
基于注意力机制和残差连接的BiLSTM-CNN 文本分类
2019-07-25 08:03关立刚陈平华
现代计算机 2019年17期
关立刚,陈平华
(广东工业大学计算机学院,广州510006)
0 引言
随着互联网和移动互联网的快速发展,每天产生的文本数据呈爆炸式增长[1]。由于文本数据的混乱,很难通过手工方式进行组织和区分。文本分类是计算机应用于根据特定的分类系统或标准自动分类文本集[2-3]。在文本分类中,如何通过预处理获取文本特征信息,一直是学界研究的热点问题[4]。随着深度学习技术的飞速发展,相比较于传统的文本分类算法如朴素贝叶斯、支持向量机(Support Vector Machine,SVM)等[5-8],深度学习在文本分类上的应用所取得了更好的效果。
卷积神经网络(CNN)是一种前馈神经网络,最初受到猫眼视觉机制的启发[9],它的神经元可以响应部分覆盖范围的周围区域,并且在图像识别和语音识别等任务中具有出色的性能[10]。与其他深度学习结构相比,CNN 需要的参数少。Kalchbrenner 提出将CNN 应用于自然语言处理并设计动态神经网络(DNN)来处理不同长度的文本[11];Kim 将经过预处理的词向量作为输入,利用卷积神经网络实现句子级别的分类任务[13]。
对于序列化数据的输入,循环神经网络(Recurrent Neural Network,RNN)能够获取文本的全局特征信息[14],类似于人拥有记忆能力。在RNN 中,对于输入的序列数据,读取的当前单词输出与之前的输出有关联。但是在传统的RNN 中,会出现梯度消失和梯度爆炸等问题[15]。
为了解决梯度爆炸问题,可在训练过程中使用梯度裁剪(gradient clipping),即在训练过程中,如果反向传播的梯度大于所给的定值,将梯度进行同比缩放[15]。在解决梯度消失问题时,提出了长短期记忆(LSTM)。作为RNN 的子类,LSTM 不仅继承了RNN 模型的优点,而且解决了RNN 的梯度消失问题。而且,它具有更强的“记忆能力”,可以更好地获得文本的全局特征信息[17]。以LSTM 为基础的双向循环神经网络(Bidirectional LSTM,BiLSTM)不仅可从前往后读取文本,同时也从后往前读取,能进一步获取文本的全局特征,从而提高文本分类的准确率[18]。
本文的主要贡献如下:
(1)将CNN 与BiLSTM 进行结合。在提取文本特征信息时,既可以让CNN 提取文本局部特征,又可以让BiLSTM 提取文本全局特征。
(2)结合注意力(Attention)机制,可以进一步获取对文本分类结果产生影响的重点单词的特征。
(3)引入残差连接,从而克服神经网络模型层数过深时,神经网络的退化问题。
1 LSTM网络
LSTM 作为升级版的循环神经网络,其基本神经元由一个记忆单元(Constant Error Carrousel,CEC)和三种门(Gate)结构组成,其中CEC 是LSTM 的重点。CEC是一种自连接单元,可保留持久的记忆信号,使LSTM能够编码远距离上下文历史信息[19]。LSTM 模型中三种门分别是遗忘门(Forget Gate)、输入门(Input Gate)和输出门(Output Gate)。LSTM 依靠门信号对信息进行添加和删除,其中信号值1 表示“让所有信息通过”、信号值0 表示“不让任何信息通过”。图1 是LSTM 神经元的网络结构图。
LSTM 中遗忘门表达式:

LSTM 中输入门表达式:

LSTM 中CEC 更新表达式:
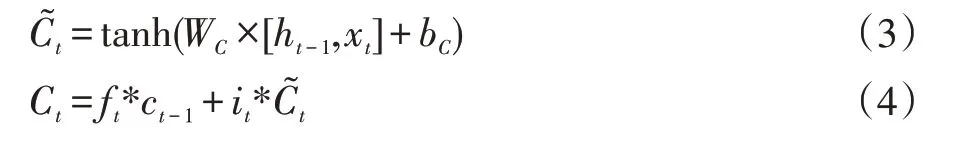
LSTM 中输出门表达式:


表1 LSTM 符号说明
2 深层注意力残差BiLSTM-CNN模型
2.1 BiLSTM模型
作为传统的序列模型,LSTM 通常只在一个方向上读取文本。图3 表示从后往前读取文本的后向LSTM模型。

图1 LSTM模型
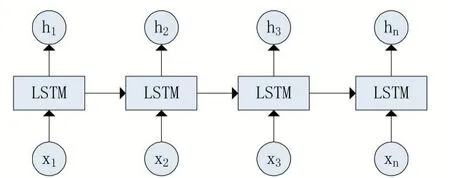
图2 模型
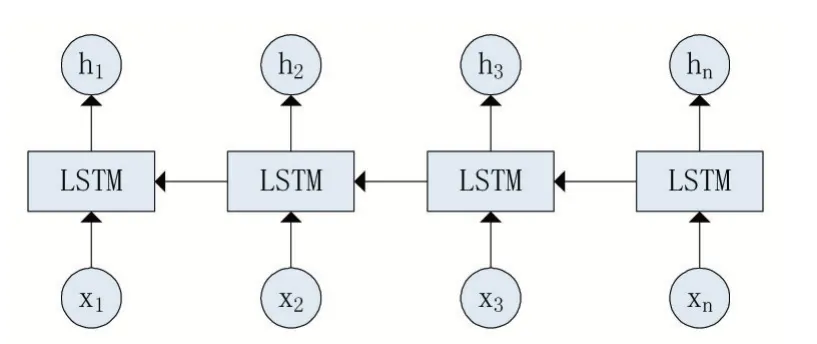
图3 模型
由于自然语言具有结构依赖性,依靠实现文本分类将忽略单词的语境含义[15],即文本单词之间的关系是双向的。以从前往后读取文本的模型为例,对于读取的当前词而言,不仅仅之前读取的单词为其提供信息,之后的单词也为其提供信息。例如,我身体现在很难受,所以我打算__一天。只依据“难受”,可以推出我打算“请假”、“去医院”、“休息”等。但如果加上后面的“一天”,就排除了“去医院”,能选择的范围就变小了,类似“请假”、“休息”之类的被选择概率就会更大。因此,结合两种模型的双向信息流模型,双向LSTM(Bidirectional LSTM,BiLSTM),可以更好地表示文本特征[20]。BiLSTM 模型如图4 所示。
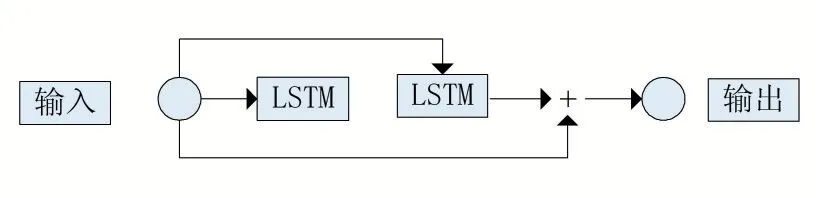
图4 BiLSTM模型
2.2 BiLSTM-CNN模型
虽然BiLSTM 模型可用于提取文本中文本的全局信息特征,但是无法获得文本的局部信息特征。并且文本向量的特征不能进一步高维特征表示。因此卷积神经网络和BiLSTM 模型进行融合。利用卷积神经网络对BiLSTM 模型获取的文本信息特征矩阵和文本的输入信息矩阵进行拼接得到新的特征矩阵,对其进行卷积获取文本信息特征的进一步抽取。解决了BiLSTM 无法获取文本的局部特征和单卷积神经网络(CNN)模型无法得到单词在上下文语义的问题。图5是BiLSTM-CNN 模型的结构图。

图5 CNN模块
在图5 中,xj(j=1,…,n)是文本中的第j 个单词的输入向量,其维度为K。和是第j 个单词的输入向量xj经过BiLSTM 模型得到的特征向量,其维度分别是和。在图5 中,将拼接后的向量作为该单词的特征向量,其维度为,作为BiLSTM-CNN 模型的输出。同时将其作为CNN 模块的输入向量,对其进行一维卷积。CNN 模块中的滤波器的数目为K。在图5 中,使用K 个大小为的滤波器,padding 形式为same,得到了K 个特征向量。当然,滤波器 的 大 小 可 以 为 其 他,例 如,等。
2.3 注意力残差BiLSTM-CNN模型
为了实现文本的深度挖掘,我们可以通过多层神经网络的结果对BiLSTM-CNN 模型进行分层并挖掘文本的深层特征[10]。但当神经网络参数过多时,会出现梯度消失和高层网络参数更新停滞等问题,并且基于BiLSTM-CNN 模型的堆叠得到的神经网络无法获取对文本分类结果产生影响的重点单词的特征。因此本文针对BiLSTM-CNN 模型堆叠所产生的上述两个问题提出了注意力残差双向LSTM(Deeply Attention Hierarchical BiLSTM-CNN ResNet,DAHBLCR)模型进行改进。在使用了LSTM 取代了传统的RNN 之后,反向传播中梯度消失的问题已不存在。但是,随着网络模型堆叠的层数过深,无法解决网络的退化问题。引入残差连接之后,可以解决网络模型过深时,每个层只有少量的隐藏单元对不同的输入改变它们的激活值,而大部分隐藏单元对不同的输入都是相同的反应。可以帮助训练更深层次的神经网络。注意力机制会决定每个特征向量对分类结果的贡献。例如,中国成功研发出一战略合金,或将促进量产超音速导弹。“导弹”对于军事新闻来说属于重点单词,而其他单词为非重点单词。
图6 为DAHBLCR 模型结构图,在整个堆叠的深度神经网络模型中,每一层由BiLSTM-CNN、ResNet 和Attention 三个模块组成。Attention 模块如图7 所示。
为了解决挖掘文本的深层特征信息,网络层数而导致的梯度消失以及高层网络中的特征很难有效的传递,而引入残差网络连接。如图6 所示,在ResNeti模块中输入是xi-1和ci,输出为
对于深度神经网络中第i 层中的BiLSTM-CNNi模块来说,残差网络在模块中的作用可以表示为:


图6 Deeply Attention Hierarchical BiLSTM-CNN ResNet(DAHBLCR)模型
为了获取对分类结果产生影响的重点单词的特征,在深度神经网络第i 层中加入Attentioni模块,如图7 所示。在Attentioni模块中,输入是,输出是。其中xi也是深度神经网络模型中第i+1 层的输入。在Attentioni模块中,注意力模型在模块中的作用通过MLPi结构表现出来。具体表示为:

式中,Wi为第i 层获取的第j 个单词的特征向量经过一个神经网络获取其隐层表示向量的状态转移参数矩阵,bi和对应的偏置项。vi为随机初始化的权值向量,用于对第j 个单词的隐层表示向量进行Softmax 标准化的参数向量。为第i 层获中的第j 个单词的权重。Wi,bi,vi的更新由模型训练时最小化损失函数反向传播所获得。

图7 Attentioni 模块
2.4 文本分类模型
在文本分类训练和测试中,本文将上面提出的DHABLCR 引入到文本分类模型中。如图8 所示。

图8 文本分类模型
对于训练中的文本矩阵w={w1,w2,w3,…,wn}由n的单词组成,并且每个单词是由分词之后的词向量经过Word2Vec 获得的128 维的词向量。整个深度神经网络(DHABLCR)模型的层数为m,最终的输出为,其中Max Pooling 层对输入的序列xm中的第j 个单词的输入特征向量选择最高值作为第j 个单词的显著特征,将上述n 个显著特征拼接成一个n 维的向量,作为文本的显著特征向量。最后,经过一个Softmax 层进行分类。
3 实验分析
3.1 实验数据
为了验证模型的有效性与泛化能力,使用的数据集如下:
数据集1:20Newsgroups 数据集,该数据集的新闻主题个数为20 个,新闻文档的个数为20000 左右。
数据集2:复旦大学收集的开源数据集。其中类别数为20,本文从中选取了40000 条数据。
数据3:IDMB,一个大型的电影评论数据集,其中共有50000 条电影评论,每条评论含有积极和消极两个情感标签。
并将上述3 份数据集,每份数据集划分为训练集和测试集,大小比例为7:3。
3.2 实验参数
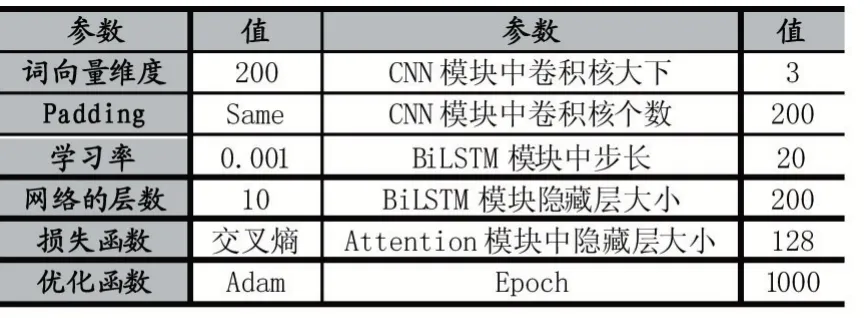
表2 模型的参数
3.3 分词
对于本文实验中的中文数据,采用的是Jieba 工具包对原始文本数据进行分词,英文数据直接使用空格进行切分。
3.4 词向量处理
将3.2 得到的分词,经过预训练好的Word2Vec 模型,将每个词映射成200 维的词向量。
3.5 实验环境和工具
实验环境:Ubuntu 16.04 操作系统,CPU 为i7 6800K,显卡为GTX 1080ti,内存为16G Kingston 骇客神条DDR4 3000,以及SSD 硬盘为512G 浦科特M7VC SATA3 固态。
开发工具为:主要为TensorFlow,其他的为numpy、pandas、scipy、scikit-learn。
3.6 实验结果与分析
本文比较了文本分类与其他文献方法的准确性。
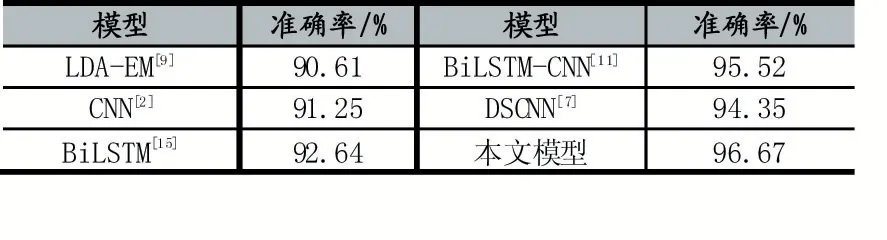
表3 20 Newsgroups 数据集

表4 复旦大学数据集

表5 IDMB 数据集
由表3-5 可知,基于上述所用的数据集,本文提出的模型不仅与基准模型相比,如CNN、BiLSTM、CLSTM 和Attention Based LSTM,还与传统的机器学习算法进行对比,如SVM 和LDA。实验结果表明,本文提出的模型在与其他模型对比中提高了文本分类的准确率,具有更优越的性能。
4 结语
本文提出一种基于卷积神经网络和BiLSTM 网络的深度文本表示模型,并将其用于新闻分类任务中。该模型既能够利用BiLSTM 双向读取文本的全局特征,又可以利用卷积神经网络获取文本的局部特征。同时引入注意力机制使得能够获取文本中重点单词的特征,同时引入残差网络,使得本文提出的网络模型在堆叠多层是不会出现梯度消失以及高层网络中的参数更新停滞。实验结果证明了本文提出的模型在文本分类中远优于传统机器学习模型、单CNN 模型和单BiLSTM 等基准模型。
未来研究的重点是网络模型层数与文本分类准确度的关系,以及模型在小数据量的微博话题分类上的应用。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
九江学院学报(自然科学版)(2022年2期)2022-07-02
新高考·高一数学(2022年3期)2022-04-28
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
电子制作(2019年24期)2019-02-23
西部资源(2018年1期)2018-11-01
