
基于谷歌翻译及Doc2vec的中英句子相似度计算
2019-07-16 03:14王闻慧
电脑知识与技术 2019年15期
王闻慧
摘要:句子相似度计算在统计机器翻译、基于实例的机器翻译与语料对齐领域有着巨大的研究价值。本文借助于谷歌翻译作为媒介,针对由Word2vec改进而来的表示句子向量的方法——Doc2vec模型,对中英句子相似度计算进行了研究。分别利用谷歌翻译将中文译文进行中文句向量训练及计算与英文译文的英文句向量训练及计算对比分析。实验结果表明,基于Doc2vec的方法在计算句子相似度方面,无论是中文句向量还是英文句向量,其作为句向量表达句子含义的准确性都还有待商榷。
关键词: Doc2vec;谷歌翻译;句子相似度计算;双语句对齐
中图分类号:TP391 文献标识码:A
文章编号:1009-3044(2019)15-0224-04
Abstract: Sentence similarity calculation has great research value in the fields of statistical machine translation, instance-based machine translation and corpus alignment. This paper uses Google Translate as a favorable medium to study the similarity between Chinese and English sentences based on the Doc2vec model, which is improved by Word2vec, which represents the sentence vector. Using Google Translate to use Chinese translation to carry out Chinese sentence vector training and calculation and English sentence vector training and calculation comparison analysis. The experimental results show that the Doc2vec-based method in terms of calculating sentence similarity, whether it is Chinese sentence vector or English sentence vector, its accuracy as a sentence vector to express sentence meaning is still open to question.
Key words: Doc2vec; Google Translate; sentence similarity calculation; bilingual sentence alignment
1 引言
句子相似度计算在统计机器翻译、基于实例的机器翻译与语料对齐领域有着巨大的研究价值。进行句子相似度计算的经典方法就是IBM的语言模型,但IBM的模型对于句子相似度的计算仅停留在表层,如词型、语序、句長等,没有深入到语义层面,也就造成了该模型对两个在结构和用词有着巨大差异的同义句无法计算出。为此,我们考虑利用包含了部分语义特征的句向量和词向量来进行句子相似度计算,作为不同于IBM语言模型的一种新的方法探索。
句子相似度的计算与句子表达有着密切的关系。最常用的句子特征的表达有词袋模型或者是向量空间模型( vector space model,VSM)。在建立向量空间模型的过程中,由于词频—逆文档频率( term frequency inverse document frequency, TF-IDF) 计算相对简单,有较高的准确率和召回率,成为使用最广泛的权重计算方法。词汇的 TF-IDF 值可以衡量其对于文本的重要程度,一个词在某一篇文本中出现频率越高,而在语料库其他文本中出现的频率越低,则该词越能反映一篇文章的主题,相应的 TF-IDF 值也越大。从以上 TF-IDF 值的物理意义可以看出,这种采用 TF-IDF值作为权重的向量空间模型只包含统计信息,而无法表达每个词汇的语义信息。
在实际应用当中,只考虑词汇出现的频率是远远不够的。目前随着神经网络的兴起,词汇表达也不再停留在原始的独热表示(one hot),基于神经网络的词汇稠密向量化表示方法——Word2vec已经在自然语言处理的各种任务中都有较好的效果。
虽然Word2vec表示的词性量不仅考虑了词之间的语义信息,还压缩了维度。但是,有时候当我们需要得到Sentence/Document的向量表示,虽然可以直接将Sentence/Document中所有词的向量取均值作为Sentence/Document的向量表示,但是这样会忽略了单词之间的排列顺序对句子或文本信息的影响。基于此,Tomas Mikolov 提出了 Doc2Vec方法。本文旨在通过谷歌翻译这个媒介将两种语言提升在同一平面,利用Doc2vec模型进行相似度对比。本文首先用谷歌翻译将平行语料中的中文译成英文,再得到英文译句的句向量,通过计算平行语料英文句与中文所对应英文译句的相似度,最终得到双语句对齐结果。研究发现结果不佳,本文考虑到谷歌翻译系统对英译中的效果要好于中译英,因此针对这个特点再对平行语料的英文进行翻译,得到中文句向量后计算最终的句子相似度。
2 研究综述
随着深度学习的广泛应用,作为神经网络训练N-gram语言模型“副产物”的Doc2vec也被应用在众多NLP领域之中。例如,贾晓婷等人通过结合Doc2vec与改进聚类算法实现了中文单文档自动摘要,主要做法为先利用Doc2vec训练出结合上下文语境、语义信息的语句向量,再通过经过改进的K-means算法对语句向量进行聚类,计算每个类簇中句子的信息熵,将类中与其他句子语义都相似的句子提取出来作为摘要句。杨宇婷等人采用了一种基于文档分布式表示的方法对微博文本进行文本分类。先是结合上下文语义、语序和情感等特征生成文本高维空间的特征向量,再利用支持向量机判断文本的情感极性。潘博等人将doc2vec模型用于薪水的预测当中,以模型能够深层次表示文本语义特征的优势,结合随机森林、 SVM 等机器学习算法建立薪水预测模型,实验结果表明使用doc2vec模型预测薪水能将误差率降低5%。
另一方面,目前已经有很多基于word2vec所做的一些应用。唐明等人在word2vec基础上加入TF-IDF值,改进了以往研究中对文档向量未考虑单个词产生影响的缺陷,在文档向量化表示中表现出很好的效果。王明文等在基于word2vec模型的基础上提出了一个两阶段大中华区词对齐模型,通过用 word2vec模型得到大中华区词语的向量表示形式,并利用有效的余弦距离计算方法以及后处理技术,实验表明该模型在维基百科词对齐上取得了较高的准确率。唐亮等人利用词向量来解决越汉跨语言信息检索中的查询翻译问题,首先构建汉语、越语事件关键词特征向量,再通过计算两者之间语义相似度实现检索关键词翻译上的对齐问题,并在实验中验证了方法的有效性。郑文超等人利用word2vec实现了对中文词进行聚类的研究,在进行过中文分词的基础上用word2vec对每个词进行向量化表示,再通过计算余弦距离计算相似度,最后使用K-means聚类算法将获取的词向量进行聚类。冯冲等人提出了一种在词向量层面的实体链接方法,该方法充分利用了指称以及候选实体的语义信息。首先利用神经网络对词向量进行训练,然后将实体聚类所获得的类别标签作为特征,最后用多分类模型预测目标实体的主题类别从而完成实体消歧的任务。杨阳等人提出了一种用词向量发展微博新词的方法,其主要思想在于用基于词频、左邻接熵、右邻接熵、互信息这四个统计量的方法识别出新词,再通过神经网络训练出词向量,结合词向量中的语义关系从而挖掘情感新词。
3 基于Doc2vec的句子相似度计算
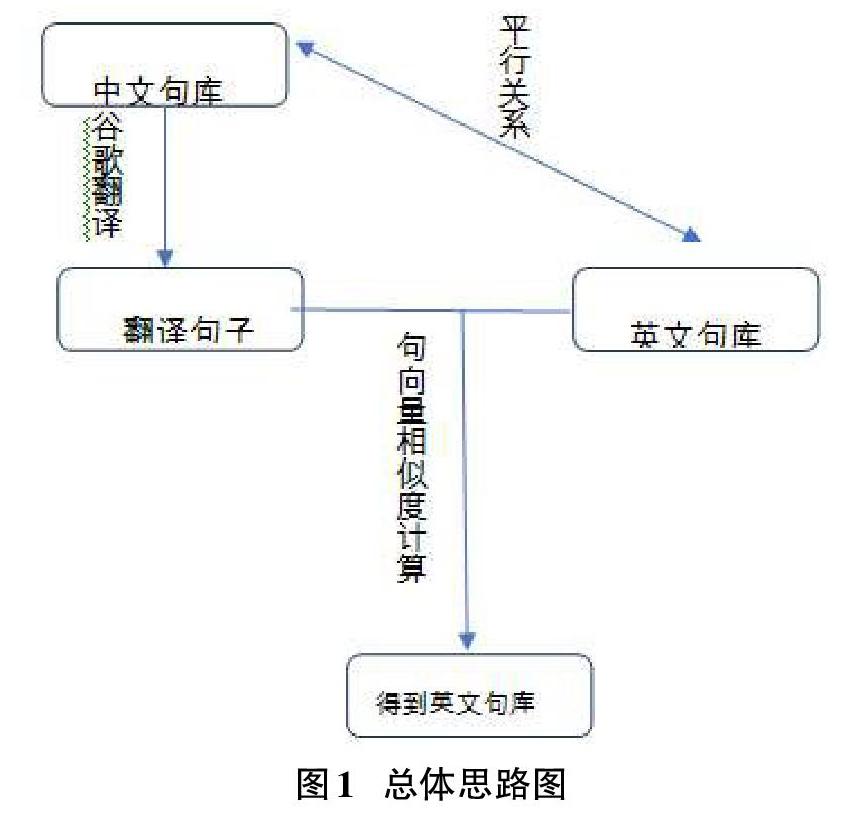
本文在平行语料的基础上进行句子相似度的计算,总体思路为:通过谷歌翻译对中/英文句子进行翻译,再将翻译好的句子进行句向量的相似度计算从而找到原句子所对应的中/英文平行语句。实验分别从中译英——计算英文句向量和英译中——计算中文句向量两方面入手,其次,再通过训练词向量对句子相似度计算结果进行对比。总体思路如下图所示:
3.1 独热表示
One-hot(独热表示)又称稀疏向量,属于早期常用的词向量方法。其主要思想为基于词典大小N,建立一个N维的词向量,对于每一个词只有其中一维是1,其余全为0。例如词典中包括书包、水杯、牙缸这三个词,其向量分别是书包(1,0,0),水杯(0,1,0),牙缸(0,0,1)。这种方法能够根据词向量之间夹角余弦值对不同词之间进行有效区分,然而也正是由于每个向量之间余弦值都为0,词与词在语义上的相似性也无法得到表示。其次,one-hot的维度为词典规模大小相等,这就直接引起向量长度过长所导致的维度灾难。
3.2 Word2vec模型介绍
Word2vec模型是在NNLM(Neural Network Language Model)与Log-linear模型的启发下由Mikolov等人提出来的。通过训练,word2vec模型可以将对文本内容通过神经网络训练成为N维向量,因此对文本内容的处理就可以扩展为在由这些向量組成的向量空间上的向量运算,而这些文本内容在向量空间上的相似度可以用来表示其在语义上的相似度。目前,Word2vec所能做的与NLP相关工作有很多,例如句法分析、情感分类、信息检索、中文分词等。
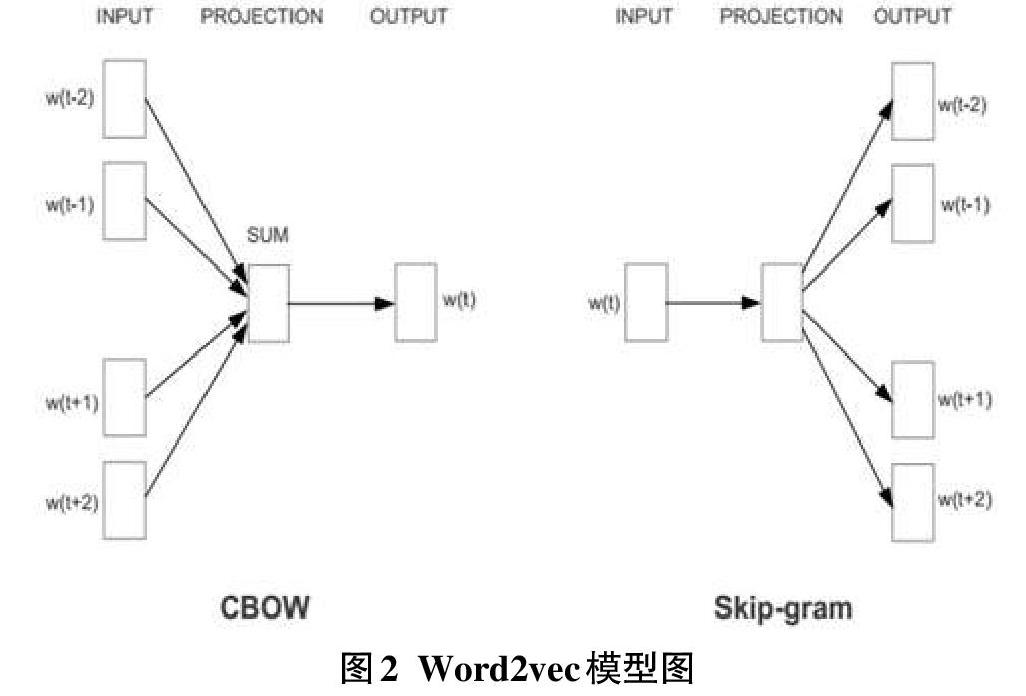
Word2vec模型有两种方法生成,分别是CBOW(Continuous Bag-Of-Words)词袋模型和skip-gram模型。其中,CBOW模型的目标是根据上下文预测当前词,而Skip-gram模型与CBOW模型正好相反,其是通过当前词预测词前后的上下文。在CBOW模型中,词的上下文被“装”进了词袋中,其中每个词都被视为是同等重要而忽略了词的顺序关系。如图1所示,w(t-2),w(t-1),w(t+1),w(t+2)表示当前词w(t)前后两个词,SUM所表示的是这些词所对应向量的累加和。在Skip-gram模型中输出的则是当前词上下文的向量序列。Skip-gram模型可以克服N-gram语言中窗口大小的局限性,以其“跳跃性”的特点概括超出窗口更完整的语义。例如“这个电影拍的真是太好看了”中有4个3元词组,分别为“这个电影拍的”,“电影拍的真是”,“拍的真是太好看”,“真是太好看了”。这4个3元词组都无法表示句子的真正完整的含义,而Skip-gram模型就允许中间某些不那么相关的词被跳过,从而使得窗口向后移动以表示更完整的语义。词在输入层被表示为向量之后通过向量相加或者连接进入到隐藏层,根据词在语料中出现的频数构建Huffman树,再根据Huffman树进行logistic分类从而达到不断修正中间向量和最终词向量的目的。
3.3 Doc2vec模型介绍
文本向量化就是将一个文本表示成一个向量的形式。对文本进行向量化处理可以便于计算两个文本之间的相似度,因此被广泛地用于信息检索、机器翻译、文本聚类等自然语言处理相关领域之中。文本向量化方法是基于词向量方法的基础上的,较早的有BOW(词袋)模型,与one-hot模型类似,向量的维度等于词典的大小N,每一维代表一个词是否在文档出现,出现则为1,不出现则为0。这种词袋模型同one-hot模型一样会引起“维度过高”的灾难,并且对于一篇文本而言,其总词数远小于词规模,这就在一定程度上造成了资源的浪费。在计算文本相似度方面,除了词袋模型以外,比较常见的用于计算两个文本相似度的则是计算TF-IDF值,考虑了单词在文章中的出现次数,并结合其在整个文本数据集中的出现次数来对词是否具有区别性特征进行判断。
作为一个处理可变长度文本的总结性方法,Mikolov等人在word2vec的基础上提出了 Doc2vec方法。Doc2Vec是一种无监督式学习算法,可以获得句子、段落和文档的向量化表达,是word2vec的拓展。学出来的向量可以通过计算距离来判定 sentences、paragraphs、documents之间的相似性,或者进一步可以给文档标签。
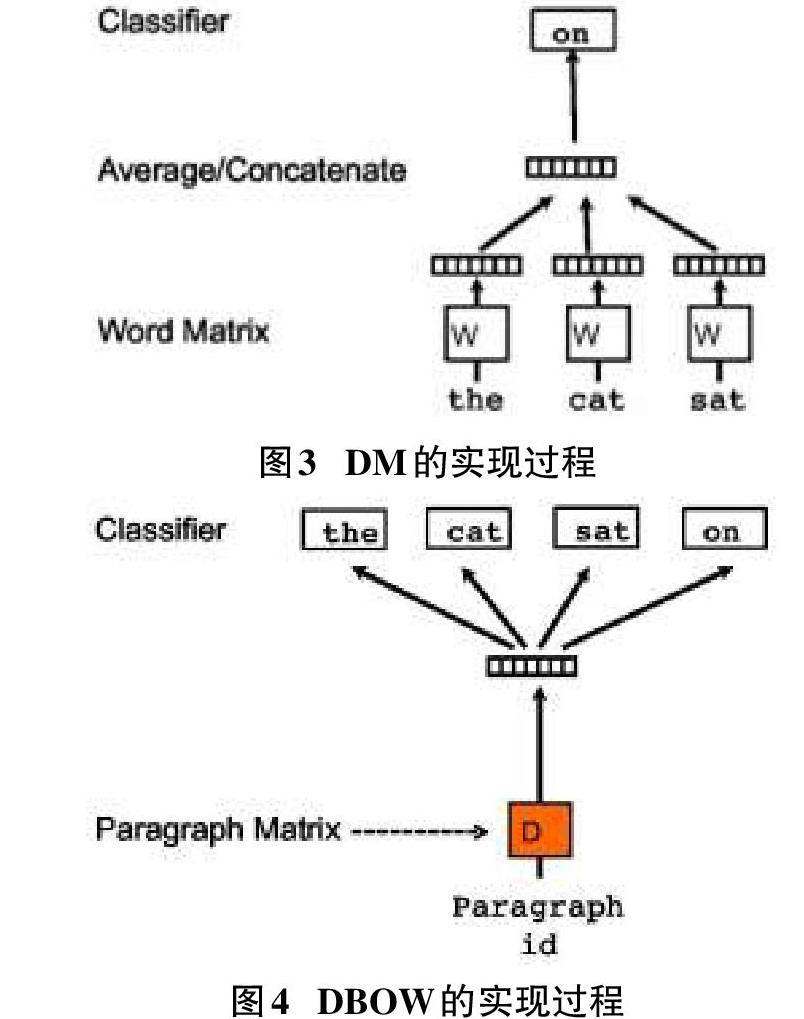
与word2vec模型类似,doc2vec模型也分为两种方法,即Distributed Memory(DM) 和 Distributed Bag of Words(DBOW),与word2vec模型中的CBOW和Skip-gram相对应。主要思想为在神经网络训练词向量过程中加入文本向量ID,整个过程中文本向量保持不变,文本向量同词向量进行连接或者相加,对于给定的上下文预测当前词或者根据当前词预测上下文,最后通过梯度下降的方式收敛得到最终的词向量和新文本向量。以图为例,图1代表着DM方法的整个过程,输入的是“the”、“cat”、“sat”三个词 以及这句话的向量ID,以此来预测下一个词为“on”。图代表DBOW的实现过程,输入的是整个句子的向量(ID),目的是预测出整句话的词语序列。
3.4 实验语料
实验中用于Doc2vec句向量的训练语料选自于中英平行句对2万句,大小约为2MB。
3.5 实验过程
在上述整体思路的基础上,本文选取中英平行语料的中文前50句作为测试语料,将谷歌翻译当作中介从而实现中文语料到英文句子的转换,在用维基百科语料训练出来的词向量作为实验材料,将中英平行语料的英文前50个例句用Doc2vec句向量表示成句向量。其中,中英平行语料的中文句子记为C1,中英平行语料的英文句子记为E1,通过谷歌翻译将C1翻译成的英文句子记为E2。其次,由于在实际中计算相似度的时候,候选句子不可能是语料中所有句子,而在句对齐的时候,候选句子也仅限于该句的上下文一定范围内的句子,因此本组在上述方法的基础上将E1、E2相似度计算的范围由原来E2与所有E1的对比缩小为E2与E1上下两句的对比,并通过设立一定的阈值来处理多对一的问题。
在实验过程中,首先将中英对齐语料中的英文语料存成csv格式,再通过提取Discuss项将语料提取出来,用作训练语料。然后再按照分词结果将词存在x_train列表里面,通过训练命令训练出句向量。将待中文语料翻译好的句子作为输入存为strl,将其表示为句向量以后计算出与strl最相近的前20位结果。如输入句为They lost the land and were captured by the invading army. 而结果如下图5。
由结果可看出在这20句中没有出现中英文平行语料中所对应的那句,实验总共测试了100句,能在前20句找到对应的英文例句有32句,准确率仅仅达到了32%。
类似的,考虑到谷歌翻译在英译中方面翻译效果更佳,本文对英译中的中文句向量进行相似度计算,总共测试的100句中能在前20句找到的对应中文例句有27句,准确率仅仅达到27%。
4 实验结果分析
本文采用Doc2vec模型的主要原因在于该模型一定程度上克服了稀疏向量在语义相似度联系上的缺陷,利用神经网络训练融合了上下文语境信息,其次该模型压缩了数据规模,将词表示成固定长度的稠密低维实值向量,除此之外生成Doc2vec模型仅仅需要做很少的手工工作,因为是由神经网络来自动提供特征信息。其次,该模型忽略了单词之间的排列顺序对最终结果的影响,即模型只是基于词的维度进行了所谓的“语义分析”,而并非像传统语言学那样依据上下文进行真正意义上语义分析。
从实验结果来看,Doc2vec的方法对于中文句向量相似度的准确率达到27%,英文句向量相似度的准确率达到32%。这说明:
1) 从Doc2vec原理来看,它只是训练词向量基础上加进去的一个副产物,而其本身训练出来的句向量是否真正能表示文本语义还有待考量。
2) 本文所采用的将机器翻译作为一种媒介辅助最终的相似度计算是一种创新式的构想,有效地实现机器翻译在其他任务上的重要作用。
针对本研究方法最终结果由此分析得到本文所使用的方法有以下不足之处:
1) 在向量维度统一化处理阶段,将每句话都补全为所有句子中最长的维度,会造成原本语义相似的句子距离相对扩大。
2) 在计算句子向量时未将停用词都去除掉,这就导致一些含有is、a、of等非关键词占有影响最终结果的比重,如果将停用词都去除掉实验的准确率将会有一定程度的提高。
3) 本组工作下一步能提高改进的地方还有很多,例如,可以将Doc2vec训练得到的句向量、句子长度、句法结构等都作为有用信息添加进去并将其赋予一定的权重,有望进一步提高最终结果的准确率。
4) 实验的句子数不够多,下一步将使用更大规模的训练语料和测试语料进行实验。
5 结束语
基于Doc2vec计算句子相似度的方法在短文本的实验上效果不佳,这不仅仅与实验语料规模、句长语序等方面有关,最重要的是其作为被外界称为是Word2vec的“升级版”这一说法的理论依据性有待考量,用Doc2vec训练出来的句向量是否有句子语义相关的意义还有待商榷。另外,本文的方法在一些细节处理上还有待优化,并可以加入一些规则的信息,如句法结构等信息来进一步提高计算的准确率。
此外,本研究在句向量上进行的句子相似度计算的不理想也说明了句向量在自然语言处理任务中的作用比较有限,也折射出深层语言学信息难以直接用数字来度量以支持神经网络进行语言信息处理的难题,而这也是我们今后努力的方向。
参考文献:
[1] 熊富林,邓怡豪,唐晓晟.Word2vec的核心架构及其应用[J].南京师范大学学报(工程技术版),2015,15(1):43-48.
[2] 王明文,徐雄飞,徐凡,等.基于word2vec的大中华区词对齐库的构建[J].中文信息学报,2015,29(5):76-83.
[3] 唐明,朱磊,邹显春.基于Word2Vec的一种文档向量表示[J].计算机科学,2016,43(06):214-217+269.
[4] 唐亮,席耀一,彭波,等.基于词向量的越汉跨语言事件检索研究[J].中文信息学报,2018,32(3):64-70.
[5] 张剑,屈丹,李真.基于词向量特征的循环神经网络语言模型[J].模式識别与人工智能,2015,28(4):299-305.
[6] 杨阳,刘龙飞,魏现辉,等.基于词向量的情感新词发现方法[J].山东大学学报(理学版),2014,49(11):51-58.
[7] 杨宇婷,王名扬,田宪允,等.基于文档分布式表达的新浪微博情感分类研究[J].情报杂志,2016,35(2):151-156.
[8] 贾晓婷,王名扬,曹宇.结合Doc2Vec与改进聚类算法的中文单文档自动摘要方法研究[J].数据分析与知识发现,2018,2(2):86-95.
[9] 姜天文,秦兵,刘挺.基于表示学习的开放域中文知识推理[J].中文信息学报,2018,32(3):34-41.
[10] 刘知远,孙茂松,林衍凯,等.知识表示学习研究进展[J].计算机研究与发展,2016,53(2):247-261.
【通联编辑:梁书】
