
用户短文本无关语自动识别方法研究∗
2019-07-31 09:54刘亮亮张再跃
计算机与数字工程 2019年7期
陈 国 刘亮亮 张再跃
(1.江苏科技大学计算机科学与工程学院 镇江 212003)(2.上海对外经贸大学统计与信息学院 上海 201620)
1 引言
在电子形式的文本信息数量飞速增长的背景下,文本挖掘[1~2]成为信息领域获取知识的重要手段。目前,文本挖掘的主要方法有关联分析[3]、总结[4]、分类[5]、聚类[6~7]等,其中较为常用的方法是文本聚类。在文本聚类过程中发现,文本中存有大量无关信息,这些无关信息对计算句子的相似程度有很大的影响。因此,就需要对文本中的无关信息做处理,其中就包含对所谓“无关语”的识别与清理。从结果看,通过无关语的自动获取处理,可以成功提升文本聚类效果。在无关语获取获取方法一般可采用基于规则的,或基于统计的,或基于机器学习的等。姜仁会等[8]利用微博评论和转发进行词频统计,通过规则筛选,实现了面向微博文本的命名实体识别;袁璐等[9]同样利用统计与规则相结合的方法,提出了一种依存分析和隐马尔科夫相结合的文本信息抽取算法实现自由文本的信息抽取。R.Speck等[10]通过机器学习中的集成学习来提高命名实体识别工具的性能,利用多种识别方法、验证方法在多个数据集上进行测试,证明了集成学习可以将命名实体识别系统的错误率大幅度降低。目前在中文无关语研究方面,周峰等[11]通过种子无关语推导出强无关语,结合强无关语和语料特征对种子集的无关语进行扩充,该方法能有效获取固定位置内的无关语,但当语句较长时识别率却不很理想。
隐马尔科夫模型[12]是可用于标注问题的统计学习模型,属于生成模型,隐马尔科夫模型在自然语言处理领域中被广泛的应用。综合上述思想方法,本文在用户短文本预处理过程中采取标注法对短文本无关语状态进行预测,通过加入词性特征与相对位置特征标注对预测结果进行优化,并将符合一定规则的状态值序列视为无关语隐状态的预测序列值;扩展隐马尔科夫模型,用最大似然估计法进行模型参数训练,结合训练的模型,利用改进的维特比算法[13]求最优状态序列,以达到最终获取短文本无关语的目的。
2 基本概念与方法简介
2.1 无关语特点
一般而言,短文中的无关语具有以下几个方面的特点:
1)主体无关性。主体无关性体现在其存在与否不影响句子的语义。
2)领域无关性。短文本具有一定的领域性,如咨询文本、网络评论、即时通信聊天记录等。无关语的领域无关性体现在其在任何领域均为无关语。
3)位置特殊性。通过对大量的短文本中无关语进行手工识别,对其在短文本中出现的位置进行记录,发现绝大多数无关语出现的位置较为特殊,如在短文本的句首或句尾等。
4)词性特殊性。无关语的词性相对较为有限,通常不会包含一些名词信息,如地名、人名和专业名词等。
2.2 隐马尔科夫模型
隐马尔科夫模型属于生成模型,可用于标注问题的统计学习模型,通常可以通过三元符号表示隐马尔科夫模型λ 为

其中,A 是状态转移概率矩阵,B 是观测概率矩阵,π 是初始概率向量。在无关语识别过程中,本文中主要利用隐马模型求解隐状态序列的思路进行语料的隐状态预测标注,也就是将句子中的每个词标注为一个隐状态预测,符合一定规则的隐状态序列构成一个无关语。句子中的词,词性,相对位置均可视为可见状态,通过状态转移概率矩阵A与初始状态概率向量π 确定了隐藏的马尔科夫链,生成的即为隐状态的状态序列。观测概率矩阵B确定了如何从状态生成观测。
隐马尔科夫模型具有齐次马尔科夫性[14],即在当前状态进行状态转移时只考虑前一个位置的状态,这样的假设条件与自然语言出现的规律不符。相比较传统的隐马尔科夫模型,二阶隐马尔科夫模型[15]具有一定的优势,主要体现在其考虑了更多的历史状态,从而提升了预测效果。
2.3 二阶隐马尔科夫模型
隐马尔科夫模型的变量可分为两组。第一组为状态变量 S={s1,…,st},其中 si∊S 表示第i 个位置系统的状态,也称为隐变量。第二组为观测变量O={o1,…,ot},其中oi∊O 能表示第i 个位置的观测值。在隐马尔科夫模型中,系统通常在多个状态{q1,…,qN}之间转换。观测变量oi的取值范围为V={v1,…,vM},也就是每个隐状态对应的观测值有M 个。
二阶隐马尔科夫模型λ 可以通过五元组表示为λ=(A,A',B,B',π)。其中各参数如下。
状态转移概率矩阵记为 A'=[aij]N×N,A=[aijk]N×N×N,对任意 i,j,k=1,2,…,N ,有
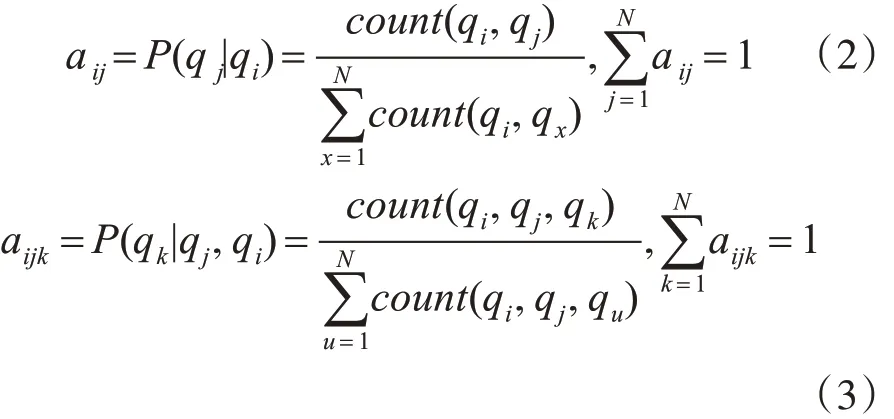
aij表示当前状态为qi下一个状态为qj的概率。aijk为表示状态qi状态qj依次出现时下一个状态为qk的概率。 count(qi,qj)表示状态qi到状态 qj的转移次数表示状态qi到任意状态的转移次数之和;count(qi,qj,qk)表示状态qi、状 态 qj转 移 到状 态 qk的总 次 数;表示状态qi、状态qj转移到任意状态的总次数。
观测概率矩阵记为 B'=[bil]N×M,B=[bijl]N×N×M,对任意的i,j=1,2,…,N ,l=1,2,…,M ,有

bil表示状态为qi的条件下,观测值为vl的概率,bijl表示状态依次为qi、qj的前提下,状态qj对应的观测值为vl的概率。count(vl,qi)表示状态为qi的前提下观测值为vl的次数;表示状态为qi的前提下观测值任意的总数;count(vl,qi,qj)表示状态qi、状态qj出现的前提下观测值为vl的总次数;表示状态qi、状态qj和出现的前提下观测值任意的总次数。
初始状态概率向量通常记为π=(π1,π1,…,πN),对任意的i=1,2,…,N ,有
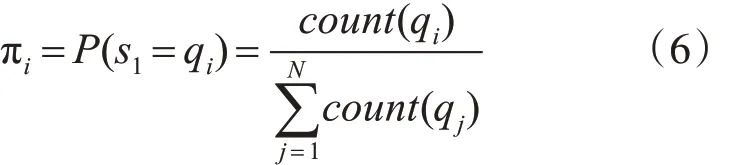
πi表示模型的初始状态为 qi的概率。count(qi)表示状态qi的作为初始状态的总次数;表示任意状态作为开始状态的次数和。
3 多特征预处理无关语自动识别方法
本文用户短文本无关语获取方法采取四个基本步骤:首先对实验语料进行分词;其次,进行词性与相对位置标注;第三,进行隐状态标注;第四,用扩展二阶隐马尔科夫模型来建立训练模型,通过最大似然估计法进行模型参数训练,确定模型参数;第五,结合训练的模型,利用改进维特比算法求最优状态序列;最后输出标记好的无关语。
3.1 语料预处理
语料预处理的过程包括语料分词、隐状态标注和相对位置标注。首先从文本中手工筛选出一批用户咨询短文本,利用ICTCLAS对其进行分词并进行词性标注,手工对分词后的语料中的每个词语进行BMEOS标注[16]。其中:
B表示该词位于一条无关语的起始位置;
M表示该词位于一条无关语的中间位置;
E表示该词位于一条无关语的结束位置;
O 表示该词位于一条无关语外部,不属于无关语成分;
S表示该词为一条无关语。
然后对标注后的语料进行相对位置标注,此处的相对位置表示的是一条咨询短文本中的一个词相对于这一条短文本的相对位置。取短文本句子的平均长度L 作为相对位置的最大取值,对于一个长度l 的句子中的第i 个词wi,i 的取值范围为[1,l]。其相对位置ri的计算方法为

通过式(7)可以对一个句子中所有的词进行相对位置标注,至此文本预处理阶段结束。
3.2 扩展二阶隐马尔科夫模型参数训练
通过式(2)和(3)可以计算确定矩阵 A 和 A',通过式(4)和(5)可计算确定矩阵 B 和 B',通过式(5)计算确定π。由此可以确定二阶隐马尔科夫模型 λ=(A,A',B,B',π)中的各个参数。为了获取的结果更好,在此加入词性的观测概率矩阵C=[cijl]N×N×M和 C'=[cil]N×M以及相对位置的观测概率矩阵 D=[dijl]N×N×M和 D'=[dil]N×M,分别记录在某一状态下观测到某个词性的概率以及在某一状态下观测到某一相对位置的概率。其中词性观测概率矩阵C 和C'中各元素计算公式为

相对位置观测概率矩阵D 和D'中各元素计算公式为
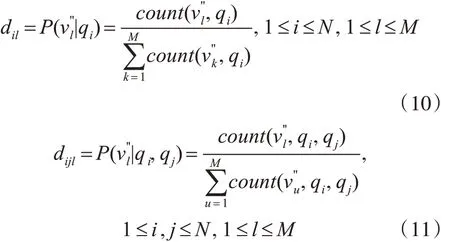
对所有矩阵归一化,最终求出扩展的二阶隐马模型 λ=(A,A',B,B',C,C',D,D',π)。
3.3 基于融合多特征的维特比算法的标记预测
输入:λ=(A,A',B,B',C,C',D,D',π)和观测词序列O=o1,o2,…,oT、对应的词性序列 O'=,…,、对应的位置序列O''=,…,。输出:最优路径S*=,,…,
1) 初 始 化 :δ2(i,j)= πi⋅[bi1⋅ci1⋅di1]⋅aij⋅[bij2⋅cij2⋅dij2],ψ2(i,j)=0 。 1 ≤ i,j ≤ N
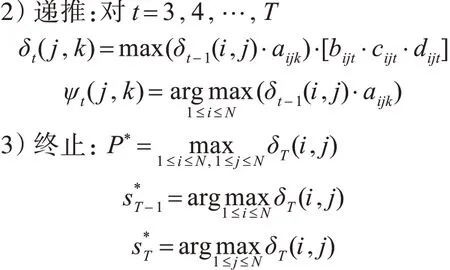
4)状态回退序列:对于t=T-1,T-2,…,2
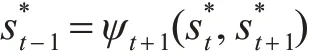
4 实验结果和分析
4.1 实验语料与实验参数
在先前的相关工作中积累了大量的用户咨询短文本,将这些用户咨询文本作为实验语料。首先从语料中随机提取6000 行不重复的咨询语料进行手工标注,并从这手工标注的6000 行咨询中随机抽取4000 行做模型训练,剩余2000 条作为测试集。以此方法执行五次,取五次实验结果的均值为本次实验的衡量标准。实验采用精确度(precision)、召回率(recall)和F1 度量值来评价当前模型的计算效果。
4.2 实验结果对比分析
实验分两组进行:第一组只考虑词语单一特征的情况下,分别采用一阶和二阶隐马尔科夫模型获取无关语效果对比分析;第二组实验则是在第一组实验基础上,综合考虑词语多种特征,包括词性特征以及相对位置特征等,采用扩展隐马尔科夫模型进行的无关语获取实验,并与文献[11]的方法进行了对比分析。结果如下。
1)通常一阶二阶隐马尔科夫模型结果对比分析。
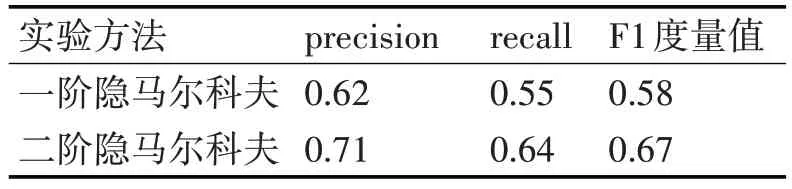
表1 通常一阶二阶隐马尔科夫结果对比
从中可以看出,在仅考虑词语本身时,一阶隐马尔科夫模型的实验结果并不理想,而采取二阶隐马尔科夫模型则得到了相对一阶而言较好的结果,这是因为二阶隐马尔科夫考虑到了更多的情况,因此获得了更好的实验结果。
2)采取扩展一阶二阶隐马尔科夫模型结果对比分析。
在考虑词语词性特征以及相对位置特征的情况下,对比一阶隐马尔科夫模型、扩展二阶隐马尔科夫模型和文献11 的方法的结果进行对比。结果如表2所示。

表2 扩展一阶二阶隐马尔科夫结果对比
从实验结果可看出,在加入了词性、位置特征后无关语的获取结果有了明显的提高。对比文献[11]的方法获取到的结果,本文的方法有更好的精度和召回率。这是因为参考文献[11]的方法仅考虑了在特定位置出现的无关语,而在此识别过程中,特定位置的选取较为重要,在一些文本长度稍长时就会出现识别不完整的情况,而本文的方法将位置作为其中的一个考量因素同时还考虑了其他因素,因此取得了更好的结果。
5 结语
本文讨论了用户短文本无关语自动识别的问题。通过对无关语特性的分析,采用二阶隐马尔科夫模型建模。在标注过程中融合了无关语的词性特征和位置特征,使用改进的维特比算法进行标注工作。为了进行验证,本文通过真实的咨询语料进行实验,实验结果证明本方法是能有效识别出短文本中存在的无关语。在对实验结果的分析中发现虽然本文的方法提升了获取无关语的精度,但是本方法尚存在的一些问题,如对于分词结果、错别字较为敏感,在处理长度较长的文本时表现不佳等。针对分词结果敏感、错字敏感等问题,在自然语言处理领域可采用非词错误校正、分词时导入手工整理的词典等方法实现优化,相关问题在后续的无关语识别工作中需要进行改进。
猜你喜欢
九江学院学报(自然科学版)(2022年2期)2022-07-02
安徽工程大学学报(2021年5期)2021-11-30
中等数学(2021年9期)2021-11-22
有色金属(矿山部分)(2021年4期)2021-08-30
厦门大学学报(自然科学版)(2021年4期)2021-06-22
电脑知识与技术(2019年23期)2019-11-03
智富时代(2018年12期)2018-01-12
智富时代(2018年12期)2018-01-12
数学学习与研究(2017年20期)2018-01-02
中学数学杂志(初中版)(2016年3期)2016-06-24
