
基于频繁项集挖掘的数据库超文本查询算法研究
2019-08-01 01:52刘建
数字技术与应用 2019年4期
刘建

摘要:目前数据库超文本查询方法存在查询准确率较低的问题,为解决这一问题对基于频繁项集挖掘的数据库超文本查询算法进行研究。研究通过建立频繁项集挖掘数据库超文本查询模型,以模型为基础对数据库超文本查询关联规则计算,从而实现数据库超文本查询权重计算。通过实验,对繁项集挖掘数据库超文本查询算法与传统查询算法精准度相比较,从而证明频繁项集挖掘数据库超文本查询算法的有效性。
关键词:频繁项集;挖掘;数据库;超文本
中图分类号:TP391 文献标识码:A 文章编号:1007-9416(2019)04-0119-02
0 引言
我国在向着信息时代发展的同时,已经拥有数量庞大的网络用户,因此在信息查询过程中信息数量巨大与信息易丢失成为目前面临的最大问题[1]。互联网的大量使用,使越来越多的人利用搜索引擎进行查询操作,但在引擎查询时往往通过查询关键词执行查询,因此会出现较多不需要信息,导致查询速率较低。提升数据库超文本查询的查准率与查全率,是目前需要解决的最大问题。因此对基于频繁项集挖掘的数据库超文本查詢算法进行研究,从而有效提高算法精准度。
1 基于频繁项集挖掘的数据库超文本查询算法
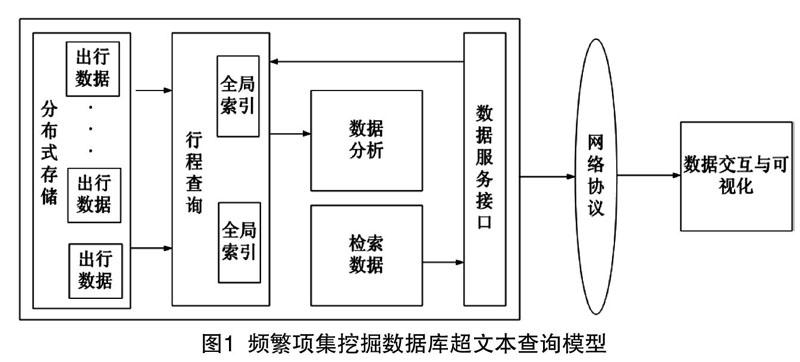
1.1 频繁项集挖掘数据库超文本查询模型
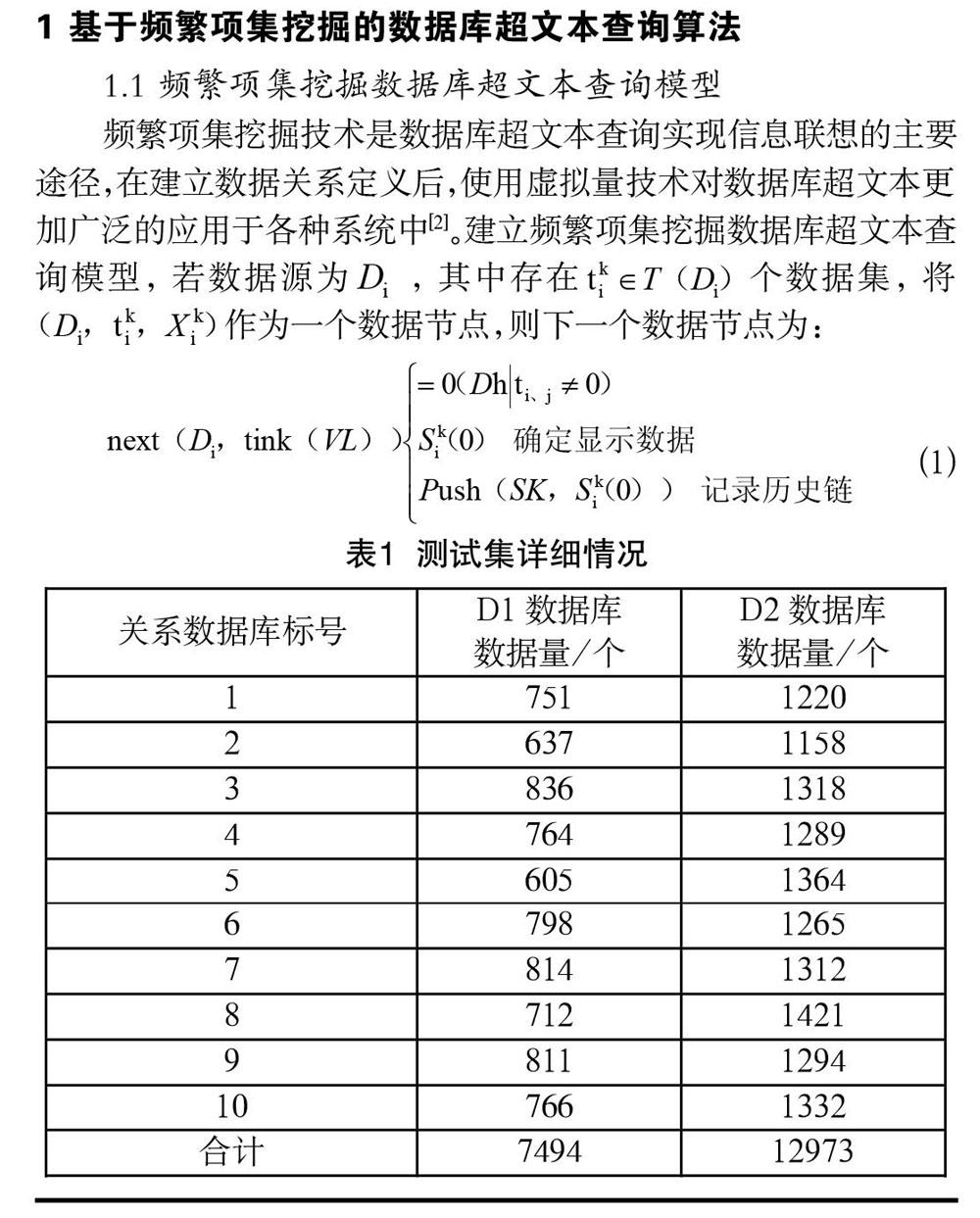
频繁项集挖掘技术是数据库超文本查询实现信息联想的主要途径,在建立数据关系定义后,使用虚拟量技术对数据库超文本更加广泛的应用于各种系统中[2]。建立频繁项集挖掘数据库超文本查询模型,若数据源为,其中存在个数据集,将作为一个数据节点,则下一个数据节点为:
2 仿真实验
2.1 实验准备
为基于频繁项集挖掘的数据库超文本查询算法的有效性,因此选择10个大型关系库作为测试样本,在各个数据中选取超文本,从而建立查询数据。通过建立分组小数据库,对数据库中关键词进行查询,从而得到800×10个超文本,将其形成分组小容量数据库D1;而在大容量数据库中采集1300×10个超文本,将其分为大容量数据量D2。利用数据库超文本查询精准度作为实验对象,分为两组。其中基于频繁项集挖掘的数据库超文本查询算法为实验组,传统查询算法为对照组。将各超文本中数据结果进行排列,其测试集情况,如表1所示。
2.2 查询精准度对比
通过大型关系数据库超文本查询,实现在查询过程中最大程度的对查询目标的相关信息寻找。对实验组与对照组之间的查询精准度进行统计比较,其结果如图2所示。
分析图2可知,在对相同目标进行查询条件下,实验组查询精准度与对照组查询精准度相比具有明显优势,且实验组查询精准度能够在保持较高水准,因此说明实验组查询算法具有更好有效性。
3 结语
频繁项集挖掘作为数据库超文本查询算法中较为重要的一项工作,在整体数据超文本查询过程中,将查询目标数据从频繁数据中挖掘出来,以数据集形式进行输出,从而减小数据所占查询空间。
参考文献
[1] 张素智,赵亚楠,杨芮.基于MPB-Tree索引的空间数据多关键词模糊查询算法研究[J].华中师范大学学报:自然科学版,2017,51(06):49-55.
[2] 顾荣,仇红剑,杨文家,等.Goldfish:基于矩阵分解的大规模RDF数据存储与查询系统[J].计算机学报,2017,40(10):2212-2230.
[3] 万木君.云计算环境下基于矩阵加密的查询算法研究[J].科技通报,2017,33(07):133-136.
[4] 焦润海,张谦,陈超.基于Spark改进的最大频繁项集挖掘算法[J].计算机工程与设计,2017,38(7):1839-1843.
[5] 田喜平,黄勇杰.基于关联规则的大型关系数据库超文本查询算法研究[J].科技通报,2018,34(10):109-112.
猜你喜欢
魅力中国(2018年5期)2018-07-30
文理导航(2016年30期)2016-11-12
生物学教学(2016年10期)2016-08-20
长春教育学院学报(2013年14期)2013-08-15
