
基于用户协同过滤算法的E-Learning 平台个性化推荐研究
2019-07-25 08:03耿晓利邓添文罗桦锋许佳惠
现代计算机 2019年17期
耿晓利,邓添文,罗桦锋,许佳惠
(广州大学华软软件学院网络技术系,广州510990)
0 引言
2012 年,一种基于网络、针对大众人群的大规模开放在线课程(Massive Open Online Courses,MOOC)出现并发展很快,在线学习(E-Learning)成为一种深受欢迎的学习方式。在线学习平台将教学者和学习者的行为完整记录,产生了大量连续的教学互动信息。而深入挖掘这些数据,研究学习者的学习行为和学习心理,可以反映出学习者的学习状况,有利于提高学习者学习效果和学习质量,同时有利于向学习者针对性推荐课程,满足个性化需求。
目前的E-Learning 技术大多是均质化的,忽略了E-Learning 平台用户之间的差异,无法满足用户对学习的个性化需求,致使大量的时间都花费在课程的查找中。而丰富的、多样化的学习资源也容易让E-Learning 平台的用户产生认知超载和迷茫的现象。根据用户特点为其提供课程推荐服务,帮助用户快速地发现有价值的学习资源,能快速提高E-Learning 效率,同时帮助用户快速构建专业知识体系。
1 E-Learning研究现状
国外研究者很早就开始重视网络学习领域的个性化推荐。Chu 等人[1]基于Apriori 算法设计出一个基于Web 的课程推荐系统,为面临选课的学习者提供建议。Aher 等人[2]在K-means 算法聚类的基础上,应用Apriori 算法对各类学生的课程学习记录进行关联规则分析,得到各类学生偏好的课程学习顺序,从而向学生推荐合适的课程。
我国对网络学习中进行个性化推荐的研究起步较晚,学习者的体验程度不高。柴艳妹等人[3]对2008 年到2016 年中有关基于数据挖掘技术的E-Learning 行为的文献进行综述,指出大多数研究者主要研究热点是学习者对E-Learning 平台的接受程度,而把数据挖掘应用到E-Learning 平台的研究较少。孙歆等人[4]引入用户行为权重问题解决了冷启动问题。王琳琳[5]利用Web 日志挖掘和系统操作信息收集结合的方式,建立学习者兴趣模型,将用户聚类加入到推荐算法中,实现个性化资源的推荐。谢修娟等人[6]基于协同过滤技术设计并实现了一个个性化推荐系统。
伴随着E-Learning 平台资源的海量增加,ELearning 平台传统的课程学习、作业管理、成绩查询的功能己经不能满足学习者需求,个性化资源推荐可以帮助学习者更好地循序渐进学习、自我管理,提高个性化资源推荐为核心的服务将越来越紧迫。
2 基于用户的协同过滤个性化课程推荐的实现
协同过滤推荐算法主要有三种:基于项目的推荐、基于用户的推荐、项目和用户结合的推荐。基于用户的协同过滤算法能够共享其他用户的经验,避免推荐内容的片面化,也可以发现用户的潜在兴趣,并针对各个用户产生个性化的推荐结果。
结合所收集到的数据特点及学生用户在专业方向的相似性,本文拟将基于用户的推荐算法应用到E-Learning 平台中,为学习者实现个性化的课程推荐,帮助其更好地循序渐进学习课程,快速建立自己的知识体系。
2.1 算法基本原理
针对选取的E-Learning 平台的数据特点,本文采用基于用户的协同过滤推荐技术。通过用户的历史行为数据发现用户对课程或内容的喜欢,并对这些喜好进行度量和打分。根据不同用户对相同课程或内容的态度和偏好程度计算用户之间的关系。在有相同喜好的用户间进行课程推荐。算法的基本原理如图1所示。

图1 基于用户的协同过滤基本原理
图1 中,如果用户1 和用户3 用户同时选修了课程2 和课程3 两门课程,并且课程评分均为5 分,则可以认为用户1 和用户3 属于同一类用户。可以将用户1 学习过的课程1 和课程4 也推荐给用户3。
本算法的流程图如图2 所示。

图2 算法流程图
2.2 数据处理
本文实验所搜集的数据源为笔者所在学校的学生在E-Learning 平台的学习数据,包括课程数据、选课数据、成绩数据及课程评论数据等。其中用户数据包括学号、姓名、出生日期、年级、专业方向、学历、兴趣特长、手机号、宿舍等信息;课程数据有课程名称、课程简介、相关视频及文档资料信息;用户学习课程数据包括考试成绩数据及用户对课程的评论数据。
本文对收集到的原始数据进行处理,将用户的学号、姓名、手机号等敏感信息脱敏处理,部分用户数据如表1 所示。

表1 用户数据
对课程的代码信息进行删除处理,对课程简介信息删减,展示主要内容,部分课程数据如表2 所示。
表2 课程概要表
用户学习课程后产生了成绩数据和评论数据。成绩数据能反映学生学习课程的效果,成绩的高低一定程度上能反映学生对课程的兴趣程度。学生对课程的评论数据里,有对课程的评论,也有对授课教师的评论,反映课程的兴趣度相对较为狭隘。本文认为,用户参与课程学习获取的测试成绩越高,说明对此课程的学习效果越好,用户对课程的兴趣程度越高,对课程的评分也越高。
本次实验主要对用户的成绩数据进行转换,最终生成评分表,如表3 所示。

表3 用户评分数据
2.3 算法实现
本文实现的基本思路为:首先分析数据,建立用户-课程评分矩阵模型,接着通过计算用户对课程评分之间的相似性,寻找目标用户的最近邻居,最后根据最近邻居的评分向目标用户产生推荐课程。
(1)建立“用户-课程”评分矩阵
根据用户对课程学习后的测试成绩作为评分数据,建立用户-课程评分矩阵,如表4 所示。用户-课程评分矩阵是一个mÍn 矩阵,m 表示用户数,n 表示课程数,m[i]n[j]表示第i 个用户对第j 门课程的评分。

表4 用户-课程评分矩阵
(2)计算相似度
设N(i)为用户i 评分的课程集合,N(j)为用户j 评分的课程集合,那么i 和j 的相似度Wij值如公式(1)所示。

本文采用修正的余弦相似性方法,通过减去用户对课程的平均评分来修正不同用户的评分尺度问题。
设用户i 和用户j 共同评分的课程集合用Nij表示,则用户i 和用户j 之间的相似度值Wij如公式(2)所示。

其中,Si,m、Sj,m分别表示用户i、用户j 对课程m 的评分,分别表示用户i、用户j 对课程评分的平均分。
(3)产生推荐列表
从矩阵中找到与目标用户最相似的K 个用户,用集合S(u,K)表示,将S 中用户感兴趣的课程提取出来,并去除u 已经兴趣或已学过的课程,对每门候选课程i,用户对它的感兴趣的程度用以下公式计算:

其中Rvi表示用户v 对课程i 的兴趣程度。
3 实验结果分析
本文使用准确率来验证推荐的质量。推荐的准确率计算公式为:

其中test 表示测试数据集中的课程数量,topN表示系统推荐给用户的N 个课程。
本文选取实验数据主要为学院理工科部分学生,共获取369 个用户数据、549 门课程数据及16721 条评分数据。实验结果如图3 所示。
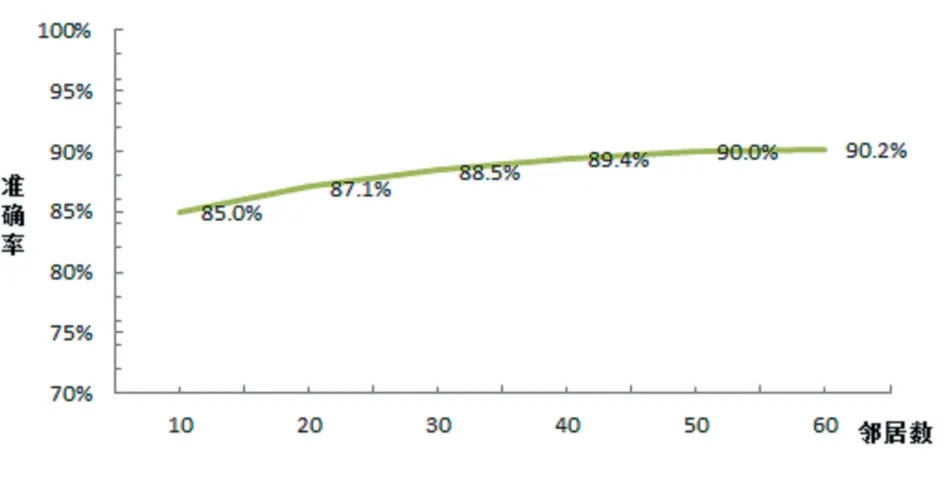
图3 算法的准确率
由图3 可知,随着邻居数量K 值的变化,准确率也在变化。在一定范围内,邻居数量K 值越大,推荐的准确率越高。本实验中,邻居数量K 值在50 时,准确率趋于平稳。
对于新来的用户,其没有选课记录,无法找到最近邻居。本文从用户的专业方向和兴趣爱好出发,把高年级学生兴趣的课程推荐给该用户,以此来解决冷启动问题。
4 结语
本文实现了基于用户的协同过滤算法在E-Learning 平台的个性化推荐课程。但由于其服务的用户局限于学生,算法考虑的因素较少,有一定的局限性。在下一步的研究中,把以下因素纳入考虑:用户修读课程的轨迹线、课程之间的序列关系、课程之间的相似性等,同时结合用户的评论文本数据。在推荐效果上评价指标也不单看准确率,还有MAE 值等。根据用户的兴趣实现更为精确的个性化推荐的同时,从用户的角度出发给用户提出相对应的发展路线,是进一步的研究方向。
猜你喜欢
电脑知识与技术(2022年11期)2022-05-31
成都信息工程大学学报(2021年3期)2021-11-22
皮肤病与性病(2021年3期)2021-07-30
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
学生天地(2020年15期)2020-08-25
文苑(2020年4期)2020-05-30
意林·少年版(2020年2期)2020-02-18
