
面向大学教育的排课算法研究∗
2019-10-08 07:12尚英武
计算机与数字工程 2019年9期
尚英武
(咸阳职业技术学院 咸阳 712000)
1 引言
调度是由一组有限的资源执行一组给定的任务的问题[1]。作为典型的调度问题,大学课程调度问题引起了人工智能和运筹学的高度重视。在经典的排课问题中,一系列事件(如课程和考试)被分配到一些“课堂时间”的时段,以满足一系列约束[2~3]。
排课算法问题可以是考试或课程安排。在考试安排中,一个目标是尽可能均匀地分散考试,而在课程安排中学生要求考试时间尽可能紧凑[4]。本文考虑了针对课程计划的大学排课问题。由于课程、讲师以及教室数量的激增,对于每个学期的课程计划对高校教务人员来说总是一项复杂的工作[5]。
大学排课问题是NP问题,包括两个主要决定:讲师分配和课程安排[6]。这两个安排需要考虑到讲师的专业资格、对课程和上课次数的限制,讲师加班的合理分配以及对教室安排的可行性[7]。而且,课程安排还应避免教师时间表和课堂上的冲突。
可将大学排课问题的约束条件可以分为两类:硬约束条件和软约束条件。只要满足所有的硬约束条件,就可以实现一个课程计划。硬约束条件的一个典型例子是,没有一个老师一次最多能教一门课[8]。另一方面,软约束条件是那些虽然必要、但应尽可能实现的要求。因此,软约束条件也可以称为首选项,用于评估解决方案的质量。软约束条件包括讲师加班的合理性等[9]。排课算法的主要目标是找到一个可行的时间表,满足所有的硬约束,最大限度地满足教师和课程的软约束[10]。
本文首先描述排课问题的不同方面,然后将排课问题表示为整数线性数学模型。为了对模型进行优化求解,本文提出了三种基于人工免疫、遗传和模拟退火算法的启发式算法。最后通过仿真试验对模型的有效性和不同算法的性能进行验证。
2 排课问题的表述
大学排课问题的对象是一组讲师、一组课程和一组教室,以及待排课日期和每天固定的授课时间段[11]。在每个授课时间段,每个教室可以提供给一门课程。每位讲师和对应的专业课程之间有较为固定的对应关系。每门课程只能在教室和授课时间的一个子集中呈现。排课算法的目标是最大限度地满足课程数量安排,并尽量减少教室的使用数量。
大学排课问题通常用整数线性规划公式来建模。排课算法中所使用的符号和参数如表1所示。

表1 数学模型中符号的含义
排课问题的数学模型表述如下:

约束条件表述如下:

式(1)为课程调度的数学表达式。式(2)确保了每门课程都被安排。式(3)是保证教师具有教授的课程,并且确保每位教师在任何时间点最多只有一门课程。式(4)确保教师在他们空闲的日子能够讲课。式(5)保证一次只能在每个教室中只安排一个课程。式(6)是确保每个教师都被分配到其对应的专业课程。式(7)指定每个课程被分配给符合条件的课堂。式(8)和式(9)定义了决策二元变量和。
3 解决算法
由上可知,排课问题是NP问题,因此最有效的算法是启发式算法。常见启发式算法包括图形着色启发式、模拟退火、进化算法、萤火虫算法、两阶段启发式算法以及蚁群算法[12~14]等。基于对上述算法的研究,本文提出了三种算法:人工免疫算法、遗传算法和模拟退火算法,并比较这三种算法在解决课程调度问题中效率。首先阐述在算法中使用的编码方案。
3.1 编码方案
使用两个二进制矩阵和调度规则来表示解空间,如图1所示。
第一个二进制矩阵显示课程和讲师对应关系,也就是把讲师分配到对应的课程在这个矩阵中,行和列分别表示课程和讲师,其中“1”表示分配,而“0”表示不分配,“-”表示相应的讲师不能讲授课程。
第二个矩阵表示每个讲师在某个工作日是否安排上课。在这个矩阵中,行和列分别表示天和讲师,其中“1”表示安排上课,“0”表示不安排上课,“-”表示当天该讲师因故(出差、调休等)不能安排上课。注意每天讲师最多可以安排3门课程,因此讲师的安排上课的天数取决于分配的课程数量。

图1 编码解决方案的示例
应用的调度规则是把课程分配至教室和对应的时间段。首先确定讲师分配和上课日期的分配,再对教室时间段的安排进行确定。也就是说,哪个课程安排在什么教室的哪些时间段是排课问题的硬约束条件。排课算法遵循以下规则:在该课程讲师足够分配的前提下,每个课程都分配到第一个符合课程要求的教室。如果一个讲师被连续安排上课超过一天,则其授课课程将以符合该讲师要求的最高优先级安排上课时间段和教室。
以图1为例对编码方案进行说明。图1展示了一个考虑八个课程、四个讲师、两个工作日和两个教室以及每天有四个上课时间段的排课问题。在图1所示的解决方案中,课程1和课程6分配给讲师1,课程3和7分配给讲师2以及分配2、4、5和8分配给讲师4。没有课程分配给讲师3。讲师1和4被安排到第一天上课,讲师2和4在第二天,而讲师4在第一天和第二天都被安排上课。
3.2 遗传算法
遗传算法(Genetic Algorithm,GA)是针对传统方法难以解决的一些问题而设计的。目前,遗传算法是众所周知的基于种群的进化算法,可以解决离散和连续优化问题。遗传背后的想法来自达尔文的“适者生存”的概念,这意味着良好的父代会产生更好的子代。
3.2.1 算法框架
GA算法搜索一个由染色体数量表征的解决方案空间,其中每个染色体代表一个解决方案的编码[15]。适应值根据其性能分配给每个染色体。染色体越好,适应值越高。染色体数量在一组算子控制下进行迭代演变,直到符合迭代终止条件后形成最终最优染色体。遗传算法的典型迭代过程阐述如下。初始种群中最好的染色体被直接复制到下一代(繁殖)。选择机制是从当前种群中选出适应值较高染色体,赋予其较高的交叉繁殖机会。选择出染色体被交叉产生新的后代。经过交叉繁殖过程后,每个后代可能会通过另一种称为突变的机制进行突变遗传操作。完成上述两个遗传操作后,对形成的种群进行适应值计算,并重复上述整个过程。上述GA算法的框架如图2所示。

图2 GA算法框架
3.2.2 种群初始化和选择机制
GA的解空间包含许多染色体,每个染色体代表一个可能的排课方案。在GA算法中最初的染色体组成初始种群。最初的染色体是由可能的排课方案中随机生成的。
在初始化算法之后,通过目标函数来评估每个染色体并计算其适应度值。依据适应值确定染色体k参与交叉遗传操作机会的计算公式为
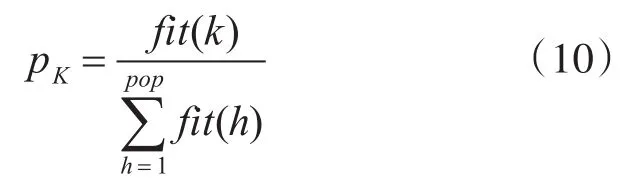
式(10)中fit(k)是染色体k的适应度,pop是初始种群的数量。
3.2.3 交叉和突变遗传操作
交叉遗传操作目的是创造适应度更好的子代。交叉遗传操作通过交叉算子在父代染色体之间进行交叉遗传。值得注意的是,交叉操作必须避免产生不可行的解,即本文中的不符合约束条件的排课方案。交叉遗传操作的步骤描述如下。
首先随机产生均匀分布在0和1之间的随机数。如果这个数字小于0.6,那么来自父代的那个讲师的两列(比如,来自图1中教师-课程分配表和教师-上课日期分配表中对应讲师的两列)被复制到新的排课方案中。新排课方案的其他列由父代排课方案填充。新排课方案可能需要对其不符合约束条件的地方进行修改才是可行的排课方案。比如,在讲师和课程的分配中,如果课程分配给两名讲师,则随机选择一名讲师,另一名讲师被划掉;如果一个课程没有分配给任何一个教师,则它被随机分配给一个讲师。
交叉操作后,每个排课方案由变异算子进行突变。应用突变的主要目的是为了保持群多样化避免收敛到局部最优。本文使用变异算子描述如下。随机选择一名讲师,然后将其安排上课次数最多的一天和其安排上课次数最少的一天进行交换。将上述突变操作随机应用到所有讲师,并且不重复应用到任何以为讲师。这将导致了重新安排每位讲师的排课方案。完成突变操作后,对种群中染色体适应值重新计算,选择这些新排课方案中的最佳方案。
3.3 模拟退火算法
模拟退火算法(SA)是一种基于局部搜索的元启发式模拟退火过程[15]。SA包含一个称为验收标准的机制,使其能够摆脱局部最优。验收标准决定是接受还是拒绝新生成的解决方案。在这种机制下,甚至可以接受较差的解决方案。
3.3.1 算法框架和验收标准
模拟退火算法通过对初始解决方案进行处理,并进行一系列的移动,获得最佳解决方案。算法想法是通过一个算法操作由当前的解决方案x生成一个新的解决方案s。验收规则是用来确定接受或拒绝这个新的解决方案。验收规则由温度参数t控制。首先计算两个解决方案的客观值之间的差异。如果Δ≤0,则接受该解决方案;否则,以等于exp(Δti)的概率接受解决方案。在每个温度ti,算法继续进行固定次数的移动。SA移动时,温度ti逐渐下降。温度下降的计算公式为

式(11)中初始温度通常设定为50,α=0.97。SA算法总体框架如图3所示。

图3 SA算法框架
3.3.2 移动操作
本文通过以下过程从当前的排课方案中产生一个新的排课方案。随机选择一门课程,并将其分配给另一位合格的讲师。值得注意的是,课程重新分配会影响两名教师,一名课程减少,另一名课程添加。因此,这两位讲师上课的天数可能需要更新。基于这个新的课程安排,两位教师的上课日期的安排也被更新。
3.4 人工免疫算法
人工免疫算法(AIA)是一种基于总体的元启发式算法,它通过几种编码的解决方案进行并行搜索[16]。AIA的基本思想来自对自然生物体的生理免疫系统的模拟。免疫系统是防御外来病毒(抗原)的身体。这是由一组抗体完成的。在检测到抗原的情况下,鉴定该抗原的抗体通过克隆增殖。也就是说,无论何时抗原渗透到体内,他们首先认识到这些抗体更有资格与抗原的侵入作斗争,然后系统在下一代产生更多的这些抗体的变异。
每种抗体的质量由亲和力值表示。亲和力较强的抗体可以更好地与抗原作用。抗原是指正在考虑的问题。每个抗体是一个可行的解决方案,亲和力是抗体获得的目标函数值。
3.4.1 算法框架
AIA用抗体种群搜索问题空间。每个抗体依据其性能将被赋予一个亲和力值。抗体越是理想,亲和力值越高。使用免疫算子,包括克隆选择算子和亲和力成熟算子,从当前的种群中产生新的种群。
克隆选择旨在繁殖消除抗原的更好抗体。亲和力成熟算子由超突变和受体编辑组成。超突变对应于产生类似的但不完全相同的新解决方案。较低的抗体应该以较高的速率超突变,而较高的抗体则以较低的突变率。受体编辑是确定超突变率的机制。
AIA算法框架为:首先使用一个用户定义的亲和函数计算每个抗体的克隆数量;随后所有增殖的克隆体都聚集在一个突变池中;然后突变池的克隆被超突变产生新的抗体;最后对新种群进行评估,整个过程重复。初始的染色体是由可行解随机生成的。
3.4.2 克隆选择过程
亲和力值测量是衡量每种抗体消除抗原的能力。亲和力值越高意味着与抗原作用的抗体越好。假设优化问题作为抗原和编码方案的抗体。更好的抗体可以更好地对抗优化问题。设定每个抗体的亲和力等于目标函数值。
克隆每个抗体进入突变池的概率与其亲和力值成正比例关系。因此亲和力越高的抗体越有可能具有更多的克隆。变异池具有固定数量的克隆体,其中一部分是当前种群中最好的抗体的克隆体,剩余部分是采用选择机制选择部分抗体的克隆体。
3.4.3 亲和力成熟过程
亲和力成熟过程的主要功能是对池中存在的所有克隆体进行随机更改。每个克隆根据亲和值经历不同的变化率。较低的克隆经历较高的变化率,而较好的克隆受到轻微的变化。这些改变基于超突变过程完成。
首先对低速率的超突变过程进行描述。随机选择一门课程,并重新分配给另一位具有最高优先级的合格讲师。课程的重新分配影响到两个讲师,一个课程减少,另一个课程增加,这两位讲师的上课天数可能会发生变化,因此要对讲师的上课日期安排进行更新。基于对所有课程的本地搜索进行上述随机、不重复重新分配。通过重新分配每个课程来产生n个新的排课方案。从中选择出最佳的排课方案。
对于高速率的超突变过程,本文使用GA中定义的变异算子。通过定义一个标准来确定是否使用高速率超突变的变异算子。如果满足式(12),则进行低速率超突变,否则使用变异算子进行高速率超突变。

本文使用类似于模拟退火的验收标准的方法来确定是否接收新的排课方案,这导致除了接受更好的新排课方案外,可能还会接受较差的排课方案。通过这个验收策略使得算法容易避免陷入局部最小值。同时为了保证算法效率,算法应用了精英克隆策略,意味着最好抗体将直接被复制到下一代。
4 仿真验证
利用两组实例的计算评估模型的性能和所提出的算法。第一组由较少讲师和课程数量组成,用于评估模型解决问题的能力以及算法的一般性能。该组包括10对课程讲师组合(m,n):(20,5),(20,7),(40,10),(40,15),(60,10),(60,15),(80,15),(80,20),(100 ,20)和(100,25)。
第二组包括较多讲师和课程的数量组成,通过这些实例比较所提出的算法的性能。该组实例包括6个组合(m,n):(100,20),(100,30),(200,30),(200,50),(300,50)和(300,70)。
两组实例的其他参数假设还有:200间教室、每周有5个工作日以及每天有3个时间上课段。我们通过随机生成问题的其他参数为每个排课问题生成10个实例。
模型和算法分别在CPLEX和JAVA中实现。它们运行在4.0 GHz Intel Core 2 Duo和8 GB RAM内存的个人电脑上。该模型允许最多600s的计算时间。算法的停止条件被设置为固定为nm秒级别的CPU运行极限。随着课程或讲师的数量的增加,这个停止标准需要更多的时间。相对百分比偏差(RPD)被用作模型性能指标。RPD计算方法为
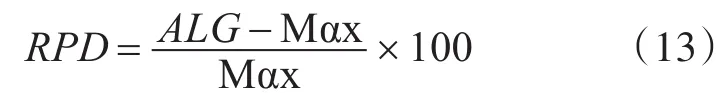
式(13)中ALG和Max是算法计算出的排课方案和给定实例的上限。其中给定实例的上限等于为给定实例找到的最佳目标。
4.1 算法参数设置
GA和AIA的关键参数是种群大小,SA的关键参数是降温速率。种群大小分别设置为{20,40,70,100},而温度下降速率则被设置为{0.95,0.90,0.85,0.8}。针对第一组数据生成20个不同的实例。然后,我们通过不同算法分别计算。计算结果如图4所示。

图4 测试算法的平均RDP
由图4可以看出,GA算法的最佳种群大小为40,而AIA为40。对于SA算法最佳温度下降速率为0.95。
4.2 较少课程和讲师数量的实验
通过本文模型来计算小规模排课实例。计算结果如表1所示。

表2 较少课程和讲师数量的模型计算结果
由表1数据可以看出,该模型能够在不到60s的时间内解决m=60和n=15的实例。m=80的实例需要小于500s。但是该模型不能在600s内解决m=100的实例。
采用三种测试算法对排课实例进行计算,得出的平均RPD如表3所示。

表3 不同算法的RDP
由表3可以看出,AIA优于其他算法,平均RPD为0.87%。其次为GA,为1,47%。表现最差的算法是SA,平均RPD为1.91%。综上所述,AIA在小规模的排课问题中表现最好。
4.3 较多课程和讲师数量的试验
在本节中,所提出的算法(GA,SA和AIA)在第4节中提到的60个较大规模的排课问题上进行比较。表3显示了算法的结果。图5显示了三种测试算法的平均RPD和最小显着差异(LSD)间隔。

表4 不同算法的平均RPD
由表4和图5可以看出,表现最好的算法是AIA,平均RPD为0.63%。其次式GA算法,平均RPD为1,66%。最后是SA算法,其平均RPD为2.89%。
图6显示了算法的性能与课程数量的关系。

图6 算法的平均RPD与课程的数量
就课程数量而言,AIA在不同规模的排课问题上保持了基本稳定的优于其他算法的性能,而SA在大规模排课问题上性能表现相差较大。
5 结语
对于大学课程安排的问题,本文将目标函数定义为安排课程来最大化教师、课程和上课日期的利用效率。首先以整数线性程序的形式对排课问题进行数学建模。仿真实验证明了该模型能够解决多达6门课程和15名教员的问题。此外,本文开发了三个先进的启发式来解决较大规模排课问题。算法基于人工免疫,遗传和模拟退火算法。在仿真实验中对算法参数进行优化调整之后,通过与模型得到的最优解进行比较来评估它们。并且将这些算法应用在一组较大规模的排课问题上进行计算性能比较。实验结果表明,所提出的人工免疫算法优于其他算法。
猜你喜欢
环球时报(2022-09-20)2022-09-20
今日农业(2020年24期)2020-12-15
家庭影院技术(2020年10期)2020-12-14
家庭影院技术(2020年6期)2020-07-27
家庭影院技术(2020年2期)2020-03-25
科学之谜(2019年3期)2019-03-28
科学之谜(2018年8期)2018-09-29
小学生导刊(2018年1期)2018-03-15
中学生理科应试(2016年4期)2016-11-19
恋爱婚姻家庭·养生版(2016年9期)2016-09-07
