
基于大数据分析的大学生就业率评估模型仿真研究
2019-09-25 04:16王程
微型电脑应用 2019年9期
王程
(商洛学院 经济管理学院, 商洛 726000)
0 引言
大学生就业问题越来越受到社会的关注,大学教育也已经常说的精英教育逐步变成了大众教育[1],随着就业形势的越来越严峻,大学生就业情况成为一所高校教育优良程度的评判标准[2],就业率较高的高校成为大家的首选。对于高校来说,就业问题需要进行指导和管理,对于这种管理的流程需要分析不同的角度,从学生角度来分析,大学生就业首先要有一个合理的评估方法,对于学校的角度,学校对于毕业生的就业要增加管理的力度。针对高校的就业情况,除了必要的统计之外,更加需要建立以模型为基础的评估制度,该模型需要考虑学生的考试成绩等等,并且通过学生的综合能力,比如科研能力、社交能力等等形成一种特征参数,该参数是通过筛选甄别海量的数据所归纳出来,基于大数据的分析总结出评估模型,并且运用该模型支撑未来毕业生的就业选择问题,提供必要的理论依据。
1 大数据与大数据管理
1.1 大数据定义与特征
在目前的业界尚未对大数据由清晰明确的定义,它的第一次出现是在麦肯锡公司的报告中出现的,在维基百科上的较为模糊的定义是很难运用软件的手段获取大量的内容信息,对其处理后整理得出的数据集合。其他计算机学科的学者给出的定义是数据的尺度极为巨大[3],常规的数据处理软件无法对数据识别、存储和应用的海量数据信息[4]。虽然无法确切地给出精确的定义结论,然而在大数据领域的学者和教授们都是认可大数据所具有的几个明显特征,第一种是规模性[5],数据的规模已经无法用当前的计量模式去计算,获取数据的行为也需要发生变化。第二种是高速性,海量数据往往是以人类无法想象的速度来产生的,在很短的时间内就可以积累出海量的数据。第三种是多样性[6],数据的多样性,既是指数据的表现形式是多样的,文字、音频、视频、图片等等,另一方面又具有内容的多样性,许多不同观点的内容。互相交织在一起,十分复杂,难以有效管理。
1.2 大数据管理
大数据的管理是一项极为艰巨又困难的项目,其主要的措施包含三个方法,分别是对数据的集成、数据分析和数据解释[7]。首先对于收集到的数据先进行必要的集成和存储,然后再对数据进行分析,对于大学生就业问题,应考虑就业问题的繁琐性,对就业情况的分析要全面具体,更要注重某一因素的变化带来的就业情况的变化。针对分析后的数据归纳时,要有合理的解释过程[8],对数据的解释和结果归纳在将来都要作为理论基础来指导就业实践问题,其分析的数据信息收集图如图1所示。

图1 基于大数据管理的信息收集监测系统细节图
大数据的分析与管理,尤其涉及大学生自身能力与综合实力考量的数据分析,有助于提升学生学习的兴趣,增加学生的创业意识和学习能力,针对该模型时的信息统计,进而得出就业率评估模型,如图2所示。

图2 基于大数据管理的信息统计分析图
2 学生就业率估计原理分析
在创建大学生就业率评估模型的过程中,通过获取毕业生的历史毕业结果与就业数据,将这些数据集成在一起[9],然后进行分类总结,提取出大学生们的就业数据中的特征参数,转换为建立模型所必要的特征向量,具体的原理分如下面的描述,首先假设R表示样本数据集,O代表就业估计的期望信息量,K代表历史学生就业数据,Y代表学生就业的数据样本,则利用式(1)毕业生的就业估计的样本数据进行分类所示。p代表学生就业的分类函数,T表示学生就业数据的不同方式的类型,如式(1)。
(1)
对于大学生来说,F表示的是高校毕业的学生就业状态向量,w代表高校毕业生中待预测的毕业生利用式式子(2)组建学生就业率估计模型如下式(2)。
(2)
传统的就业分析模型不适于互联网时代数据量越来越复杂的情形,所以传统的方法对数据的分析既不高效,又容易出现偏差,分析和预测的结果往往不会让人满意,所以基于大数据的分析更加精确一些。
3 基于大数据分析的学生就业率估计模型
4.1 大学生就业分类方程的组建
在创建就业评估模型时,考虑每一个学生的特性,不同特性信息首先分类,根据决策树,保证分类到的数据信息可以获得最大数据增益率,组建的方程如下所示,由S代表给出的学生就业数据集,n代表其就业学生的数据样本数量,{C1,C2…,Ck}代表数据类别的集合,针对Si代表学生的不同就业信息类别Ci中的样本数量,并且需要满足于如下的式(3)的条件,如式(3)。
(3)
并且在综合考虑后,则可以利用式(4)的表述对于给定的待估计学生信息数据进行分类的期望信息。
(4)
其中,对于数据样本A的划分熵由Z来表示,Sij则代表条件概率,从而得到当前的样本数据集合A的信息增益如式(5)。
(5)
为了计算出高校毕业生的就业率的最大信息增益率,需要利用毕业生不同属性的学生信息熵[10],该熵值用split(A)来表示,用以针对数据A的分析,特此加以区分。总之分析出的学生毕业后的就业信息增益率如式(6)。
(6)
综上所述,可以根据式子分析出对于评估模型某些定性的分析方式,在创建了基于决策树的高校毕业生的就业分类方程后,主要是为了求得毕业生的特征向量,使其满足于最大的信息增益率,获得最为优化的结果。
4.2 基于灰色系统理论的学生就业估计模型
通过上面的高校毕业生就业率的增益率数据分析的理论基础,对于这些数据采用灰色系统理论进行分析、总结归纳,来估计未来毕业生的就业情况。灰色系统理论是控制论中的重要理论,对小样本的不确定性问题有着良好的指示,对于评估学生就业率的问题鲁棒性很强,同时应用该理论到模型建立问题中去,依据上述的最大信息增益率基础,设定模型建立的步骤,式(7)作为宏观预测任意年度的某一学科门类毕业生就业数量的模型,则该模型的残差为式(7)。
(7)
其中,分子上的两个表达式相减,被减数和减数分别是灰色微分方程的时间相应序列。下一步骤的展开则用来得到该数据样本的白化方程,σ代表对于评估的模型的关联度检测,X是指毕业生数据信息的紧邻均值序列,Y代表当前全体毕业生的就业率状态,B则是指明历史上的就业率信息,运用灰色理论的式(8)的白化方程为式(8)。
(8)
由U来代表对学生就业估计所需的关系数据,ε代表毕业生的就业信息特征最大化的类内的相似性关系,M是指模型的小误差概率,则利用式子可以创建待评估的整体的学生就业估计模型W,具体如下式(9)所示,其中γ是数据信息的维度。
(9)
为了更好地实现基于大数据分析模型进行大学生就业成功率评估的可行性,将实验重点关注评估的一致性作为评价指标,同时针对大数据分析模型进行大学生创业成功率评估的精度也作为考量的对象。在实现中为了彰显实验的全面性和公正性,将文献中所提基于统计模型作为对比模型进行共同的分析和对比,从评估的全面性和评估的误差率这两方面来对大学生就业成功率评估的质量进行考量。利用Matlab2017的软件,在Windows平台下进行安装,基于Intel Core i7的处理器,在Matlab中输入上述分析的模型语言转换成Matlab的函数和输入的数据信息。
4.3 实验结果与分析
利用matlab搭建大学生就业率评估模型,如表1所示。
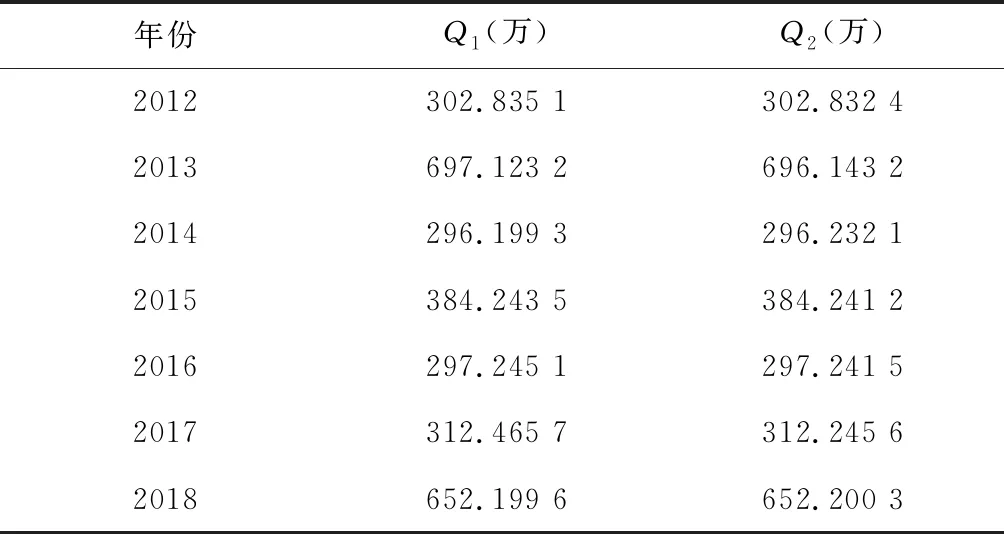
表1 模型就业率评估的误差
对其进行仿真,评测该模型的有效性,实验数据选取某省高校的毕业生数量,通过与统计数字的比较就可以分析出,Q1和Q2的数量上基本一致,表现出其误差很小,数据拟合出的曲线非常一致,Q1是模型预估出的就业毕业生的数量,Q2是真实的毕业生数量。
同时为了体现该评估模型的优越性,需要与其他评估模型作出比较,针对聚类分析相关的预估模型,作出合适的比较过程。针对误差比较,对比两种模型的误差分析,可以确切地看出本文采用灰色系统理论建立的模型的误差小于聚类分析的构建模型,如下图3所示。

图3 采用不同模型的评估误差对比图
接下来再比较分析两个模型的稳定性,可以清晰地分辨出其稳定性的差异,该差异体现出本文的模型评估的稳定性较好,几乎都处于85%以上,其高可靠的稳定评估的毕业生就业率较为平稳,不会出现较大的变化差错,其具体的描述为图4所示。

图4 采用不同模型的稳定性对比图
以上的仿真结果可以表明,该评估模型对于就业率的分析较为高效,为后续分析就业的措施和政策的实施,提供了一定的理论基础,具有良好的指导性指示。
5 总结
本文为满足对于大学毕业生就业率的探索,基于大数据的分析,找出适当而合理的分析模型,该模型分析出毕业生的就业情况,作为一定的就业率分析依据,首先,介绍大数据的定义与特征,以及本文基于大数据的特征构建模型,最后将模型与传统的预测模型比较,在稳定性的方面显示出较为优越的特性,同时其误差也表现的较为微小。在后续的研究中,将继续提高试验的精度,引入神经网络,对模型的确立更加精准。
猜你喜欢
昆明医科大学学报(2022年4期)2022-05-23
大学(2021年2期)2021-06-11
英语文摘(2020年9期)2020-11-26
意林(2020年15期)2020-08-28
意林·全彩Color(2019年7期)2019-08-13
发明与创新·职业教育(2018年6期)2018-05-14
新闻前哨(2014年11期)2014-12-25
职业技术教育(2014年9期)2014-07-08
浙江人大(2014年5期)2014-03-20
浙江人大(2014年1期)2014-03-20
