
基于稀疏表示的人脸人耳融合识别算法∗
2019-07-31 09:54郑秋梅马茂东王风华孙燕翔
计算机与数字工程 2019年7期
郑秋梅 马茂东 王风华 孙燕翔 李 波
(中国石油大学(华东)计算机与通信工程学院 青岛 266580)
1 引言
随着人们对信息安全问题的日益关注,生物识别技术已经成为保护信息安全的重要技术之一。目前,单模生物特征识别在防盗系统、移动支付、金融服务等领域已取得广泛应用,但单模生物识别技术在噪声干扰、识别率等方面有明显不足。多模生物特征融合识别技术具有系统可靠性更高、适用性范围更广、安全性更强等优点,近年来备受青睐。Brunelli 于1995 年提出了利用多生物特征融合实现身份识别的策略[1],将人脸和声音两种形式的生物特征实现了在匹配层上的融合识别,获得了良好的识别结果,其思想为以后多模生物识别的研究开辟了道路,此后越来越多的研究人员开始探索多模生物识别[2~3]。选择融合的生物类别也是一种关键,本文采用易于实现同步采集、采集方式具有非接触性、非侵犯性和易接受性的人脸和人耳生物特征进行多模融合识别的研究。实验证明,相较于人脸与人耳单模生物识别,识别效率得到明显的提高。
近几年较为常见的人脸人耳融合识别算法,主要为主成分分析算法(PCA)[4]、典型相关分析算法(CCA)[5]、核典型相关分析算法(KCCA)[6]等,这些算法在图像光照变化、表情变化、拍摄角度变化等方面鲁棒性不强,而基于稀疏表示的分类算法[7~8]能有效利用子空间的特性,在光照、表情变化复杂的环境下,具有更好的识别效果。所以本文将稀疏表示理论引入到人脸人耳融合识别中,提出了基于稀疏表示的人脸人耳融合识别算法。实验证明,相较于其他人脸人耳识别算法,基于稀疏表示的人脸人耳融合识别算法鲁棒性更强,识别率更高。
2 基于稀疏表示的分类算法
基于稀疏表示的分类算法,简称SRC(sparse representation based classification),被广泛应用于模式识别中。其工作原理为,将测试图像样本用所有类别的训练样本线性表示出,而测试图像样本所属的训练图像样本可以表示的更为稀疏,也就是说用最少的训练图像样本达到更好的重构。在对稀疏表示系数进行约束后,进行稀疏表示求解,得到的非0 系数所对应的项为测试图像样本所属的训练图像样本所对应的项。这样,可以根据各类训练样本所取得对测试样本的重构误差来进行分类,其中重构误差最小的,即为最佳分类。本文通过求解速度更快的正交匹配算法进行稀疏求解,其基本数模模型如下所示。
设A 是由训练样本特征向量构成的字典集,y为测试样本的特征向量,n 为字典A 的向量总数。残差向量r0=y,匹配索引集V=φ,迭代次数i=1。
1)在字典集A 中寻求与残差向量r0最匹配的原子:vni=argri-1,vj。
2)更新匹配索引集:Vi=[Vi-1,vni]。
3)通过最小二乘法求得残差向量在正交化处理后的原子集上的最佳投影,更新匹配的系数值x˜:x˜=arg min||y-Vix||1。
4)更新残差向量:ri=y-Vix˜。
5)i=i+1,判断 ||ri||2<θ ,其中 θ 为最大残差阈值,如果满足条件则停止迭代,输出匹配系数集合x˜,否则跳到第2)步继续循环执行。
3 基于稀疏表示的人脸人耳融合识别算法(MSRC)
3.1 算法整体流程
本文首先对人脸人耳特征进行特征提取,采用能有效降低计算复杂度的PCA提取算法。其次,开始对人脸人耳特征进行特征融合。考虑到不同模态生物特征对最终识别的贡献可能有所不同,故人脸人耳融合算法采用加权串联融合法。本文采用迭代速度比较快的正交匹配追踪算法来对测试样本在训练样本中稀疏表示系数进行求解。最后,通过最小残差法来进行分类识别。通过实验证明,本文提出的算法具有较好的识别性能。本文算法的实现流程图如图1所示。
3.2 特征提取
基于稀疏表示的分类识别算法(SRC),它的计算量比较大。为了有效降低计算复杂度,本文采用主成分分析PCA[9~10]来对人脸人耳进行特征提取。
PCA 算法的基本思想是由训练样本中较大特征值所对应的特征向量来构造一个投影观测矩阵P,特征向量即为原样本向量在这个投影观测矩阵上的投影向量。对于任意的一个样本向量x,特征向量z 可由投影观测矩阵P 对向量 x 进行投影得到,即 z=PTx。
设人脸和人耳的测试对象共有c 个类别,每个类中分别有m 个人脸测试样本和m 个人耳测试样本。人脸训练样本和人耳训练样本分别用Af=[,,…,]和Ae=[,,…,]表示,其中 Ai=[ai,1,ai,2,…,ai,m](i=1,2,…,c) 代表第 i 个类别对象的m个测试样本。然后,人脸训练样本的特征向量和人耳训练样本的特征向量可由Df=(Pf)TAf,De=(Pe)TAe计算得到,其中,Pf为人脸训练样本通过PCA 算法得到的人脸投影观测矩阵,Pe为人耳训练样本通过PCA 算法得到的人耳投影观测矩阵,Df为人脸训练样本的特征矩阵,De为人耳训练样本的特征矩阵。人脸人耳测试样本对应的特征向量可通过 zf=(Pf)Tyf,ze=(Pe)Tye计算得到,其中 yf,ye分别表示人脸、人耳的测试样本向量,zf,ze分别表示人脸、人耳测试样本的特征向量。
3.3 人脸人耳特征融合
特征级融合即能实现冗余信息的有效压缩,又能最大程度地利用不同模态生物特征的可区分性,故人脸人耳的特征融合层级选用特征级融合。特征融合的方法有以下几种:串联融合法[11]、并行融合法[12]和典型相关分析(CCA)[13]。串联融合法与后面两种方法相比,更简单高效,更容易扩展到超过两种模态的多模生物融合。因此,本文中采用串联融合法来进行特征融合。
考虑到人脸人耳特征信息对身份识别可能有不同的识别能力,所以本文在进行特征向量的串联融合时加入了权重系数,以此来充分利用人脸和人耳特征信息对身份识别的影响能力。
特征融合具体过程如下所示。
1)特征向量的归一化表示
为了能使人脸人耳的特征向量在身份识别中具有同等的表现力,所以本文在人脸和人耳特征向量融合之前,对这两种特征向量进行了归一化处理[14]。由上一节可知:Df,De分别为人脸训练样本的特征矩阵和人耳训练样本的特征矩阵,设为Df中第i 个类别中的第j 个样本的特征向量,下面本文对进行归一化处理,=(- μf)/σf,其中,μf为Df中所有列向量的均值向量,σf为Df中所有列向量的方差向量。经过归一化之后,所有人脸样本特征向量的均值为0,方差为1。同理,再用相同的方法对人耳训练样本的特征向量De进行归一化处理,=(-μe)/σe,其中为De中的列向量,μe为 De的所有列向量的均值向量,σe为De的所有列向量的方差向量。
2)特征向量加权串联融合
设D 为人脸和人耳测试样本的特征向量融合之后的特征矩阵,di,j为D 中第i 个类别中的第j 个样本融合后的特征向量,人脸人耳特征向量的加权融合方法如式(3)所示:
其中,α 和 β 要满足约束条件 α+β=1。
在具体实验中,为了充分利用不同模态的分类识别能力,权重系数可通训练获取,具体方法为:以0.1 为单位,将权重系数α 从0.1 开始逐步调整到0.9,对应的权重系数 β 在满足约束α+β=1的限制下也逐步进行调整,分别完成整个识别过程,其中对应最高识别率的权重系数即为最佳权重系数。
3.4 稀疏表示稀疏求解
因为正交匹配追踪算法[15~16]相较于基追踪和匹配追踪等算法,收敛速度更快、对目标向量的分解更为稀疏,所以本文采用正交匹配追中算法来对稀疏表示系数进行求解。
人脸和人耳特征融合后的训练样本矩阵为D,测试样本对应的人脸和人耳特征融合后的向量为z,由正交匹配追踪算法可求得测试向量z在训练样本构成的字典矩阵D 上的稀疏表示系数x ,x 为n(n=c×m)维空间中的向量,稀疏表示系数x 要满足如下条件||Dx-z|≤φ ,其中,φ 为迭代阈值范围。
3.5 分类识别
在基于稀疏表示的分类算法的文献中,大多数文献通过最小残差法[17]来得的最终的识别结果。所以本文亦采用比较普及的最小残差法来进行分类识别。
其基本思想为:通过训练样本在某一类别上的线性组合来重构测试样本,其线性组合系数为测试样本在训练样本矩阵对应类别上的稀疏表示系数,重构样本与测试样本残差最小的类别即为测试样本所在的类别。
设 xi,(i=1,2,…,m)∊Rn为稀疏表示系数 x 中第i 个类别所对应的系数,其余类别所对应的系数为0,所以通过稀疏表示系数xi可得到由第i 类别训练样本重构的测试样本,=Dxi,其中 zˆi为第 i类别训练样本重构的测试样本向量。第i类别训练样本的重构残差为ri=||ˆ-z|,其中重构残差最小的类别即为测试样本所在的类别,因此可以判定测试样本z所在的类别为identity(z)=
4 实验结果分析
4.1 实验人脸和人耳数据库介绍
实验用的人脸数据库为ORL 人脸库,ORL 人脸库中一共有40 个人的人脸图像,其中每个人的人脸图像包含10 张不同的人脸图像,数据库中所有的人脸图像为400 张。ORL 人脸库中的每个类别对象具有丰富的拍摄角度变化、拍摄时间变化、人脸表情变化(主要包含闭眼、睁眼、微笑、吃惊、生气、愤怒、高兴)及不同的脸部细节(主要有戴眼镜、不戴眼镜、发型不同、有胡子、没胡子),这些变化主要包含拍摄时间变化,图2展示了ORL人脸数据库中部分类别的人脸图像。
图2 ORL人脸数据库中的图像示意图
实验用的人耳数据库为自己拍摄制作的人耳数据库,人耳数据库总共采集30 个人的人耳图像,其中每个人包含11 张不同的人耳图像,人耳数据库中所有的人耳图像为330 张。因为人耳的生物特征具有刚性特点,人耳图像不会因表情或姿态变化而有所不同,故拍摄的人耳库主要包含光照和拍摄角度变化,其中拍摄角度主要包含正面、左面、右面、上面和下面,其角度变化在5°~10°范围内。下面图3展示了课题组人耳库中部分类别的人耳图像。

图3 人耳数据库中的图像示意图
在实验中,取ORL 人脸库中的前30 个类别的人脸图像与人耳库中的30 个类别的人耳图像进行搭配实验,其中,每个类别的人脸和人耳图像各选取10张进行实验。
4.2 实验结果分析
为了确定最佳的人脸人耳特征融合权重系数α,β ,本文进行了实验一来求取最佳权重系数α,β ,其中,本文采用的基于稀疏表示的人脸人耳融合识别算法(MS β=1-α RC),将权重系数 α 从0.1 开始以0.1 为步长逐步调整到0.9,统计每次权重系数对应的识别率,统计结果如图4所示。
从图4 中可以看出,当权重系数α 为0.3 时,对应的权重系数β 为0.7,此时的识别率最大,为最佳权重系数。从上述实验可以看出,人耳特征对最终识别结果的影响更大,原因在于本文实验用的人脸数据库相较于人耳数据库在光照、表情和姿态变化上更加丰富。
为了比较多模融合算法和单模算法的识别性能,进行了实验,分别比较了人脸识别、人耳识别与人脸人耳融合识别的识别性能。实验中将人脸和人耳数据库中每个类别的7副图像用做训练样本,其余3副用做测试样本。识别结果如表1所示。
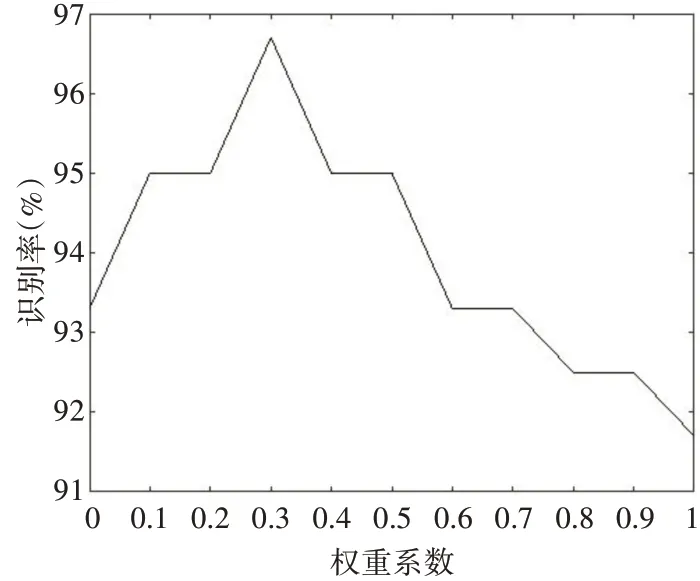
图4 权重系数α 对应的识别率

表1 不同模式类别的识别率比较
从表1 中可以看出,人脸人耳融合识别的识别率要高于人脸和人耳单模生物识别的识别率,这说明了多模生物识别技术比单模生物识别技术在识别性能上表现更优。
为了将本文提出的基于稀疏表示的人脸人耳多模融合识别算法(MSRC)与其他人脸人耳融合算法在识别性能上进行比较。在实验中本文对比了近几年较为常见的人脸人耳融合识别算法,分别为主成分分析算法(PCA)、典型相关分析算法(CCA)、核典型相关分析算法(KCCA),各种算法的识别率统计结果如表2所示。

表2 各种多模融合算法识别率比较
从表2 中可以看出相比于其他人脸人耳融合识别算法,本文基于稀疏表示的人脸人耳识别融合算法(MSRC)的识别性能更好。因实验用的数据库包含丰富的光照、表情、姿态及拍摄角度变化,本文的MSRC 算法仍能取得比较满意的识别率,故MSRC算法对光照及表情变化等具有较强的鲁棒性。
5 结语
本文针对单模生物识别所存在的局限性,提出了人脸和人耳特征融合识别算法,通过实验证明,多模生物识别技术比单模生物识别技术在识别性能上更优,多模生物识别技术也成为未来生物识别技术的重要研究方向。本文将稀疏表示的方法应用于人脸及人耳特征的表达分类上,通过实验证明,相比于其他算法,基于稀疏表示的识别算法要更加优秀。
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02
保定学院学报(2022年2期)2022-04-07
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
科技创新与应用(2020年6期)2020-02-29
数学学习与研究(2018年15期)2018-11-12
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
奇闻怪事(2014年5期)2014-05-13
