
基于高光谱技术的香肠亚硝酸盐快速检测方法
2019-07-03 02:07刘峥殷勇
食品与机械 2019年5期
刘 峥 殷 勇
(河南科技大学食品与生物工程学院,河南 洛阳 471023)
在香肠的制作过程中,为了呈现良好的色泽和防止腐蚀,会加入一定量的亚硝酸盐。随着香肠存放时间的延长,原先添加的亚硝酸盐会分解消耗掉一部分,而香肠中的肉品本身也会产生一部分亚硝酸盐,导致香肠在储藏过程中亚硝酸盐含量不断变化,存在不确定性。由于亚硝酸盐的毒性强,摄入过多时会让血液中的血红蛋白转化成高铁血红蛋白,失去输送氧气的能力,使组织产生缺氧,引起紫绀现象甚至死亡[1]。
现阶段,检测食品中亚硝酸盐的主要方法有高效液相色谱法[2]、国际格里斯(Griess)试剂比色法[3]、荧光光度法[4-5]、毛细管电泳法[6]、离子色谱法[7]等。虽然这些方法较为普遍,但是存在操作复杂,对环境敏感,适用范围窄等问题。而高光谱技术具有可视性、快速性等优点,在水果[8-9]、小麦[10]、玉米[11]、茶叶[12]等农副产品品质检测中得以广泛地运用。文献检索发现,利用高光谱技术针对肉制品中亚硝酸盐检测的研究报道比较少。陈晓东等[13]利用高光谱技术研究了香肠中亚硝酸盐的预测方法,指出了高光谱技术检测香肠中亚硝酸盐的可行性。但是,该文是基于主成分分析提取的特征所构建的预测模型还不能较好地满足实用要求,模型最高预测精度仅为0.918。本试验拟从回归模型输入信息的选择方面作为切入点尝试提升高光谱技术检测香肠在储藏过程中亚硝酸盐含量的准确性。
1 材料与方法
1.1 试验材料
香肠样品:双汇润口香甜王玉米风味香肠,购于超市。样品保质期为120 d,储藏方式与购买时超市的存放方式相同,即自然条件(温室环境)下储藏。由于购买日期是生产日期的第29天,所以试验选取储藏30,50,70,90,110,130,150 d的香肠样品进行亚硝酸盐含量检测。每个样品分别选取40个样本,每个样本含量为(24.0±0.5) g,包含21个香肠切片。其中,任选30个样本构造训练集,共210个样本;剩余的10个样本构造测试集,共70个样本。在模型构建中,随机生成3组训练集及其对应的测试集来分别构建模型和校验模型,以说明研究结果的可靠性。
1.2 高光谱系统
实验采用的高光谱系统是由计算机、光谱仪(IST 50-3810型,德国Inno-spec公司,光谱范围为371.05~1 023.82 nm,涵盖可见光和部分近红外光谱)、4个500 W 的光纤卤素灯(RK90000420108型,德国Esylux公司)和传送装置等组成。其示意图与性能参数与刘燕德等[14]使用的装置相同。
1.3 样本高光谱数据采集和校正
在采集样品高光谱数据时,将香肠样品切片平铺在规格为10 cm×1 cm的培养皿中,再将盛有样品的培养皿放置在传送带上,带速2 mm/s,用SICap-STVR V1.0.x 控制驱动,获得高光谱信息采集结果。每个测试样本的高光谱反射值采用ENVI 4.8软件提取,最终可以采集到1 288个波段的高光谱反射值。在采集样本的高光谱图像时,须进行黑白校正。具体校正方法为:白板校正是使用白色特氟龙(Teflon)标准矫正板进行扫描得到全白的标定图像,黑板校正则是关闭光源及相机镜头得到全黑的标定图像。
其他数据处理方法均在Matlab 2014a平台上实现。
1.4 光谱预处理
采集高光谱信息时,会受到高光谱仪器的电路噪声干扰,而且样品表面不平整也会影响到原始光谱数据的采集。所以,为了减少这些外界因素对光谱信息的干扰,在建立模型之前需对原始光谱数据进行预处理。采用Savitzky-Golary卷积平滑法(SG平滑)对原始光谱数据进行预处理[15-16]。Savitzky-Golary卷积平滑法是通过多项式来对移动窗口内的数据进行多项式最小二乘拟合,其实质是一种加权平均法,更强调中心点的中心作用[17]。
1.5 香肠中亚硝酸盐含量测定
采用GB 5009.33—2016的检测方法。对所选择的每个储存时间的样品进行3次平行样本测试,取平均值作为检测结果。
1.6 特征波长的提取
因高光谱信息共有1 288个波段的光谱数据,数据繁多,会提高建模时的复杂度,所以在高光谱分析中通常会进行特征波长的提取[18-19]。在特征波长提取方法上,常用偏最小二乘回归系数大小作为选择特征波长的依据[20-21]。因此,采用偏最小二乘回归系数提取特征波长。
1.7 香肠中亚硝酸盐的定量分析方法
1.7.1 多元回归 多元回归是对相关随机变量进行预测,确定这些变量之间数量关系的可能形式,并用数学模型来表示。多元回归模型的精确度由决定系数(determination coefficients,R2)、均方根误差(root mean squared error,RMSE)2个指标决定,R2越接近于1,精度越高,模型越稳定,RMSE越小,模型的预测能力越高。
1.7.2 主成分回归 主成分回归(PCR) 是目前处理高维复杂数据时非常有效的方法之一。它可以对复杂的高维数据进行降维,在不丢失主要数据信息的情况下选择维数较少的新变量来代替原来较多的变量,以排除众多信息共存中相互重叠的现象以及夹杂的噪声等干扰,还可以解决高维数据的多重共线性问题,从而使预测结果更加准确合理。本研究采用R2和RMSE进行评价,R2越接近于1,精度越高,模型越稳定,RMSE越小,模型的预测能力越高。
1.7.3 偏最小二乘回归 偏最小二乘回归(PLSR)是一种多元统计数据分析方法,可以同时实现回归建模、简化数据结构和分析2组变量间的相关性。PLSR模型预测精度取决于R2、RMSE两个指标,R2越接近于1,精度越高,模型越稳定,RMSE越小,模型的预测能力越高。
2 结果与分析
2.1 香肠中亚硝酸盐的含量
由表1可知,香肠在储藏过程中亚硝酸盐含量是变化的、不确定的。因此,对香肠储藏过程中亚硝酸盐的检测、监控是必要的。
2.2 光谱预处理
为了减少外界因素对于光谱信息的干扰,需对原始光谱数据进行SG平滑处理。从图1、2中可以看出,经过SG平滑法处理过的光谱曲线相较于原始光谱曲线更平滑,受到的噪音影响很小,有利于后期模型的建立。
表1 亚硝酸盐理化试验结果
Table 1 Physicochemical test results of nitrite content
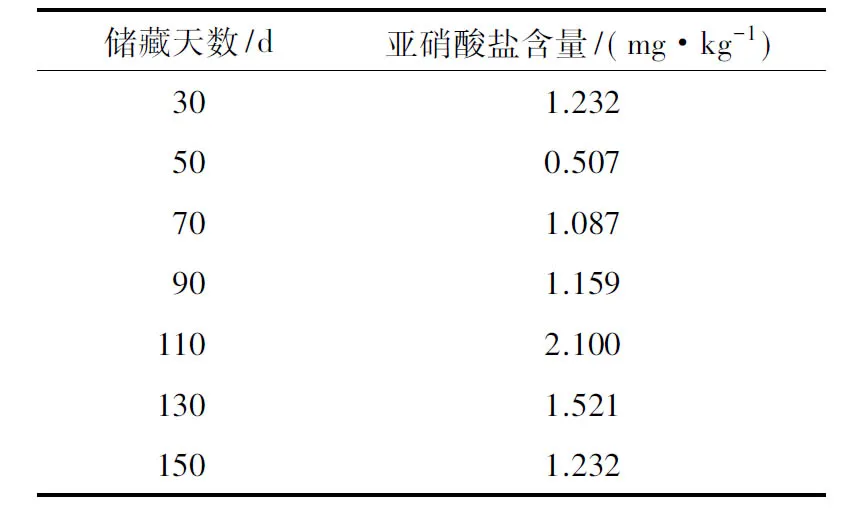

图1 原始光谱图

图2 经SG平滑处理后的光谱图
2.3 特征波长的筛选
可见—近红外高光谱中波长范围是371.05~1 023.82 nm,但试验操作过程中由于首尾波段受环境及仪器噪声影响较为严重,因此在光谱信息分析的过程中应只考虑400~1 000 nm波段下的信息。对全波长数据经偏最小二乘回归分析后,得到的回归曲线如图3所示。第1主成分涵盖的信息较为全面和常见,波动较小,不能较好地体现样本间的差异;第2主成分有一定的波动,可部分体现样本间的差异,所以选取第2主成分回归系数的最大值和最小值所对应的波长作为2个特征波长;第3主成分波动明显,可较好地体现样本间的差异,所以选取第3主成分所有波峰和波谷的回归系数所对应的波长作为特征波长。这样,第2主成分有2个特征波长,第3主成分有27个特征波长,共计29个特征波长。
2.4 特征波长下的定量分析
2.4.1 特征波长下多元回归建模 直接将29个特征波长作为模型的输入变量,进行回归分析。图4给出了第1组数据集的预测结果。由图4可以看出,预测值与真实值相差较大,预测结果精确度不高。表2给出了3组测试集模型预测结果的R2与RMSE,从表2中可以看出,3组预测集R2最高为0.858 8,对应的RMSE为0.168 7,预测结果不理想。考虑到各个特征波长之间会存在一定的相关性,影响建模的精度,故尝试建立特征波长下主成分回归和偏最小二乘回归的预测模型。
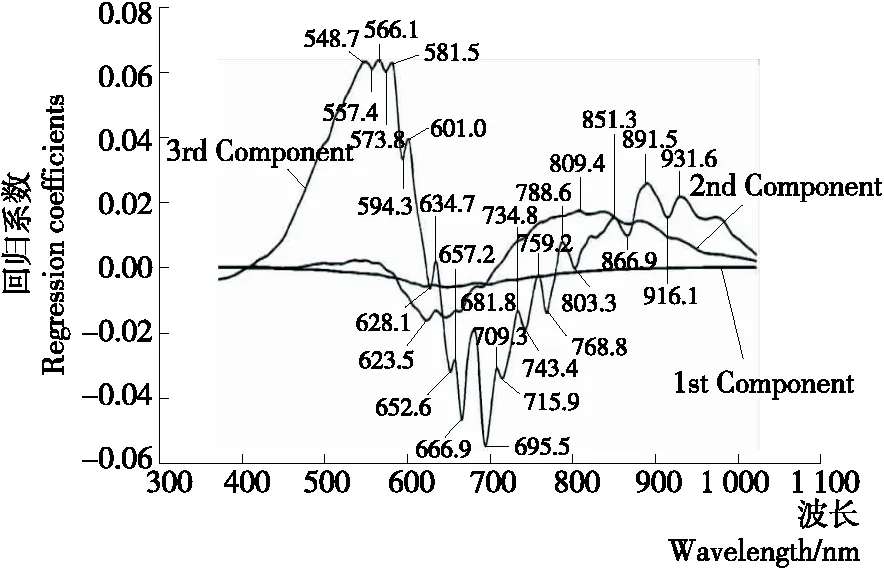
图3 权重系数图
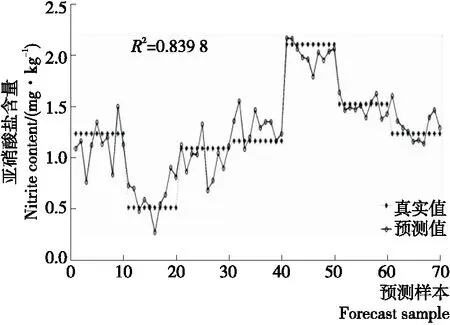
图4 特征波长下多元回归结果
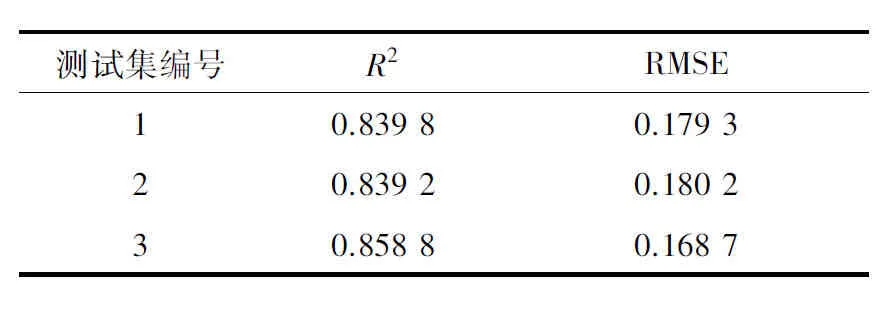
2.4.2 主成分回归模型的定量分析 对29个特征波长变量进行PCA分析,得到按贡献率从大到小排序的29个主成分。经比较,在提取前26个主成分时预测结果准确性相对较高,如图5所示(以第1组测试集为例,下同)。表3为3组测试集模型预测结果的R2与RMSE,从表3中可以看出, 3组测试集的预测结果的R2最高为0.896 1,对应的RMSE为0.148 8,模型精度仍不理想。
表3特征波长下的主成分回归与偏最小二程回归结果
Table3Principalcomponentregressionandpartialleastsquaresregressionresultsatcharacteristicwavelengths

2.4.3 偏最小二乘回归模型的定量分析 对于PLSR模型的构建,经比较,同样在提取前26个主成分时预测结果相对较高,如图6所示。表3给出了3组测试集模型预测结果的决定系数与均方根误差,从表3中可以看出,3组测试集的预测结果的决定系数R2最高为0.911 1,对应的均方根误差RMSE为0.139 7。模型精度有所提高,但还是不太理想。
综合基于特征波长的检测结果来看,在特征波长下建立PCR和PLSR预测模型的结果虽然比直接回归建模分析的结果较优,但仍不很理想,且模型的变量仅降到26个,比29个特征波长并无明显的减少,建模的复杂度仍较高。陈晓东等[13]在用主成分分析方法提取特征波长的基础上构建了预测模型,但预测精度只有0.918,且数据处理过程繁杂。这可能是选择特征波长表达的信息不够全面,不能充分体现原始数据的信息,从而导致了预测模型的精度不高。而岳学军等[22]采用全波长数据信息作为模型输入向量较好地实现了对柑橘叶片叶绿素含量的检测。受此启发,本试验尝试了在全波长下建立PCR和PLSR预测模型的效果。

图5 特征波长下主成分回归结果

图6 特征波长下偏最小二乘回归的结果
2.5 全波长下的定量分析
为了克服特征波长不能充分表征原始光谱信息这一问题,本试验对1 288个全波长数据进行PCA分析;同时选取前29个主成分作为回归模型的输入向量,这样可以与特征波长下的定量分析结果形成对比。
2.5.1 主成分回归的定量分析 在全波长下建立PCR预测模型,基于前29个主成分构建的模型得到的预测结果如图7所示。从图7中可以看出,预测值与真实值较为接近,预测结果精确度提高。表4为3组测试集模型预测结果的R2与RMSE,从表4中可以看出,3组测试集模型预测结果的R2最高为0.952 2,对应的RMSE为0.097 4。模型精度较高,预测结果较为理想。
2.5.2 偏最小二乘回归的定量分析 在全波长下建立PLSR预测模型,其主成分变量仍为前29个,得到的预测结果如图8所示。图8表明,预测值与真实值非常接近,预测结果精度很高。表4为3组测试集模型预测结果的R2与RMSE,从表4中可以看出,3组测试集模型预测结果的R2最高为0.982 9,对应的RMSE为0.059 2。模型精度很高,预测结果非常理想。
预测结果可以表明,全波长下建立的预测模型结果精确度较高,且偏最小二乘回归的结果高于主成分回归的,决定系数可以高达0.978 8以上。因此,在全波长下建立偏最小二乘回归的预测模型可以满足检测要求。综上研究认为,在全波长下建立的主成分回归和偏最小二乘回归预测模型,将变量也降低到了29个,远低于1 288个波长,省去了特征波长的选择计算,不仅简化了数据处理步骤,而且还能得到较为理想的预测结果。另外,也可以认为,全波长下的前29个主成分可以较充分地表征原始光谱数据的信息。
表4全波长下的主成分回归与偏最小二乘回归结果
Table4Principalcomponentregressionandpartialleastsquaresregressionresultsatfullwavelength

测试集编号主成分回归R2RMSE偏最小二乘回归R2RMSE10.952 20.097 40.982 90.059 220.938 30.112 90.978 80.064 730.950 70.100 20.980 20.066 2
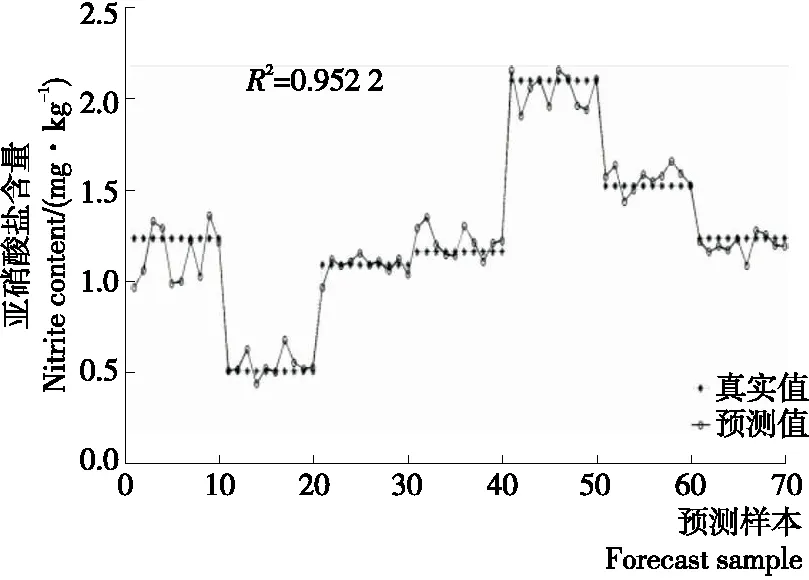
图7 全波长下主成分回归的结果

图8 全波长下偏最小二乘回归的结果
3 结论
采用高光谱技术检测香肠储藏中亚硝酸盐含量时,在提取特征波长的基础上进行回归模型构建,得到的模型精度不高,效果不理想,预测精度最高只达到了0.911 1,且数据处理过程复杂。直接在全波长之下建立的预测模型既可以提高预测结果的精度,又可以降低从预处理到建模计算过程中的复杂性。所以全波长信息作为香肠储藏过程中亚硝酸盐含量高光谱检测模型信息的输入是合适的。另外,考虑到提取特征波长在高光谱研究中的优势,在今后的研究中,应该对特征波长的提取方法进行更多的尝试,以提高检测模型的预测精度。
猜你喜欢
故事作文·低年级(2022年5期)2022-05-29
阅读(科学探秘)(2021年8期)2021-09-01
红领巾·萌芽(2020年2期)2020-05-07
当代水产(2019年6期)2019-07-25
特别健康(2018年2期)2018-06-29
当代水产(2018年12期)2018-05-16
中南大学学报(自然科学版)(2016年2期)2017-01-19
恋爱婚姻家庭·青春(2016年7期)2016-07-05
中国照明(2016年4期)2016-05-17
创新作文(1-2年级)(2016年6期)2016-05-14
