
Attention机制在脱机中文手写体文本行识别中的应用
2019-09-09 03:38王馨悦董兰芳
小型微型计算机系统 2019年9期
王馨悦,董兰芳
(中国科学技术大学 计算机科学与技术学院,合肥 230027) E-mail:wxy66@mail.ustc.edu.cn
1 引 言
随着计算机技术的不断发展,人们越来越依赖计算机来接受和处理信息,将纸质文档中的信息转换到计算机中,能够更方便的存储、编辑和管理信息.纸质文档的数据量十分巨大,而目前主要是通过人力来完成转换,大大降低了工作效率.如果让计算机自动识别,便可以在很大程度上提高工作效率,降低人力成本,具有重要作用.
与中文印刷体相比,手写体字符的书写随意性大,缺乏规范性.出自不同书写者的同一类汉字在字形、结构上都会有明显的差异;并且相邻汉字之间会存在粘连,增加了识别的难度.与英文手写体相比,汉字种类繁多,根据GB2312-80标准,汉字共有6763个,其中包括一级汉字3755个,二级汉字3008个,同样给中文手写体识别增加了难度.因此,中文手写体识别仍然是一个具有挑战性的研究课题.
对于脱机手写体文本行识别,主要包括分割成单个字符的识别和整行识别两种方法[1].对于分割成单个字符的识别方法,通常利用连通域分析,投影等方法对文本行进行字符分割,然后利用单字分类器对单个字符进行识别.针对整行识别,通常利用滑动窗口按照一定步长进行滑动,再利用单字分类器对滑动窗口内的字符进行识别[2],然后在贝叶斯框架下,结合中文语言模型,对文本行的上下文进行建模,来实现文本行的识别[3].由于近几年深度学习不断发展,利用深度学习实现文本行识别是一个极具潜力的研究方向,Messina R等人[4]首次提出将MDLSTM-RNN网络应用到中文手写体文本行识别,在CASIA-HWDB[5]数据集上进行训练,在ICDAR 2013竞赛数据集上进行测试,字符准确率为83.5%.Wu Y C等人[6]在MDLSTM-RNN网络基础上做了改进,用分离的MDLSTM-RNN进行中文手写体文本行识别,未加语料库的前提下准确率提升了3.14%.可以看出利用神经网络进行文本行识别准确率相对较低,有较大的提升空间.但是由于汉字种类较多,目前成功应用在中文手写体文本行识别中的神经网络较少,因此找到合适的神经网络去拟合大类别的离线中文手写体文本行识别,仍然是一个值得研究的问题.
对于离线中文手写体识别,相比基于切分策略的文本行识别,利用神经网络可以避免字符切分,实现真正无分割端到端离线中文手写体文本行识别.encoder-decoder[7]是较常见的框架,广泛应用在语音,图像,视频等领域.沈华东等人[8]将该框架应用到文本摘要的自动提取;Deng Y等人[9]将该方法用到了公式识别中;O Vinyals 等人[10]将encoder-decoder框架应用到图片描述中,Xu K等人[11]首次提出在 encoder-decoder框架添加Attention的思想,应用到图片描述中.图片描述是指给定一张图片,计算机会自动输出一句话来描述这张图片.而对于离线中文手写体,则是给定一张中文手写体图片,输出对应的可编辑的中文汉字.通过类比,我们可以将离线中文手写体的识别看作是获得该张图片的描述.本文分别对传统的encoder-decoder和基于Attention机制的encoder-decoder两种方法作了对比实验.实验结果表明,基于Attention机制的encoder-decoder比传统的encoder-decoder框架具有更好的识别结果;同时也表明encoder-decoder框架可以成功应用到大类别中文手写体文本行识别中.本文的网络结构与目前成功应用到大类别中文手写体文本行识别中的MDLSTM-RNN网络,具有以下优点:
1)本文不需要利用单字符和中文语料库来扩充中文手写体文本行数据集;
2)也不需要利用其他语言的手写体进行预训练.本文直接利用已有数据集CASIA-HDWB2.0-2.2,在CNN+BLSTM+Attention+LSTM网络结构下直接进行训练,并取得了较好的实验结果.
2 模 型
本文采用的网络结构是基于Attention机制的encoder-decoder框架,具体的结构为CNN+BLSTM+Attention+LSTM,如图1所示.
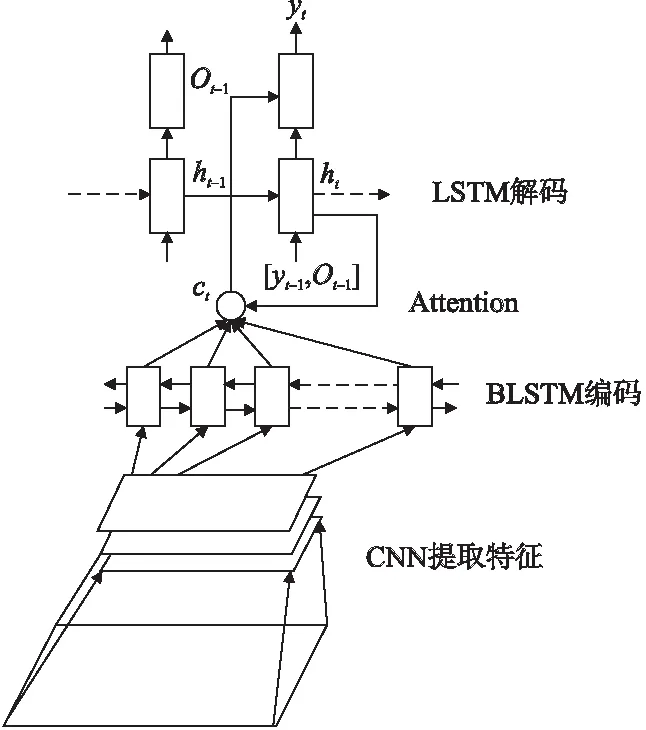
图1 整体框架结构图Fig.1 General framework structure
首先用卷积神经网络(Convolutional Neural Network,CNN)[12]提取特征,然后将特征图的列向量依次输入到双向长短期记忆模型(Bidirectional Long Short Term Memory Network,BLSTM)[13]中进行编码,再将BLSTM输出结果结合Attention,输入到长短期记忆模型(Long Short Term Memory Network,LSTM)[14]中进行解码.具体的识别步骤如算法1所示.
算法1.脱机中文手写体识别算法
输入:经过预处理后的离线中文手写体图片
输出:识别结果
1)图片预处理,按照图片大小分成33类;
2)For epoch=1…15:
3)将预处理后的图片输入CNN;
4)将步骤3得到的特征图,按列依次输入BLSTM进行编码;
5)将编码后的结果,结合解码时当前时刻隐藏层的输出,作为全连接层的输入,全连接层后连接tanh激活函数;
6)把步骤5的输出采用softmax进行归一化,得到每列对应的概率值,也称为Attention;
7)将步骤4得到的编码结果和步骤6得到的Attention,对应相乘得到新的编码结果;
8)将步骤7的输出和当前时刻的LSTM隐藏层的输出作为全连接层的输入,全连接层后用tanh激活函数;
9)将步骤8的结果用softmax归一化,归一化后的结果作为词典中字符的概率;
10)目标函数采用条件概率的负对数似然.
2.1 卷积神经网络
传统的汉字特征提取的方法有骨架特征、网格特征、笔画密度特征及方向线速特征等[15].本文采取卷积层进行特征提取,池化层进行特征选择.LeCun Y等人[12]提出的卷积神经网络最近广泛应用于图像识别领域.卷积神经网络如图2所示,由若干层卷积层、池化层和全连接层组成.卷积神经网络和全连接神经网络相比,具有局部感知野、权值共享和下采样这三个结构特性,使得卷积神经网络提取到的特征对输入数据的平移、旋转、缩放都具有较高的鲁棒性.对于图像识别来说,卷积神经网络会尽可能保留重要的参数,来达到更好的识别结果.

图2 卷积神经网络结构图Fig.2 Convolutional neural network structure
如果用卷积神经网络来提取一张中文手写体图片的特征,则会得到一组丢失图片中汉字相对位置信息的向量;如果去除全连接层,则会得到具有汉字图片相对位置的向量.所以为了保留图片的相对位置,本文采用去除全连接层的卷积神经网络,类似VGGNet[16]的结构.VGGNet是由牛津大学计算机视觉组(Visual Geometry Group)和DeepMind公司一起研发的深度卷积神经网络,通过反复堆叠3×3的小型卷积核和2×2最大池化层,成功构建了11到19层的卷积神经网络,并取得ILSVRC 2014比赛分类项目的第二名和定位第一名.
2.2 BLSTM编码
在图片描述中,编码一般会采用LSTM、RNN、CNN.LSTM被广泛应用于语音识别、自然语言理解、文本预测等具有序列信息的数据.带有语义信息的离线中文手写体图片也是具有序列信息的数据,在识别的过程中同样可以使用LSTM.长短期记忆神经网络是改进的循环神经网络(Recurrent Neural Network,RNN)[17],通过增加单元状态和开关来解决RNN无法处理长距离依赖的问题.
开关在实现的时候用了门(gate)的概念.门实际上就是一层全连接层,它的输入是一个向量,输出是一个0到1的实数向量.LSTM单个神经元如图3所示.
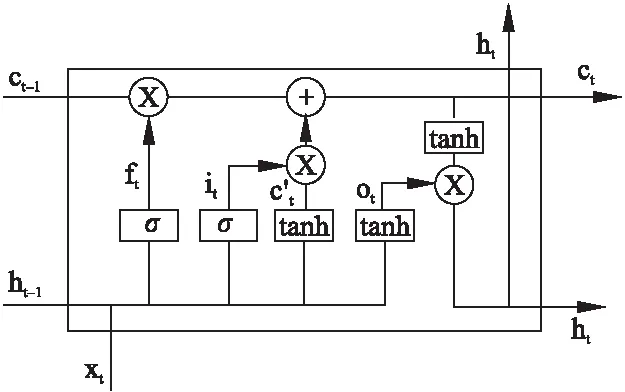
图3 LSTM单个神经元Fig.3 Single neuron of LSTM
LSTM总共采用三个门,分别是遗忘门、输入门、输出门,LSTM利用遗忘门和输入门来控制单元状态c的内容.遗忘门决定了上一时刻的单元状态ct-1有多少保留到当前时刻的单元状态ct;输入门决定了t时刻的网络输入xt有多少保存到单元状态ct;输出门是用来控制单元状态ct有多少输出到LSTM的当前输出值ht.遗忘门、输入门、输出门分别为:
ft=σ(Wf·[ht-1,xt]+bf)
(1)
it=σ(Wi·[ht-1,xt]+bi)
(2)
ot=σ(Wo·[ht-1,xt]+bo)
(3)
其中ft是遗忘门,Wf是遗忘门的权重矩阵,bf是遗忘门的偏置矩阵,σ是sigmoid激活函数;ht-1表示t-1时刻LSTM的输出,xt表示当前时刻的输入;[ht-1,xt]表示把两个向量横向连接.it和ot分别是输入门和输出门,其中Wi是输入门的权重矩阵,bi是输入门的偏置矩阵;Wo是输出门的权重矩阵,bo是输出门的偏置矩阵,其余的参数和遗忘门相同.
为了计算当前时刻的单元状态,需要计算当前输入的单元状态c′t,c′t是根据前一时刻的输出和当前时刻的输入进行计算的:
c′t=tanh(Wc·[ht-1,xt]+bc)
(4)
接下来计算当前时刻的单元状态ct,ct是由遗忘门ft按元素乘以t-1时刻的状态ct-1,再加上当前输入门it按元素乘以当前输入的单元状态c′t得到的:
ct=ft°ct-1+it°c′t
(5)
°表示按元素相乘,由于遗忘门和输入门的控制,它既可以保存很久之前的信息,也可以剔除当前时刻无用的信息.最后计算LSTM的最终输出ht,它是由输出门和单元状态共同控制:
ht=ot°tanh(ct)
(6)
由此看出LSTM对前后有联系的序列信息有较好的学习能力.BLSTM是LSTM的改进,LSTM表示当前时刻的输出只和前面的序列相关,如图4(a)所示;而BLSTM表示当前时刻的输出不仅与前面的序列相关,还和后面的序列相关,如图4(b)所示.
针对中文手写体文本行识别,假如有一张图片的标签为“我的笔记本坏了,我想买一个新的笔记本”.如果使用LSTM,从前向后学习,如果“买”这个字的图片信息不明确,根据 “坏”这个字,可能学到是“修”,“扔”,“买”等.但如果使用BLSTM,可以从后向前学习,根据“新”这个字,此时学到
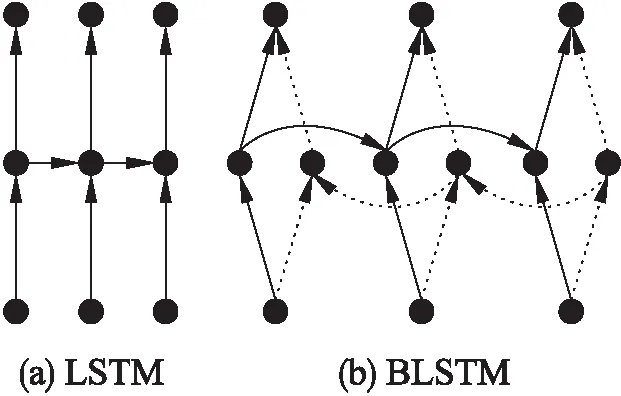
图4 LSTM和BLSTM结构Fig.4 Structure of LSTM and BLSTM
“买”的概率会变大.所以针对具有语义信息的文本行,BLSTM具有更强的学习能力,本文也采用BLSTM进行编码.
2.3 解码
解码的目的是将图像特征转换为识别结果.Vinyals O等人[1,0]直接用LSTM进行解码,它是将编码后的向量直接输入到LSTM中.即无论我们当前学习的是什么,它的输入都是整张图片的信息,也就是说ht必须包含原始句子中的所有信息.但是当句子比较长时,ht没办法存放这么多信息,此时便会造成精度下降.为了解决这个问题,Xu K等人[11]提出了一种Attention机制,分为Hard-Attention和Soft-Attention,本文采用的是Soft-Attention.在使用Attention机制之后,每一时刻的输入不再是整张图片的信息,而是让decoder在输入序列中自由的选取特征.

图5 中文文本行图片的识别过程Fig.5 Process of Chinese text line image recognition
基于Attention机制的中文手写体图片的识别过程如图5所示.标签为“天阴雨湿声啾啾”,当分别要识别“天”、“阴”、“雨”、“湿”,“声”、“啾”、“啾”、“.”这8个字符时,他们的注意力可视化分别如图5(a)、(b)、(c)、(d)、(e)、(f)、(g)、(h).如图5(a)可以看出在识别“天”时,“天”所在图片的位置的Attention值会比较大.而Attention的计算过程如下:
et=a(ht,{Vh,w})
(7)
αt=softmax(et)
(8)
zt=β({Vh,w},αt)
(9)
其中a操作用的是Luong M T等人[18]的方法,Vh,w表示特征图中h行w列组成的向量,ht表示LSTM在t时刻的输出.softmax表示softmax函数,αt就是Attention,它表示特征图中元素对应的权值.β同样采用Luong M T等人的方法,zt是decoder的输入,decoder过程如下:
ot=tanh(W,c[ht,zt])
(10)
ht=LSTM(ht-1,[yt-1,ot-1])
(11)
p(yt+1|y1,…,yt,V)=softmax(Woutot)
(12)
其中p(yt+1|y1,…,yt,V)表示生成yt+1的所有候选字符的概率,tanh表示tanh激活函数,W,c表示权重参数,向量zt和ht横向连接来预测yt+1的概率.
本文在t时刻的解码,需要t-1时刻解码的输出和编码后的特征图作为输入.首先根据公式(7)和公式(8)计算特征图中列向量对应的权重,再根据公式(9)计算出加权和,将加权和的结果作为t时刻LSTM的输入,最终求出t时刻生成的字符类别.
3 实 验
3.1 数据集
由于本文采用的方法是针对有语义信息的文本行,所以选取CASIA-HWDB2.0-2.2[5]数据集,该数据集下共有5019页图像,分割为52230行和139414个汉字,共有2703类.52230行又分为训练集和测试集,其中41780行作为训练集,10450行作为测试集.并且所有图像均为灰度图像.
3.2 预处理
BLSTM分为两类,第一类不支持变长输入,第二类支持变长输入.显然,由于我们的手写体文本行的长度都是不固定的,所以本文采用的是支持变长输入的BLSTM.这里的变长不是指任意长度,而是多个固定长宽.根据CASIA-HWDB2.0-2.2数据集中文本行图片的大小,采取的固定长宽分别为:[240,130]、[400,180]、[560,180]、[640,180]、[800,180]、[950,200]、[1030,200]、[1210,180]、[1290,200]、[1370,200]、[1450,200]、[1530,200]、[1610,180]、[1700,130]、[1700,170]、[1700,220]、[1800,130]、[1800,170]、[1800,220]、[1800,300]、[1900,130]、[1900,170]、[1900,220]、[1900,300]、[2000,150]、[2000,220]、[2000,300]、[2100,150]、[2100,220]、[2100,300]、[2200,260]、[2300,260]、[2600,500].根据图片的大小,从前往后判断当前图片的长宽所处的边界范围.如果图片长和宽恰巧等于边界值,则不需改变图片;否则需要根据边界的大小,将图片的右侧和下方加白边;将图片大小超过[2600,500]边界的图片直接归一化为[2600,500].这样就把所有的图片按照大小分成33类.并且为了高效的进行训练,把所有分类过后的图片进行归一化,长和宽分别设置为当前图片的二分之一.
3.3 评估方法
由于本文采取的是端到端的识别,输入文本行图片,直接输出整行的识别结果.对于一行的识别结果,如果直接将它和标签从前往后进行比对,这种方法计算出的正确字符数是不准确的.所以采取了字符串编辑距离(Levenshtein Distance)来计算识别结果和标签的相似程度.对于两个字符串,定义一套操作方法来把两个不相同的字符串变得相同.如果两个字符串相同,那么它们的编辑距离为0;具体的计算方式如下:
1)替换一个字符,编辑距离加1;
2)插入一个字符,编辑距离加1;
3)删除一个字符,编辑距离加1.
最后当识别结果和标签两个字符串相同时,此时的编辑距离就是识别结果中出错的字符的数目,字符的准确率和正确率分别定义为:
(13)
(14)
AR表示字符的准确率,CR表示字符的正确率.N是总的字符的数目,Sub是替换字符的数目,Ins是插入字符的数目,Del是删除字符的数目.
3.4 实验结果
本文采用去除全连接层的卷积神经网络,并且在一些卷积层后面增加批标准化(Batch Normalization,BN)[19].如表1所示,maps表示特征图的数量,Window表示池化层窗口大小,k、s、p分别代表卷积核,步长和填充.由表1可知,卷积层的卷积核的大小都是3,卷积核移动的步长均为1,填充也为1,激活函数使用的均为ReLU,池化层全部为MaxPooling.
表1 卷积神经网络配置
Table 1 Configuration of convolution neural network
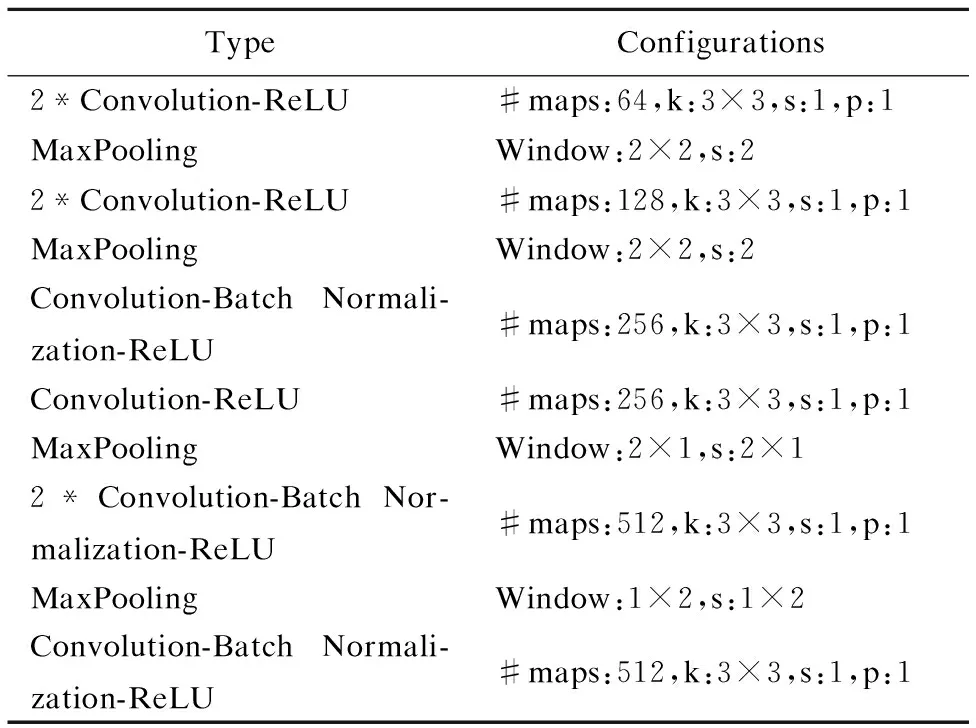
TypeConfigurations2*Convolution-ReLU#maps:64,k:3×3,s:1,p:1MaxPoolingWindow:2×2,s:22*Convolution-ReLU#maps:128,k:3×3,s:1,p:1MaxPoolingWindow:2×2,s:2Convolution-Batch Normali-zation-ReLU#maps:256,k:3×3,s:1,p:1Convolution-ReLU#maps:256,k:3×3,s:1,p:1MaxPoolingWindow:2×1,s:2×12*Convolution-Batch Nor-malization-ReLU#maps:512,k:3×3,s:1,p:1MaxPoolingWindow:1×2,s:1×2Convolution-Batch Normali-zation-ReLU#maps:512,k:3×3,s:1,p:1
编码使用的是BLSTM,隐藏层为256.解码用的是LSTM,隐藏层为512.初始学习率为0.1,总共训练了15个迭代,选取了最好的实验结果.
表2 实验结果
Table 2 Experiment results

MethodARCRAttention with blank95.76%96.73%Attention no blank94.29%95.30%Negative-awareness CNN[5]92.04%93.24%Conventional [2]77.34%79.43%
本文使用的网络框架在编码和解码都用到了LSTM,它对文本行前后序列的学习能力非常强,所以在给文本行打标签的时候,增加了空格标签.比如原始标签为“大家好”,加空格后的标签变为“大#家#好”,空格标签用#表示,这样能在一定程度上抑制前后的联系.如表2所示,加空格标签的字符准确率达到95.76%,比不加空格标签的准确率提升了1.47%.本文采用的加空格标签的Attention机制比Song Wang等人的方法AR提升了3.72%,CR的准确率提升了3.49%.
为了验证基于Attention机制的encoder-decoder的有效性.本文还采用传统的encoder-decoder来进行中文手写体识别,具体的网络结构是使用CNN进行编码,再使用LSTM进行解码.为了保持一致性,两种方法的CNN均采用表1中的结构,LSTM解码参数设置和训练时的参数设置均和基于Attention的encoder-decoder参数相同.实验结果如表3所示.
表3 Attention机制对比实验
Table 3 Comparison experiment of attention

MethodARAttention with blank95.76%no Attention with blank82.93%
表4 不同卷积层的对比实验
Table 4 Comparison experiment of different
convolutional layers

CNN层数AR6层65.20%9层95.76%10层73.94%
表4列出了在添加空白标签的前提下,不同数量的卷积层对识别结果的影响.当CNN为6层、9层和10层时,对应的字符准确率分别为65.20%、95.76%、73.94%.对比表明,9层的卷积层的识别结果最好,6层的卷积层可能存在欠拟合的情况,而10层的卷积层可能又存在过拟合的情况.
4 结束语
本文将图像描述中Attention方法应用到离线中文手写体文本行的识别中.整个网络是基于encoder-decoder框架,采用9层卷积层提取特征,BLSTM进行编码,将编码结果结合Attention输入到LSTM进行解码.由于整个网络结构使用两次LSTM,所以针对具有语义信息的数据会取到较好的实验结果.本文还在原始标签的基础上增加了空格标签,准确率得到进一步的提升.为了进一步提高实用性,接下来的研究工作,会将CASIA-HWDB1.0-1.2中孤立手写字符,转换为带有语义信息的中文手写体图片,然后再修改成合适的网络结构重新进行训练.
猜你喜欢
环球人物(2022年4期)2022-02-22
小学生学习指导(中年级)(2021年12期)2021-12-30
小资CHIC!ELEGANCE(2021年32期)2021-09-18
汉字汉语研究(2020年2期)2020-08-13
汉字汉语研究(2020年2期)2020-08-13
电子制作(2019年22期)2020-01-14
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
疯狂英语·新读写(2018年3期)2018-11-29
