
基于改进SVM算法的聚焦爬虫设计与实现∗
2019-10-08 07:12乔平安田晶晶
计算机与数字工程 2019年9期
乔平安 田晶晶 任 静
(西安邮电大学 西安 710061)
1 引言
作为Internet搜索引擎的核心部分,网络爬虫[1]是如今研究重点之一[2],它面向整个互联网并从大量的网页中爬取资源,是搜索引擎的数据来源。随着互联网信息量的骤增,传统的搜索引擎已无法满足不同环境、不同背景下用户对主题或领域相关信息的查询需求,并存在网页采集周期长、信息更新不及时以及查准率不高等诸多问题。
针对这种情况,主题搜索引擎以更专注于某一主题、速度更快、信息更新及时等诸多优点成为研究的热门技术。本文针对网页特征提取算法,将UM值计算方法与SVM分类算法中权重的计算方法结合,设计实现了一种基于改进SVM算法的聚焦爬虫,提高了聚焦爬虫算法的性能,在保证不降低分类准确性的情况下减少训练时间,提高分类的效率。
2 相关工作
聚焦网络爬虫是为了爬取与某主题相关的信息而产生的网页信息爬取工具。因此,聚焦网络爬虫的首要问题是使用何种方法去判断主题与所要爬取的网页信息内容是否相关,以及依据主题相关度对统一资源定位符(Uniform Resoure Locator,URL)进行优先级排序来提高爬取结果的精确度和搜索效率。而网页文本特征的提取是确定网页主题的关键之处,文本特征提取结果的好坏和特征的数量直接影响网页爬取的效果和主题相关度的计算速率。目前常用的文本特征提取方法主要有以下两种类型:1)依据词频信息提取文本特征或者把所有的词都作为文本特征,但此方法忽略了语法结构的特点以及词汇之间的关系,同时特征数量也会很多;2)利用串匹配算法选择一些字符串作为文本特征,但该方法会提取到大量的“无价值”的字符串序列,从而使提取的文本特征不能代表网页文本的特征,且文本特征数量较多。针对文本特征的提取问题国内外学者针对该研究提出了不同的算法思路:Schleimer等提出的Winnowing算法,是把滑动窗口内最小哈希值选取为指纹特征[3],该算法的问题是数字指纹密度较大[4];针对该问题,韦永壮等提出了CCDet算法,根据句号特征串匹配规则进行文本特征提取,抽取句号前的若干词语作为句号的特征,进行相似度比较[5],但计算量很大;徐琴提出合并整体词的概念,将具有整体性的词语进行合并将其作为文本特征,通过二次特征提取算法来减少数字指纹数量[6],但是该算法存在计算复杂度高的问题;Sidorov等提出了一种基于语法结构的的n-grams特征提取算法,将语法信息引入特征提取过程中[7];Vani等提出利用文档的概念在不同的结构层次上对文档和段落级别进行检测[8]。
本文针对特征提取存在的计算复杂度高、特征数量多的问题,提出结合SVM算法中词权重的计算和UM计算的词权重综合作为特征词的权重,提高特征提取的精确性和降低特征向量的维数,从而提高爬取的效率、查全率和查准率,且计算复杂度降低。
3 特征提取方法改进
3.1 网页特征提取
在利用SVM分类算法对网页进行分类前,需将网页的每一个文档表示成为一个特征向量,以此表示网页的信息,而特征词是特征向量的一个分量。SVM算法中采用向量空间模型(VSM)表示网页文本特征。
VSM[9~10]将文档的内容用多维特征向量表示出来,将文档 d 用特征向量{<w1,t1>…<w6,t6>…<wi,ti>}进行表示,其中 wi为文档中的词组,ti为该词组在文档中所占的权重,词组的权重用TF-IDF(term-frequency-inverse document frequency)算法获得。
词频TF(d,t)可通过式(1)计算:

其中n(d,t)是词 t在文档d中出现的次数,分母是文档中词t的总量。词t的逆文档频率IDF(t)可用式(2)得到:

其中D为所爬取的文档总数,Dt是含词t的文档数量。词t在文档中的权重TF-IDF可以通过式(3)得到:

通过VSM可以将文档表示成较为标准的特征向量,即每个特征向量都是一个n维的空间向量,便于对文档进行分析处理。但利用TF-IDF算法得到的有些特征对文本分类作用不大,并使向量空间的维数增大,甚至会降低SVM分类的准确性。
3.2 聚焦爬虫特征提取优化
3.2.1 特征词权重优化
通常在对文本进行分类时,需要利用文本的特征词来进行预测,而特征词则由最确信的词确定。针对以往常用特征提取方法中这样类似的问题,本文把UM值的特征提取方法[11]运用到聚焦爬虫算法中。通常,UM描述的是一个特征项属于一个类的概率,用式(4)、式(5)计算特征项的概率值。当UM的值越近似1时,这个特征项属于这个类别的概率就越大,相反,当UM的值越近似0时,这个特征项属于这个类别的概率就越小。

tf(t,c)是特征项t在c类中出现的频率,tf(t)是特征项t在整个类集合中出现的概率。阈值th的范围在[0,1),若特征项的UM<th,则被丢弃;若特征项的UM≥th,则保存。因为在SVM算法中每个特征项都有一个权重,所以同时也将UM值作为这个特征项的权重。因此,若特征项的UM值高,则它的权重就大。以此剔除特征词在文档中的权重TF-IDF值比UM值小的权重值,从而减少向量空间的维数和降低算法的复杂度提高分类的准确率。
3.2.2 阈值设定的方法
目前针对高频词阈值的设定方法主要是频次选取法、前N位选取法、中心度选取法、高低频词界定公式选取法和普赖斯公式选取法。文献[11]对五种方法进行了对比介绍,结合本文权重优化计算方法,本文的阈值的设定选择普赖斯公式选取法进行计算。
普赖斯公式最早是用于确定高频被引用的文献,从而确定某研究领域内的核心作者。因普赖斯公式相较于用高低频词界定公式更简单,比自定义选取法更科学,逐渐被学者们接受并应用于不同领域的研究中。其高频词阈值根据普赖斯公式确定,计算公式:,其中M为高频词阈值,Nmax表示区间学术论文被引频次最高值[11]。普赖斯公式可以用于确定领域核心文献,因此也可利用此公式确定领域核心关键词。将自变量Nmax表示为关键词的频次最高值即可,因此本文用普赖斯公式计算本文阈值th,其值设置为0.3。
4 聚焦爬虫的实现
4.1 支持向量机分类
本文利用SVM算法进行网页分类[12~13],其流程如图1所示。
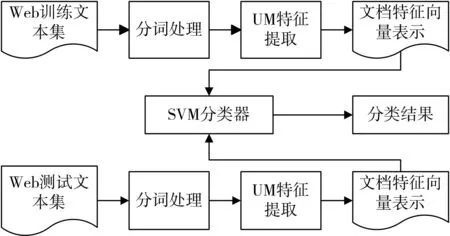
图1 Web文本分类流程
利用SVM分类算法进行分类的具体执行过程如下:
1)运用VSM把网页文本数据转化为SVM分类算法可以处理的格式。
2)选择合适核函数。通过多次试验众多核函数(线性核函数、sigmoid核函数、高斯(RBF)核函数),实验结果表明,选择RBF作为核函数所得结果最好。
3)计算最优的参数。通过试验对比遗传算法和粒子群优化算法(PSO)对SVM参数的优化,试验结果表明,采用PSO最优化算法计算SVM分类器的最优参数。
4)对文本样本数据进行训练并用测试集进行分类预测时,利用3)所得到的最优参数运用到SVM算法分类器中来进行实现。
对网页进行分类后,再进行聚焦爬虫可以提高爬取的效率,减少运算量和时间。
4.2 主题相关度分析
为了爬取的网页与主题有关,需要对网页进行筛选。在聚焦爬虫中若一个页面的主题相关度很低,则表明某些关键词只是偶尔出现在该网页中,且指定主题和页面的主题之间关系较小,处理其中的链接没有意义。因此,将主题相关度值小于设定阈值的网页舍弃,不需要处理该页面中的链接。
目前相似度的计算方法主要有向量内积、欧式距离、余弦距离等几种。本文聚焦爬虫的主题相关度[14]计算则采用余弦度量法,余弦距离越大表示文档的相似度越高。该方法是统计网页中关键词出现的频率,然后与初始的关键词按式(6)求余弦值,即可得到该网页的相关度。

对网页进行分析时,需要设定一个阈值r,若cos<α,β>≥r,则判定该页面和主题是有关联的。根据经验和实际要求确定r(取值范围是[0,1))的取值,如果r值设置的小则获得较多的页面,若r值设置的大则获得较少的页面。在本文的程序中,将阈值r设置为0.95。其中阈值r以相似与不相似文本的界限值来设置的,对于三组文本,相似度分别是0.85、0.74与0.95,数值上虽都接近1,但第一组是不相似的文本,第二组是相似度较高的文本,第三组是最相似的文本。而对于不相似的两组文本,相似度都集中0.85附近,因此以0.95作为阈值则可区分相似度高和不相似文本。
4.3 网页排序
网页排序[15]主要依据主题相关度值使网页主题相关度高的网页排在前面,以便用户更加快速地访问到所需要的信息。本文采用余弦距离除以该网页包含的链接个数,获得了更加精确的优先级顺序。
分析链接排序采用PageRank算法[16~18]排序,其排序结果相对更好。算法中网页的重要程度值可以表示为:P=w1·cos<α,β>+w2·R(u),其中cos<α,β>是通过上述的主题相关度分析计算出的主题相关度值,用于页面排序的网页PageRank值,其中d为界于(0,1)区间的阻尼系数,取值为0.85;w1为主题相关度的权重,w2为R(u)的权重,根据实验需求来设置二者的取值,但必须保证w1+w2=1,通过试验本算法设定w1取0.6,w2取0.4;u是一个网页,F(u)是u指向的网页集合,B(u)是指向u的网页集合,N(u)是u指向外的链接数。利用网页的重要程度值P对网页进行排序,得到网页的优先级序列。
4.4 评价指标
通常每个类的评价指标[15,19]是以查准率(Precision)和查全率(Recall)作为标准,而对于不同的分类器的性能进行评估时选用F1值(综合考虑准确率和查全率,得到的新评估指标F1测试值,也称为综合分类率)作为标准测度。计算公式如式(7)所示:式(7)中 Pi为类i的查准率,Ri为i的查全率,Ai为正确分到i类的测试文档数,Bi为错误分到i类的测试文档数,Ci为属于但未被分到i类的测试文档数。

4.5 聚焦爬虫实现
本文实验采用Java程序语言实现聚焦爬虫,在Eclipse开发环境下运行,具有良好的扩展性和可移植性。程序流程如图2所示。

图2 程序运行流程
Step 1:对种子和关键词进行初始化;
Step 2:从初始种子开始爬取网页得到其全部链接,并将爬取的链接添加到待抓取队列之中;
Step 3:对所爬取的网页利用SVM方法进行分类;
Step 4:从优先队列中获得链接,抓取网页;
Step 5:判断网页的相关度以决定是否舍弃该网页:利用VSM和余弦距离计算主题相关度,如果网页相关度大于阈值,则再将其添加到优先队列中等待爬取,否则舍弃;将有用链接放入等待抓取的URL队列;
Step 6:以最佳的搜索策略(OPS)[20~21]从队列中选取接下来要抓取的网页URL,并循环此过程,一直到满足爬取结束的某一要求时终止此次爬取;
Step 7:将所有被爬虫抓取的网页保存起来,对其进行一定的分析、过滤,并建立索引,方便以后用户的查阅和检索。就聚焦爬虫而言,这一过程所得到的分析结果可对以后的抓取过程给出反馈和指导。
5 实验结果及分析
本文主要是对传统的聚焦爬虫算法和基于改进的SVM算法的聚焦爬虫算法进行实验对比验证。本文算法分词工具采用ICTCLAS版本,选择云计算为主题,种子链接选取URL=http://cloud.csdn.net/进行爬取,利用SVM算法进行分类并存储。然后在各个分类块中进行聚焦爬虫,获取与主题相关的网页并计算F1值和主题相关度。
实验一:两种算法在爬取速度方面的对比。对传统的聚焦爬虫算法、基于改进SVM的聚焦爬虫算法与基于自适应遗传算法(AGA)的聚焦爬虫和基于遗传算法(GA)的聚焦爬虫进行爬取速率的对比。获取达到表1要求的网页,爬虫访问所需时间与网页数量变化的关系,如图3所示。

表1 算法与主相关度的对比
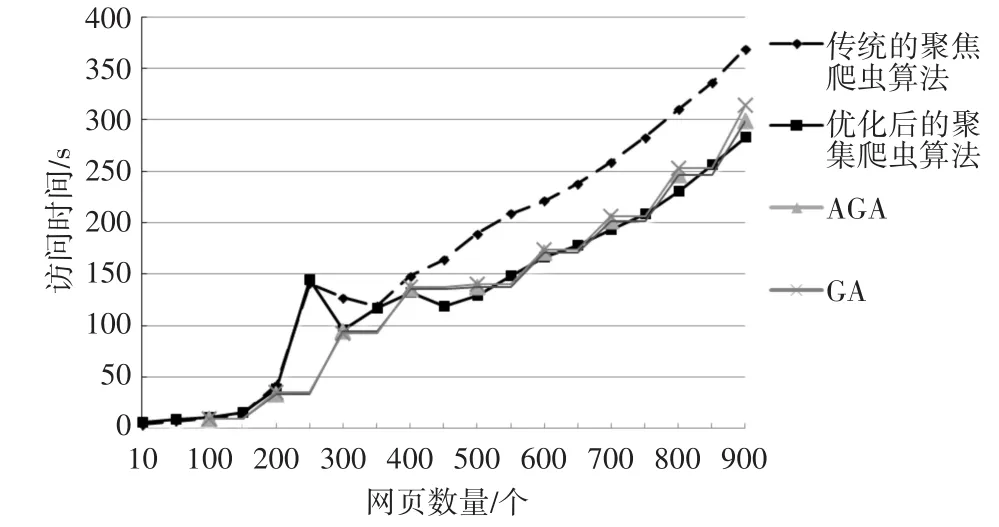
图3 算法访问时间与网页数量的变化
从图3中可以看出,在爬取网页的开始阶段,优化后的聚焦爬虫算法在爬取达到表1要求的相关网页时的速度不及传统的聚焦爬虫算法、AGA和GA,但随着算法的推进,优化后的聚焦爬虫算法抓取到的相关网页速度明显略高于传统的聚焦爬虫算法、AGA和GA。说明优化后的聚焦爬虫算法通过对特征词权重的调整和对网页进行分类调整后,在聚集爬虫爬取网页的过程中具有更大的覆盖率,能够抓取到更多的相关网页,速率较高。
实验二:两种算法在爬虫查全率和查准率(即F1值)方面的对比。在实验中增加可供测试的网页文档的数量。随着文档数量的增加,验证传统的聚焦爬虫算法、基于改进SVM算法的聚焦爬虫和基于AGA的聚焦爬虫的F1值随着网页数量的增多的变化关系,以及与广度优先搜索策略(BFS)进行比较,实验结果如图4所示。

图4 F1与网页数量的关系对比
从图4可明显看出,爬取到的网页在查全率和查准率(即F1)方面,对爬取到的网页利用优化后的特征提取方法和用分类器分类后,优化后的聚焦爬虫算法随着更深入的爬取F1明显比AGA提高的快和高;采用BFS抓取到的网页F1随着爬取的深入开始降低,AGA在持续一段时间后开始降低,而优化后的聚焦爬虫算法整体有较小的波动后区域稳定,说明优化后的聚焦爬虫算法能够爬取到更多的主题相关度高的网页,且随着网页数量的增多效果反而更好更稳定。
6 结语
通过研究,本论文实现了一个基于改进的SVM算法的聚焦网络爬虫,其中UM值的计算是通过词频进行特征词权重计算,之后用其对SVM算法中计算权值组成的n×n特征向量进行降维处理,剔除了“无意义”的特征词,从而降低主题词与网页特征向量匹配的计算复杂度。同时,利用主题相关度对URL进行排序,提高访问的速率。通过实验证明,算法提高了爬取与主题相关的URL时间、主题相关度以及查全率和查准率。提出的此算法在爬取网页URL时可进行控制,随时暂停爬取并访问爬取的网页,以验证是否为所需的网页;还可自行设置爬取的网页数量。在网络环境良好的情况下爬取网页的质量和效率都取得了不错的效果。
猜你喜欢
房地产导刊(2022年10期)2022-10-18
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
现代信息科技(2021年21期)2021-05-07
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
雷达学报(2018年5期)2018-12-05
智能计算机与应用(2018年5期)2018-10-20
电脑知识与技术·经验技巧(2018年1期)2018-05-30
