
语音识别技术在3D虚拟智能 家居系统中的应用研究
2019-09-23 09:05卫敏
太原学院学报(自然科学版) 2019年3期
卫 敏
(山西职业技术学院 计算机工程系, 山西 太原 030006)
1 3D虚拟智能家居系统概述
本研究项目依托3D虚拟平台尝试开发了一个智能家居的交互模拟系统,其目的是通过三维虚拟仿真技术对智能家居交互系统的演示效果进行模拟。虚拟智能家居系统主要提供了两种交互方式,一种是通过移动终端的触摸屏操作实现人机交互,一种是通过语音识别进行人机交互[1]。采用设备操作的方式进行人机交互,用户需要花费时间在设备上进行浏览、选择和点击等操作,如果界面设计功能较多的话,人们还需要再对界面进行学习和了解。而语音识别的交互方式极大地简化了系统的操作步骤,用户可以直接通过语音发布指令,脱离了对设备操作的依赖性。
目前主流的3D开发平台都未集成语音识别功能。为了满足虚拟智能家居的语音交互需求,本文尝试对基于隐马尔可夫算法的语音识别策略进行了改进,并应用在了虚拟智能家居交互系统当中。
2 语音识别技术
2.1 原理
语音识别技术简单来说就是将语音转换成对应文字的一种技术,它主要由声学模型与语言模型两部分构成,前者用于解决语音的发声特性识别问题,后者用于描述语言的用词习惯,并对其进行区分[2]。其功能模型的一般结构如图1所示。
语音本身的特征变化非常丰富,同一个人连续两次发同一个音时,都会存在持续时长和语气轻重的不同变化,不同的人发出的语音更是千差万别。因此在构建语音识别模型时,对语音识别的算法设计是非常重要的。

图1 语音识别系统功能结构图Fig.1 Functional structure diagram of speech recognition system
2.2 语音识别算法
语音识别技术中比较具有代表性的算法有动态特征值规整算法、隐马尔可夫算法和神经网络模型等[3]。
非线性的动态特征值规整算法,简单来说就是将输入的语音信号基于时间轴进行弯曲调整,目的是要将其特征值曲线与算法内置的特征模板尽可能地进行匹配。这种匹配不仅是基于时长的,还包括距离测度。将语音信号中获取的特征值与特征模板中特征值视作两个矢量,不断进行最小距离的测算(可采用路径算法),以达到距离上的匹配,最终获取的最小距离所对应的语音即为识别结果。由于语音时长的不均匀,输入的语音特征与模型特征的比对就会出现较大误差;采用该算法能够较好地解决这一问题,但其算法过于简单,未引入统计模型对特征值进行连续的记忆和分析,在连续发音情境下识别准确度较差。
基于统计模型的隐马尔可夫算法,其统计模型的构建,主要由状态序列与观察序列两组识别基元组成。为了能够适应各类突发情况,两组识别基元可实现连续和离散两种状态下的特征参数分析,并在识别过程中,持续将新的识别结果加入到统计模型当中进行学习。随着统计模型的不断扩充,该算法能够高效地模拟出人类通过大脑对语法和语言需要的分析所产生的音素流,使其变为一个可观测的时变序列,由此可以快速准确获取其状态序列,并进行识别。由于统计模型中能够不断通过学习获取到不同的特征参考序列,因此该算法可以对各类语音特征进行准确识别,具有极高的识别性与抗噪性。
神经网络模型,该模型借鉴了人类神经系统工作原理,设计了神经元、网络拓扑和学习方法三个功能模块[4]。通过神经元实现非线性的语音识别处理,通过网络拓扑实现大规模数据的并行处理,通过学习方法提高语音识别的学习能力。适用于较为复杂的环境背景,例如语义不明、噪音干扰、知识背景不确定和逻辑关系不清等。但该算法的实现非常复杂,且开销较大,不易应用在较小规模的系统开发当中。
结合3D虚拟智能家居系统开发的实际需求,基于隐马尔可夫算法的语音识别功能实现,既可以有效提高语音识别的准确性,又不会对系统性能造成太大的开销负担,是目前较为理想的一种解决方案。
3 语音识别技术的应用策略研究
语音识别技术在虚拟智能家居系统中的应用主要是实现系统控制命令的识别功能,例如开关灯命令和开关电器命令等。这类词汇语义简单,词汇量也很少,通过构建小型的孤立词识别库,即可满足语音识别的需求。
3.1 孤立词识别策略
采用隐马尔可夫算法实现孤立词汇的语音识别功能,首先要构建孤立词识别库。由于虚拟智能家居系统的控制命令都较为简单且有限,因此孤立词识别库的构建并不复杂,只要识别库中涵盖了所有的操作命令即可[5]。接着要对输入的语音信号进行矢量化序列转换,经过量化转换的语音信号才能与识别库中的孤立词汇做进一步的比对。在与孤立词的特征序列比对过程中,依次计算语音信号与各个孤立词的匹配概率,最后选取匹配概率最高的孤立词作为最终的识别结果。实现过程如图2所示。
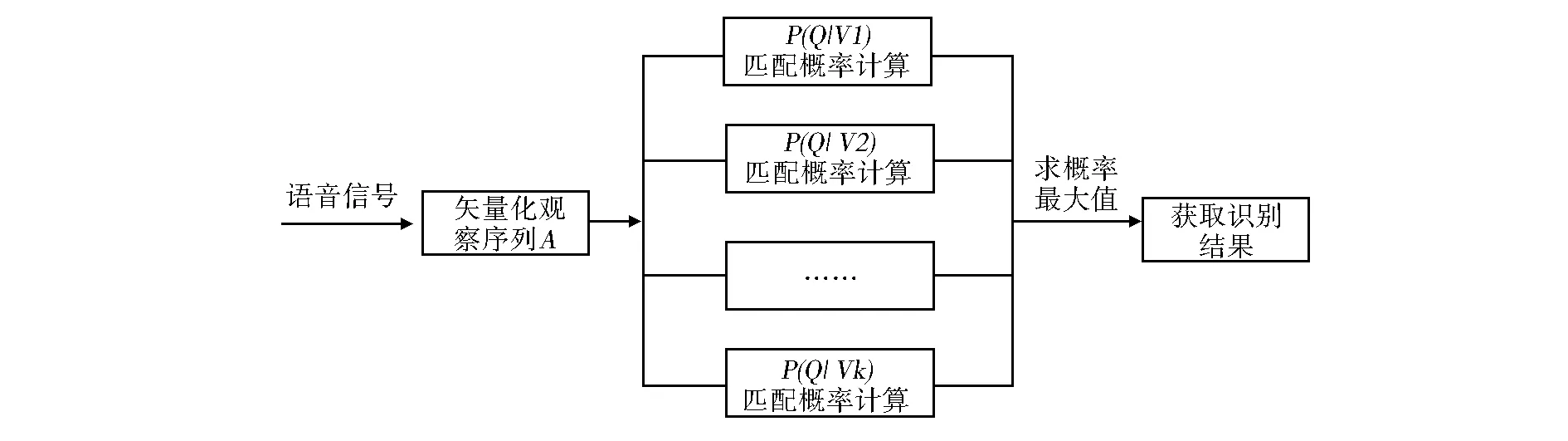
图2 基于隐马尔可夫算法的孤立词识别策略Fig.2 An isolated word recognition strategy based on HMA
语音信号的矢量化转换实质是从信号采样中抽取若干特征矢量,并构成离散型的观察序列。设该观察序列为Q={q1,q2,…,qn},观察序列的概率P(Q|V)由公式3.1可知:
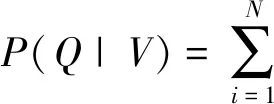
(1)
其中N为观察序列可能取值的个数,at连续观察时刻下特征值状态的前向概率。设孤立词模型的给定模型参数V=(A,B,π),其中A表示状态转移概率,B表示输出观测概率,π表示初始状态概率,计算最大概率值V*,公式如下:
V*=arg max{P(Q|V1),P(Q|V2), …,P(Q|Vk)}
(2)
最后依据V*所对应的孤立词模型,获取最终的识别结果。
隐马尔可夫算法所构建的统计模型支持自主训练学习,通过训练获取到大量的语音数据,可以对语音信号作出精确的描述,识别效果良好,功能稳定[6]。但是该算法对于语音中噪声的过滤效果较差,如果处于非常嘈杂的环境当中,其识别的准确率就会大大降低。为了有效解决这一问题,还需对语音识别功能做出进一步改进。
3.2 语音识别的策略改进
在日常生活中,人们常常会处在非常嘈杂的环境当中,身边会有各种各样的噪声干扰语音识别的准确性。为了能够从语句中准确识别出有效的词汇指令,本文尝试在语音识别策略中加入了预处理改进功能。
预处理的主要目的是对语句中疑似指令的词汇进行特征分析和提取,以过滤无效的噪声,提高指令识别的准确率。其功能实现主要由三部分组成,如图3所示。

图3 语音噪声过滤预处理功能的实现过程Fig.3 The realization process of voice noise filtering preprocessing function
在人机交互中,人们通常会对涉及指令的词汇加重发音,因此可以通过预加重方式对语音中的每帧信号按一定比例做增强处理。增强后的语音信号的高低频差异会更加明显,通过对低频信号的过滤可以剔除掉大部分的噪声。信号加重公式为:
s[n]=p[n]-ep(n-1)
(3)
其中:s[n]为加重后的信号样本序列;p[0]为输入的初始语音信号序列,数字化语音信号的最小存储单位为16 bit,也是最小的信号样本,n为输入的信号样本总数;e为预设的信号加重系数,其取值范围为0.9 经过初步过滤后,将提取到的高频信号序列作进一步的分段处理,以获取到真正有效的语音段。由于语音信号的变化与时间长短有着密切关联,且有效语音信号在短时间内会呈现出较为平稳的状态,通常这个时间长度约在10 ms到20 ms之间。采用过零率分析法,以15 ms为一个时间周期,假设音频采样频率为40 kHz,可知需采样的语音样本点为225个,公式如下: As=(15000/1000)×15=225 (4) 对这225个信号样本进行过零电平检测,如果过零的次数超过了系统所设定的阈值,则认为该时间段内的语音为有效语音,否则为无效语音。 为了使获取到的多个有效语音段之间能够平滑地过渡,对其进行分帧处理,即将语音序列以帧为单位进行前后衔接,每帧所持续的时长即为帧长。为了保证帧之间的衔接信号完整,一般会使前后帧有一定重叠。采用加窗法对语音序列进行分帧,通过给定宽度的可移动窗口加权的方式对语音信号进行分帧操作。公式表示为: F(n)=s(n)×win(n) (5) 其中s(n)为待分帧处理的语音信号序列,win(n)为加窗函数。加窗函数按计算方式分为三类,分别为Rectangle window、Hamming window、Hanning window。Rectangle window虽然低通性较差,但在短时语音特征分析中能够更好地实现过渡,且计算效率较高,因此选用Rectangle window作为加窗权值。 经过预处理的语音信号中无声段和明显的噪声段都可以得到有效去除,因此能大大提高隐马尔可夫算法的语音识别效率和准确度。 图4 语音识别服务主要功能Fig.4 The main function of voice recognition service 语音识别策略主要提供的是语音识别服务,应用在虚拟智能家居系统中还需要提供对应的接口进行交互,即各类终端语音采集设备的调用,统称为语音交互服务系统。语音交互服务系统采用WEB服务框架实现其核心功能的调用,通过http方式实现语音请求的提交。语音识别服务功能主要包括三大部分,如图4所示。 1)采集与校验语音信息,目前终端的语音采集设备已经将采集与识别、校验等多种语音服务封装在统一的接口调用中,能够为各类第三方软件提供语音的交互服务。 2)过滤噪声,通过语音识别的预处理策略提取有效的语音序列。 3)基于语音识别算法实现语音控制命令的识别。 3D虚拟智能家居系统中语音交互功能调用采用Java编程来实现,并封装了三类接口: 1)常量类设置接口,包括TracktypeCon(声道类型接口),用于切换语音输入的声道类型,声道类型主要包括单声道与双声道两种;SampleRate(采样频率接口),采样频率的设置决定了语音采样的样本点生成数量,样本过少会降低语音识别的准确率,样本过多又会对系统性能产生影响,结合虚拟智能家居系统的实际运行情况,这里提供两种采样频率,分别为16 kHz和20 kHz;Parsetting(系统参数接口),用于对全局资源中所需参数进行初始化配置,并提供了全局变量设置的对外接口。 2)外部调用类接口,包括ListenintMec(监听事件接口),采用Android事件监听机制监听外语语音的输入请求;ResultsDataOn(结果数据获取接口),获取语音识别的结果数据;ErrorDataOn(错误信息获取结果),用于捕获识别过程中的异常错误信息;StartSpeech、EndSpeech分别是开始识别与结束识别的调用接口。 3)中间类控制接口,主要实现语音识别服务系统的内外部功能衔接控制。接口定义的代码如下: MiddleControle(int TracktypeCon,int SampleRate,int Area,int Amountres,int frequency,int genderage,int TypeChannelTo,string OnBase,TManager Telmanager) MiddleControle中的形参主要涉及外部的参数设置,例如声道选择和频率设定等,以及全局变量的传递和语音控制命令的传递。 以上三种常用类型的接口功能调用实现了3D虚拟智能家居系统的语音交互功能,结合后端的语音识别算法,基本满足了系统的交互需求。 本研究结合3D虚拟智能家居系统中语音交互的功能需求,围绕语音识别技术的算法原理和策略应用展开深入研究,在语音识别策略中采用隐马尔可夫算法实现了对系统命令的语音识别,通过预处理策略改进实现了噪声的有效过滤。并在此基础上尝试构建了语音交互服务系统,通过常量类设置接口、外部调用类接口和中间类控制接口调用实现了3D虚拟智能家居系统语音交互功能的扩展。 隐马尔可夫算法是语音识别技术中应用非常成熟的一种算法,因此针对孤立词的识别效果非常好,准确率可达到90%。但是由于其对噪声过滤的性能较差,因此还需进行另外的噪声处理,也就增加了系统执行开销。当交互环境非常嘈杂的时候,对语音识别的准确度也会有很大影响。在之后的研究当中,本研究还将针对系统性能的进一步提高与噪声的有效屏蔽等问题继续开展语音识别策略的改进研究。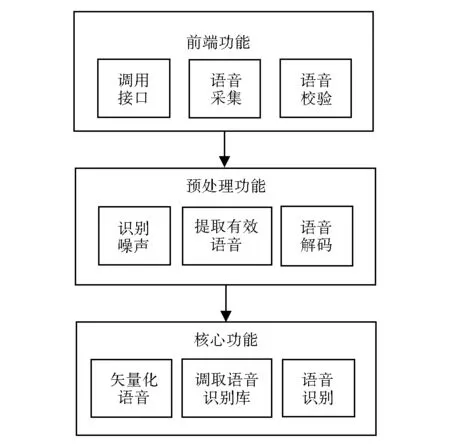
4 语音识别策略的应用
4.1 语音交互服务系统
4.2 语音交互功能的接口实现
5 结论
猜你喜欢
电子制作(2019年20期)2019-12-04
计算技术与自动化(2019年3期)2019-11-05
阅读(快乐英语高年级)(2019年5期)2019-09-10
电子制作(2019年14期)2019-08-20
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电子制作(2019年9期)2019-05-30
科技创新导报(2019年31期)2019-04-07
小说界(2018年5期)2018-11-26
电子制作(2018年1期)2018-04-04
