
基于CUDA 并行化的K-Means 聚类算法优化∗
2019-07-31 09:54丁芙蓉张功萱
计算机与数字工程 2019年7期
丁芙蓉 张功萱
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
聚类分析是一个将数据集中在某些方面相似的数据成员进行分类组织的过程。一个聚类就是一些数据实例的集合,这个集合中的元素彼此相似,但它们都与其他聚类中的元素不同。K-Means是一种基于划分的聚类算法,它通过随机初始聚类中心,不断地迭代调整聚类中心,得到最终的聚类结果[1]。K-Means 算法执行简单,聚类效率高,目前已被广泛地应用于数据挖掘[2]、模式识别[3]、图像处理[4]、气象分析[5]等领域。
在大数据背景下,数据具有规模巨大,高速产生,形式多样的特点,针对大规模,高维数据,聚类在每次迭代过程中的计算量非常大,耗时严重[6]。在高性能计算领域,多核和众核芯片的普及,计算设备的计算能力不断提高,如何充分利用计算设备的计算能力来进行数据分析成为研究的热点[7]。GPU 上有几十个甚至上百个计算核心,采用GPU并行化K-Means 聚类算法相比于串行的K-Means算法,能达到 2~75x 的加速比[8],大大地降低了算法的运行时间。目前,在GPU 上进行K-Means 聚类优化多集中在初始聚类中心选择方面,文献[9]提出了初始多组聚类中心,迭代4 到5 次选择最佳聚类中心的方法,文献[10]提出了动态调整聚类中心的策略。上述方法在优化聚类中心的选择后,算法的准确率和性能得到了提升,但是在进行聚类的迭代计算过程时,使用CUDA 的同步计算模式,即将CPU 作为程序的控制端,GPU 作为加速部件,在GPU 进行加速计算时,作为主控端的CPU 陷入忙等状态,直到GPU 上的计算任务完成并返回。在多核普及的时代,这种方式大大浪费了主机端CPU的计算资源,因此本文提出了基于CPU/GPU 异步计算的优化方法,利用GPU 核函数和CPU 异步执行的特点,通过数据并行策略,将聚类过程进一步并行化,减少了CPU 忙等,加速了K-Means 聚类算法的执行。
2 相关算法与技术
2.1 K-Means聚类算法
设 样 本 数 据 集 为 D={xi|i=1,2,…n} ,C={ci|i=1,2,…k}表示聚类的k 个类别,其中ci是第i 个聚类的中心。用‖‖xi-cj表示从xi到第j个聚类中心的距离,定义d(x,C)2=K-Means 算法的目的就是找到一个包含k 个聚类中心的集合C ,使得误差最小。
K-Means聚类算法的步骤如下[11]:
1)随机选择k 个样本(c1,c2,…ck)作为初始聚类中心;
2)将样本数据集D 中各样本按照最近距离原则指派给k 个聚类中心;
4)判断是否满足收敛准则,不满足跳转至步骤2),否则算法收敛,中止算法。
2.2 CUDA程序设计模型
CUDA 是由NIVIDA 公司推出的一种利用GPU进行通用并行计算的整套解决方案,包括硬件支持、程序语言扩展、编译器、调试器等整套开发工具链。在CUDA 中,物理上的SM(Streaming Multiprocessor,流多处理器)和SP(Streaming Processor,流处理器)被映射为逻辑上的网格(grid)、块(block)和线程(thread),同一个线程块中的线程可以通过共享存储器实现数据共享,一个块中可以通过唯一的索引来控制块内的每个线程来完成并行计算[12]。一个典型的CUDA 应用由两部分组成:在主机CPU上执行的host 端程序,负责数据传输,初始化和启动GPU;完全在GPU 上执行的device 端程序(被成为kernal 函数)。host 端与device 端之间的数据传输通过 PCI Express 总线传输[13]。CUDA 程序员可以使用CUDA C,一种扩展C 语言的编程语言来实现kernal 函数。在调用kernal 函数时,会以多线程的方式在GPU上并行执行。
2.3 基于CUDA并行化的K-Means算法
由2.1 节可知,K-Means 聚类算法的迭代过程主要由样本指派和更新聚类中心两个阶段组成。第一阶段样本指派,通过计算各个样本到聚类中心的距离,将样本指派给距离最近的聚类中心,该阶段具备典型的数据并行的特点,各个样本的最小距离可以相互独立计算,适合于在GPU 上用多线程来加速计算,即将聚类空间中的每个样本点对应一个线程,负责该点的指派。聚类算法中计算量最大的一部分是样本指派,通过并行设计,可以提高算法的运行速度。对于更新聚类中心阶段,需要计算样本坐标累加和,计算新的聚类中心。若在GPU上用多线程来更新聚类中心,需要所有线程访问一个求和值,而GPU的block间缺少全局的同步性,计算累加和容易引起Bank 冲突。因此将数据传回主机端,将其在用于较大可读写cache 的CPU 上进行[14]。
基于CUDA 并行化的K-Means 聚类算法的伪代码如算法1[15]所示,首先初始化聚类中心,之后进行迭代计算。算法的主体包含一个循环,先将聚类中心拷贝到GPU上,然后在GPU上通过调用CUDA 的函数进行样本指派gpu_labeling(),样本指派完成后,将样本指派的结果通过cudaMemcpy()拷贝回CPU,此时的数据拷贝是同步的,只有第4 行GPU 上的kernal 函数执行完毕才开始数据拷贝。样本指派的结果拷贝完成后,在CPU上进行聚类更新updateCentroids()。通过定义偏差率φ 来表示先后迭代中聚类中心发生变化的比例占全部样本的比例,并针对偏差率定义阈值φ0,表示算法终止的条件。
算法1:基于CUDA的并行K-Means聚类算法
1)init(D,C)//D 表示聚类的输入数据集,C 表示聚类中心
2)while φ > φ0do
3) cudaMemcpy(…)
4) gpu_labeling<< <…> >>(D ,C)
5) cudaMemcpy(…)
6) updateCentroids(D ,C)
7) compute φ
8)end while
3 基于CPU/GPU异步计算的并行化
3.1 算法存在问题
经典的基于CUDA 并行化的K-Means 算法的执行过程如图1。S1 表示迭代的第一阶段,样本指派gpu_labeling();S2 表示迭代的第二阶段,更新聚类中心点updateCentriods()。 D 表示输入的数据集,图中的箭头表示各个执行阶段间的数据依赖关系。执行时,必须满足箭头标示的顺序一致性。
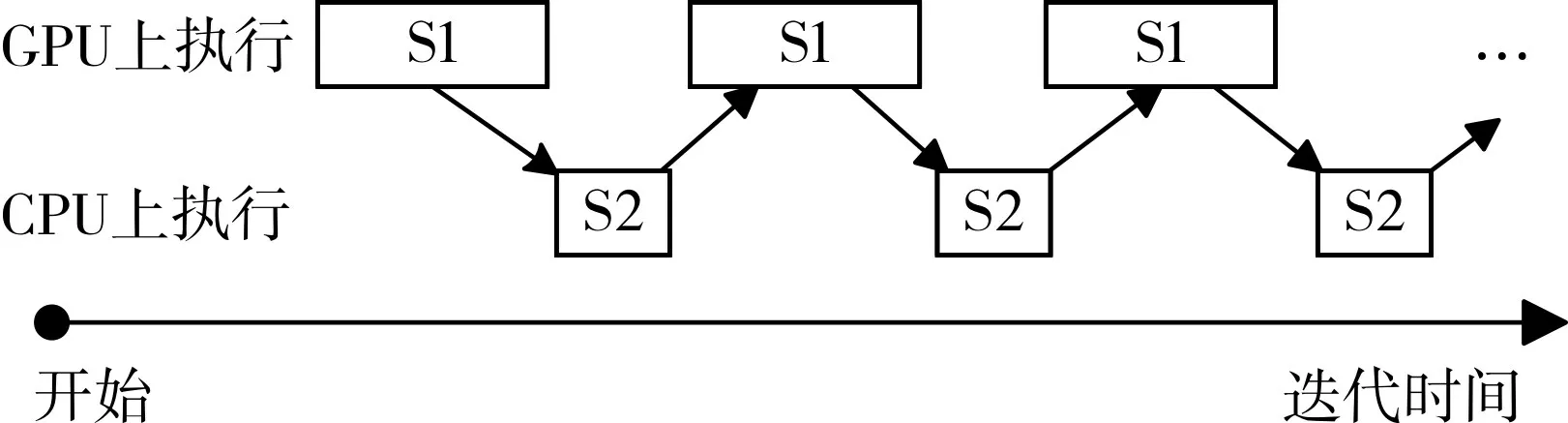
图1 基于CUDA的并行K-Means执行过程
在理论上,对于数据规模为n,样本维度为d ,聚类划分个数为k 的K-Means聚类过程,样本指派的运行时间是O(n×k×d),而更新聚类中心的运行时间是O((n+k)×d)。采用CUDA 并行化后,样本指派的运行时间是,其中 p 为计算单元的数量,与GPU 的性能有关。此时,样本指派/更新聚类中心的比率等于n ≫k 。随着聚类划分个数k 的增加,样本指派/更新聚类中心的比率会变大,即S1/S2 的比值增大。大部分时间在GPU 上进行计算,CPU 处于忙等状态,浪费了CPU 的计算资源。随着多核CPU 的普及,原有的并行模式不能充分利用CPU端的计算能力,浪费了CPU 的计算资源。本文利用GPU/CPU异步执行的特点,提出数据并行策略,将聚类数据集分配到 CPU 和 GPU 上,增加了 CPU 和 GPU 的数据通量,对传统的并行算法做优化,提高了聚类的效率。
3.2 数据并行优化策略
由3.1节分析可知,当k 增大时,算法的主要时间开销在样本指派阶段,即GPU 上执行的计算任务,此时CPU 处于忙等状态,浪费了多核CPU 的计算资源。样本指派的时间复杂度为通过减小在GPU 上的聚类数据量,可以减小样本指派阶段的执行时间。因此,将聚类数据集进行划分,一部分数据在GPU 上进行样本指派,另一部分数据在CPU 上进行样本指派,通过数据并行的方式,GPU 上的运算和CPU 上的运算同时进行。通过GPU 和CPU 的计算重叠,减小算法的执行时间。利用数据并行策略对CUDA 并行化的K-Means聚类算法进行优化,在提高CPU的利用率的同时提高了算法的执行效率。如图3 所示,数据集分成了g 和c 两个部分,在保证原来的数据依赖关系下,完成聚类。
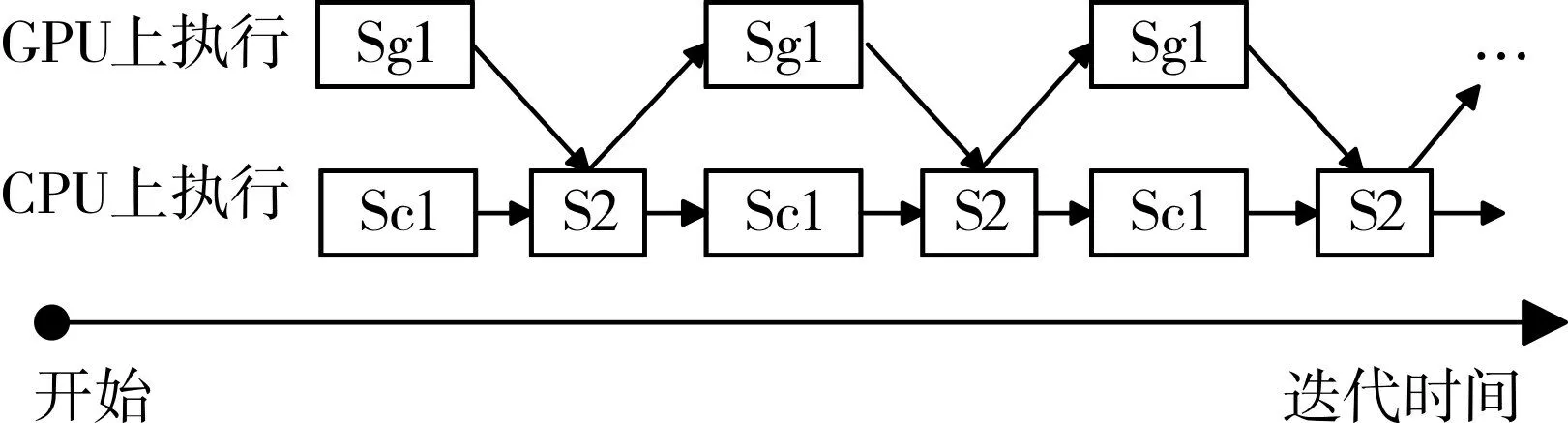
图2 数据并行优化的K-Means执行过程
基于数据并行策略的CUDA 并行化聚类方法,将输入数据集划分成两个部分,利用CPU 和GPU异步执行的特点,分别在CPU 和GPU 上完成迭代过程中的样本指派。然后再实现CPU 和GPU 的同步,在CPU 上合并两个部分样本指派的结果,重新计算聚类中心。
算法2 给出了基于数据并行策略的CUDA 并行化K-means 聚类的迭代过程。首先将数据集分成两个部分D1、D2,每次迭代调用GPU 核函数gpu_labeling()来对数据集 D1 完成样本指派,调用CPU 函数 cpu_labeling()来对数据集 D2 完成样本指派。由于GPU 和CPU 是异步执行的,这两部分的计算重叠。通过gpu_finish 和cpu_finish 变量来表示GPU 和CPU 上的样本指派是否完成,从而实现GPU和CPU的同步。然后再对数据集D 进行更新聚类中心updateCentroids()。
其中,GPU 和CPU 的异步执行以及同步操作,我们总结如下:
1)GPU 和 CPU 之间的数据传输使用 cudaMemcpyAsync 异步传输的方式,因此5-8 行代码的操作提交到GPU 后,控制权立即返回给host 端,此时第9 行代码开始执行。通过这种方式,实现了GPU 和CPU的异步执行。
2)GPU上的样本指派完成后,插入一个流事件gpu_finish。调用cudaEventQuery 函数,通过监听gpu_finish 来判断GPU 上的样本指派是否完成。CPU上样本指派完成后,将cpu_finish置为1。通过gpu_finish 和 cpu_finish 来 实 现 GPU 和 CPU 样本指派完成后的同步。
3)当更新聚类中心updateCentroids()完成后,要置cpu_finish为0,进行复位。
算法2:数据并行策略优化的算法
1.Init(D,C)//D 表示聚类的输入数据集,C 表示聚类中心
2.cpu_finish=0
3.cudaEvent_t gpu_finish
4.while φ > φ0do
5. cudaMemcpyAsync(…)
6. gpu_labeling<< <……>> >(D1,C)
7. cudaMemcpyAsync(…)
8. cudaEventRecord(gpu_finish)
9. while(cudaEventQuery(gpu_finish)== cudaError-NotReady)do
10. if(cpu_finish)
11. continue
12. cpu_labeling( D2,C)
13. cpu_finish=1
14. end while
15. updateCentroids(D ,C)
16. cpu_finish=0
17. compute φ
18.end while
4 实验与分析
有很多文献在GPU 上加速K-Means 算法,算法的执行流程如算法1。因此本文的对比算法为算法1,实验的主要目的是分析算法的执行时间和加速比。由于相同初始条件下,K-Means算法最终的聚类迭代次数相同,在进行实验时,确保算法1和算法2的初始聚类中心相同。
4.1 实验环境
为了验证算法的有效性,依据本文提出的数据并行优化策略,利用CUDA C 语言,在GPU 上实现了算法1 和算法2。实验平台为配有两个Intel Xeon E5-2620 2.10GHz CPU,NIVIDIA Tesla C2050 GPU的服务器,采用64位Windows server 2012操作系统。主机端的英特尔至强处理器每个处理器有8 个物理核心,支持超线程技术,在主机端每次可以最多可以支持32 个线程。NVIDIA Tesla C2050计算卡拥有448 个频率为1.15GHz 的CUDA 核心,3 GB GDDR5 专用存储器,存储器接口384 位,存储器带宽144GB/s,通过PCIe×16 Gen2 接口与主机相连。
4.2 真实数据集测试
使用UCI 上的真实数据集Spambase 进行聚类测试[16]。该数据集具有4601 个数据样本,每个样本具有57 个维度。实验中聚类的划分个数k 分别为10、20 和50,进行三组实验,每组实验算法各运行10 次,统计聚类过程中样本指派/更新聚类中心的耗时比值S1/S2 平均值、聚类迭代过程的平均耗时和优化后的算法的加速比。
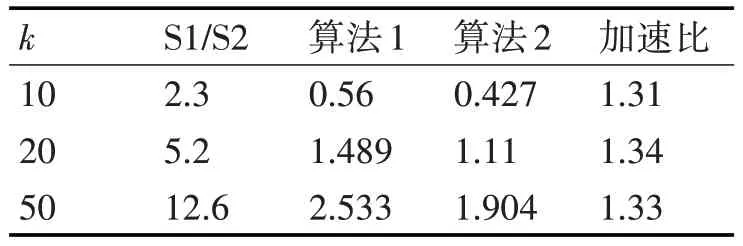
表1 Spambase数据集实验结果
由实验可以看出,随着k 的增加,S1/S2 的比值增大,即在GPU 上的计算耗时占比增大。利用数据并行策略,将聚类数据划分一部分到主控端CPU上,充分利用多核CPU 的计算能力,能够为算法加速。
4.3 人工生成数据集测试
为了评估文本提出的数据并行策略在样本维度增加和聚类划分个数增加时算法的性能,采用人工生成的数据集进行实验。实验数据集包括10、50 和100 维的100 000 个样本,所有的样本被指派到 10,50,100 个聚类中,一共进行 9 组对比试验。每组实验算法各运行10 次,统计聚类迭代过程的平均耗时作为评价指标。实验结果如图3。
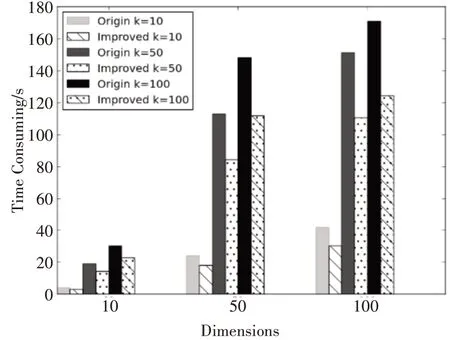
图3 运行时间对比
图4 显示了9 组对比试验,每组对比试验的加速比,即本文提出的数据并行的优化策略相对于传统的基于CUDA 并行化的K-Means 算法的加速比。本文的优化方法能获得31% ~38%的性能提升。从图4 中可以看出,随着数据维度和聚类划分个数的增加,加速比基本保持不变。
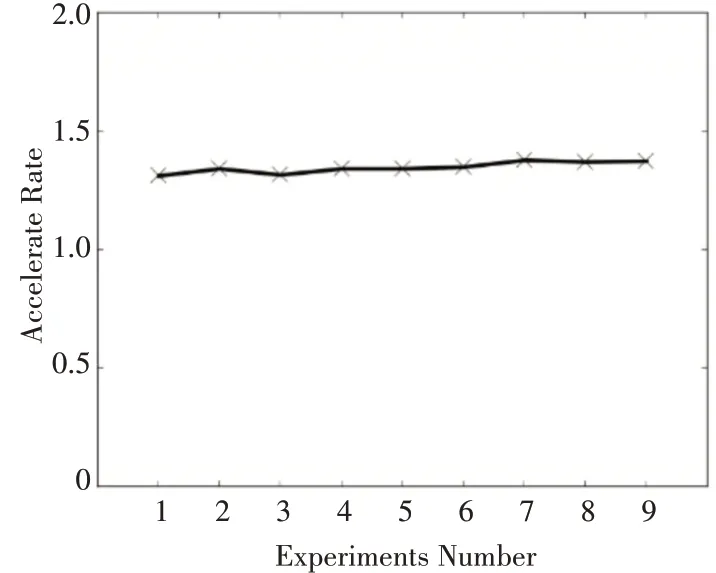
图4 加速比比较
5 结语
本文研究基于CUDA 并行化的K-Means 聚类算法在CPU 和GPU 上的执行特征,指出了聚类划分个数对聚类在GPU 和CPU 上执行时间比值的影响,从而提出了数据并行策略,对原有的基于GPU并行化的K-Means 聚类算法进行优化,利用GPU核函数与CPU 异步执行的特征,通过将CPU 与GPU的计算重叠,减小了算法的执行时间。实验证明,优化的算法有很好的加速比。随着CPU性能的提升,多核CPU 的普及,CPU 和GPU 异构计算中,作为主机端的CPU计算性能不断提升,本文在研究加速计算时,在使用GPU 作为加速部件的同时,进一步挖掘了主机端CPU的计算能力,提高了算法的并行性。本文的下一步研究工作是深入研究CPU和CPU异步计算的模式,以提高其他聚类算法的并行化。
猜你喜欢
计算机应用与软件(2022年9期)2022-10-10
北京航空航天大学学报(2022年8期)2022-08-31
现代电子技术(2022年8期)2022-04-13
体育科技文献通报(2022年1期)2022-01-15
物流科技(2021年1期)2021-07-05
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
电脑知识与技术(2017年17期)2017-07-14
互联网天地(2016年1期)2016-05-04
西部学刊(2016年5期)2016-04-26
