
基于机器学习的专利质量评估研究∗
2019-07-31 09:54杨美妮张建军
计算机与数字工程 2019年7期
杨美妮 沈 静 张建军
(海军工程大学理学院 武汉 430033)
1 引言
专利作为无形资产的重要组成部分,在国民经济中发挥着重要的作用。专利价值的评估,一方面可以使得企业对其所拥有的专利有一个全面的认识,便于对这些专利进行有效保护;另一方面可以为专利转让,专利购买等无形资产运营行为提供重要的价值参考。专利价值的主要影响因素包括专利质量、市场价值、技术可替代性和专利保护强度四个方面,在这四个要素中,专利质量是基础[1]。因此,对专利质量进行科学合理的评估具有重要的意义。
专利数据中蕴含着丰富的计量指标,这些计量指标和专利质量之间存在着密切的联系。例如,专利的引用、专利的科学关联度以及专利的技术周期可以用来描述专利所代表技术的先进性程度[2];专利的学科覆盖程度同专利的诉讼之间存在着一定的联系,赢得诉讼的专利通常具有较高的质量[3];在本国以外地区申请的专利质量一定程度上优于只在本国申请的专利[4]等。在对专利质量进行分析时,经常需要分析处理大量的专利,完全手工分析费时费力。在这样的情况下,可以将专利的计量指标作为输入特征,建立机器学习的模型对专利质量进行自动评估,从而减少专利分析的投入并且加快分析的过程[5~7]。本文分别使用逻辑回归,支持向量机,神经网络三种机器学习的方法建立了专利质量评估的模型,并将其运用于3D 打印相关专利的质量评估之中。
不同于以往的工作,首先,本研究所采用的数据规模相对比较庞大,一共采用了上万条专利六千多个专利族作为机器学习模型的样本,样本中的测试集规模有两百多个专利族,研究结果相对较为可靠;其次,利用逻辑回归模型在输出上的概率解释特性,对输出结果的准确率和召回率进行了单边控制,从而使得专利评估模型能够满足某些特定应用场合的需求;最后,本文的方法选取了引用专利质量评价指标、权利保护范围专利质量评价指标和区域保护范围专利质量评价指标,一共三类指标11组计量特征作为模型估计专利质量的依据,计量特征的选取相对比较全面。
2 模型构建
2.1 机器学习过程
对已标注数据自动分析获得规律,并利用规律对未知数据的标注进行预测是机器学习的一个重要的研究方向。具体过程可以参见图1,其中f 是未知的理想目标函数,X 为函数输入,Y 为函数输出,这个函数是所有现实标注数据产生的依据,机器学习的目标就是为了找到一个能够近似于f的函数;训练集是一些已经被标注的数据,用于给机器学习的算法提供相应的支持,其中xi是数据特征,yi是该输入特征所对应的标注;学习算法A是机器学习的核心,用于从训练集中总结出相关的规律,从假设空间H 中选取最优的假设函数g 作为目标函数f 的近似[8]。在对专利质量进行评估的过程中,目标函数f 是理想的专利质量评估公式,使用这个公式能够准确的计算出专利的质量,训练集是已经标注好专利质量的历史专利质量记录,假设空间H是可能的专利质量估算公式集合,假设函数g 则是学习算法A 从训练集中学习到的可以用于对未知质量的专利进行评估的公式,该公式近似等于f。
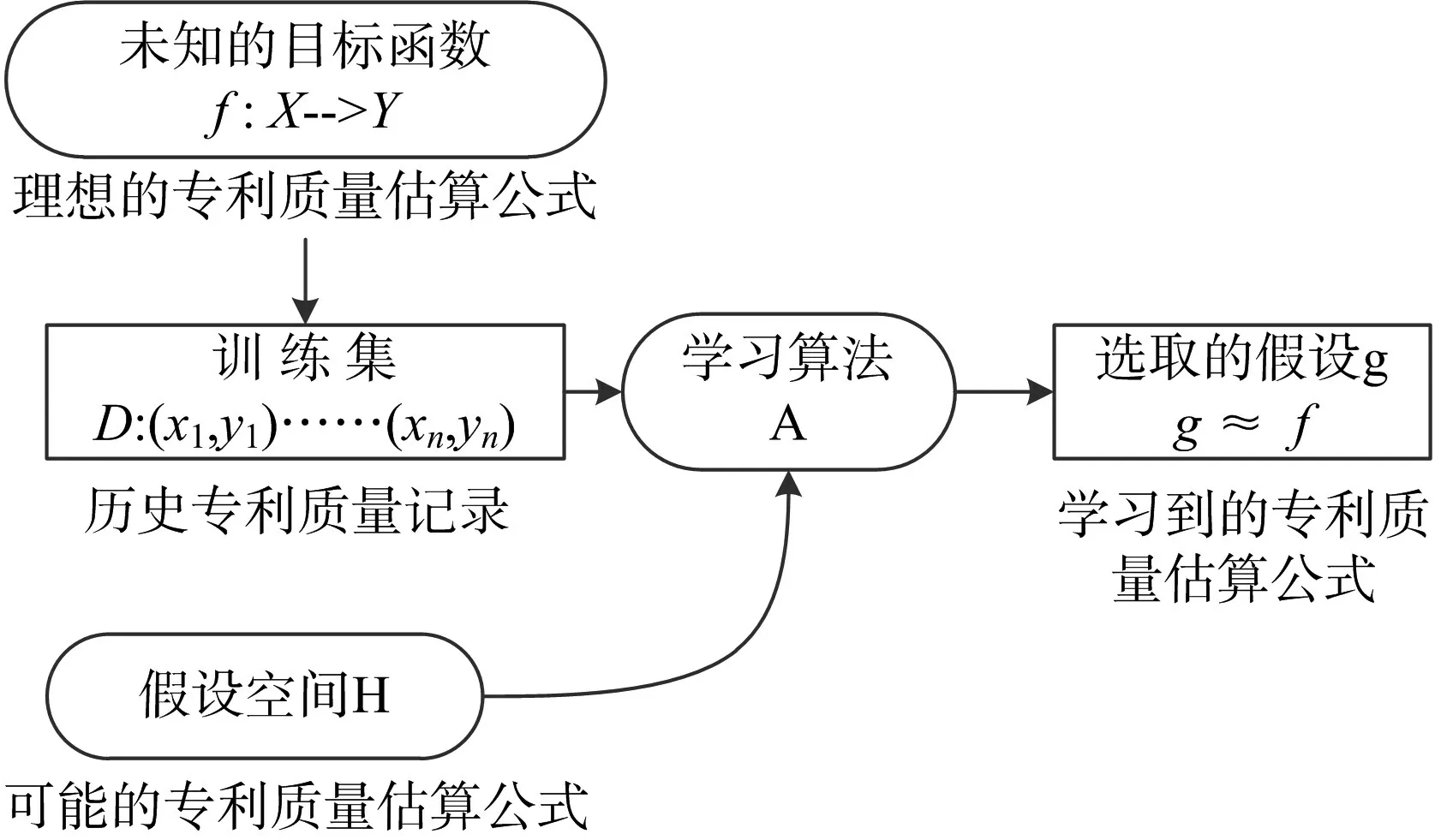
图1 机器学习过程
本研究将专利质量的评估抽象为一个机器学习的二分类问题,所有待判断质量的专利都将被自动划分为两类中的一类,如果某个专利质量可能比较高,那么模型将该专利划归为一类,否则该专利被划归为另一类。
2.2 输入特征与输出
在机器学习建模时,模型的输入特征必须体现出与模型输出相关的信息,输出表现的是机器学习的目标,两者的建立必须和机器学习所要解决的具体问题相对应。
在本文中,所建立的机器学习模型是为了对专利的质量进行评估,参照之前的工作[9],选取了包含引用指标、权利保护范围指标和区域保护范围指标一共三类指标11 组计量信息作为模型的输入特征,这些计量信息和专利的质量都存在着某种联系。具体如表1 所示,表中的专利族列代表这些指标来自于专利族还是单条专利。
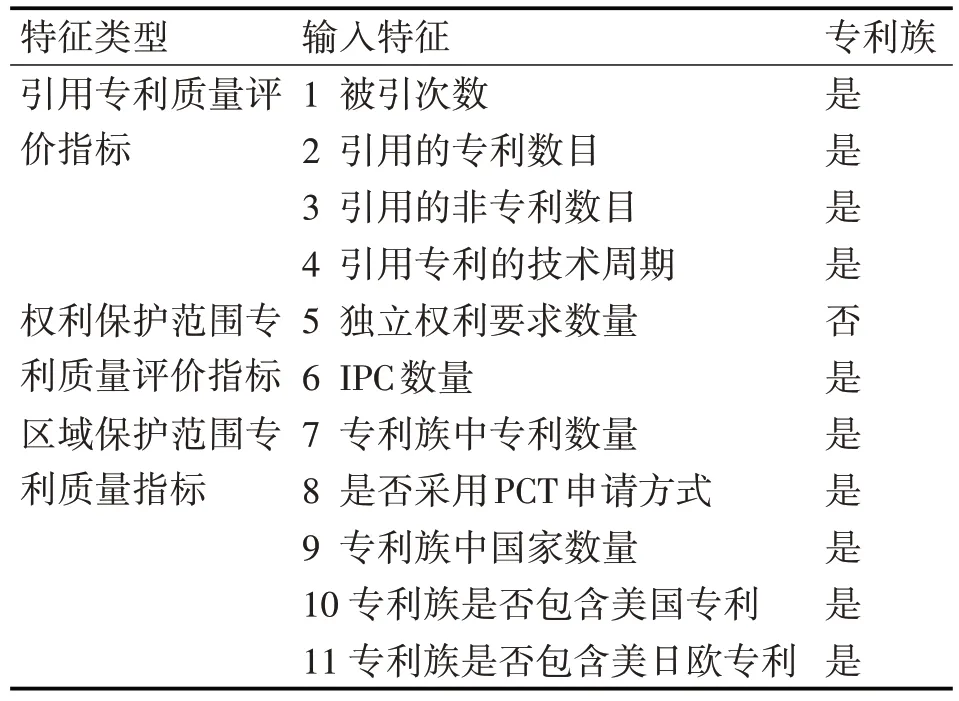
表1 模型输入特征列表
专利质量是个比较抽象的概念,在不同的情况中常常表现为不同的形式[6],比如说曾被转让的专利质量通常较高,赢得诉讼的专利质量通常较高等等。本文从专利转让这一角度描述专利质量,也就是说,机器学习模型的输出是专利可能被转让的情况。
2.3 三种机器学习模型
在该研究中,我们分别采用了逻辑回归模型,支撑向量机模型,神经网络模型作为专利质量评估的模型。逻辑回归模型结构简单,输出具备概率特性,利用这一特点,能够单方面地对研究结果的准确率或者召回率进行控制,以满足特殊的需求。支撑向量机模型是优秀的分类器,参数数量少,通常能够相对比较容易得到可以接受的结果。神经网络模型结构复杂,参数数量多,模型功能非常强大,通常能够得到优秀的实验结果,但同时该模型的操控空间也比较大,容易发生过拟合,从而影响研究结果。之所以选取这三个模型,一方面是想利用逻辑回归模型输出的概率特性,另一方面逻辑回归模型较为简单,对复杂些的数据分布无法进行有效的分类,所以引入能够处理复杂数据分布的支撑向量机模型和神经网络模型,用支撑向量机模型作为神经网络模型的一个比对。
2.3.1 逻辑回归模型
逻辑回归模型是机器学习中的一种监督式的分类模型,算法相对简单和高效,在实际应用中非常广泛[10]。在本文的逻辑回归模型中,输出变量是一个介于0 和1 之间的实数,代表某一专利具备较高质量的概率。影响第i 个专利质量的11 个输入变量分别为xi1,xi2,…xi11,对应表1中的11组输入数值特征,逻辑回归的模型可表示为

式(1)中,a0,a1,…,a11是模型的系数,可以依据训练集计算出来。式(2)中,Pi代表第i 个专利具备较高质量的概率。
2.3.2 支撑向量机模型
支撑向量机模型能够在高维或者无限维空间中寻找出用于分类的间隔最大的超平面,然后使用超平面对数据点进行分类。由于能够将低维空间线性不可分的数据映射到高维空间从而使其变成线性可分,所以这种机器学习算法可以处理线性不可分数据[11-13]。
具体来说,支撑向量机就是求解如式(3)所示的约束最优化问题:

其中(xi,yi)是训练样本,w,w0是超平面的相应参数,C 是惩罚因子,δi是用来允许一定分类错误的松弛变量。 K(xi,xj)≡φ(xi)Tφ(xj)T是选取的核函数,在本文中,选用的是径向基核。
2.3.3 神经网络模型
神经网络是一种模拟生物神经网络结构和功能的机器学习模型,由大量的节点和相互之间的连接构成。每个节点代表某个特定的激活函数,节点之间的连接代表节点间相应的权重。神经网络模型通过调整这些节点之间的权重以达到学习数据规律的目的[14]。本文中所使用的前馈神经网络模型如图2 所示。由于输入所对应的是11 个专利质量指标,所以输入层一共是12个节点,包括11个特征输入节点和1 个偏置节点。输出层是2 个节点,如果第一个节点的输出值较高代表专利质量较高,否则代表专利质量没有那么高。通过比较研究,神经网络的中间层被设置为6 个节点,包括5 个普通节点和1个偏置节点。
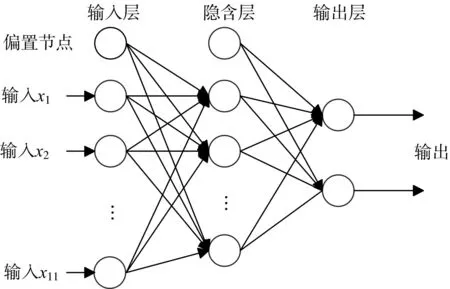
图2 神经网络模型
3 数据与分析
3.1 数据来源
从Thomson Innovation 中检索了与3D 打印技术相关的一共14840条专利,7452个专利族。由于小部分导出的专利数据缺少权利要求字段与专利族字段,这种类型的专利无法提取出机器学习模型的输入特征,所以被移除,最后参与实验的是一共6148 个专利族。从这些专利族中随机抽取60%作为训练数据,20%作为验证数据,最后余下的20%作为测试数据。训练数据和验证数据主要用于训练机器学习模型,确定模型的各种参数,测试数据不参与模型的训练,用于对训练好的模型进行评估以确定其性能。三个机器学习模型均采用相同的实验数据切分,以便于进行比较。
3.2 评估指标
本文将专利质量的评估抽象为机器学习中的二分类问题,所以采用机器学习中常被用于评价分类效果的准确率(Precision),召回率(Recall)和F1值作为实验的评估指标[15]。准确率是被分类器判断为具有较高质量的专利中正确的比例,召回率是模型判断为具有较高质量的专利中正确的占全部测试集具有较高质量专利的比例。F1 值则是平等考虑准确率和召回率,将两者结合在一起所产生的综合指标。
假设有 m 个专利 patent1,patent2,…patentm,对应的标签为 label1,label2,…labelm,标签代表该专利是否曾被转让,那么准确率,召回率,F1 值的计算方法如式(4)、(5)所示:
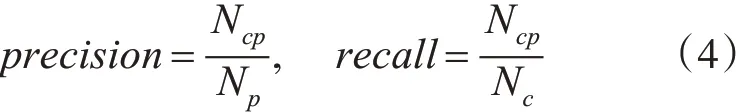

其中,Nc是m 个专利中曾经发生过转让的数量;Np是m 个专利中机器学习方法预测可能发生转让的专利数量;Ncp是曾发生转让的专利中被机器学习方法预测正确的数量。
3.3 研究结果分析
三种机器学习模型的研究结果如表2 所示,从结果中可以看出逻辑回归模型的准确率最高,神经网络模型的召回率最高,如果同时考虑准确率和召回率的综合指标F1 的话,神经网络模型的效果较好。
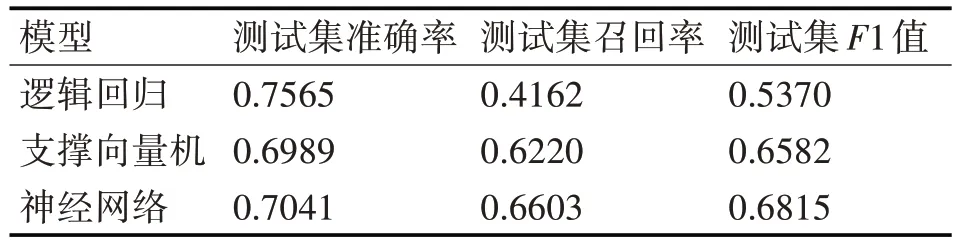
表2 三种机器学习模型结果比较
在使用机器学习的分类问题中,准确率和召回率两者通常是相互影响的。理想的情况是两者都能取到比较高的值。但是一般情况下,如果准确率较高的话,召回率就可能较低,召回率较高的话,准确率就可能较低。在这样的情况下,我们可以对模型进行一定的设置,对准确率或召回率进行单边控制,使得结果的准确率较高或者召回率较高。也就是说,可以让模型输出少数几个结果,从而使得结果中绝大多数的专利都确实是高质量的专利,也可以让模型多输出一些结果,从而使得所有高质量的专利几乎都在输出的结果中。
逻辑回归模型的输出为某专利是否具备较高质量的概率,利用模型的这一特性可以设置一定的阈值,只有模型输出的概率值大于指定的阈值,模型才判定该专利具备较高的质量。通过这样的方式,就能够对实验的准确率与召回率进行单边控制。在研究过程中,不同阈值所对应的准确率和召回率如图3 所示,纵坐标代表召回率,横坐标代表准确率,图中点上的数值代表设置的阈值。从图中可以看出随着阈值的增大,准确率的整体趋势是逐步上升的,召回率的整体趋势在逐步下降。比如说,最左侧点设置的阈值为0.1,代表逻辑回归的输出大于0.1 就判定专利质量比较高,由于设置的阈值很低,所以召回率达到了0.95 的高值,但是相应的准确率只有0.29。再比如说最右侧点设置的阈值为0.9,代表逻辑回归的输出大于0.9就判定为该专利质量较高,由于设置的阈值很高,所以准确率达到了0.88 的高值,但是相应的召回率也下降至0.03。这样就可以通过控制阈值以获得较高准确率的输出或者较高召回率的输出。
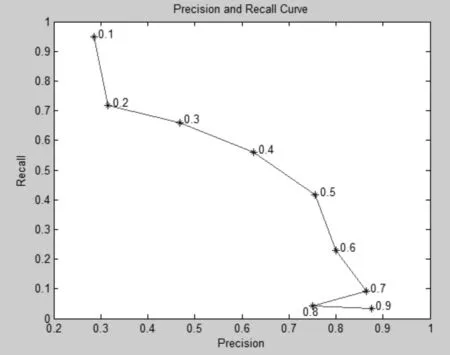
图3 不同阈值下的准确率和召回率
4 结语
本文选取了覆盖引用专利质量指标、权利保护范围专利质量指标和区域保护范围专利指标,一共11 组专利计量特征作为机器学习模型的输入,分别构建了逻辑回归、支撑向量机以及神经网络三种机器学习模型对专利质量进行评估。在与3D打印相关的六千多个专利族所构成的数据分析上,神经网络的综合性能最优,逻辑回归模型由于其概率输出特性,可以用来对实验结果的准确率和召回率进行单边控制,以满足某些特定的需求。
分析中将专利被转让的可能性作为模型的输出,对专利的质量进行判断是不够完善的,因为通常情况下专利被转让只是专利具备较高质量的充分条件,而不是必要条件。在未来的工作中,我们将构建更为完整的对专利质量的描述作为机器学习模型的输出,从而提高专利质量判断的准确程度。
猜你喜欢
法律方法(2022年2期)2022-10-20
建材发展导向(2021年19期)2021-12-06
中学生百科·大语文(2021年11期)2021-12-05
计算机仿真(2021年6期)2021-11-17
纺织科学研究(2021年7期)2021-08-14
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
临床骨科杂志(2020年1期)2020-12-12
