变量在被试、体素和试验三个水平上带来的随机波动,均为0均值的高斯分布产生的随机数。仿真实验中,按照设定的被试数目、体素数目和试验数目产生仿真数据。
1.3 多体素模式分析
MVPA本质上为利用多变量模型解码分析神经机制的过程,利用MVPA解码相关行为的神经机制一般分为以下几步,如图1所示。
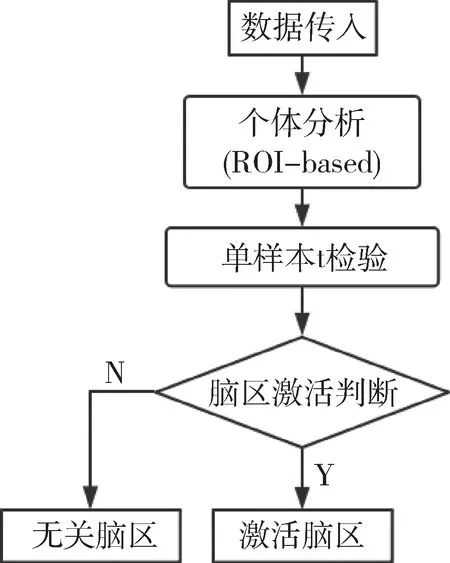
图1 MVPA判断脑区激活流程示意图
(1)导入数据,为避免模型过拟合,一般建模检验时,只导入感兴趣区(Region of Interest,ROI)的数据,本实验数据为模拟数据,本身即为按照脑区生成,故可直接导入模型;
(2)个体分析,基于ROI内的fMRI数据和行为学数据建模分析,以体素为特征,以行为为标签,以机器学习算法为分类器,训练并检验多变量模型的性能,训练模型的算法选择为本文研究的重点;
(3)组间检验,个体分析得到每个被试不同脑区的解码准确率,为检验准确率的稳定性,本文采用独立样本t检验,检验样本脑区的敏感度指数均值与随机选择的敏感度指数均值之间差异;
(4)激活脑区输出,根据检验结果的显著性和均值大小关系,判断脑区是否是激活脑区。
1.4 评价指标
本文采用的评价指标为敏感度指数(Sensitivity Index,SI),其为信号探测领域常用的评价指标。敏感度指数的数学表示形式可由混淆矩阵(Confusion Matrix)计算得出,混淆矩阵定义如表1所示。
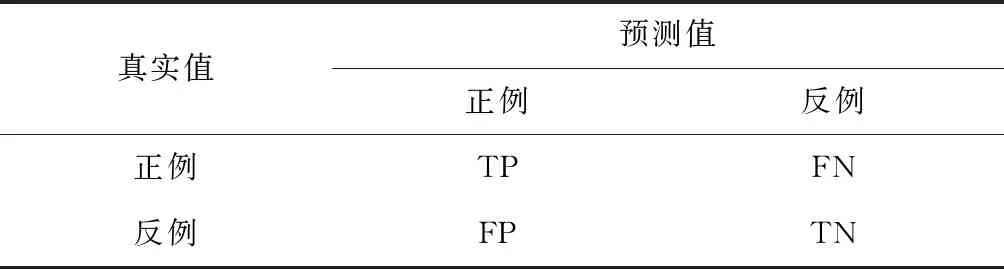
表1 混淆矩阵
表1中,TP为真正例(True Positive);FP为假正例(False Positive);FN为假反例(False Negative);TN为真反例(True Negative)。
敏感度指数的定义如式(5)所示:
(5)
(6)
(7)
敏感度指数借助TPR和FPR,计算方式如下:
SI=Z(TPR)-Z(FPR)
(8)
式中,Z(p)为高斯分布函数的反函数,p∈[0,1]。
2 实验结果与分析
实验中,共生成20个被试数据,每个被试模拟生成200次试验数据,即每个被试的样本数目为200,令施加刺激的试验为正样本,未施加刺激的试验为负样本。
单变量模式分析中,常采用的分析模型为广义线性回归,本实验单变量模型采用逻辑斯蒂回归,实验中,先将脑区数据取平均[8],再将处理后的均值样本传入模型;多体素模式分析中,机器学习分类算法采用线性判别分析(Linear Discriminant Analysis,LDA)、K近邻(K-Nearest Neighbor,KNN)、朴素贝叶斯(Naïve Bayes,NB)和支持向量机(Support Vector Machine,SVM),其中,支持向量机采用线性核函数(linear)和径向基核函数(radial basis function,rbf)。
实验中,各模型的分类敏感度指数均值和方差如表2所示,由表知,线性支持向量机的解码敏感度均值最高,单变量模型的解码敏感度均值最低。为便于各模型的均值比较,并观察均值差的显著性,做各模型的解码均值的误差棒状图,如图2所示,图中误差棒代表标准误差。

表2 各模型分类敏感度指数均值和标准差
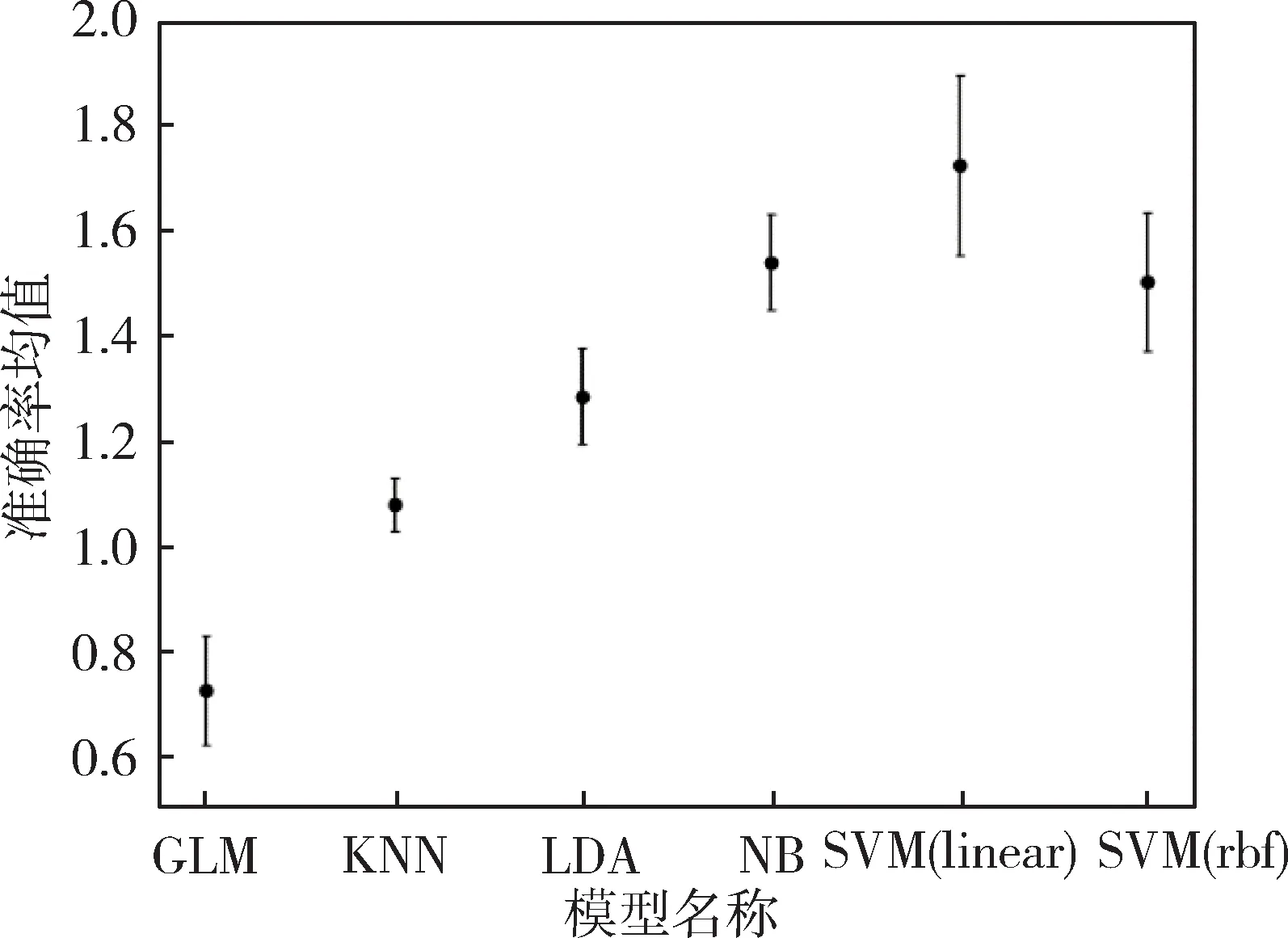
图2 各模型分类的敏感度指数误差棒状图
由图2和表2可得,多变量模型的敏感度均值高于单变量模型。为了确保结论的可靠性,本文分别比较每个多变量模型和单变量模型的均值差异,并利用统计检验确认均值间的差异的显著性。各多变量模型均值与单变量均值间的独立样本t检验结果如表3所示,表中,p值是多变量模型和单变量模型均值相同的置信度。由表中p值均远小于0.05可知,多变量解码能力优于单变量模型。

表3 多变量模型与单变量模型敏感度的统计检验
另由表2和图2,比较各多变量模型的解码敏感度均值,KNN和LDA的敏感度均值较小,但方差小,模型表现较稳定;线性SVM的表现效果好,缺点是结果方差大,个体因素对模型影响大,这与模型复杂度高有关;NB的模型解码表现仅次于线性SVM,且模型的方差较小,在解码表现上较好。另一方面,由于非线性模型会对解码体素做变换,对于确定起解码作用体素的解释性弱于线性模型。综上,确认fMRI数据解码神经机制任务中,线性支持向量机的解码效果最好。
3 结论
本文针对基于fMRI解码神经机制的方法进行探讨,基于fMRI模拟数据,对比多变量和单变量解码模型,证实多变量模型的解码能力优于单变量模型,对比多种多变量模型,从解码能力和解码脑区的解释性两个角度,可以确认线性支持向量机最优,其解码能力优于其他模型,且能够解释解码脑区的合理性。
猜你喜欢
家庭医学(2022年3期)2022-04-07
中华骨与关节外科杂志(2021年8期)2021-11-30
贵州大学学报(自然科学版)(2021年5期)2021-09-26
心理学报(2021年8期)2021-08-11
分子影像学杂志(2021年4期)2021-07-21
电子技术与软件工程(2021年8期)2021-06-16
现代计算机(2021年8期)2021-05-13
西安邮电大学学报(2021年6期)2021-05-10
中学科技(2018年9期)2018-12-19
健康管理(2017年3期)2017-04-20
