
分支定界半监督SVM在油层识别中的应用
2019-09-05 10:44贺紫平夏克文潘用科
重庆邮电大学学报(自然科学版) 2019年4期
贺紫平,夏克文,潘用科,王 莉
(河北工业大学 电子信息工程学院,天津 300401)
0 引 言
在石油勘探与开发以及测井解释的过程中,通常采用测井解释工程师的经验进行油层识别。但其无法达到高效的推广油层解释工作的目的。为此不少学者将监督的人工智能方法,比如贝叶斯支持向量机[1]、量子粒子群优化的支持向量机(support vector machine based on quantum-behaved particle swarm optimization, QPSO-SVM)[2]、多核相关向量机(multiple-kernel relevance vector machine based on SOCP, MKRVM)[3]等应用到石油识别中,取得了不错的效果。由于有标签样本缺乏,传统监督预测模型存在着过拟合的问题。其次,获取有标签的石油数据需花费很大代价。半监督学习可以通过大量的未标记数据来改善分类器效果,训练在所有数据分布上都具有强泛化能力的模型。Shamanism和Landgrebe于1994年首次将半监督学习(semi-supervised learning,SSL)方法应用于卫星遥感图像分析中,而后SSL陆续在中文文本分类、视频、网页信息提取、图像分类、大规模图像检索等众多领域取得了成功应用。如Zhang等将基于图的SSL应用于视频领域研究[4]。Cheng等将粒子群优化算法(particle swarm optimization, PSO)优化的S3VM算法应用于中文文本分类[5]。Guilaumin等将多模态SSL用于图像分类[6]。Wang等将SSL散列法用于大规模图像检索中,取得了显著的性能提高[7]。Carlson等利用耦合的SSL在网页中提取有效的信息[8]。罗伟平等将最小二乘半监督SVM应用于海上石油识别,成功地对油层进行了准确预判[9]。文献[10]针对软件缺陷预测研究中类标签数据难以获取和类不平衡分布问题,提出基于采样的半监督支持向量机预测模型。王立国等将K均值聚类和孪生支持向量机相结合的半监督方法应用于高光谱图像分类中,最终缩短了整个分类过程中所需的时间,并提高了分类销量[11]。文献[12]提出了一种集成S3VM的方法,并将该算法应用于极化合成孔径雷达图像的地面覆盖分类。传统监督预测模型如QPSO-SVM在有标签样本过少时,易出现过拟合问题,导致预测精度低,最小二乘支持向量机(least squares support vector machine, LS-SVM)预测模型为降低求最优解的时间复杂度,却损失了SVM解的稀疏性。而S3VM算法则能仅利用少量标签样本训练得到较高预测精度的分类器,弥补了全监督算法的缺陷。但是,S3VM算法存在易陷于局部最优的问题,为此,许多学者提出了全局搜索技术[13]、分支定界(branch and bound)[14]技术、基于全局和局部保持的S3VM[15]、基于标记生成的WELLSVM[16]等技术方法。
Chapelle O等提出的分支定界算法可以在小样本上实现全局最优化,将其结合S3VM可以有效地避免S3VM陷入局部最优解,且可读性快,分类速度快[14]。为此,为提高石油预测精度和训练速度,提出一种基于分支定界半监督支持向量机的油层识别模型,并应用于实际测井中,以期获得更好的油层识别效果。
1 半监督SVM
统计学习的结构风险最小化准则和VC维理论使得SVM算法具有完备的理论基础,泛化错误率低,计算开销不大,结果易解释的优点。半监督SVM在SVM的基础上还能结合无类标签的样例提高算法预测的精度,是基于低密度假设与聚类假设的完美实现[17-18],近年来成为机器学习领域的热门研究方向。依照参数优化的差异,半监督SVM可以分为基于组合与基于连续方法2类,而本文BBS3VM算法则是一种经典的基于组合半监督SVM。
1.1 基于组合的半监督SVM
给定一组有标签训练样本集为
(x1,y1),(x2,y2),…,(xl,yl),xi∈Rd
假定为二分类,其对应的标签为
yi∈{+1,-1}
同时,给定无标签训练样本集为
U={x1,x2,…,xu},xi∈Rd
这里n=l+u为训练集的样本总数,有标签训练样本集与无标签样本集都属于同一分布,且相互独立。
则半监督SVM可以由(1)式描述为
(1)
(1)式中:向量yu为无标签样本集U的标签;C1表示有标签样本的惩罚因子;C2表示无标签样本的惩罚因子;ξi和ξj依次对应有标签样本与无标签样本的损失函数;ω表示基于预测标签yu对无标签样本进行分类时的最优超平面;b为偏移量。
首先,对无标签样本yu进行组合。其次,在其所有组合中采用全监督的SVM算法对其所有组合进行优化,最终得到目标函数的最优解,即最优组合。
若给定任意一组yu的组合,那么此时全监督模型的目标函数可以由(2)式表示为
(2)
此时半监督SVM的目标函数可以由(3)式表示为
(3)
s.t.yi(ωxi+b)≥1-ξi,i=1,2,…,l
yj(ωxj+b)≥1-ξj,j=1,2,…,u
1.2 分支定界
分支定界的主要思想便是采用深度优先原则遍历问题的解空间树的解方法,采用深度优先的分支策略,即依次搜索根节点的所有分支,对不满足约束条件的结点进行剪支,其余结点列为非叶子结点,继续进行分支训练,从非叶子结点子集中选择一个结点作为下一个根结点,继续搜索。
分支定界一般步骤如下:首先生成在根结点处的所有分支,即非叶子结点,其次再在非叶子结点集中选择下一个分支对象。以上的搜索过程需要耗费大量的时间,因此,为了加快搜索速度,并更加高效地挑选下一个分支对象,通过计算得到一些界限,首先只能通过这些界限从当前的非叶子结点集中选择一个最可靠、最有利的结点作为下一个分支对象,即下一个根结点;其次,将不满足界限条件的分支剔除于非叶子结点集中,缩小非叶子结点集范围,加快分支速度,最后使得当前解逐步往最优解的分支上前进。
1.3 平衡约束
在半监督学习中,很难仅通过少量的有标记样本直接预测大量无标签样本集中的样本标签分布情况,从而或多或少存在数据不均衡的问题,容易将所有的无标签样本划分为一个类别,为此专家们提出了一个可以尽可能使无标签样本划分到2个类的平衡约束。本文为简化计算,令C1=C2,设置无标签样本集的二分类样本比例为r,但由于其标签是未知的,因此r通常用有标签样本集中的二分类样本比例来估计,如(4)式所示
(4)
(4)式中,标签样本与无标签样本的样本总和由n=l+u计算得到。
2 分支定界半监督SVM
2.1 基本原理
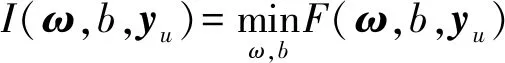
1)标记:首先在给定的有标签样本集L上进行SVM训练得到目标函数值,作为分支定界树的根结点,其次从无标签样本集中选择样本对其进行标注,并分别计算预测标签不同时,此时的目标函数值。
2)分支:由于分支定界是从深度优先的方式搜索解空间树,所以需要不断的更新其上界与下界,从而获得一个尽可能紧的界限,有利于快速的修剪分支,去除非可行解的子集,从此时的最优解集中选择一个子集,对其进行分支操作。
在给定节点上,一些无标记的点已经被标注了一个标签,如何挑选最不容易出错的,最可靠的无标签样本作为下一个分支标注对象,在算法的迭代中非常重要。若挑选一个易错分的样本进入训练,得到其标签后加入有标签训练集即等同于加入了噪声样本进入训练过程,将会降低分类准确率。此处引入对无标签样本的置信度准则,如果一个未标记点距离另一个标记点最近,那么使用最可靠的距离度量,计算2个点之间的距离,就可以对无标签样本进行标注。本文采用了一种更加可靠的度量方法,其主要思想是如果一个标签样本的标签是可靠的,那么当给这个有标签样本一个相反的标签时,此时的目标函数值会大大的增加。根据此思想,就可直观的挑选使目标函数值增长最大的那个样本与此时假定赋予该样本的标签,那么就可认为该标签为下一个进行训练的对象,其预测结果即为与此刻标签相反的标签。
其算法描述为,给定当前有标签样本集L,无标签样本集U,令s(L)为此时在训练集L训练得到的SVM的目标函数值,可以由(5)式表示为
(5)
(5)式中,ξ可以由(6)式表示为
ξ=max(0,1-yi(ω·xi+b))2
(6)
现在就在无标签样本集U中选择一个样本点,那么有
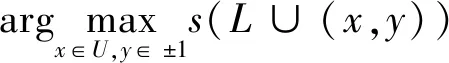
(7)
根据(7)式挑选出使目标函数增长最大的无标签样本x和此时对应的标签y,该点就为最不容易错分的样本点,并给其标注为-y。
3)定界:分支定界算法中上界(upper bound, ub)与下界(lower bound, lb)的定义决定剪支与分支的情况,一个好的上界与下界能够快速修剪非可行解的分支,加快训练速度。
定义1分支上界。
初始化时,上界ub=∞ 。随着全局搜索的进行,在叶子结点上,在分支定界半监督支持向量机中,上界ub简单定义为此刻半监督支持向量机目标函数的最优解Imin(ω,b,yu),可以表示为
ub=Imin(ω,b,yu)
(8)
(9)
(9)式中,k为叶子结点总数。
而非叶子结点则不存在上界。
定义2分支下界。
当C2=0时的半监督支持向量机目标函数值小于当C2>0时的值,然而c2=0时,半监督支持向量机为一个标准的监督支持向量机,没有考虑无标签样本的影响。为此,首先,要计算在给定的有标签样本集上的标准支持向量机的目标函数值,得到一个初始的下界。此时,可构造一个对偶的半监督SVM的目标函数为
s.t.
αi≥0
∑αi=0
(10)
随着对解空间树的搜索,无标签样本开始加入训练,计算得到无标签样本的标签yu,并构造一个满足(10)式中约束条件的向量yu。此时,任意满足约束条件的yu都有

令Q(yu)=D(α(yu),yu) ,那么此时下界lb就可以由(11)式表示为
lb=minQ(yu)
(11)
对于所有的叶子结点,该结点上的所有样本都已经被标签,故lb同时也是在该节点上的目标函数的值,即lb=ub。
对于非叶子结点,其下界就是要找到一个yu的组合,使得下界可由lb=minQ(yu)计算得到。
首先在有标签样本集上进行SVM训练得到初始分类器SVM0以及向量α;其次,将无标签样本在初始分类器SVM0里训练,获得其预测标签yu;最后,根据yu向量α(yu),D(α(yu),yu)就可计算得到该非叶子结点的下界lb。
4)剪支:根据以下原则对现分支定界树进行剪支,删除不可行的分支子集,再对剩下的分支子集进行分支。
原则1如果当前的结点的下界大于全局分支定界中的上界,那么剪支。
原则2如果当前结点的样本集不符合平衡约束,那么剪支。
最后,当所有无标签样本都被标记时,则得到最终最优解,即最优组合。
2.2 算法实现
分支定界半监督SVM算法实现如下所示。
输入:有标签样本集L;
无标签样本集U;
混合标签Y:有标签样本集标签与先设定为全0的无标签样本集标签;
初始上界ub=∞;
输出:无标签样本集的预测标签Y*;
相对应的目标函数值v;
步骤1初始化,计算目标函数值,得到上界ub及下界lb。
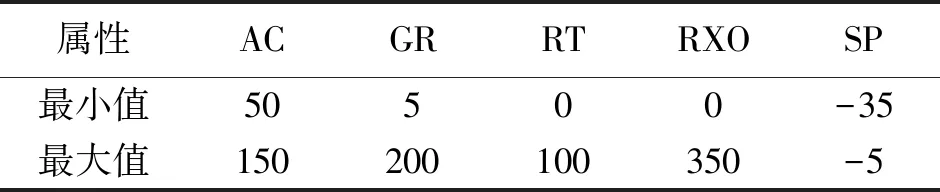
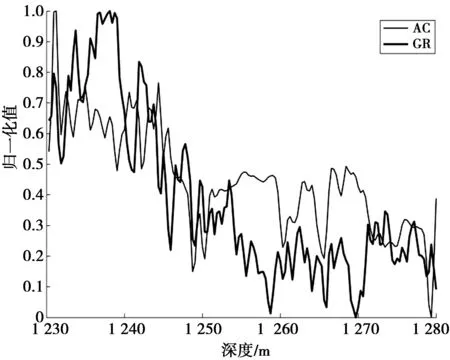
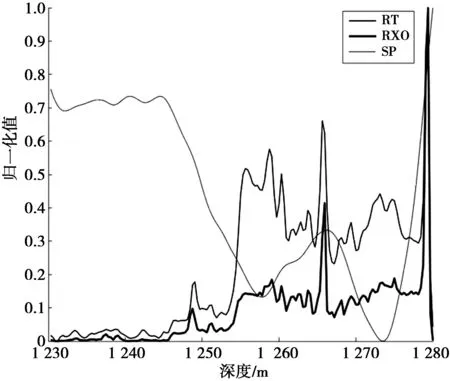
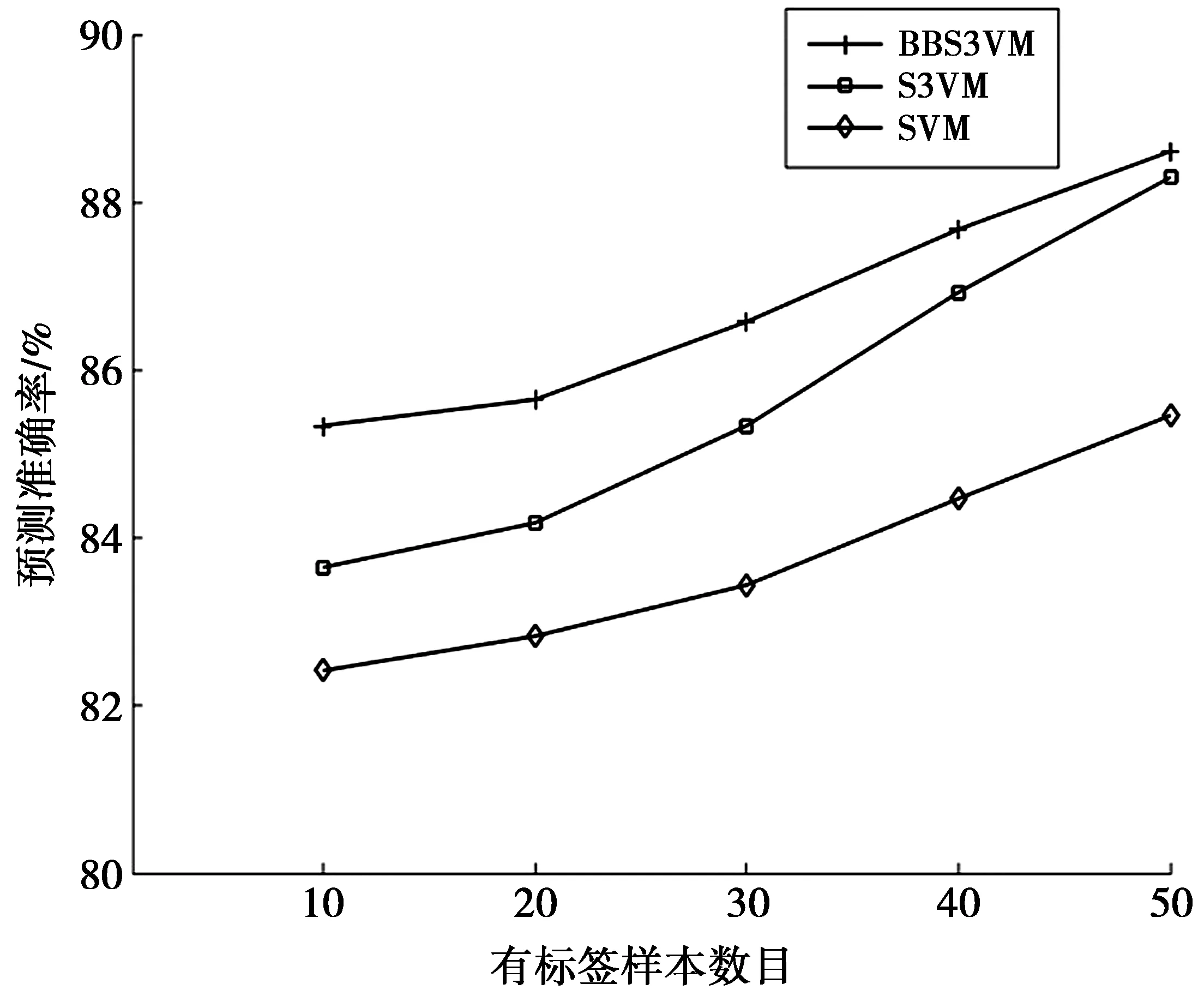
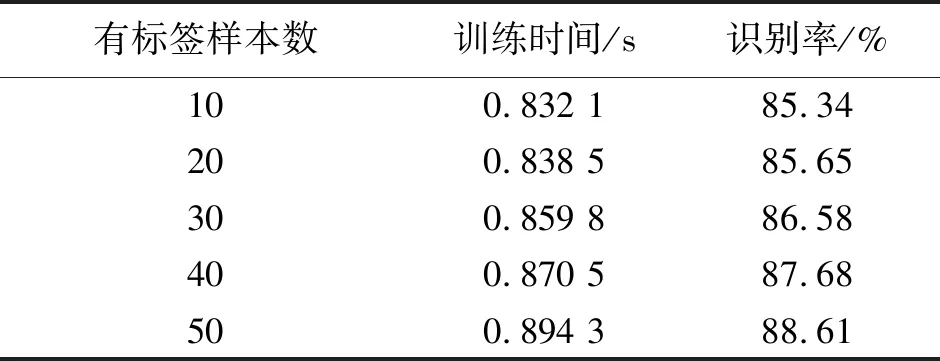
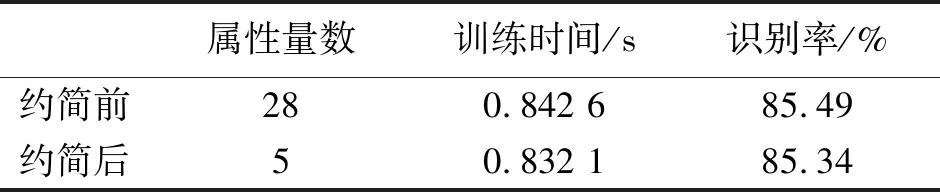
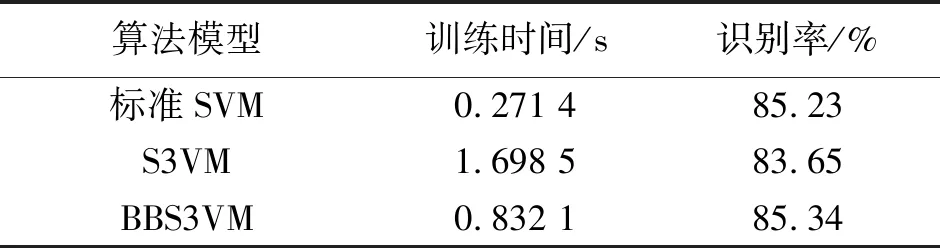
if ∑max(0,Yi)>urOR ∑max(0,-Yi) return%平衡约束条件不满足 endif%剪支 v=SVM(Y) %计算在训练样本集L上训练得到 SVM的目标函数值 步骤2判断,根据分支及剪支原则对结点进行剪支或分支操作。 ifv>ub then return%下界大于上界 endif%剪支 ifYisfulllabeled then Y*=Y Return%得到叶子结点 endif 步骤3计算无标签样本置信度,选择置信度高的作为下一个标注样本。 Findindexiandlabelyasin(7)%寻找下一个标注的无标签样本 Yi=-y%从置信度最高的样本开始标注 步骤4解得最优解,并输出及v (Y*,v)=S3VM(Y,ub) %解得此时的最优解 Yi=-Yi%切换标签 ifv2 end if 分支定界半监督SVM油层识别模型如图1。 图1 分支定界半监督SVM油层识别模型Fig.1 Oil layer recognition model by BBS3VM 油层识别主要有如下几个步骤。 ①样本信息选取及预处理:首先,应该选择具有和油层紧密联系的信息的样本;其次,为避免计算饱和,将样本进行归一化处理。 ②属性离散化和泛化:分别用0、1表示油层与干层,则有决策属性D={d},d={di=i,i=0,1},然后将选取的样本进行决策属性泛化,且使用曲线拐点方法每个属性各自单独离散化。 ③样本信息属性约简:通常,比较完善的测井数据至少有10余种测井信息,然而大多数数据中都存在冗余且充分的属性,为此采用基于属性重要性的简约算法进行约简。 ④分支定界半监督SVM算法建模:在BBS3VM模型中,输入经属性约简后的样本信息,采用S3VM算法进行训练,对无标签样本进行标注,同时利用分支定界算法加快求解速度和精度,最后得到BBS3VM分类模型。 ⑤识别输出:在整个井段利用最终训练所得半监督识别模型进行油层识别,从而得到输出结果。 本文选取同课题组LIU Liu等成功验证和应用过的某油井真实数据进行训练和测试[19]。该油井实际测得28个属性信息,分别为{AC,CNL,DEN,GR,RT,RI,RXO,SP,R2M,R025,BZSP,RA2,C1,C2,CALI,RINC,PORT,VCL,VMA1,VMA6,RHOG,SW,VO,WO,PORE,VXO,VW,AC1},约简后得到{AC,GR,RI,RXO,SP}5个属性。 从井段1 230~1 270 m提取160个测井数据作为训练集,包括油层46个,干层114个,属性信息约简后得到{AC, GR, RI, RXO,SP}5个属性。使决策属性D={d},d={di=i,i=0,1},0,1分别表示干层和油层。将在训练机上训练好的预测模型对井段1 200~1 280 m的641个样本进行油层识别,属性在全井段的归一化范围如表1。 表1 属性在全井段的归一化范围 将约简后的属性在井段1 230~1 270 m间进行归一化处理。图2为属性AC与GR的归一化处理。 图2 AC属性与GR属性归一化处理Fig.2 Normalization attribute AC, GR 图3为属性RT,RXO与SP的归一化处理。其中:X轴代表油井深度;Y轴代表归一化值。 实验1有标签样本数目对半监督算法的影响。 为考虑有标签样本集数目对半监督算法的分类准确率与速度的影响,将分支定界半监督SVM与经典S3VM算法及标准SVM算法进行对比。为使预测结果更加可靠,并验证其具有强泛化能力,本文采取随机抽取并划分有标签样本集与无标签样本集的方式来构成训练集。有标签样本集分别由从原始的训练集中随机的抽取数目为10,20,30,40,50的样本及其标签构成,其余的训练集样本去除标签,与其对应的作为无标签样本集。其中,标准SVM算法只选取划分好的有标签样本集作为其训练集。经过10次独立重复实验取平均值,得到2种半监督算法与1种全监督算法的训练精度对比如图4。分支定界半监督SVM的训练时间和精度数据如表2所示。表2中训练时间是在CPU为Intel Core i7,内存为16GB的计算机上的训练时间。 图3 RT,RXO与SP属性归一化Fig.3 Normalization attribute RT, RXO, SP 图4 预测准确率对比Fig.4 Comparison on predictive accuracy 由图4可以看出:①随着有标签样本数目的增加,3种半监督模型及监督模型的分类准确率都越来越高,但分支定界半监督SVM模型增幅更为稳定,且在有标签样本越少时,本文的算法模型与经典S3VM算法相比,预测精度更高。而2种半监督算法模型由于无标签样本加入训练,皆比只采用有标签样本进行训练的SVM算法预测精度高;②在有标签样本数目较多时,依据此时的训练集,2种半监督算法都可以训练得到一个性能好的分类器,因此,2种半监督算法分类准确率趋于一致。而监督的SVM算法由于仅使用有标签样本进行训练,预测精度仍随着有标签样本数目增加而逐步提升。 表2 性能指标比较 从表2的数据可知,当有标签样本数目增加时,模型的训练时间也有所增加,这是由于若有标签样本训练集增大,那么进行初始SVM训练得到初始分类器的训练时间也将跟着增加,分类精度更好,即相对应的油层识别率随着有标签样本的增加而稳步提高。增加有标签样本集样本数量,即提高了由有标签样本训练得到的初始分类器的分类精度,而后能够对无标签样本进行更好的预测,减少噪声样本的加入。 总之,有标签样本数目的增加,能够小幅度地提高分支定界半监督SVM的分类识别率,且能够更好估计无标签样本集的2类标签分布,但仅采用少量有标签样本(10个)时,训练精度与采用大量有标签样本(50个)时分类识别率差别不大,满足半监督学习的理论效果。 实验2属性约简前后对比。 为验证测井数据属性约简的有效性,在属性约简前后分别对井段1 190~1 290 m的641个样本的分类结果进行了对比和分析,如表3。 表3 识别结果 分支定界半监督SVM的训练集由10个有标签样本,150个无标签样本构成。由表3可知,经过属性约简后的数据略微的提高了算法的训练时间,但稍微的降低了识别率。 实验33种算法比较。 图5 油层识别结果Fig.5 Results of oil layer recognition 最后将在训练集上训练好的以上3种识别算法模型在井段1 190~1 290 m的641个样本进行油层识别。比较3种算法在真实石油测井数据上的分类效果,如表4。 表4 几种模型的识别结果 从表4可得出结论,同半监督的SVM相比,在同样的样本选择的情况下,本文的BBS3VM算法训练时间更快,且识别精度更高,比半监督SVM具有更好的应用前景。同全监督的SVM相比,由于BBS3VM需要进行多次SVM运算,所以训练时间要略长于标准SVM,而识别率能与标准SVM保持很接近,则可表明,本文的BBS3VM算法能够仅使用少量的有标签样本,就能达到与全监督接近的识别效果,降低了对标签样本的依赖程度,具有广泛的应用前景。 针对传统的监督SVM算法对有标签样本依赖性太强,且石油测井中标签样本获取难度大的缺点,本文使用分支定界算法优化的半监督支持向量机油层识别模型,使无标签样本的标签预测更准确,其次加快了训练速度,提高了分类精度。此方法应用于油层识别时,分类效果好,在使用少量有标签样本的情况下,提高了识别率,减少了样本提取代价,明显优于其他2种算法,具有很好的应用前景。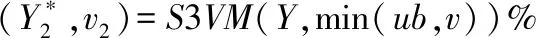

3 油层识别应用
3.1 油层识别基本模型

3.2 实例分析


4 结束语
猜你喜欢
建材发展导向(2022年3期)2022-04-19房地产导刊(2022年4期)2022-04-19电子制作(2022年1期)2022-01-28电子制作(2021年14期)2021-08-21石油化工应用(2020年2期)2020-03-18西南石油大学学报(自然科学版)(2018年5期)2018-11-06西南石油大学学报(自然科学版)(2018年1期)2018-02-10北京航空航天大学学报(2017年3期)2017-11-23特种油气藏(2016年2期)2016-12-20中国土地科学(2010年11期)2010-03-20
