
基于多部情感词典和规则集的中文微博情感分析研究
2019-09-13 03:37吴杰胜
计算机应用与软件 2019年9期
吴杰胜 陆 奎
(安徽理工大学计算机科学与工程学院 安徽 淮南 232001)
0 引 言
微博是近些年来一个新生的适用于大众的社交媒体平台,随着移动互联网的普及,大众对微博的使用率越来越高,微博也得以快速发展。广大的用户群体都可以通过微博来发表自己对当前的一些热点话题的看法,所以他们每天都在提供海量且丰富的观点文本数据,而这些数据中包含着很多情感信息。如何充分挖掘情感信息并进行分析就是情感分析。情感分析在当今的研究很广泛,提取情感信息对社会发展起到一定的作用,而微博除了作为一个社交媒体平台之外,还具有其他特性,因此对微博的情感分析研究至关重要。
目前国内外都在对微博进行研究,但中文微博和英文微博的研究进展差距很大,英文微博的研究成熟度高于中文微博,而且中文微博与英文微博的特性几乎不同,因此如何能利用中文微博情感信息来进行研究分析是我们现在要做的工作。本文利用多部情感词典和中文语义规则集相结合的方式判断中文微博的情感极性。
1 相关工作
文献[1]中指出情感即文本作者的意见和观点,因此对情感的分析也可以理解为对意见的挖掘,文本意见挖掘属于数据挖掘的子类,主要是利用现有的计算机技术挖掘出蕴含在文本间的观点、情绪等元素。在当今可以通过构造相应的情感词典和利用机器学习算法来对微博文本进行情感分析、极性分类。构造情感词典来对微博进行情感分析出现比较早,而且它对微博文本这种细粒度的情感分析效果极佳。文献[2]就是在基础情感词典的基础上,构造了两种计算词汇语义的情感权值方法。文献[3]也在基础情感词典的基础上,构造了一种分类器,可以对文本语义之间的歧义进行消除,从而提高情感分析准确率。
基于机器学习的方法来进行情感分析,主要是通过选取一些特征来标注训练集和测试集,接着利用朴素贝叶斯、支持向量机等分类器进行情感分类。文献[5]利用支持向量机或朴素贝叶斯与支持向量机相结合的方法对微博进行情感分析。文献[7]首先构造微博语料库,再用朴素贝叶斯算法进行分类。
总之,微博情感分析常用的两种方法都有一定的作用,但谁也不能做到更高的准确率,只能在这个基础上不断地加以改进方法提高准确性。基于情感词典的方法擅长处理细粒度的文本情感分析,因此本文主要也是利用情感词典,在此基础上加以改进,并结合文本之间的语义规则集来对微博进行情感分析,最后通过各个部分的情感权值加权求和得到微博的情感极性。微博的整体情感分析流程图如图1所示。
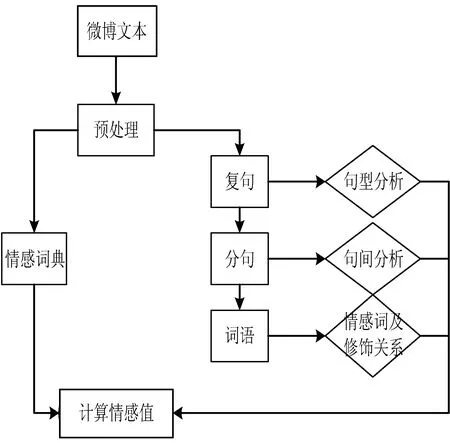
图1 微博整体情感分析流程
2 情感词典的构建
目前国外的情感词典《General Inquirer》完善度很高,但在国内还没有一部这样比较完善的词典,所以对微博来说,有一部完善的情感词典是很有必要的。现在国内使用常见的代表性情感词典有知网HowNet情感词典,台湾大学的正、负面情感词典和大连理工大学中文情感词典库等等。所以本文在此基础词典的基础上进行整合和优化,构建一个扩展的多部情感词典,同时还需要单独构建一个微博特定领域的情感词典来一起组成微博情感词典,从而进行微博情感分析。
2.1 微博文本的预处理
微博文本具有元素多样性、随意性、口语化等特点,所以需要进行预处理。预处理步骤如下:
1) 将网页中的链接、图片、视频、动画删除;将“@+用户名”删除;将“#话题#”删除。这些内容虽对微博情感分析有一定作用,但是影响不大,可以删除。
2) 将文本中的繁体字、英文等其他语言都翻译成中文,这是为了后续工作的方便,可使用特定的工具来进行翻译。
3) 保留微博文本中的表情符号。因为表情是情感状态的外在表现,与情感有关,可以参与情感权值计算。
4) 分词,本文使用中科院ICTCLAS软件进行分词与词性标注。
5) 删除停用词,比如助词“的”,代词“她”、“他”等之类的词。
在预处理完成之后,微博文本就是词语连接成串的形式,比如“我国运动员武大靖在短道速滑男子500米决赛中夺冠。”就会变为{我国,运动员,武,大靖,在,短道速滑,男子,500,米,决赛,中,夺冠 }。
2.2 构建多部情感词典
目前中文情感词典还没有完整成熟的情感词典,所以除了构造基础情感词典外,还有否定词词典和双重否定词词典、程度副词词典、关系连词词典、表情符号词典。
2.2.1基础情感词典
基础情感词典是取自大连理工大学的中文情感词典库。这个词典库将情感词分成了五个强度和三类词。本文用数字1表示正面词,数字2表示反面词,0表示中性词且它的权值为0。示例如表1所示。
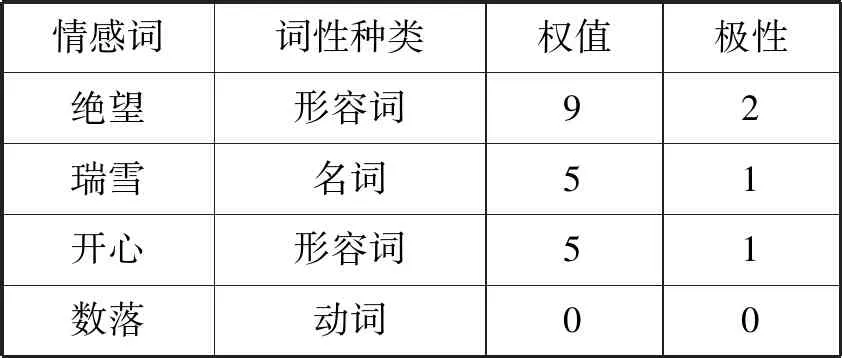
表1 基础情感词典示例
2.2.2否定词词典和双重否定词词典
否定词词典包括否定副词和反问词这两部分。文献[10]中指出否定副词和反问词修饰情感词时,都会改变词的情感极性,但反问词语气更强,而双重否定不会改变词的情感极性,但是语气会更加强烈。通过人工筛选共获取25个否定词,示例如表2所示。

表2 否定词词典和双重否定词词典示例
2.2.3程度副词词典
程度副词词典来自于知网词典库。将这些词一共分为6个等级。等级分别是超、最、很、较、稍、欠。分别对这6个等级给予一定的权值,对所修饰的情感词的情感强度扩大一定的倍数。示例如表3所示。
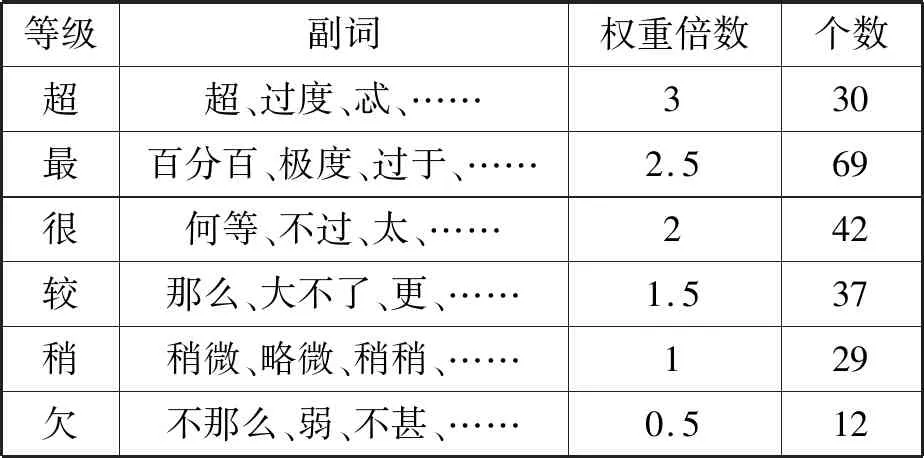
表3 程度副词词典示例
2.2.4关系连词词典
关系连词主要有转折、让步、递进、因果、假设等关系,它们在句子与句子之间的连接起到作用。本文收集整理常用的一些词构建了一个关系连词词典,并赋予一定的权值,示例如表4所示。
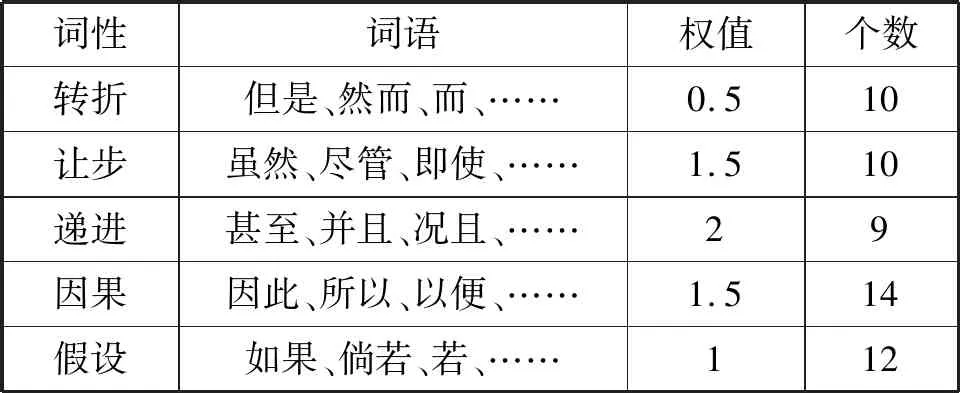
表4 关系连词词典示例
2.2.5表情符号词典
微博表情在微博文本中具有很强的情感倾向性,可以通过它去判断微博情感极性有一定的作用。本文通过微博抓取了一些频率使用比较高的部分表情构造表情词典,共计217个表情。示例如表5所示。
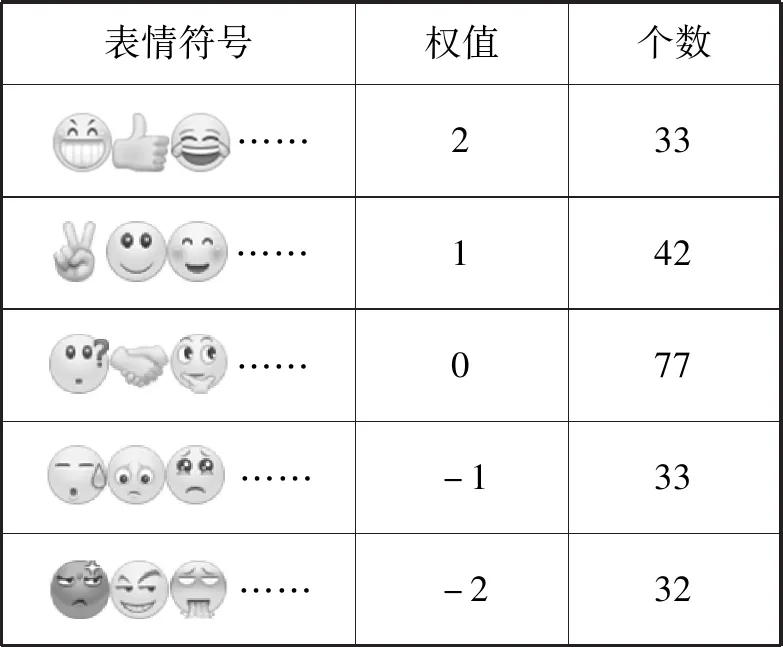
表5 表情符号词典示例
2.3 微博领域情感词典的构建
由于基础的情感词典还不完整,对情感词的概括是有限的,所以还需要针对微博上一些特有的情感新词进行识别,从而对这些新词集合构建一个词典。首先要基于统计信息来识别新词,然后在新词中进行情感识别。
2.3.1基于统计信息的新词识别
文献[6]中给出三个定义,分别称作字串频数、内部耦合度、邻字集信息熵,一个字串能否成词与这三个定义有关。微博文本是由一连串词语组成的文本,首先我们用一个长字串来表示微博文本,同时将一个新词的成词长度设定为一个值,本文设定为7。同时再考虑上面三个定义,它们每个都要设定一个参数阈值,如果有任何一个条件不满足,即超过阈值范围,则这个字串不是一个词。最后剩下的能构成的词语集合中,仍需要比对情感词典中的词语,若该词在已有的词典中找不到,即成为新词。
2.3.2新词情感分析与PMI算法改进
通过以上方法能识别并挖掘出新词,但是对这些词的情感极性还需要继续识别,从而构建出一个微博特定领域的情感词典。首先根据以上方法识别出新词,按照词频进行统计并排序,按照从上到下的方式来筛选,筛选出情感极性较强而且词频比较高的词语作为种子词。然后对这些词的情感极性作出判断,紧接着利用PMI算法计算其他未知词与它们之间的语义相似度,最后计算未知新词的情感极性,方法如下:
点互信息主要是可以计算词与词之间的相似度。两个词w1和w2之间的相似度计算公式为:
(1)
式中:P(w1,w2)表示w1、w2共同出现的概率,p(w1)、p(w2)分别表示w1、w2单独出现的概率。
w1表示未知词,w2表示种子词,若式(1)的计算结果较大即相似度高,则可知两个词情感极性相同,否则就不同。但仅仅计算一对词的语义相似度在微博情感分析中不具有说服力,所以本文在考虑这个的基础上,在词阈的范围内选取了30对正负面情感极性的种子词,同时考虑到使用频率高的表情元素,选取了5对正负面情感极性表情符号作为种子词,一起构成正面的情感词集合WP和负面情感词集合WN,用来考察多词之间的语义相似度。同时对PMI公式进行改进,得出新词w的情感极性判断的新公式:
(2)
式(2)的值如果大于0,则新词w的情感极性为正面;等于0,新词w的情感极性为中性;小于0,新词w的情感极性为负面。
最后一起构建成微博特定领域的情感词典,本文识别并挖掘出2018年微博新词共计164个,将这些词分为4个级别,并赋予一定权值,示例如表6所示。

表6 微博新词词典示例
3 微博文本规则集的情感分析
微博文本也是普通文本,都是由汉字等其他元素构成的表达文本,而文本之间肯定存在着一些语法关系和语义规则,它们对文本的情感分析也有一定作用。
3.1 句间分析规则
一条微博文本可以通过标点符号划分成若干个复句,一条复句可以分成若干个分句,句间分析规则就是考虑分句与分句之间的关系,而句间关系主要有三类:转折、递进、假设。这里用S表示整个复句,Si表示复句的各个分句。定义集合{S1,S2,…,Si}为复句的分句集合,Ri表示句间规则对分句Si的情感权值。
3.1.1转折关系规则
转折关系中,基本都会实现前后的情感翻转作用,转折之前的分句情感会变弱,而主要突出后面分句的情感,后面分句与前面分句的情感极性相反。规则定义如下:
1) 若复句S中只有单一的转折后接词出现(如“但”,“可是”,“却”等)在分句Si中,则Si之前的分句权值Ri都设为0,Si之后的分句权值Ri都设为1。
2) 若复句S中只有单一的转折前接词出现(如“虽然”,“如”,“尽管”等)在分句Si中,则Si之前的分句权值Ri都设为1,Si之后的分句权值Ri都设为0。
3) 若复句S中出现成对的转折连接词(如“虽然…但是…”等),且转折后接词出现在分句Si中,则Si之前的分句权值Ri都设为0,Si之后的分句权值都Ri设为1。
3.1.2递进关系规则
递进关系,顾名思义,在这个关系规则中,复句的每个分句根据从前到后的顺序逐渐增强情感。规则定义如下:
若复句S中出现递进关系的连接词(如“更”,“更加”,“更重要的是”等),则分句的权值为:
Ri=1Ri+1=1.5 …Rj=1+0.5×(j-i)
3.1.3假设关系规则
假设关系建立在现实情况中的一种设想,它表达的情感主要在假设复句的前半分句,而对后半分句的情感相对弱化一些。比如:如果A,那么B。则句子强调的是内容A。
1) 若复句S中未出现否定的假设连接词,但是出现假设关系的后接词(如“那么”),且假设后接词出现在分句Si中,则Si之前的分句权值Ri都设为1,Si之后的分句权值Ri都设为0.5。
2) 若复句S中出现否定的假设连接词,而且假设后接词(如“那么”)出现在分句Si中,则Si之前的分句权值Ri都设为-1,Si之后的分句权值Ri都设为-0.5。
上面描述的这三种句间关系都能影响到整个微博文本的情感极性,所以情感分析中要考虑到它们。至于其他的句间关系如因果、并列等,对情感分析的影响可以忽略不计。
3.2 句型分析规则
上一节所说的是复句的分句之间的关系,这一节说明的是复句的句型对整个文本的情感极性的影响。本文主要讨论陈述句、疑问句、反问句和感叹句这四类常见句型。它们常以“?”、“!”、“。”等标点符号结尾。一个文本用D来表示,则文本分割成各个分句即复句,用集合定义为{D1,D2,…,Di,…,Dn}。复句用Di来表示,定义Ti为句型规则对复句Di的情感权值。具体的规则定义如下:
1) 如果微博文本中有复句Di以感叹号“!”结尾,则表示此复句为感叹句,它的权值Ti设为1.5。
2) 如果微博文本中有复句Di以反问号“?”结尾且结尾处有反问标志词或者没有以反问号“?”结尾但有反问标志词,则表示此复句为反问句,它的权值Ti设为-1。
3) 如果微博文本中有复句Di以反问号“?”结尾且结尾处无反问标志词,则表示此复句为疑问句,它的权值Ti设为0。
4) 如果微博文本中有复句Di以句号“。”等其他标点符号结尾,则表示此复句为陈述句,它的权值Ti设为1。
4 微博综合情感计算
本文基于多部情感词典和规则集的微博情感分析,对微博从词到句进行整体综合情感计算。用D表示整个文本,文本中各个复句用Di表示;S对应一个复句Si表示复句中的各个分句;E表示情感权值,Ri表示分句的句间关系规则情感权值,Ti表示复句的句型关系规则情感权值,seni表示词典匹配得到的权值。
1) 词语情感值E(Wi)计算公式为:
E(Wi)=N×A×seni
(3)
式中:N表示情感词前对应的否定词或者双重否定词,A表示情感词前对应的程度副词,seni表示情感词与词典匹配得到的权值,Wi表示情感词语。
词语的情感权值计算不仅与它自身的权值有关,还与在其前面修饰的程度副词、否定词有关,所以在情感权值计算时要将它们考虑进去。
2) 分句情感值E(Si)计算公式为:
(4)
3) 复句情感值E(Di)计算公式为:
(5)
4) 文本情感值E的计算公式为:
(6)
5) 表情情感值Em计算公式为:
(7)
6) 微博情感值Elast计算公式为:
Elast=m×E+n×Em
(8)
式(8)表示微博的最终情感值计算,m和n表示文本情感值和表情情感值在微博情感权值计算中所占分量的大小,本文根据文献[9]中分析分别设置为0.6和0.4,计算得出Elast的大小。如果Elast大于0,则表示此微博的情感倾向为正面的,如果Elast小于0,则表示此微博的情感倾向为负面的,如果Elast等于0,则表示此微博情感为中性的。
5 微博情感分析实验
5.1 实验方法
首先通过爬虫工具爬取了微博上两个相关的微博话题,然后对这些数据进行情感分析,具体的实验步骤如下:
1) 获取实验数据。利用爬虫软件爬取微博上比较两个热门话题“#短视频整顿#”和“#《我不是药神》爆红引社会热议#”的文本数据。
2) 情感极性的人工标注。获取数据的情感极性没有进行标注,采用人工方法对这两个话题进行标注。人工标注主要是通过统计抽取随机选择三名实验同学对这两个话题进行主观判断,标注情感极性,最后统计结果。
3) 预处理。根据上述对应的方法构建六部情感词典。
4) 话题情感分析。分别在一部基础情感词典、六部情感词典和基于六部情感词典与规则集的基础之上对这两个话题进行三组实验,得出微博的情感分析结果。
5.2 实验数据
本文通过爬虫软件爬取到关于两个微博话题的数据集,接着利用人工标注的方法,将这些文本进行情感极性标注,给出每条微博的情感权值并进行分类。共筛选出话题“#短视频整顿#”共计25 720条,其中正面数据18 634条,负面数据1 385条,中性数据5 701条;话题“#《我不是药神》爆红引社会热议#”共计17 695条,其中正面数据10 672条,负面数据2 856条,中性数据4 167条。判断标准是:微博情感权值大于0为正面,小于0为负面,等于0为中性。从筛选结果可知正面微博数据所占比例较大,负面微博数据和中性微博数据所占比例较小,且数据较少。
5.3 实验性能评估指标
本实验根据本文提出的微博情感分析方法对每一条微博文本进行情感分析,然后将在此方法下自动分析得出的结果与我们人工分类得出的结果进行比对,看情感分析的效果如何。采用以下三个指标进行分析,分别是正确率P、召回率R和综合度量F指标值,具体公式如下:
(9)
(10)
(11)
5.4 实验分析与结果
为了验证本文提出的方法具有更好的作用,还另外做了只基于一部情感词典和只基于六部情感词典的实验。将本文提出的方法实验结果与这两种方法得出的实验结果进行对比,利用性能评估指标对结果进行分析。
对两个话题分别做如下三组实验:
第一组实验:分别对话题“#短视频整顿#”和“#《我不是药神》爆红引社会热议#”采用基于一部基础情感词典的微博情感分析,并进行微博分类。
第二组实验:分别对话题“#短视频整顿#”和“#《我不是药神》爆红引社会热议#”采用基于六部基础情感词典的微博情感分析,并进行微博分类。
第三组实验:分别对话题“#短视频整顿#”和“#《我不是药神》爆红引社会热议#”采用基于六部基础情感词典和规则集的微博情感分析,并进行微博分类。
实验结果如表7和表8所示。

表7 #短视频整顿#实验结果
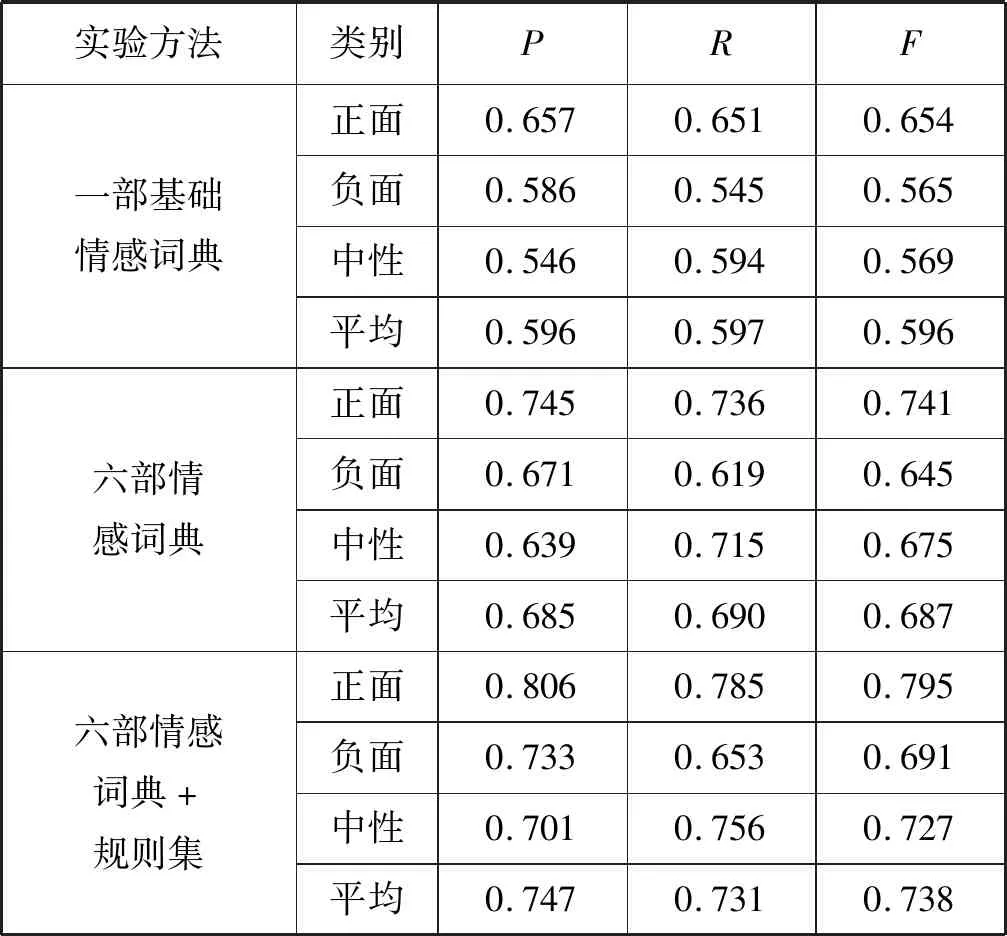
表8 #《我不是药神》爆红引社会热议# 实验结果
通过表7和表8的数据,对实验结果进行如下分析:
1) 实验结果表明本文提出的方法提高了微博的情感分析的正确率。若只单纯靠一部基础情感词典,那么正确率是较低的,因为微博的特殊的文本包含了很多普通文本不具有的特性,所以要在原来的基础上扩建多部情感词典,提高词典的覆盖面,同时将文本语义规则集考虑进去,更有利于微博的情感分析。
2) 通过两个话题的实验结果可以看出,话题“#短视频整顿#”的正确率高于话题“#《我不是药神》爆红引发社会热议#”的正确率。这是因为前者所获取的正面数据居多,而且对后者话题中一些判断失误的微博文本进行分析发现这是一部关于电影反讽刺的话题,有网友发表微博就使用了一些反讽刺的表达。比如“电影中的药商真的好棒啊,竟然可以把药卖给病人,真的是好样的!”,这其中“好棒”“好样”都是正面情感词,但实际上是起到讽刺作用,是负面的微博,因此在后续对微博的情感分析中还可以继续对语义规则进行完善分析。
3) 通过表格中数据发现正确率和F值都是正面微博偏高,通过微博分析得知是由于正面、负面、中性数据分布不平衡造成的,因为这两个微博都是社会热点话题,众多网友持支持态度。
4) 通过对比F值可以发现在引入六部情感词典之后,F值相对于一部情感词典下有很大提高,这是因为在六部情感词典下,匹配微博文本的面更广,尤其加入了微博特定领域的情感词典,而且在加入规则集以后,F值又有了一定的提升。虽然F值总体上提高了,但还可以继续提高,因为实验预处理过程中有个分词过程,还有语义规则的分析过程,这两个过程的优劣程度都会影响最后结果。当然还有一些其他因素,比如一词多义现象等。
实验表明,本文提出的方法利用多部情感词典,并考虑文本语义规则集,对微博的情感分析效果有明显的提升,且在三个指标下,都验证了此方法对微博情感分析有效果。
6 结 语
基于词典的情感分析是已有的研究方法,本文在基于词典的基础上,构建了除基础情感词典之外的其他五部词典,这些词典范围更广,其中微博特定领域的情感词典构造至关重要,未来还需要继续不断完善这部词典。最后在六部词典的基础上,考虑文本之间的语义规则,因此提出一种基于多部情感词典和规则集的中文微博情感分析方法,通过实验验证了此方法具有很好的作用。
微博的情感分析研究还有很多可以改进之处,比如要考虑微博的点赞数、转发数和阅读数等。我们将继续改进方法,力争使中文微博情感分析更上一个台阶。
猜你喜欢
莆田学院学报(2022年4期)2022-09-17
成都信息工程大学学报(2022年3期)2022-07-21
成都理工大学学报·社会科学版(2022年1期)2022-05-26
中学生报·教育教学研究(2022年1期)2022-04-18
新生代(2019年3期)2019-10-19
时代英语·高一(2019年5期)2019-09-03
科技视界(2016年1期)2016-03-30
数理化学习·高一二版(2009年2期)2009-03-30
数理化学习·高一二版(2009年1期)2009-03-19
安徽理工大学学报·自然科学版(2008年1期)2008-06-25
