
基于弹性网络正则化的隐因子预测模型
2019-07-16 01:18贺文灏王德贤
计算机应用与软件 2019年7期
贺文灏 王德贤* 邓 萍 刘 锐
1(西华师范大学计算机学院 四川 南充 637000)2(西南交通大学信息科学与技术学院 四川 成都 610000)
0 引 言
在信息数据爆炸式发展的大数据时代,用户要在过载且关联度很低的信息中去选择和发现有用的知识,这给用户带来很大的挑战。研究表明,虽然过载的信息能更好地满足用户需求,但也会降低用户的决策质量。
互联网是当今最好的信息共享渠道,但它也会造成信息过载。因此用户通常需要借助搜索引擎、推荐系统等工具来有效地过滤无关信息,仅保留最能满足用户需求的数据。在用户短时间不能处理和筛选海量信息的领域中,通常借助推荐系统来处理信息。推荐系统现在运用到各个领域中,包括电子商务、科学研究、在线约会、智慧教育等相关领域。
推荐系统高效的处理高维稀疏(High Dimensional Sparse, HiDS)矩阵,并精准地预测稀疏矩阵中的缺失数据。基于协同过滤的推荐系统是推荐系统中的重要分支。在协同过滤推荐系统中LF(Latent Factor)分解技术最受青睐。LF的工作原理是通过将目标矩阵中的实体映射到两个低维的隐特空间,并通过目标矩阵中的已知数据建立一系列的目标函数。通过LF模型求解可以高效精准地预测模型中的缺失数据。因此,LF模型被大量的学者广泛应用于推荐系统中[1-5],其中代表性的模型有 SVD++模型[6-7]、概率矩阵分解模型[8]和非参数化贝叶斯LF模型[9]等。
由于在HiDS矩阵中的已知数据分布是不平衡的,导致目标函数的高度不平衡。因此,仅用隐因子模型来进行HiDS矩阵中缺失数据的预测是不适定的,无法得到全局最优解。为解决这个问题通常采用Tikhonov正则化的方式来保持它的一般性[1-3]。
通过集成Tikhonov正则化即为L2范数到目标函数可以高效地防止模型过拟,增强模型的通用性,但是并不能调整隐因子(Latent Factors,LFs)的分布。在之前的研究中[10-11]表明实体在线性和双线性模型中仅和特征空间的部分维度相关,即实体仅属于本分的实体簇。从这一角度而言,进一步调整实体间LFs的分布,能更加精确地描述实体所倾向的实体簇,增强模型的性能。在传统的线性和双线性问题中已经证明了L1正则化能很好地调整模型目标系统参数的分布[10-11],但由于L1正则化不可微的原因,导致在LF模型通常仅加入L2正则化来对目标函数进行限制。基于此,本文中通过向前次梯度向后截断(Forward-looking sub-gradients and forward-backward splitting, FOBOS)方法[12]来构造一个弹性网络隐因子(Elastic Network Latent Factor, ENLF)模型,将L1和L2同时整合到目标函数中,提高模型性能。本文主要贡献:
① 基于FOBOS方法提出了一个ENLF模型。
② 在ENLF模型中加入偏差提出BENLF(Biased ENLF)模型,增强模型性能。
③ ENLF和BENLF模型的算法设计和分析。
④ 在来自工业应用的2个数据集上验证模型的性能。
1 相关工作
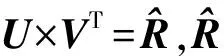
用LF模型来处理高维稀疏矩阵时,本文仅聚焦于目标矩阵中的已知数据Λ。为了衡量目标矩阵R中的已知数据和隐因子空间中对应的实体的预测值之间的差异,通常采用欧几里德距离公式[1,3]来构造目标函数,表示为:
(1)
式中:f表示隐因子矩阵的维度。um,k和vn,k分别是低秩隐因子矩阵U中第m行第k个值和矩阵V中的对应的第n列第k个值。
在之前的研究中[1-3]已证明随机梯度下降(Stochastic Gradient Descent,SGD)算法在求解LF模型的高效性。因此应用SGD算法来求解目标函数时经常考虑在每个训练实例上的瞬时损失。瞬时损失目标函数为:
(2)
式中:在{um,k,vn,k|k=1~f}中每一个决策参数都要执行SGD算法来最小化瞬时损失εm,n,这个求解εm,n的过程对应于Λ中的实体迭代来实现ε(U,V)的局部最优解。式(2)是不适定的,它会导致模型过拟合。为了解决这样的问题,通常通过加入正则化项来解决,具体表示为:
(3)
式中:‖·‖α计算对应向量的Lα正则化值,um和vn分别表示在U和V中第m行和第n列向量。λ为正则化系数。
当α=1时,由式(3)得:
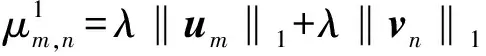
(4)
式(4)用L1正则化对目标函数进行限制,L1能很好地保持模型的稀疏性,调整模型中隐因子的分布,但由于仅用L1正则化来对目标函数进行限制会导致模型的精度损失严重且L1不可导。
当α=2时,由式(3)得:

(5)
式(5)用L2正则化对目标函数进行限制,L2能很好地保持模型的一般性,因此在一般模型中我们通常用式(5)作为目标函数来构造一个SGD_LF模型求解隐因子[1,3]。由于L2不能调整隐因子模型中隐因子的分布和改变实体特征的稀疏性,因此对单一实体而言其实体特征就会和很多非相关簇也存在关联关系,导致在隐因子预测模型中精准损失,在基于隐因子的社区检测中不能很好地预测实体所属的社区关系。
为了解决以上分别仅用L1和L2限制目标函数时存在的问题,本文通过FOBOS的方法来构建一个同时用L1和L2来限制的目标函数的ENLF模型。
2 基于FOBOS的ENLF模型
弹性网络是一种有效的优化框架,其将L1和L2正则化项整合到凸函数ε(U,V)对目标函数进行限制,构成弹性网络隐因子模型的目标函数。其中弹性网络正则化项表达式如下:
(6)
式中:λ1和λ2分别为正则化项参数,它们用于平衡L1和L2对模型的影响。在式(1)中加入正则化项可得:
(7)

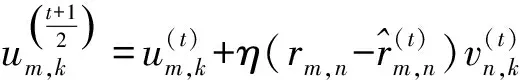
(8)
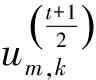
(9)
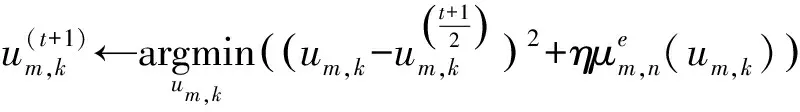
(10)
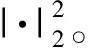
(11)
(12)
式中:将um,k的系数2折进了λ2中,通过整理可得更新公式如下:
(13)
通过设置软阈值,对式(13)进行分析可得um,k的更新规则如下:

(14)
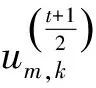
(15)
同样地,可得vn,k的更新公式如下:
(16)
根据FOBOS算法推理,可得ENLF模型实现的算法伪代码如算法1所示。
算法1 ENLF算法
Input:Λ, M, N, f
Operation
InitializeP|M|×f,Q|N|×fat random in(0,0.5)
Initializeη,λ,i=1, Maximum_round_count
1: while not converge andi≤Cdo
2: for eachrm,n∈Λ
5: fork=1 tof
6:um,k_temp=um,k+η×errm,n×vn,k
7:vn,k_temp=vn,k+η×errm,n×um,k
8: end for
9: end for
10: ifum,k_temp>ηλ1
11:um,k=(um,k_temp-ηλ1)/(1 +ηλ2)
12: else ifum,k_temp< -ηλ1
13:um,k=(um,k_temp+ηλ1)/(1 +ηλ2)
14: else
15:um,k=0
16:i=i+1
17: end while
Output: P, Q
3 BENLF模型
在之前的研究中可得[1],隐因子模型中加入偏差能很好地提高模型精度。它的原理是在隐因子训练过程中仅通过已知评分来训练隐因子,但是由于在目标矩阵中实体间产生关系会与每个实体间的差异不同而产生不同的关系值。如在电影评分项目中,不同年龄、群体、职业等差异对物品的评分都有自己的倾向性。加入偏差能在很好地考虑到不同实体间的差异的前提下,得到更好的模型性能。
在ENLF模型中加入训练偏差Tm,n来提高模型的性能。因此在用SGD求解模型,训练单一实例时预测值为:
(17)

Tm,n=cm+cn
(18)
式中:cm和cn分别为目标矩阵行和列对应实体的训练偏差。加入偏差后的目标函数式(7)改写为:
(19)
为了更好表示数学公式推导,令:
(20)
与ENLF模型推导类似,通过SGD对式(19)进行求解,对应实体偏差更新公式为:
(21)
由于L1范数不可导,通过软阈值的方式来处理偏差的更新,得到cm的更新公式为:
(22)
同理,可得到cn的更新公式为:
(23)
(24)
类似ENLF中um,k的更新可得到在BENLF中um,k的更新如下:
(25)

(26)
BENLF模型实现的算法伪代码如算法2所示。
算法2 BENLF模型
Input:Λ, M, N, f
Operation
InitializeP|M|×f,Q|N|×fat random in (0,0.5)
Initializeη,λ,i=1, Maximum_round_count
1: while not converge andi≤Cdo
2: for eachrm,n∈Λ
5: fork=1 tof
6:cm,k=cm,k+η×(errm,n+ηλ2)
7:cn=cn+η×(errm,n+ηλ2)
8: ifcm,k>ηλ1
9:cm,k=cm,k-ηλ1
10: else ifum,k_temp< -γλ1
11:um,k=cm,k+ηλ1
12: else
13:um,k=0
14: end if
15:um,k_temp=um,k+η×errm,n×vn,k
16:vn,k_temp=vn,k+η×errm,n×um,k
17: end for
18: ifum,k_temp>ηλ1
19:um,k=(um,k_temp-ηλ1)/(1 +ηλ2)
20: else ifum,k_temp< -ηλ1
21:um,k=(um,k_temp+ηλ1)/(1 +ηλ2)
22: else
23:um,k=0
24:i=i+1
25: end while
Output: P, Q
4 实验结果及分析
在来自商业应用中的真实数据集上进行测试,验证模型性能。数据集描述如表1所示。
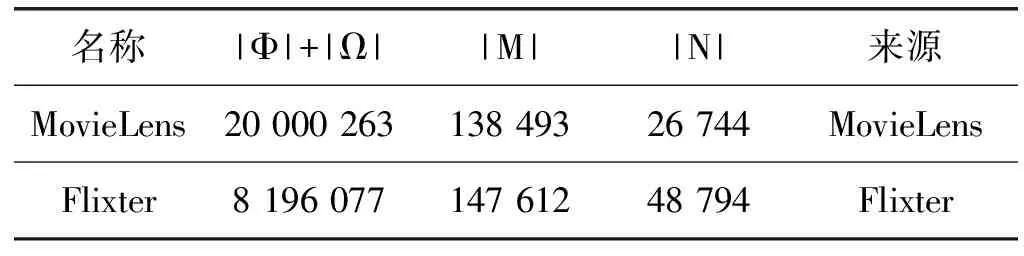
表1 数据集描述
数据集1:MovieLens 20M 数据集(下文中简称MovieLens为D1),由明尼苏达大学通过MovieLens 网站收集, 该数据集中包含了共138 493个用户和26 744 项项目之间的关系,其中共有20 000 263已知评分项。该数据集的稀疏性为0.54%,其稀疏性计算如下:
稀疏性=(矩阵中已知数目/矩阵总数)×100%
数据集2:Flixter 数据集(下文中简称Flixter 为D2),是用于测试推荐预测算法模型性能的重要数据集,共有147 612个用户对48 794个项目评分,其中已知评分数据项为8 196 007万条,该数据集的稀疏性为0.11%。
性能评价度量:由于本文是针对HiDS矩阵缺失数据的预测,因此用预测数据作为模型性能的验证。采取均方根误差[13](Root Mean Square Error,RMSE)来衡量模型对HiDS矩阵中缺失数据的预测精度。令Ω为测试数据集,有|Λ|=|ϑ|+|Ω|。Ω和训练数据集ϑ中的数据不重合:
(27)

本文实验中隐因子空间维度设为f=20,实验中的每个数据集,均采用20%~80%的比例来构造训练-测试数据和5折交叉验证来评估每个模型性能,即将数据集分为5部分,随机选取其中的1部分作为测试数据集,剩余的4部分作为训练数据集。训练过程的停止条件设置为:1) 训练的迭代次数达到1 000轮;2) 相邻两次迭代得到的精度差小于1.0e×10-5。
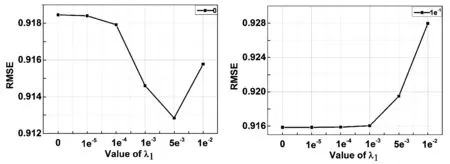
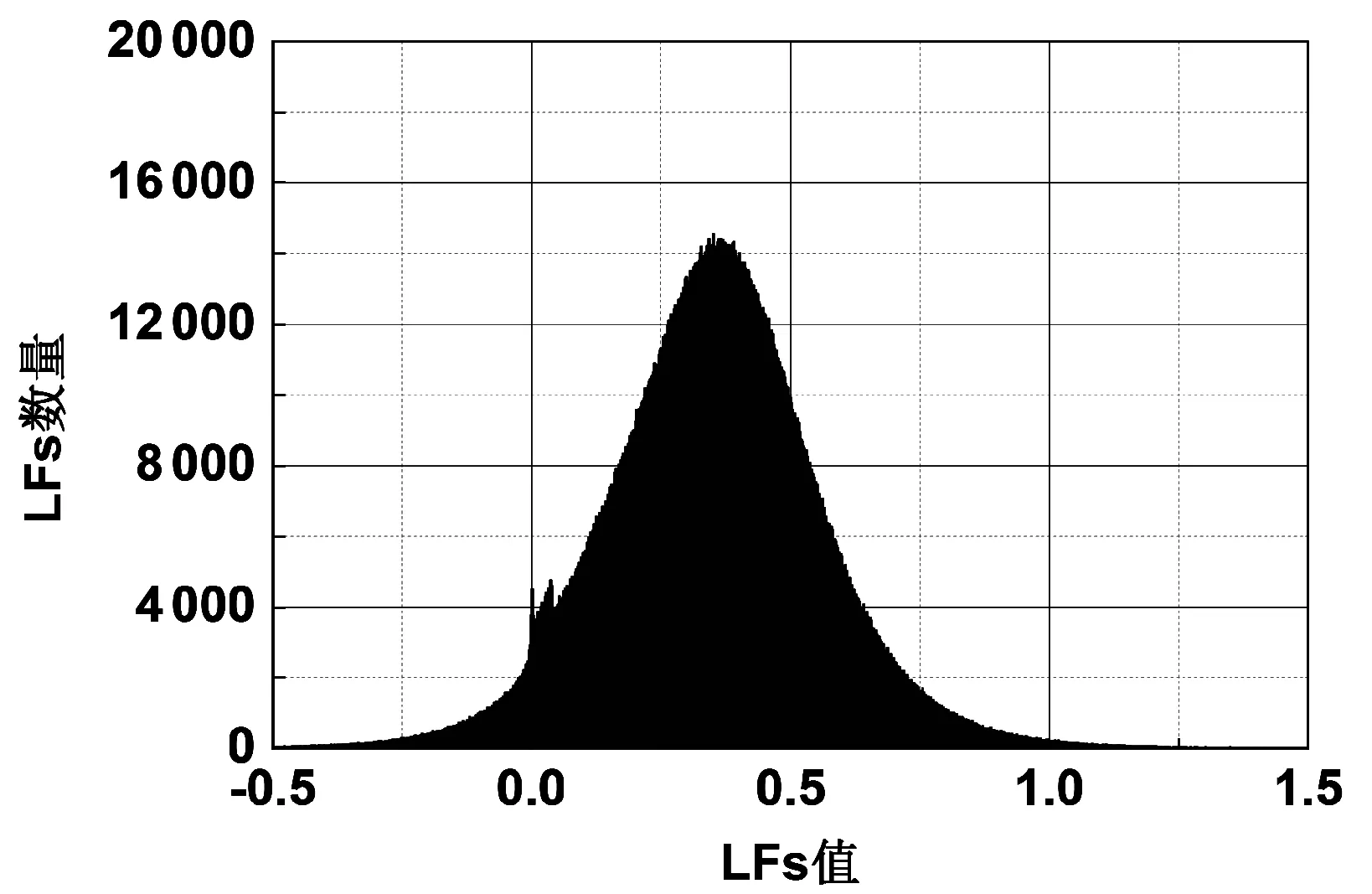
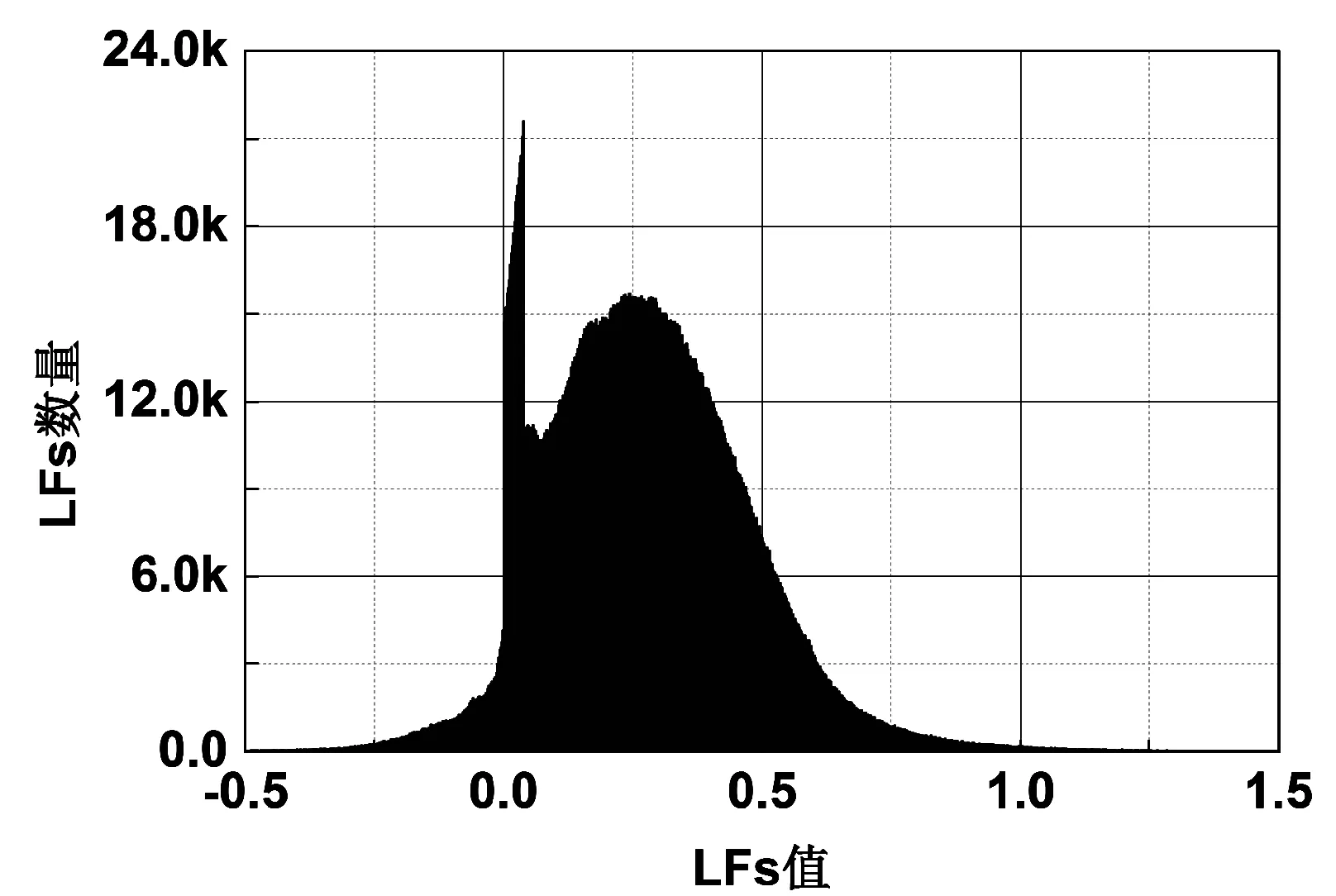
设置SGD_LF模型和本文提出的ENLF和BENLF两种模型进行性能比较,相关实验结果如图1-图5所示。其中:图1、图2分别表示ENLF模型在D1和D2数据集上正则化系数λ1和λ2网格搜索的实验结果。图3、图4分别表示在D1和D2上的λ1对隐因子分布的影响。图5比较三个模型在分别在D1和D2上的预测精度。

(a) λ2=0 (b) λ2=1e-1

(c) λ2=1e-2 (d) λ2=1e-3图1 在D1上RMSE比较
(a) λ2=0 (b) λ2=1e-1

(c) λ2=1e-2 (d) λ2=1e-3图2 在D2上RMSE比较

(a) λ1=0
(b) λ1=1e-3

(a) λ1=1e-2图3 D1的LFs值分布

(a) λ1=0
(b) λ1=1e-3
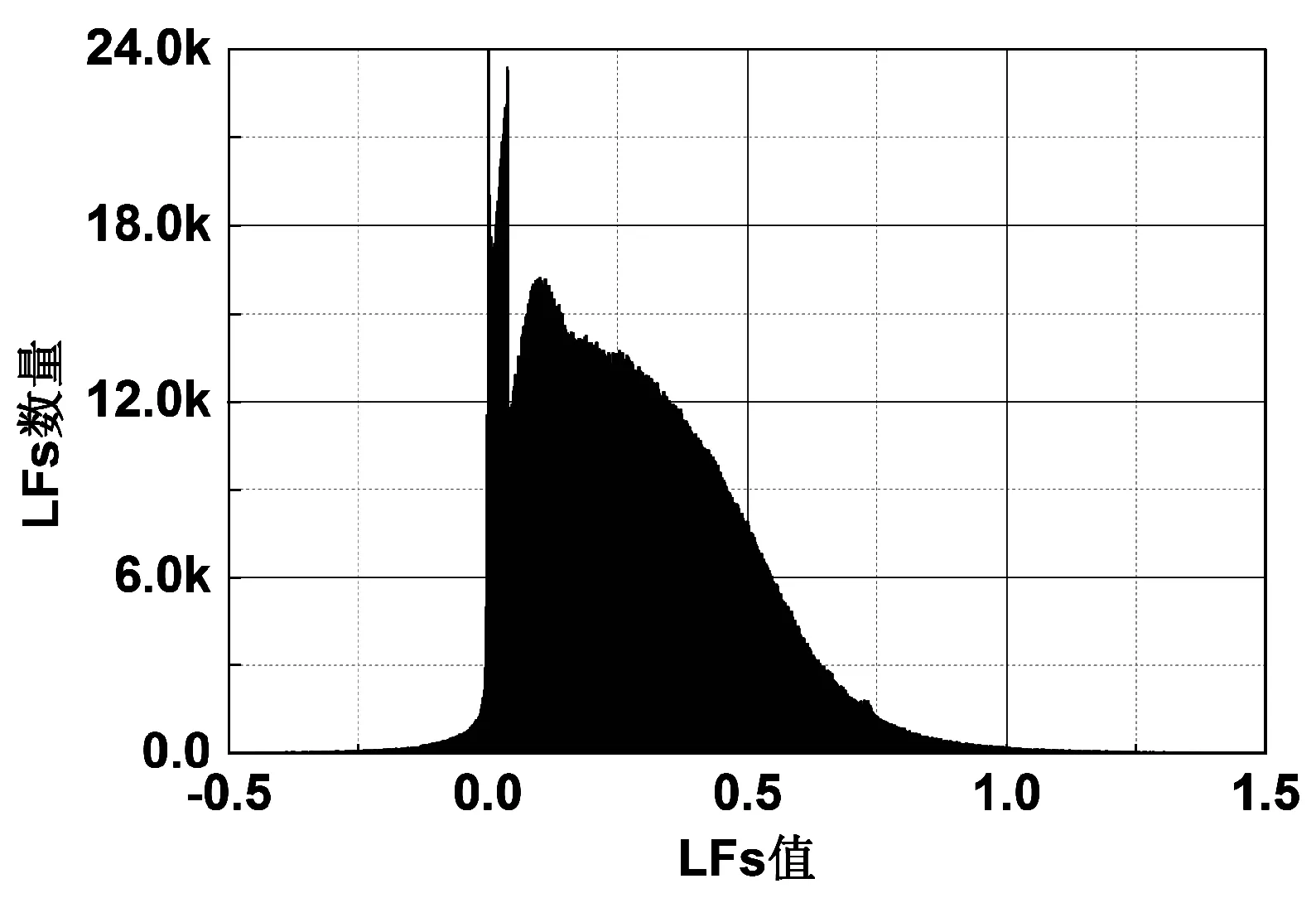
(c) λ1=1e-2图4 D2的LFs值分布
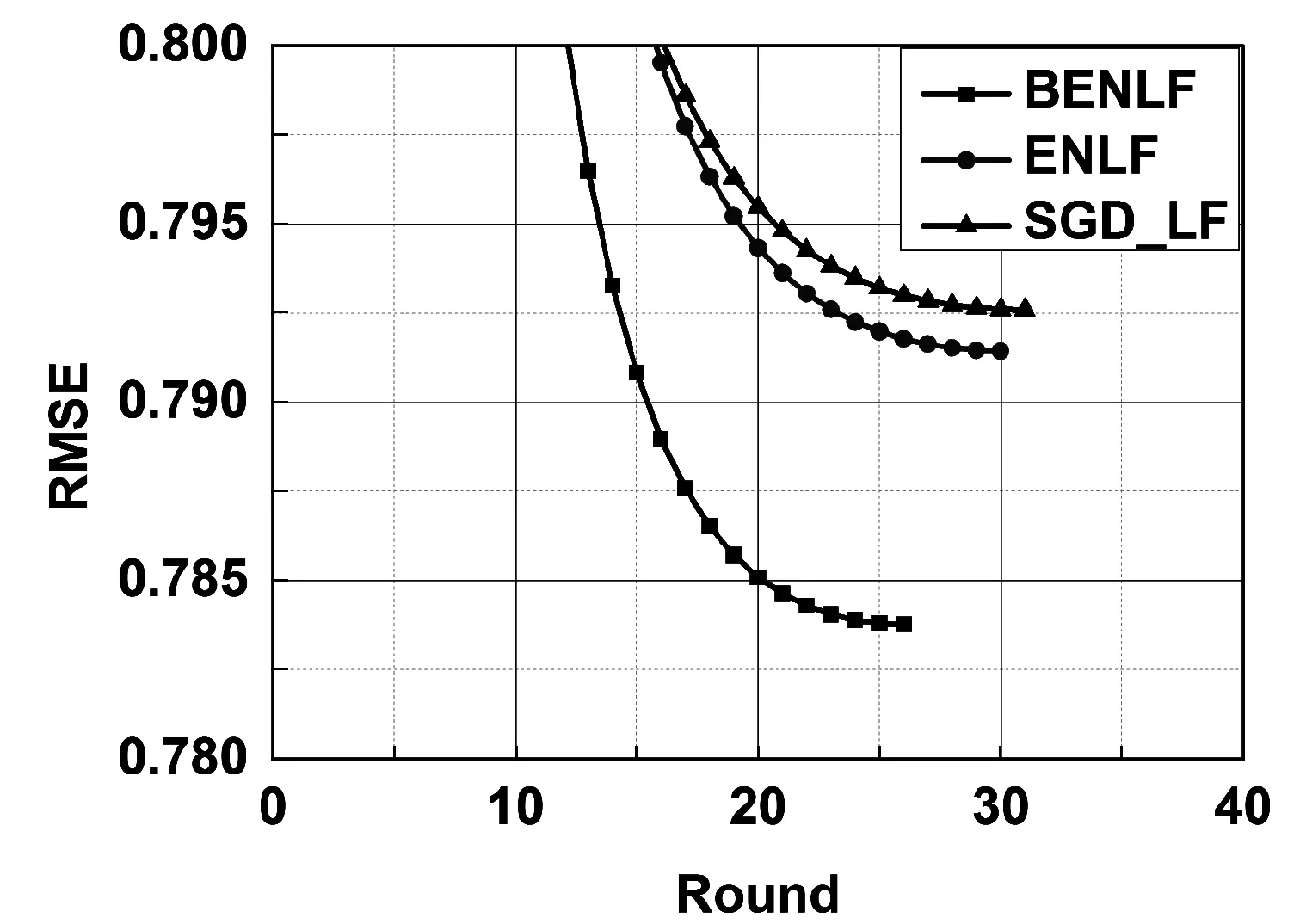
(a) D1上不同模型预测精度比较
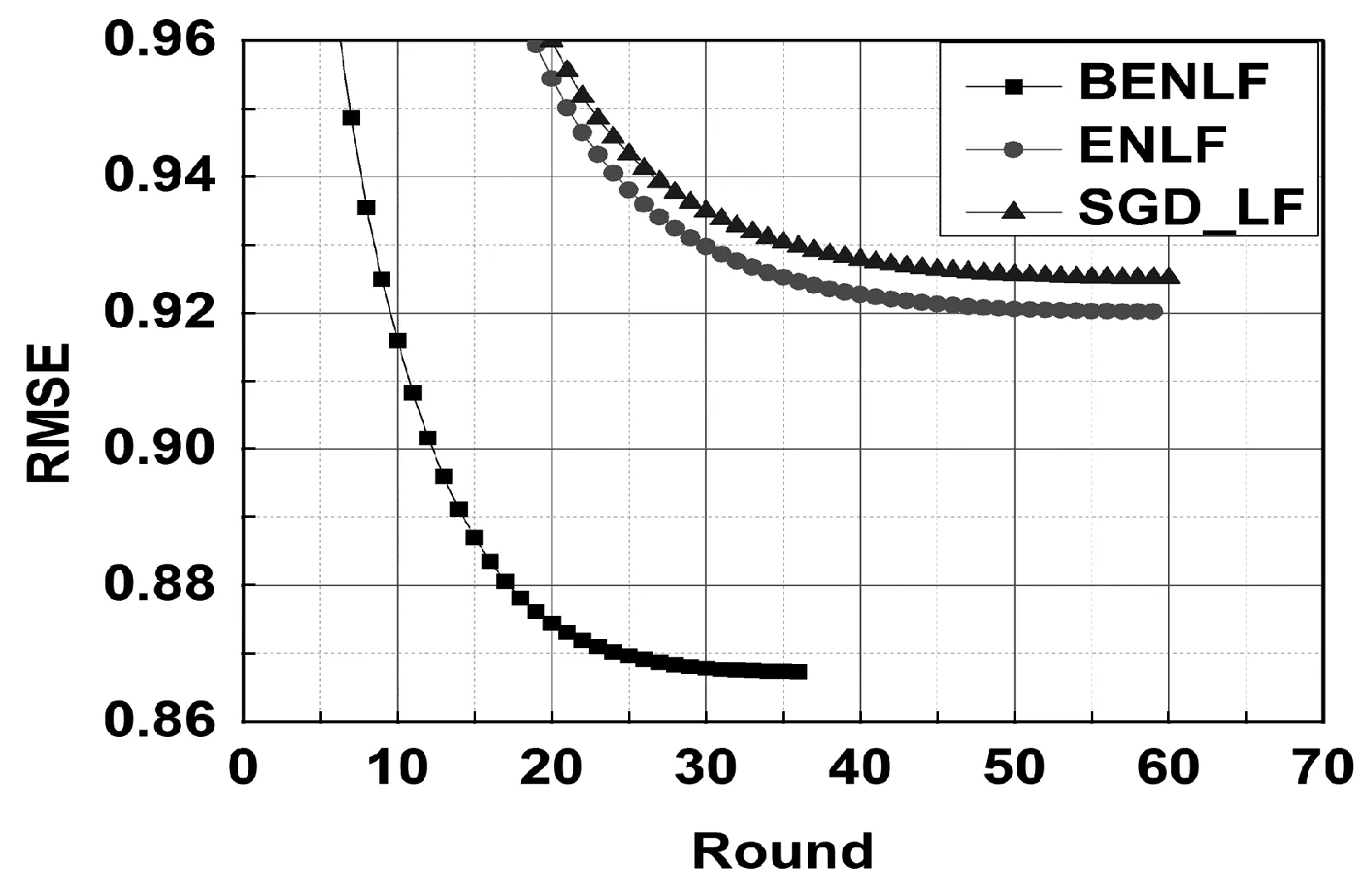
(b) D2上不同模型预测精度比较图5 模型预测精度比较
首先,在图1和图2分别给出了ENLF算法在D1和D2数据集上正则化系数λ1和λ2网格搜索训练实验结果,η均设置为0.001,有以下结论:
① ENLF模型精度高于SGD_LF模型。当λ1=0时,ENLF算法等价于SGD_LF模型。如图1(d)所示,当λ2=1e-4且λ1=0时,SGD_LF模型精度为:0.796,当λ2=1e-4且λ1=5e-4时,可得ENLF模型精度为0.791,ENLF模型精度高于SGD_LF模型0.5%。同样的情况在根据在D2上也可得到,在图2(c)中可得,ENLF模型精度比SGD_LF模型高0.25%。
② ENLF模型比SGD_LF模型能更好地调整模型的隐因子分布,体现对应实体所属的社区关系。由图3可知,在D1上,随着L1系数的不断增大,图3中为零的LFs数量越多,LFs分布图形态也相应改变。同样的情况在D2图4上也能看到。ENLF模型能提高隐因子模型的稀疏性。
为了更好地比较BENLF模型、ENLF模型和SGD_LF模型的性能,实验得到了在η=0.005时模型训练图,对模型进行更加详细的比较,如图5所示,可得到如下结论:
① BENLF模型精度远高于ENLF和SGD_LF模型性能,如图5(a)所示,BENLF模型的预测精度为0.868,ENLF和SGD_LF模型精度分别为0.921和0.925,BNILF分别比ENLF和SGD_LF模型精度高出5.75%和6.16%。同样的情况在D2上图5(b)中可见,BNILF分别比ENLF和SGD_LF高出1.01%和1.13%。
② BENLF模型的收敛速度远高于ENLF和SGD_LF模型,如图5(a)所示,BENLF模型的收敛轮数为37,ENLF和SGD_LF模型的收敛轮数分别为58和60轮,BENLF的收敛速度分别是1.56和1.62倍。同样的情况在D2也能得到。BENLF模型的收敛速度分别比ENLF和SGD_LF模型快1.15和1.23倍。
5 结 语
本文实现了一个同时带有L1和L2的弹性正则化ENLF模型。该模型不仅能通过L2来防止模型过拟合,也能通过L1来改变隐因子的分布,提高模型预测精度。本文在提出ENLF模型基础上又加入偏差,构建了BENLF模型,对比ENLF模型和SGD_LF模型,发现BENLF模型大大提高了模型的精度和收敛速度。在下一步工作中,将聚焦于模型参数自适应选择的相关研究,提高模型的效率。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
一重技术(2021年5期)2022-01-18
华南师范大学学报(自然科学版)(2021年5期)2021-11-09
当代陕西(2019年5期)2019-03-21
上海师范大学学报·自然科学版(2018年3期)2018-05-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
21世纪商业评论(2018年3期)2018-03-02
神州·上旬刊(2017年9期)2017-10-15
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
