
POF-ICN架构中的边缘缓存研究
2019-09-09 03:38吴超群
小型微型计算机系统 2019年9期
李 平,王 雷,吴超群
(中国科学技术大学 自动化系,合肥 230026) (中国科学院 电磁空间信息重点实验室,合肥 230026) E-mail:flat@mail.ustc.edu.cn
1 引 言
ICN(Information centric networking,信息中心网络)[1]以信息和内容的名字作为网络协议的核心,通过内容与位置分离以及网内缓存的方式满足大规模内容分发和移动性支持等需求,是未来网络的候选方案之一.但现有研究中的ICN架构,大多基于内容的层次化名字进行路由,以内容路由器形式组建网络,无法与现有网络基础设施兼容.随着SDN(Software-Defined Networking,软件定义网络)的发展,交换机可以支持更复杂的网络协议,SDN与ICN的结合逐渐成为未来网络的研究热点[2].POF(Protocol-oblivious forwarding,协议无感知转发)交换机支持任意自定义协议以及对本地存储的访问[3],以此为基础的POF-ICN网络[4,5]成为具有代表性的SDN融合ICN架构.
POF-ICN网络采用混合路由机制,其核心设计思想之一是仅在网络边缘使用内容名字进行路由,并依托边缘缓存实现内容的高效访问.边缘缓存的提出最早见于文献[6],与ICN结合的缓存云则是在雾计算以及物联网兴起的背景下,如文献[7]提出的架构,融合雾计算使得ICN的缓存无处不在.但目前国内外研究主要集中在边缘架构方面,文献[8]提出三层的移动边缘ICN云架构,由本地云和全球云混合提供面向物联网设备的服务从而有效降低核心网的负载,以及在车载移动云环境中应用ICN[9],并提出了适用场景以及研究方向等.边缘缓存的应用使得数据更贴近用户,也更适合小范围自组织的网内传播,文献[10]中论述了ICN中边缘缓存的理论模型与性能优越性,但没有给出明确的实际应用场景.
ICN与SDN结合的核心问题是如何把ICN网络行为映射到转发平面,换句话说,是如何把以内容名字为中心的路由过程在控制器上表示成转发规则,并将其转换成交换机流表,在转发平面上实现对内容和内容缓存的访问.Hash路由技术在过去的研究中被用于企业网络[11]中确定内容放置和检索以减小响应时延,通过哈希函数将内容标识符与放置位置建立映射关系,在ICN中类似的技术同样用来管理内容与路由节点的映射关系,文献[12]研究了ICN中考虑重定向成本的哈希路由策略以及路径选择机制,并验证了哈希路由方案可以提高ICN中的缓存空间利用率和缓存命中率.文献[13]中提出的哈希路由方案则通过对内容名字的哈希结果以及缓存归属划分来决定转发目的地.以上这些ICN中的哈希路由方案问题在于需要内容交换机节点支持哈希运算功能或是由集中代理来帮助路由请求重定向,并且转发节点的计算代价以及重定向代价可能会带来过高的时延.
本文基于POF-ICN架构,提出一种POF内容交换机边缘网络模型,以及对应的内容路由与缓存机制,实现了靠近用户端的低时延、高效率的内容分发.
2 POF-ICN架构中的边缘缓存机制
2.1 POF-ICN网络架构
POF-ICN架构中,靠近用户端的边缘网负责内容缓存及面向用户的内容分发,主干网用于连接分散在各地的边缘网,如图1所示.
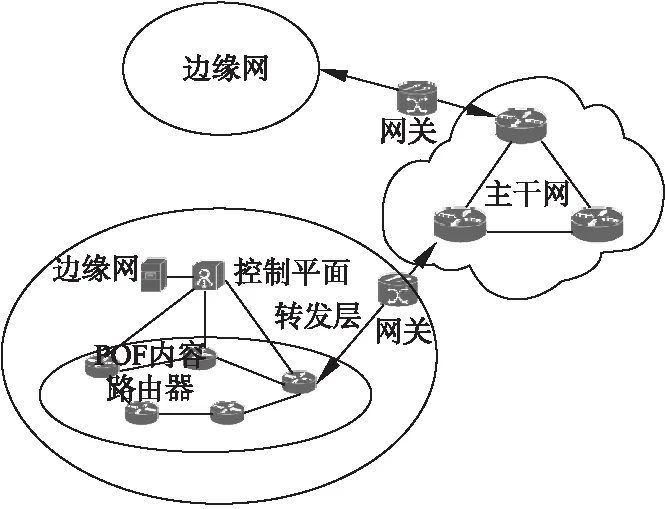
图1 POF-ICN架构示意图Fig.1 POF-ICN architecture
由于主干网主要承担的是网间数据传输,只需要考虑域间路由,链路明确而简单,因此可以使用IP路由、源路由等成熟的路由协议.而在边缘网中使用ICN协议降低请求时延、提高缓存使用效率和命中率,边缘网和骨干网之间则使用IP-ICN网关进行协议转换[14].
边缘网的设计很好体现了SDN与ICN融合的优势,其中控制平面只需决定内容与POF内容交换机的映射关系以及转发策略,而转发平面则通过灵活的协议字段匹配以及多级流表实现内容路由及缓存.POF控制器承担边缘网络的信息整合和控制管理功能,为POF内容交换机的转发模块下发流表,使得POF内容交换机识别ICN数据包并依据规则进行相应动作.POF内容交换机主要包括流表转发模块以及缓存空间实现,承担了对内容的路由和缓存功能.
2.2 边缘缓存方案
在ICN中,缓存机制与路由方案紧密联系,因此,本文提出的缓存机制同时也是边缘网络中一种路由方案的实现,在本节中一并介绍.
哈希路由是能够有效实现边缘网络中缓存内容映射并提供快速路由机制的方法.最简单的如取模不能满足一致性哈希,以往的ICN路由机制中也缺乏有效的实际哈希方案.动态的方案如信标环方案[15]可以对缓存内容动态分配从而实现负载均衡,然而针对所有内容的动态分配会引入过高的管理开销和时延.
内容寻址网络(CAN)[16]是结构化对等网络的一种实现,通过分布式哈希表实现内容与存放位置的映射,具有可拓展性、容错性、完全自组织等特点.本文基于其对内容编址的思想,利用协议无感知转发技术,设计实现了一种POF-ICN架构中的边缘缓存机制.
首先,在边缘网络中建立内容和节点的坐标映射关系,在POF-ICN数据包中,采用定长哈希值的二进制扁平化命名方式来提高命名空间利用率并统一转发规则,由128位全局唯一标志GUID来标识内容,从中选取B位构建出二维坐标,如图2所示.
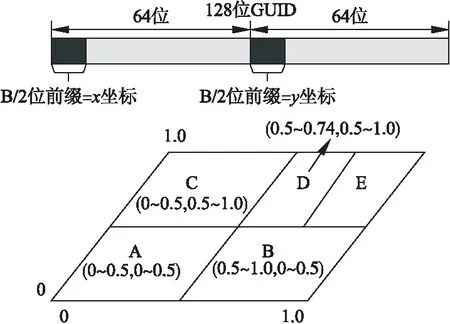
图2 构建内容编址空间Fig.2 Building content addressable space
POF控制器根据边缘网络拓扑建立坐标空间,从而使每个内容都映射到边缘网络中唯一节点,且坐标空间与物理拓扑有序对应.控制器根据节点拓扑制订转发策略,为POF内容交换机写入相应流表,使其对ICN报文中的GUID掩码匹配,通过匹配实现向同层节点或下层节点转发.
2.3 POF内容交换机转发流表生成算法
POF-ICN边缘网络中POF内容交换机集合为CR,总数为V,边缘网络假设为n层结构化拓扑,每层的POF内容交换机个数为{V1,V2,…,Vn},首先确定从GUID中选取的坐标位数B,需满足以下条件:
(1)
(2)
2B≥V
(3)
全局拓扑G={gi,j|1≤i≤V,1≤j≤V}由POF控制器与POF内容交换机建立连接后获取,流表生成算法步骤如下:
步骤1.根据边缘网络拓扑层数n以及每层POF内容交换机个数{V1,V2,…,Vn},确定B;
步骤2.对每层的POF内容交换机,根据每个POF内容交换机的转发和缓存能力进行排序,通过贪心算法分配编址空间,得到编址空间映射关系A={ai|1≤i≤V};
步骤3.对每个POF内容交换机节点CRi,根据编址空间映射关系ai生成STORE_TABLE中的流表项;
步骤4.根据全局拓扑G,由Floyd算法求出所有POF内容交换机节点两两之间最短路径P;
步骤5.对每个POF内容交换机节点CRi,根据编址空间映射关系A和最短路径P,得到GUID对应的下一跳转发端口,生成INTR_TABLE中的转发流表项.
在流表生成算法中,步骤2的排序部分时间复杂度为O(V2),贪心算法分配编址空间的时间复杂度为O(V),步骤4中的Floyd算法时间复杂度为O(V3),因此整个流表生成算法的时间复杂度为O(V3),考虑到在POF-ICN边缘缓存机制中流表可以在预部署阶段生成,无需实时计算,故时间复杂度满足要求.
POF控制器下发的流表指定POF内容交换机对自定协议报文的不定长域进行匹配动作.这里只关注两个字段:ICN报文类型,GUID.控制器对边缘网络中的每一个POF内容交换机,根据划分的坐标区域下发各自的多级流表,其中定义了对不同类型的ICN报文的操作,其中ICN_TABLE为对ICN协议报文类型的判断,分别为兴趣包、数据包等.STORE_TABLE负责根据GUID中的坐标位匹配判断内容是否属于本节点的内容编址区域,INTR_TABLE为实际的路由转发表,根据GUID中的坐标位匹配判断下一步转发的端口,PIT表类似CCN中的PIT表,负责记录经过的请求信息,使得数据包按照PIT一步一步转发回请求者,PIT表的添加和删除操作由POF内容交换机根据匹配到的ICN报文进行相应ADD ENTRY和DELETE ENTRY动作.流表示意图如图3所示.
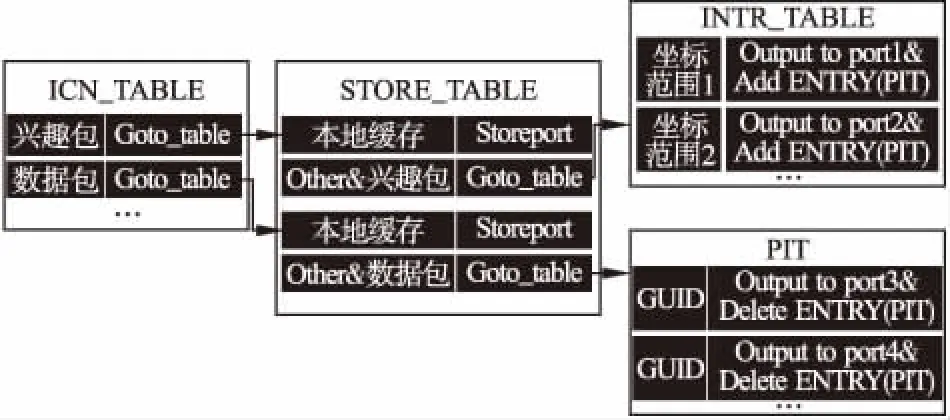
图3 POF内容交换机边缘缓存流表示意图Fig.3 Edge caching flow table in POF content switch
2.4 边缘网络内容请求流程
POF-ICN架构边缘网络中具体的请求内容流程如图4所描述,当内容发布到边缘网络之后,对内容的请求会被POF内容交换机逐跳转发直至到达内容对应编址空间的归属节点,并不断更新路径上节点的PIT流表,在POF内容交换机的缓存模块中,通过布隆过滤器快速查询缓存是否命中,从而优化缓存查询的时间和空间效率.缓存命中后,响应的数据包可以通过PIT表转发回请求者;而当缓存未命中时,则需重定向至内容源或者跨域请求,可采用重定向流表或POF-ICN中其他路由机制[4,5]等.
在控制器初次下发流表之后,边缘网络即可进入快速自组织响应路由阶段,可以减轻主干网流量压力,快速响应边缘区域用户请求.由于空间划分基于真实网络拓扑层次,比起P2P中完全逻辑化的路径规划,保证了逐跳的高速性.此外,由于其结构化的物理拓扑与内容寻址空间映射,有利于实现POF流表的掩码匹配转发规则,不需要内容交换机节点进行复杂的哈希运算,实现边缘网络中的高效快速路由,从而满足POF-ICN内容分发场景下的用户需求.

图4 请求内容的处理流程Fig.4 Process of requesting content
2.5 可拓展的映射关系
利用内容寻址网络的思想,对需要缓存的内容与节点之间建立映射关系,最简单的例子即为划分均匀的空间范围,每个区域对应一个内容交换机节点,在这种情况下所有的缓存内容均匀分布在边缘网络中的各个节点中.然而在实际的内容传输场景并非如此,首先,内容交换机节点的处理能力有所不同,核心节点具有更大的缓存和更高的转发速度;其次,内容具备一定的流行度,在网络研究中通常认为内容流行度服从齐普夫分布[17].
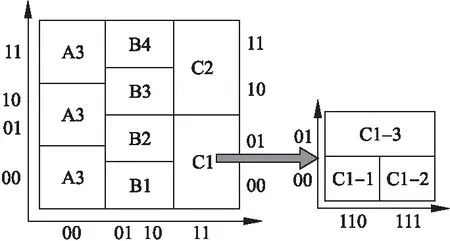
图5 可拓展的内容编址映射Fig.5 Scalable content addressing map
本文提出的边缘缓存机制可以通过可伸缩的映射关系来实现节点的负载均衡,比如一个内容交换机节点可以负责多片坐标编址区域.POF内容交换机灵活的转发处理能力以及控制器的集中管控能力允许灵活地从GUID中选择可变长度作为坐标空间映射的依据,如图5所示,一个区域很容易拓展为多个小区域,交由多个内容交换机节点负责,从而实现有弹性的缓存机制.同时,即便某个节点负载过高,也可以将原本负责的缓存区域向与周围的邻居节点重新规划,由于原本的内容编址方案基于物理拓扑,因此引入的重新规划开销在可控范围内.
3 实验分析
本节通过仿真实验来验证本文提出的边缘缓存机制的性能.实验环境:操作系统为Ubuntu 14.04.1 LTS,CPU为Intel Pentium CPU G860 3.00GHz,内存为4GB.采用具有70个节点的结构化拓扑来模拟边缘内容分发网络,每个内容交换机节点具有相同的缓存能力为C,设置1个内容源节点模拟向边缘网络中发布内容.假设内容种类为2000个,且大小相同为1MB,内容的流行度服从齐普夫分布,齐普夫分布参数为α,范围为0.5到1.5.模拟用户在靠近接入网的一侧产生对内容的请求,且请求速率服从泊松分布,整个仿真过程总共完成1000000个请求.同时,本文选取ICN中的几种常用缓存策略作为对比,分别为:LCE,LCD[18],Probability(p=0.5)[19],ProbCache[20].缓存替换策略则均采用默认的LRU.选取平均时延和缓存命中率作为性能指标.
实验结果及分析如下:
如图6和图7所示,zipf参数为0.6时,当节点缓存能力C小于15,边缘缓存机制中受节点缓存能力限制,缓存替换较为频繁,大部分请求仍需到内容源获取内容,此时哈希路由带来的重定向路径开销会导致边缘缓存平均时延较高,甚至差于其他缓存策略.而当C逐渐增加时,边缘缓存机制具有更好的表现,C=30时,边缘缓存机制比最差的LCE提升了23%,比LCD也提升了12.3%.当C大于40后,边缘缓存达到了性能极限,之后性能趋于平稳,当然此时整个拓扑中的缓存能力已经大于所有内容容量,现实场景很难出现这种情况.而在缓存命中率方面,边缘缓存则由于采用了类似哈希的协作缓存方式,所有的内容被均匀缓存在整个边缘网络中,因此缓存命中率具有明显优势.
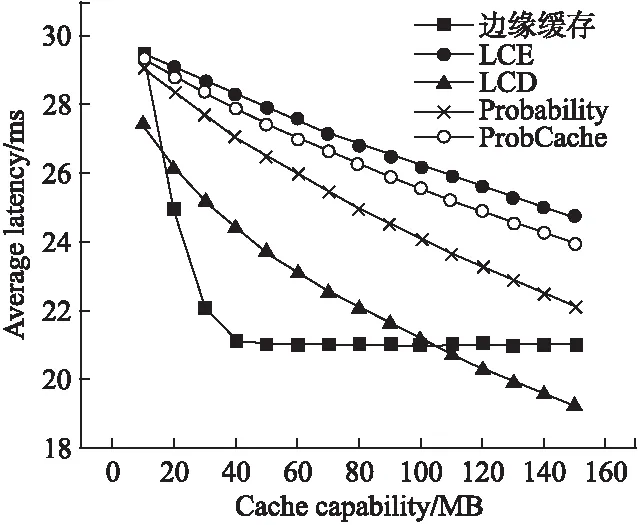
图6 平均时延随节点缓存能力变化(α=0.6)Fig.6 Average latency varies with cache capability(α=0.6)
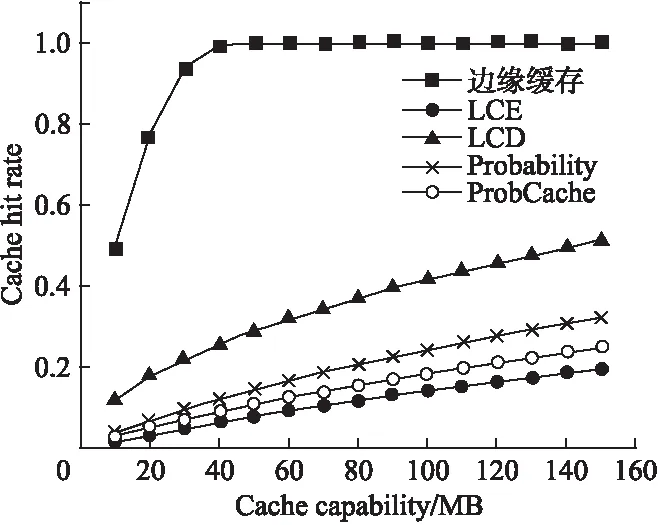
图7 缓存命中率随节点缓存能力变化(α=0.6)Fig.7 Cache hit rate varies with cache capability(α=0.6)
从图8和图9中可以看出,边缘缓存由于采取了哈希路由的策略,内容与缓存节点映射较为均匀一致,当zipf参数增长时,对最流行的内容的请求占了绝大多数,此时其他几种缓存策略会将流行内容缓存到多数节点,用户能在最近的节点获取到最流行的内容,平均时延显著减少.而边缘缓存则对内容流行度较不敏感,性能总体比较稳定,zipf参数大于1时,平均时延指标明显落后于其他的缓存策略.但是应当注意到,当zipf参数较小时,对内容的请求分布较为均匀,边缘缓存的缓存命中率大幅领先于其他策略.当zipf参数为1时,边缘缓存的平均时延比LCD高27.5%,缓存命中率却比LCD高70.2%.这说明在zipf参数较大时,边缘缓存策略通过牺牲部分性能,避免缓存的频繁替换,大幅提高了边缘网络的缓存系统的稳定性.
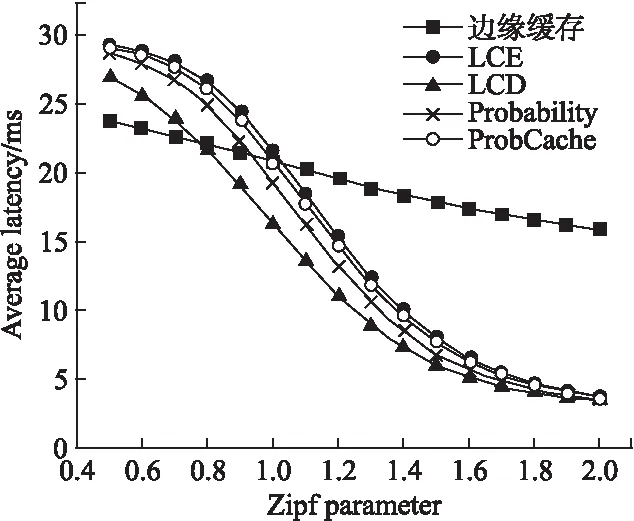
图8 平均时延随齐普夫参数变化(C=25)Fig.8 Average latency varies with Zipf parameter(C=25)
POF-ICN作为一种融合SDN的ICN架构,控制开销也是衡量网络性能的重要指标之一.交换机与控制器之间的控制开销包括数据收集成本,数据包PacketIn成本以及流表更新成本.利用Obadia M等人提出的控制开销模型[21],对边缘缓存机制的控制开销进行仿真实验分析,选取普通SDN路由(控制器根据PacketIn消息为请求规划路径)以及简单的哈希路由(取模)作为对比,交换机的流表项采用LRU策略更新.
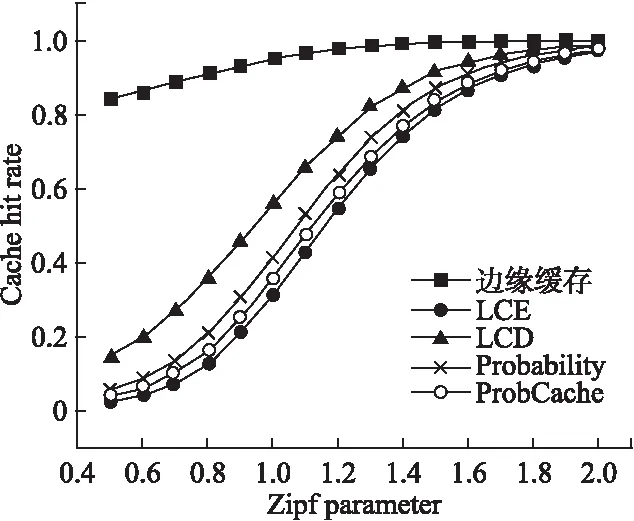
图9 缓存命中率随齐普夫参数变化(C=25)Fig.9 Cache hit rate varies with Zipf parameter(C=25)
图10反映了不同的路由策略下,控制开销随请求次数增加的情况.对于边缘缓存和简单的取模哈希路由,当缓存容量较低时,由于额外的路径开销以及频繁的缓存替换,其控制开销基本呈线性增长趋势,相较普通SDN路由并无优势.而当缓存容量充足时,边缘缓存和取模哈希路由的控制开销增长趋缓.相比于取模哈希路由,边缘缓存因针对内容空间编址,流表项聚合效果显著,能够有效降低约40%的控制开销.
4 结束语
本文分析研究了POF-ICN架构中的边缘内容分发问题,综合ICN网内缓存的特性、哈希路由中的内容映射以及POF协议无感知技术,提出了一种边缘缓存机制,该机制在改善传统缓存策略LCE、LCD的冗余和低效问题的同时,具备相当可靠的性能,能够满足POF-ICN场景下大规模内容分发的需求.仿真实验表明,在缓存命中率指标下,边缘缓存明显优于其他策略,在平均时延指标下,齐普夫参数较小时具备较好的性能且较为稳定,且相比于简单的哈希路由,能有效地降低控制开销.未来将考虑结合边缘缓存的可拓展映射机制,保证边缘缓存效率的同时,针对流行内容集中的情况进一步优化,提高边缘网络整体内容分发质量.
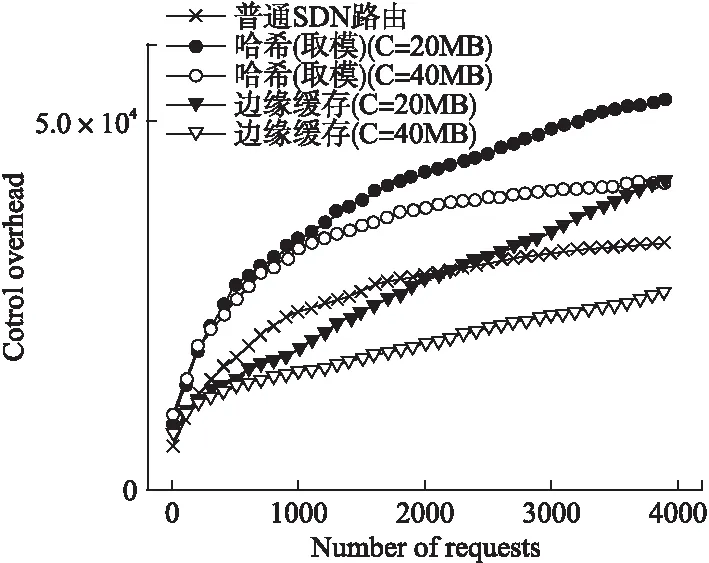
图10 控制开销随请求次数变化(α=0.6)Fig.10 Control overhead varies with requests(α=0.6)
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
数码世界(2020年11期)2020-11-23
电脑爱好者(2020年20期)2020-10-22
计算机与网络(2020年9期)2020-07-29
传播力研究(2019年24期)2019-10-21
网络安全和信息化(2019年7期)2019-07-10
电子制作(2019年24期)2019-02-23
科技与创新(2018年1期)2018-12-23
