
基于双向长短时记忆神经网络的句子分类∗
2019-07-31 09:55洪源沈勇
计算机与数字工程 2019年7期
洪 源 沈 勇
(江苏科技大学计算机学院 镇江 212000)
1 引言
随着智能问答系统的快速发展,越来越多的研究学者开始关注问题分类任务。问题分类是问答系统的关键技术之一,即为每个自然语言问句分配一个所属类别,从而在问答系统中通过问句的类别标签对候选答案进行提取。传统的问题分类大多采用基于规则的分类方法,这些方法大多是建立在待分类的句子中是否包含相同的词或者短语的基础上,因此不具有通用性。其后的基于机器学习的分类研究方法,同样也存在明显的缺点:1)在将长度不一致的问句转换为定长特征时可能会导致语句信息的缺失;2)分类器的性能会受到数据领域差别的影响,从而会导致分类性能下降。
针对以上问题,本文提出了一种基于深度学习的分类模型,采用基于注意力机制的双向长短时记忆神经网络以提高句子分类任务的准确性,并且在模型训练阶段创新性的将两条不同的句子作为模型输入。长短时记忆网络是一种更高级的RNN[2],通过在神经元上面添加门控的方式更好地控制信息的读取与写入。并且双向的长短时记忆网络能够更好地利用句子的上下文信息,同时加入的注意力机制可以提取出更加精确的句子特征向量。
本文在新浪旗下的中文问答互动平台“爱问知识人”的数据集上进行了实验,并和单向长短时记忆网络模型做了比较。实验表明双向网络模型明显优于单向网络模型,并且在数据集上也取得了比较好的分类效果。
2 相关工作
2.1 文本向量化
在自然语言处理(Natural Language Processing,NLP)相关工作前要将文本向量化,即将文本中的词转化为数学中的向量表示。主要有两种表示方法:集中式表示(One-Hot Representation)和分布式表示(Distributed Representation)。其中集中式表示采用稀疏存储方式,形式上较为简洁,但是这种表示形式有两个缺点:1)词向量的维度会随着词典的增加而膨胀,维度过高会影响训练的效率。2)不能很好地刻画词与词之间的相似性,从数学形式上看不出词与词之间的语义相关性;另外一种分布式表示形式,它是通过神经网络技术利用句子的上下文,和上下文词与目标词之间的关系进行语言模型建模,通过迭代训练得到词向量。
采用词向量的分布式表示能够降低词向量维度,可以表示出文本中的词与词之间的语义关系,从而有效地提升自然语言处理任务的性能[3~4]。本文后面的实验部分也是采用了分布式词向量表示,把预训练好的词向量作为神经网络的输入。
2.2 长短时记忆神经网络
标准的循环神经网络(Recurrent Neural Networks,RNNs)在训练过程当中存在梯度爆炸和消失的问题,并且只能存储有限的上下文信息[5~6]。长短时记忆神经网络(Long Short-Term Memory Networks,LSTMs)[7]通过扩展标准 RNN 很好地克服了这个问题[8]。LSTMs 和标准的 RNNs 一样有着重复的链状结构,但是重复的模块却有更加复杂的结构,它存在四层神经网络层并以特别的形式相互影响,网络结构示意图如图1 所示。LSTMs 中每一个单元模块可以通过门(gates)结构[9]对状态信息移除或者添加,信息可以通过门结构选择性的通过。
LSTMs 通过遗忘门(Forget Gate)、输入门(Input Gate)、输出门(Output Gate)三种门结构保持和更新每个单元模块的状态信息[10]。设 Xt、ht分别对应LSTMs 单元模块输入值和输出值。LSTMs 的单元模块工作情况如下步骤:
1)每一个单元模块处理的第一步是决定需要丢弃哪些信息,这项决策是由遗忘门的Sigmoid 层决定的。将当前时刻的输入Xt和上一时刻的输出ht-1作为输入。
2)需要决定单元模块需要存储哪些新的信息。首先,输入门的Sigmoid 层确定哪些信息需要被更新,it为将更新的信息:
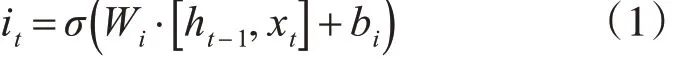
其次,一个tanh 层创建一个包含新候选值的向量,将其添加在单元模块的状态中,C˜t为候选值:
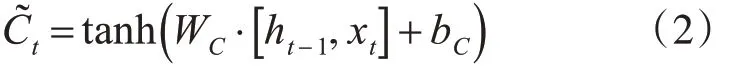
因此,遗忘信息的操作就是将上一时刻的状态Ct-1乘以 ft,再与新的候选信息 it*C˜t的和实现状态的更新。

3)由输出门决定单元模块需要输出的值。先运行一个Sigmoid层确定单元模块的状态中哪些信息需要被输出,然后将单元状态输入到tanh 函数中,再与Sigmoid的输出值相乘,最后得到将要输出的值。
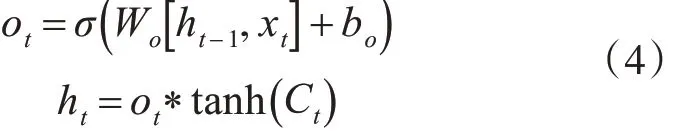
2.3 注意力机制
注意力机制(Attention Mechanism)是由Treisman 和Gelade 提出的一种模拟人脑注意力机制的模型。它模拟人脑对资源分配,因为人脑在特定的时刻对于事物的注意力只会集中在某一特定的部分,忽略其他部分。这种对关键部分分配较多的注意力,而对其他部分分配较少的注意力的思想[11]对于传统的模型具有很好的优化作用。目前很多领域都使用了这种机制,并且都有很好的效果,如计算视觉领域用于对图片的识别任务,在自然语言处理领域用于机器翻译等[12~14]。
3 构建模型
3.1 模型架构
为了克服单向的循环神经网络在处理时序序列时,忽略了未来时间点上的上下文信息的问题,本文设计的模型在长短时记忆神经网络的基础上,采用了双向长短时记忆神经网络(Bi-directional Long Short-Term Memory Networks,BLSTMs)[15~16],即使用两个LSTMs网络,一个LSTMs从前往后计算隐层向量h→,另一个LSTMs网络从后往前计算隐层向量h→,这样输入层的每一个节点都可以考虑基于它的过去和未来的语义信息。模型的整体框架结构如图2所示。

图2 模型整体框图
按照数据流向和模型架构可以分为以下几个部分:
1)数据预处理,包括去除部分停用词,对句子分词等。
2)Embedding 层,将分词后的每条句子转化为向量形式作为神经网络的输入。
3)BLSTMs 层,经过 BLSTM 网络模型抽取句子特征并将其池化。
4)对上一层抽取的句子特征通过多层神经网络(Multi-layer Perceptron,MLP)进行特征融合。
5)通过Softmax分类层给出最后的分类结果。
3.2 Embedding 处理层
Google 推出的 Word2vec[17]是一款开源的词向量工具,它是基于神经网络模型,使用词的上下文词生成当前词或者使用当前词生成上下文词的训练思路,极大化语言生成概率得到词的向量表示。Word2vec 有两种模型,分别是连续词袋模型(Continuous bag-of-words,CBOW)和 Skip-Gram 模型[18]。Word2vec 将文本词语转化成的空间向量,其向量相似度能够很好地表示词语之间的语义相似度。
本文采用基于Hierarchical softmax 算法的Skip-Gram 模型,词向量维度设置为256,窗口大小为5,训练迭代次数为10次。首先将词语通过创建的词汇表初始化为One-hot 形式的向量表示作为神经网络的输入层,然后是特征映射层,输出层是一棵Huffman 树。利用Hierarchical softmax 算法并结合Huffman 编码,文本语料库中的每个词可以从根节点沿着唯一路劲被访问到,路径即成为其编码,使得预测词二进制的编码概率最大化作为训练
的目标。
3.3 BLSTMs层
BLSTMs网络能够充分利用整个文本序列的上下文信息,其中包括每个词之间的相互关系,并且这种关系对每个节点相应的输出产生影响。在时间上展开的BLSTMs网络如图3所示。
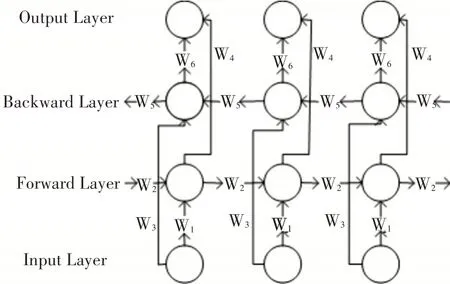
图3 双向循环神经网络在时间上的展开
BLSTMs的基本思想是提出每一个训练序列包含向前和向后两个单向LSTMs网络,而且这两个网络都连接着一个输出层。这样输出层的输入序列中每一个节点都可以考虑到过去和未来的上下文语义信息。图3是一个沿时间展开的BLSTMs网络(忽略了内部门结构),图中箭头方向代表信息流方向,w1到w6分别代表不同状态的权重矩阵,其中w1、w3代表输入到向前隐含层和向后隐含层的权重值,w2、w5代表两个独立前后向隐含层内部的权重值,w4、w6代表向前隐含层和向后隐含层到输出层的权重值。重要的是,向前隐含层和向后隐含层之间是无信息流的,因此确保了整个结构是无环结构,便于反向传播时更新梯度的值[19~20]。
本文将经过预处理并转化为向量形式的两个句子作为输入,通过两层LSTMs 网络并根据Attention 机制计算输入序列对最终状态的注意力概率分布。将注意力概率权重与历史输入节点的隐藏层状态乘积的累加得到语义编码,然后计算句子的特征向量。再将引入注意力机制后对应的输出特征进行池化,池化后的特征维度都是固定的,解决了句子长度不一致的问题。
3.4 特征融合与分类
特征融合是将多种特征进行归一化操作,融合为一种特征。模型使用MLP 融合提取的两类句子特征,得到最终特征向量f。最后将得到的特征向量f 导入Softmax 分类器进行类别结果s( x )的输出,如式(5)所示:

其中:⊗代表向量拼接,Fʹ·MS表示分类器的dropout处理,Ms是与Fʹ同形状的每轮迭代随机产生的二值向量;VS表示分类器的权值矩阵;bs表示分类器的偏置向量;g( )表示分类器的选择。输出s(x)是维度为1的向量,第i维代表可能为第i类的概率。
4 实验结果与分析
4.1 实验数据与环境
本文的实验数据语料来自新浪旗下的中文问答互动平台“爱问知识人”的语料集。选择了其中的7类话题共近10000条问句,分别为购物、社会与文化、健康与医学、教育、家庭生活、商业经济、电脑。
本文在Google 开源的机器学习库TensorFlow上实现实验设计,TensorFlow 是一个深度学习框架,它整合了当前比较流行的深度学习模型。
4.2 实验过程
本文实现了两个实验,一个是根据本文所设计的模型完成的实验,另一个是标准LSTM 模型实验,即非双向LSTM 和未添加Attention 机制的模型。本文为判断输入的两个句子是否为同一类,在各类别语料中任意取其中两句组合成句子对集合,代表正向语料,即属于同一类别。并在各类别中各取一句组成句子对作为负向语料,判别标签定位非同类。采用5 折交叉验证法,将预处理好的语料随机分为5 均份,抽取1 份作为测试集,其余4 份作为训练集。
本文采用了类别评测中常用到的正确率(precision)、召回率(recall)和F 值(F_score)三个标准作为模型评价指标。指标计算公式如下:

1)Attention Based Bi-LSTM模型实验
Attention Based Bi-LSTM 模型即为本文所设计的添加Attention机制的双向LSTM模型。首先将文本语料中的句子通过分词工具切分为词语。将语料中的单词利用Word2vec工具映射成50维的向量表示。特征提取部分采用的是加入Attention 机制的双向LSTM 网络结构,采用多层前向神经网络进行特征融合。模型的激活函数选用Relu 函数,隐藏层节点个数设为256。同样为避免过多拟合现象发生,采用L2 正则化方法约束网络参数,丢码率(dropout rate)设为0.5。学习率(learning rate)设为0.01。优化算法采用Adam 算法。分类器采用逻辑回归分类器,分类器的输入是融合后的特征向量。检测间隔步数设为100步,批尺寸设为20。
2)传统LSTM模型实验
与加入Attention机制的双向LSTM模型采用相同的参数配置和训练方法,不同之处在于去除了Attention机制,并且采用了单向的LSTM模型。
4.3 实验结果与分析
本文对上诉描述的实验模型及参数设定值在之前提到的语料数据集上进行实验,每个实验都进行多次训练调优,然后选取结果最好的实验数据。如表1给出了实验结果的统计。
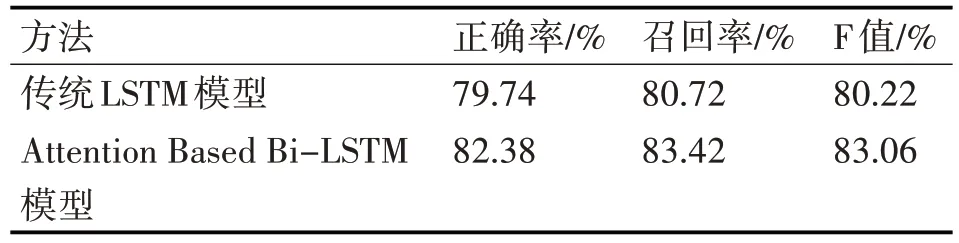
表1 实验结果统计
从表中的实验数据可以看出Attention Based Bi-LSTM 模型相比于传统LSTM 模型有效地提升了句子对的类别判断效果。Attention Based Bi-LSTM 模型获取了更多的上下文信息,并且具有每个词对句子特征影响的概率分布。并且在数据集规模并不大的情况下,Attention Based Bi-LSTM模型依然有一个类别不错的判别效果。比较传统机器学习的分类效果,深度学习模型表现出了明显的优势。
5 结语
本文针对传统深度学习方法(RNN、CNN)中无法解决文本长距离依赖问题和未考虑句子信息丢失和冗余的问题,提出了一种基于注意力机制的双向长短时记忆神经网络模型。在公共语料上的实验结果表明该方法的准确率较传统方法有了明显提升。本文的创新点在于传统的方法往往只拿一个句子作为模型的输入,而本文实验部分采用的是用两个不同的句子作为模型输入,通过分别提取句子的特征向量然后融合归一化后传送至分类器进行类别判断。并且采用双向LSTM 模型获取更多的句子上下文信息,结合注意力机制考虑模型输入与输出的相关性,从而提取了更有效的句子特征。
猜你喜欢
出版人(2022年11期)2022-11-15
大电机技术(2022年4期)2022-08-30
网络安全与数据管理(2022年3期)2022-05-23
今日农业(2021年19期)2021-11-27
厦门大学学报(自然科学版)(2021年4期)2021-06-22
电脑知识与技术(2019年23期)2019-11-03
人大建设(2018年7期)2018-09-19
文物鉴定与鉴赏(2017年5期)2017-05-16
成长·读写月刊(2017年2期)2017-03-21
唐山文学(2016年11期)2016-03-20
