
连续汉语语音切分技术研究∗
2019-07-31 09:54曹冠彬张二华王凯龙
计算机与数字工程 2019年7期
曹冠彬 张二华 王凯龙
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
汉字为单音节[1],语音切分技术就是将一段连续完整的语音,切分为一个个独立的音节。在连续语音识别系统中,不可能对整个短语进行训练和识别,因为词组或者短语的数量太大,必须将输入的语音流切分为更小的组成部分如单个字或词。
现有的连续语音自动切分技术虽然能实现对连续语音的切分,但大多存在稳定性差,易受噪声影响等缺点,例如基于时域参数或者频域参数的切分方法[2~6]存在稳定性差、易受环境噪声影响等缺点;基于模型的切分方法,如基于隐马尔可夫模型的切分方法[7~8]需要进行模型训练,训练时需要输入人工切分好的数据,不易实现自动切分。本文结合声学、语音学、语言学、信号处理和图像处理等知识,研究了汉语语音的多级切分方法,利用相干分析、多尺度分析和基音周期轨迹检测等技术实现了汉语连续语音切分。
2 语音切分技术基础
2.1 时域特征分析
对于语音信号x(m),短时能量的定义如下:

其中,En表示第n帧语音信号的短时能量,N代表每帧语音包含的采样点数。
短时平均过零率是指语音信号波形穿过时间轴的次数。为了减少随机信道噪声影响,将过零率修改为跨过正负门限T和-T的次数,如式(2)所示。

2.2 频域特征分析
2.2.1 语谱图
语谱图[9]反映语音的时频特性,语谱图的横轴表示时间(帧序号),纵轴表示语音信号的频率。语谱图中像素点颜色深表示该点的语音能量较强。语谱图的绘制步骤如下:
1)对语音信号进行预处理,再根据式(3)求快速傅里叶变换。
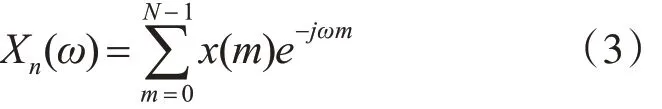
2)根据式(4)将Xn(ω)转换为振幅谱,R 表示Xn(ω)的实部,I表示Xn(ω)的虚部。

3)将振幅转换为灰度图像数据。振幅越大,像素点的灰度越深;反之越浅。
4)绘制语谱图,因为实数的振幅谱为偶函数,关于中心对称,所以绘制语谱图时只需在每一帧的起始点位置的垂直方向上绘出前一半的点即可。
2.2.2 绘制基音周期轨迹
发音过程中伴有声带振动的音称为浊音;不伴有声带振动的音称为清音。基音周期是指发浊音时声带振动频率的倒数。基音周期轨迹的绘制步骤如下。
1)对语音信号进行预处理,根据式(3)求其频谱,再求对数振幅谱lnH(ω)。再对对数振幅谱进行一次逆傅里叶变换得到倒谱,倒谱的计算公式如式(5):
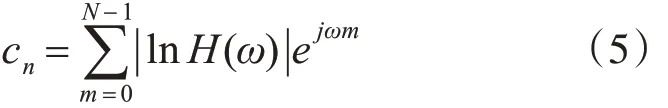
2)将倒谱数据从小到大排序,对前50%数据进行低截止置为1,对高位1%倒谱数据进行高截止置为0,取余下49%的数据的最小值h1和最大值h2,利用式(6)设置阈值T 将这49%的倒谱数据二值化,大于T置为0,小于等于T置为1。
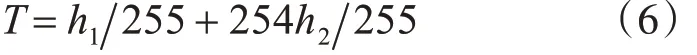
3)与语谱图类似,在每一帧的起始点位置的垂直方向上绘出前一半的点。
3 传统语音切分技术
3.1 双门限端点检测技术
双门限端点检测技术[10~12]的基本思想就是利用短时能量和短时平均过零率这两个时域特征参数对语音信号进行切分。先统计浊音部分的短时能量,设定一个较高的门限参数EH,使得语音信号的能量包络大部分都在此门限之上,根据背景噪声能量确定一个较低的阈值参数EL;再统计清音和无声段的短时平均过零率,确定短时平均过零率门限ZS。双门限端点检测技术的步骤如下:
1)对语音信号进行预处理,求语音信号的短时能量E和短时平均过零率Z。
2)寻找符合E>EH的语音段记为N1N2,N1、N2表示初判语音段的起始和终止位置。
3)从N1往左搜索,寻找E>EL的语音段,确定左侧的起始位置N3;同理确定右侧的终止位置N4。
4)从N3往左和N4往右搜索,找到Z>ZS的语音段,确定新的起始点N5和终止点N6,N5N6就是检测到的语音段。
3.2 基于倒谱的端点检测技术
基于倒谱的端点检测技术[13~14]就是利用语音信号倒谱中的最大波峰的倒谱值与次大波峰的倒谱值的比值确定语音信号是否为元音段。基于倒谱的端点检测算法的步骤如下:
1)对语音信号进行预处理。
2)通过短时傅里叶变换获得短时谱Xn(ω),对频谱的模取对数再求其傅里叶逆变换得到倒谱c(n)。
3)计算最大波峰倒谱值与次大波峰倒谱值的比值,确定该帧是否为元音段,本文的阈值设定为2.25。当比值大于等于设定的阈值时认为该帧为元音帧。
3.3 基于双门限和倒谱的综合端点检测技术
本文将双门限端点检测技术和基于倒谱的端点检测技术相结合,对连续汉语语音进行切分。具体步骤如下:
1)对语音信号进行双门限端点检测。
2)再用基于倒谱的端点检测技术对元音段进行检测。
3)从1)的结果中先选出一段有声段,寻找有声段的起始和结束帧之间是否含有元音段,元音段的结束位置可以作为切分依据。
从图1(a)可以看出对于含辅音的连续汉语音节,结合双门限和倒谱端点检测技术能实现准确的切分结果;但是对于不含明显辅音音节的连续汉语音节,该方法仍然不能实现准确的切分,如图1(b),“师恩难忘”被分成了“师”和“恩难忘”两个部分。
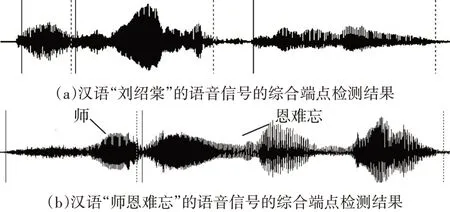
图1 基于双门限和倒谱的综合端点检测结果示例
4 汉语连续语音的多级切分算法
4.1 多级切分基础
4.1.1 相干分析
共振峰指的是声腔的共鸣频率,对相同音节的汉字,其共振峰较稳定或者缓慢变化,语谱图较相似。当语义发生变化时,汉字的共振峰也会发生变化,这种变化从语谱图上可以明显看出,例如从图2 可以看出相邻两个汉字的语谱图在界限处有明显的变化。在观察大量的语谱图后,发现在相邻两个不同语义的语音段之间,其语谱图在两个字的界限处会呈现明显的不相似。可以利用这种明显的不相似性来检测汉字音节的分界线。
相干分析法是计算数据相似性的一种方法。Gersztenkon[15]提出了一个基于协方差矩阵特征值的方法,具有抗噪能力强,分辨率高的优点。相干分析的步骤如下:
1)对于m×n维矩阵A,求其n维协方差矩阵B。2)求协方差矩阵B的特征值λ1、λ2…λn。
3)根据式(7)计算相干系数,k 值越大,表示数据越不相似。
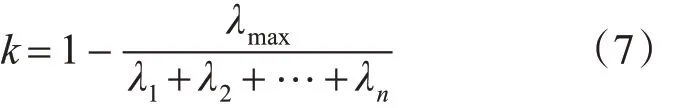
对语谱图进行相干分析的步骤如下:
1)绘制语音信号的语谱图,获取语谱图的灰度值矩阵。
2)获取语谱图的灰度值矩阵后选择m×n 大小的窗口进行相干分析,m 表示每一帧选择m 个频谱样点数据,n表示帧数。求该窗口数据的相干系数λ。
3)将窗口右移一帧,求当前窗口的相干系数。依次计算,直到窗口到达语谱图的最右端。
4)将(J-n+1)个相干系数中相邻的系数连接起来得到相干系数曲线。
从图2 可以看出在两个元音的分界处相干系数较高。在相邻字的语谱图的界限处,相干系数有时出现明显的极大峰值,可以作为切分的依据。图2 显示在图1(b)的结果上加入相干分析后的端点检测结果,明显看出将“师恩难忘”四个字的语音信号分成了四个独立的音节。
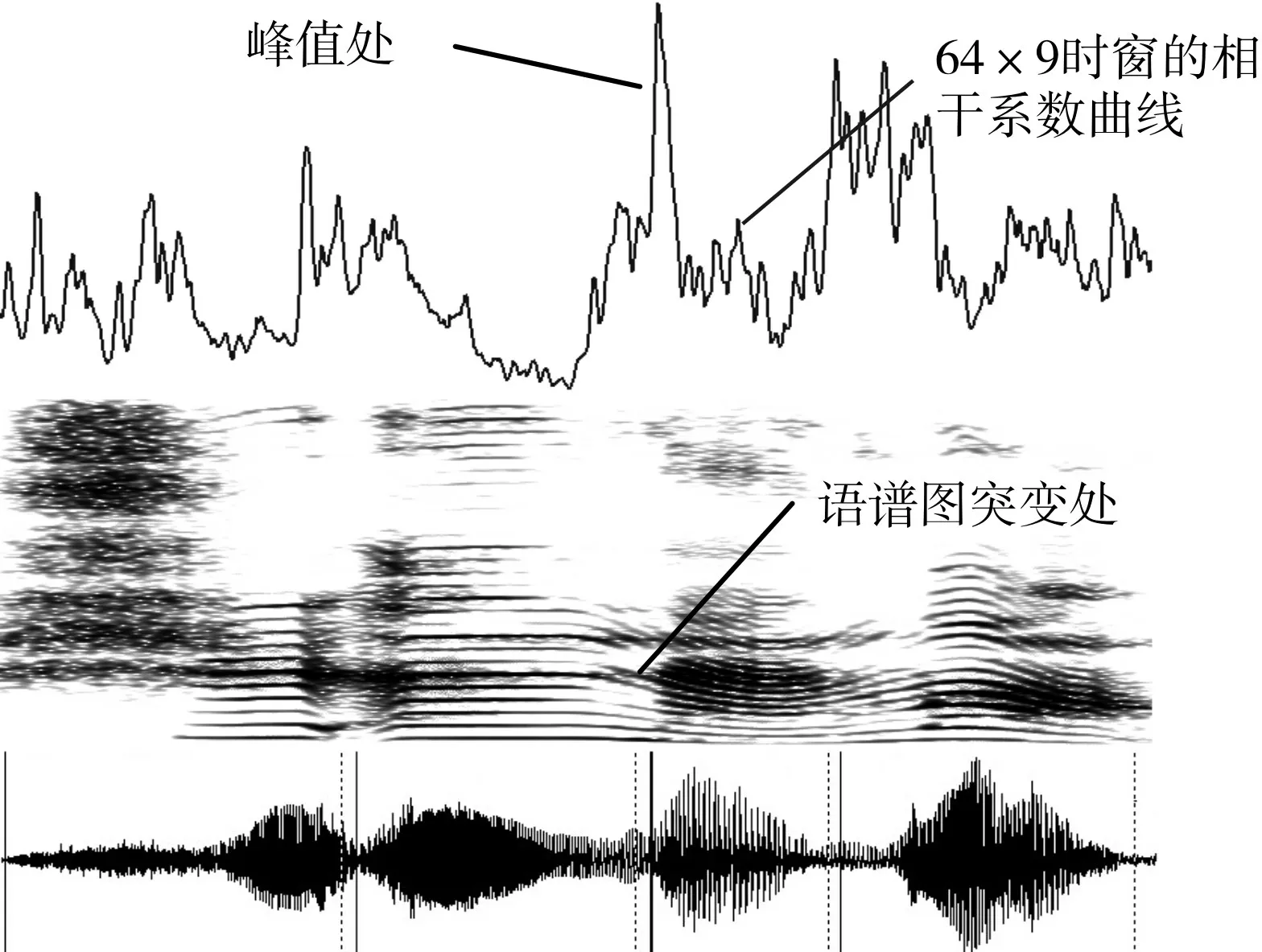
图2 汉语“师恩难忘”的相干系数曲线和切分结果
4.1.2 多尺度分析
语谱图上,语音信号的共振峰特征在不同频率范围内的分布是不均匀的,导致提取特征信息的最佳位置不一致,因此需要用多个初始位置不同或者大小不同的窗口来进行相干分析,以便适应不同频率范围的变化。
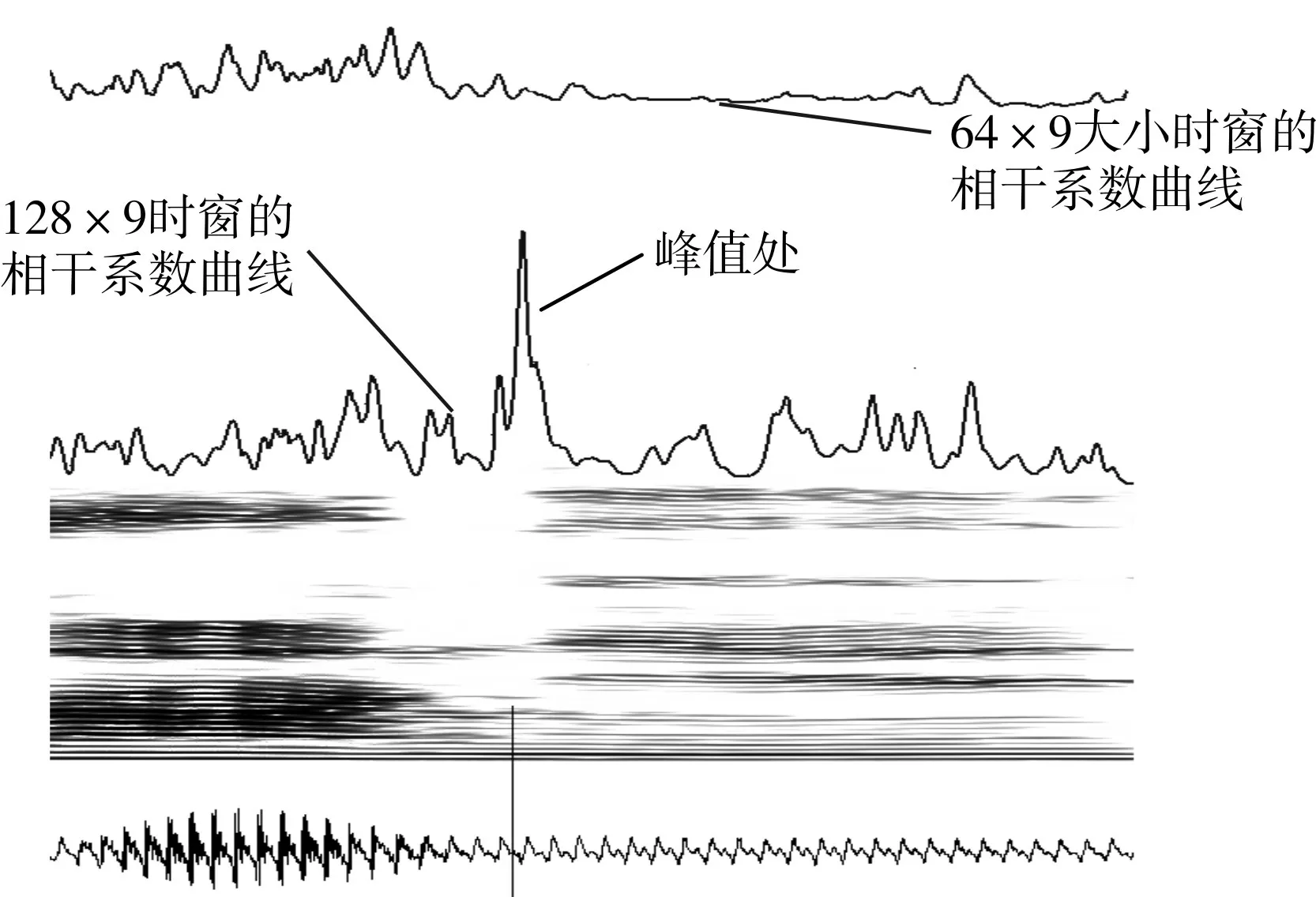
图3 汉语“那年”的语音信号的多尺度相干分析结果
本文的实验中我们选择64×9(频点范围0~64,频带范围0~2kHz)和128×9(频点范围0~128,频带范围0~4kHz)两个不同大小的窗口对语谱图进行相干分析。如图3 所示,对比分析两条曲线可以看出在“那”和“年”之间的连接处,64×9 的窗口无法表现出较高频率的语谱图的差异;128×9 的窗口因为包含了中高频的频谱差异,所以在相干系数曲线上有较明显的波峰。
对于不同大小的窗口需要设置不同的阈值,本文的实验中,对64×9 的窗口设置的阈值为0.2;对128×9 大小的窗口,设置的阈值为0.15。当相干系数大于设定的阈值时认为该位置存在音节界限。对不同大小窗口的相干分析结果需要进行综合分析确定切分位置。综合分析的基本思想:若两条相干系数曲线中任意一条曲线在某一位置超过设置的阈值,就认为该位置是两个音节的分界线;若两条相干系数曲线在同一大致位置都超过对应的阈值,则取两点的中间位置作为音节的分界线。
4.1.3 基音周期轨迹检测
基音周期轨迹可以用来判断元音段的位置,由于倒谱易受周期性复合噪声的影响,有时会出现虚假的倒谱峰值,基音周期轨迹比基于倒谱的端点检测结果更可靠。利用基音周期轨迹的检测元音段的步骤如下:
1)获取基音周期轨迹图的像素值矩阵A(m×n),其中m表示帧长的1/2,n为语音帧数。
2)找出矩阵A 中含0(黑色像素点)的行区间[a11,a12]…[an1,an2],如图4 所示,其中[an1,an2]表示一组数据,含义为第an1行到第an2行每行都含有值为0 的点,元音段的基音周期轨迹肯定包含在某一个行区间内。
3)对2)求出的行区间进行筛选,找出平均含0值点大于5 的行区间,减少孤立像素点的干扰,例如图 4 中的行段[a21,a22]明显是孤立的像素点区间,需要除去。
4)用3)求出的行区间,例如图6中的行段[a11,a12],组成新的矩阵 B,找出矩阵 B 中含 0 值的列区间[b11,b12]…[bn1,bn2]。
5)对步骤4)的列区间进行合并,若相邻列区间间隔小于一帧则合并为一个区间。
6)再次遍历列区间,找出bi2-bi1≥l 的列区间,l为设定的阈值(l 需要根据完整元音段至少包含的帧数确定)。将列号转为对应的帧号即为所求基音周期轨迹区间。
基音周期轨迹检测与基于倒谱的端点检测的结果可以相互进行校正。如图4所示。
图4 汉语“乡村小学”的基音周期轨迹检测
基音周期轨迹检测到的元音段为[A,B]、[C,D]、[E,F]和[G,H],基于倒谱的端点检测的结果为[I,J]、[K,L]、[M,N]和[O,P]。从图4 可以看出两种方法对“乡”、“村”、“学”三个字的元音段的检测结果相差不大,但是在“小”的元音段的检测上,基于倒谱的端点检测结果明显没有基音周期轨迹检测结果准确。
4.1.4 语谱图灰度均值变化分析
汉语中辅音信号的能量一般集中在高频部分,元音信号的能量集中在中低频部分。通过观察大量实验发现,当音节变化时,部分相邻音节的界限处的像素点灰度分布会出现明显变化,可以利用语谱图上像素点灰度值的变化来寻找切分点。
具体实现方法:求时窗内像素点的灰度均值,然后将时窗向右滑动,依次计算,直至语谱图最右端,求相邻窗口灰度均值的差值,然后归一化处理。
语谱图灰度均值变化曲线绘制步骤:
1)绘制语音信号的语谱图,获取灰度值矩阵。
2)选取m×n大小的时窗,m 表示窗口包含的频率点数,n表示帧数。求窗口内像素点的灰度均值。
3)窗口水平右移,每次移动n-1 帧的距离直至语谱图最右端,获取 k 个灰度均值 v1,v2…vk-1,vk,求相邻两个灰度均值之间差值的绝对值,然后归一化得到k-1个数据。
4)将归一化后的k-1 个数据中相邻数据连接起来得到灰度均值变化曲线。
对“师恩难忘”的语音信号的语谱图用128×9的窗口进行分析后得到图5 的灰度均值变化曲线,其中128 表示每一帧的第33~160 个数据点。因为在语谱图上,0~1000Hz 频带范围内的像素点的灰度值分布较为均衡,无法体现灰度均值的变化;在1000Hz~5000Hz 频带范围内的像素点(第 33~160个数据点)的灰度值随语义变化较明显,可以用来分析灰度均值的变化;当频率超过5000Hz时,像素点的灰度值分布较为杂乱,会影响结果的准确性。从图5 可以明显地看到在“恩”和“难”的界限处,灰度均值变化曲线出现了较高的极值,可以作为切分的依据。本文在大量观察分析实验后,设定阈值0.15,当灰度变化值大于0.15 时可以认为对应位置存在切分点。

图5 汉语“师恩难忘”的灰度均值变化曲线
4.2 多级切分算法
在4.1 节介绍了四种寻找切分点的思路,为了实现连续汉语语音切分,将4.1节的方法综合起来,研究了多级切分方法,主要步骤如下:
1)利用双门限端点检测技术检测到语音段[tn1,tn2]。
2)对1)的语音段利用基于倒谱的端点检测技术找出元音段[l11,l12]…[lm1,lm2]。
3)利用基音周期轨迹检测算法对2)的结果进行校正得到校正后的元音段
4)元音段的末帧可以看作是一个切分点,对于检测到的最后一个元音段应该与有声段的结束帧tn2相吻合。获得初步的切分结果
5)遍历4)的切分结果,对连续元音帧数大于T的语音段(T 需要根据完整元音段一般包含的帧数m 来确定,T设置2m),利用多尺度相干分析检测相干系数大于设定阈值的语音帧作为切分点。
6)遍历5)的结果,对连续元音帧数大于T的语音段,利用语谱图灰度均值分析找出灰度均值大于设定阈值的语音帧作为切分依据。
利用多级切分方法,通过相干分析、多尺度分析、基音周期轨迹检测和语谱图灰度分析将连续汉语语音切分为独立的音节。通过对实验语音库的语音文件进行切分实验,得到表1 的对比结果。从

表1 可以看出,对相同测试样本,多级切分方法准确率更高,比基于双门限和倒谱的端点检测技术和基于频带方差的切分方法分别高出33%和26%。
其中南京理工大学NJUST603 语音库含男生210人,女生213人,T4语音文件为作家刘绍棠的文章《师恩难忘》,含593个汉字,本文的实验选取了5名男生,5名女生的T4语音进行统计。
5 结语
多级切分方法综合了声学、语音学、语言学的知识,在分析汉语语音特征的基础上利用双门限端点检测技术、基于倒谱的端点检测技术、相干分析和基音周期轨迹检测等方法对连续汉语语音进行切分,获得了较高的准确率。实验中也发现一些问题需要去解决,例如对有些快速并且不清晰的发音如何确定音节的界限,这将是本文下一步的主要研究方向。
猜你喜欢
汽车实用技术(2022年4期)2022-03-07
考试与评价·七年级版(2021年1期)2021-08-14
考试与评价·七年级版(2020年1期)2020-10-23
语数外学习·高中版中旬(2020年8期)2020-09-10
兵器装备工程学报(2020年3期)2020-04-22
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
中学生数理化·教与学(2019年8期)2019-09-18
火力与指挥控制(2019年4期)2019-06-14
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
小学生时代·大嘴英语(2014年6期)2014-11-04
