
不平衡数据的下采样方法研究∗
2019-10-08 07:12周建伟
计算机与数字工程 2019年9期
周建伟
(南京理工大学计算机科学与工程学院 南京 210094)
1 引言
近二十年来,不平衡学习(Imbalanced Data Learning)问题作为机器学习中的一个分支得到了产业界、学术界、和政府基金机构的密切关注,成为了业界各大会议研讨的重要主题之一[1~2]。现实生活中,数据不平衡问题广泛存在于各个不同领域,如网络入侵检测、图像识别、信息检索、金融欺诈检测、风险管理、生物医学应用和石油溢出检测等[3~4]。对于这些问题,相比较于多数类,少数类样本往往包含着重要的信息,且常常具有更高的错判代价,因此我们更关注少数类样本的分类准确性。比方说,信用卡欺诈检测的案例,欺诈行为在全部交易记录中往往占非常小的比例,将一个正常交易行为误判成欺诈行为,也许会失去一个信用良好的客户,带来一定的损失。可是将一个欺诈行为归类为了正常交易行为所带来的损害则更为严重。
对于不平衡学习。其根本问题是数据分布不均衡导致很多传统机器学习的分类算法性能大大减弱。因为大多数分类算法事先假设训练集具有相等的误分类代价或平衡的数据分布[5],所以这些算法在面对相对复杂的不平衡数据集时便不能有效地反应出数据的分布特征。如此一来,当这些传统分类算法在样本不平衡的数据集上训练时,经常会出现分类面偏倚的现象,使得最终无法获得令人满意的分类效果,甚至会出现模型完全失效的糟糕情况[6~7]。
不平衡学习因其重大研究意义而在机器学习和数据挖掘领域备受瞩目,多个业内主流的期刊和会议都专门针对此问题举办过专刊或研讨会[8]。例如 AAAI'2000[9]、ICML'2003[10]、ACM SIGKDD Exploration'2004[11]和 PAKDD'2009[12]。
2 基于高斯混合模型的下采样
处理类不平衡问题的方法通常可以分为数据、算法和集成这三个层面,其中从数据层面的解决方法一般有上采样、下采样和混合采样。而下采样技术的关键就是如何通过减少多数类样本使得两类数据达到相对平衡状态,并且保持多数类样本的整体分布。概率论中的中心极限定理证明了大量相互独立的随机变量,其均值(或者和)的分布的极限是正态分布,即高斯分布。我们由高斯混合模型(Gaussian Mixture Model,GMM)的定义可知,它实质上就是单高斯分布模型的一种扩展,可以有效地近似模拟各种复杂的数据分布。基于以上思考,论文提出了一种基于高斯混合模型的下采样算法(Gaussian Under-Sampling,GUS)。首先利用高斯混合模型对负类数据进行拟合,然后再依据每个子模型上数据的分布情况,即概率区间按比例进行下采样。
2.1 高斯混合模型
高斯混合模型其实就是由K个单高斯模型组合而成的,这K个子模型就是混合模型的隐变量(Hidden Variable)。其概率分布密度函数为
其中,x表示服从GMM分布的随机变量,K表示GMM中的子模型的个数,μk和∑k则分别表示第k个子模型的均值与方差,表示第k个子模型的概率密度函数,αk是观测数据属于第k个子模型的概率,即第k个子模型的权重,并且满足以下条件:
高斯混合模型假定所有的样本点都是由有限个单高斯模型生成的,对于此模型的求解就是对其概率密度函数的参数求解,通常我们利用最大期望算法(Expectation Maximization,EM)对高斯混合模型的参数进行求解。
2.2 决策树与随机森林
决策树(decision tree)是一种基于树的结构进行决策的分类方法,它的构建过程就是选择特征和确定决策规则的过程[13]。
ID3,C4.5和CART算法都是经典的决策树算法。
随机森林(Random Forest,RF),简单来说,就是建立很多决策树,构建一个决策树的“森林”,通过各个决策树的投票来进行决策[14]。随机森林算法的基本步骤为
1)通过自举重采样的方式从N个原始的样本中有放回地随机抽取N个样本,从而产生多个样本集;
2)利用每次重采样产生的样本集作为训练样本构建一棵决策树。并且在构建决策树的过程中先从该结点的候选特征中随机选择一个包含k个特征的子集,作为当前结点的备选特征,然后再从这些备选特征中选择一个最优属性用于划分;
3)构建了指定数目的决策树后,RF对这些决策树的输出进行汇总,得票最多的类就作为RF的输出。
2.3 GUS算法
GUS算法的主要思想是利用高斯混合模型对负类数据进行拟合,得到多数类样本对应的高斯混合模型,然后根据每个单高斯模型上数据的分布情况,按照概率区间内样本的的比例进行下采样,从而使得多数类样本数与少数类样本数达到相对平衡的状态。
高斯混合模型能够有效地描述数据的分布情况,但同时高斯混合模型对参数具有一定敏感性,例如高斯分量的个数。为了更好地观察高斯分量的个数对描述数据分布的影响,我们选择了常常用来做聚类分析的二维数据集TwoMoons来进行测试。实验结果如图1所示,可以发现高斯分量的个数选择对数据的拟合是有一定影响。所以在我们正式利用高斯混合模型对多数类数据进行拟合之前,需要对数据有一定的了解。查询数据集的来源和应用背景、了解数据的属性特征以及利用相关算法进行参数寻优,都有利于我们对参数进行更好的选择。目前,对于高斯分量个数确定的方法中最常用的两种方法就是利用赤池信息准则(Akaike information criterion,AIC,又称最小信息准则)和贝叶斯信息准则(Bayesian Information Criterion,BIC)来进行参数寻优。本次实验中,我们采用了赤池信息准则来确定混合高斯模型中高斯分量的个数。
记原始训练集S=S+∪S-,其中S+和S-分别表示少数类样本集和多数类样本集。
GUS算法的主要步骤为
第一步:置新的多数类样本集Snew为空,并利用赤池信息准则AIC进行参数寻优,确定高斯分量的个数K。

图1 不同高斯分量下的TwoMoons数据集的数据分布等高线图,第一行从左到右高斯分量的个数分别为1、2、3,第二行从左到右高斯分量的个数分别为4、5、6
第二步:利用高斯混合模型对多数类S-进行拟合,建立一个高斯混合模型。
第三步:依照各个高斯分量中的数据分布以及每个高斯分量里概率区间中的数据分布情况,然后根据各个概率区间内的样本所占比例进行随机下采样,得到第i个高斯分量上的采样数据集Ci, i=1:K。
第四步:将从每个高斯分量中采样获得的样本纳入新的多数类样本集合Snew。
第五步:输出下采样后新的训练集S'=S+∪Snew。
2.4 评估指标
在机器学习的二分类问题中,通常将多数类记为负类(Negative),而将具有高识别重要性的少数类记为正类(Positive)。二分类问题的混淆矩阵(Confusionmatrix)如表1所示。

表1 混淆矩阵
从表1我们可以看出,TP和TN分别表示样本本身就是正类/负类,然后被正确预测为正类/负类的样本数,FP和FN则表示样本实际标签是负类/正类,但是却被错误地预测为正类/负类的样本数[15]。根据混淆矩阵的定义:
查全率:Recall=TP/(TP+FN)
查准率:Precision=TP/(TP+FP)
F-measure是查全率和查准率的调和均值,其定义如下:

其中,β是用于调节Recall和Precision的相对重要度的参数,通常取1,此时F-measure的实质是Recall和Precision的调和平均数,即有:
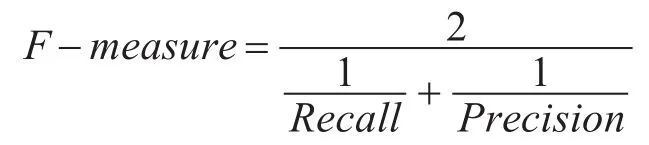
评估指标G-mean则是计算了正类和负类样本分类准确度的几何均值,其定义如下:

不平衡学习中另一个重要的评估指标就是马氏 相 关 系 数(Matthew's correlation coefficient,MCC),其定义如下:

可以看出,以上几个指标都是基于阈值的,所以我们还选取了另一种评估指标AUC(Area Under ROCCurve),即 ROC(Receiver Operating Characteristic Curve)曲线下方的面积。AUC值与阈值的选取无关,是一个衡量分类器的整体性能重要指标。
因为MCC综合考虑了各方面的评估指数,可以作为分类模型总体性能的衡量标准。本文我们则是选择MCC最大时的其他各项指标值作为实验的评估结果。
3 实验结果与分析
3.1 采样前后的数据分布比较
统计学中,可以从数据分布的集中趋势、离散程度以及形状这三个方面对数据集的分布特征进行描述。
本文就从这三个方面分析利用高斯混合模型进行下采样后样本集的数据分布,分别选择均值和方差作为描述指标,并绘制数据在采样前后的分布形状。与此同时利用高斯混合模型做聚类分析,并绘制聚类后的结果图。为了方便我们观察数据分布的形状,选择二维的数据集进行验证。数据均值与方差的统计结果如表2所示,样本集在采样前后的数据分布的形状如图2、图3、图4和图5所示。分析发现,两组数据在采样前后的均值和方差非常接近,并且采样后数据集的分布形状保持得很好。并且,我们针对三个高斯分布合成的数据在采样前后分别进行了聚类分析,得到聚类的结果分别如图6和图7所示,从最后的聚类结果来看,采样前后数据的聚类结果基本保持不变。所以,可以看出我们提出的GUS算法在减少负类样本数目的同时也很好地保持了数据的整体分布。

表2 两组数据集采样前后均值与方差对比

图2 TwoMooms数据集采样前的数据分布图

图3 TwoMoons数据集采样后的数据分布图
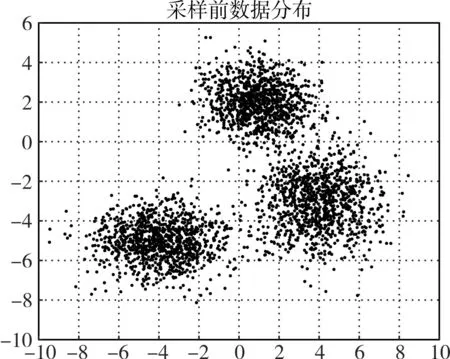
图4 三个高斯分布合成的数据集采样前的数据分布图
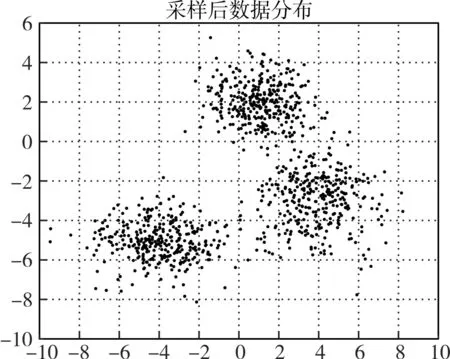
图5 三个高斯分布合成的数据集采样后的数据分布图

图6 三个高斯分布合成的数据集采样前的聚类结果

图7 三个高斯分布合成的数据集采样后的聚类结果
3.2 UCI数据集上的结果
本次我们选取了6组具有不同应用背景的不平衡数据集来进行实验。数据集的详细信息如表3所示。
为了方便和文献[16]中的其他方法进行实验结果的比较,实验选择随机森林作为分类器。与GUS算法进行比较的有:Random Forest(简称RF),表示的是对数据没有采取任何重采样技术的情况下直接使用随机森林进行分类的结果,随机下采样(简称 Under)、BalanceCascade(简称 Cascade)和EasyEnsemble(简称Easy),这三种方法都是经典的下采样方法。表4~表6详细地描述了使用GUS方法与其他方法进行分类的结果。

表3 数据集信息

表4 GUS方法与其他方法在AUC值上的比较

表5 GUS方法与其他方法在F-measure值上的比较
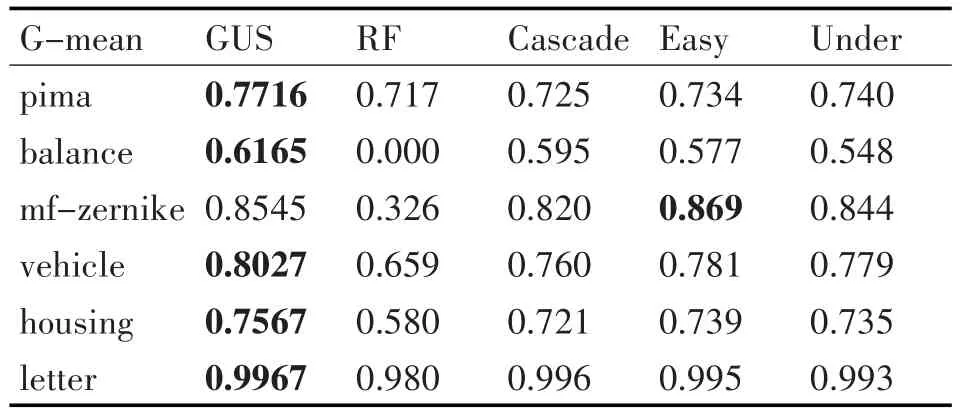
表6 GUS方法与其他方法在G-mean值上的比较
从第一个性能评估指标AUC值上观察,GUS方法在pima这组不平衡数据集上的AUC值高于其他方法。在剩下六组数据集上的值虽然不是最高的,但是结果相差不大,基本保持平均水平。
对于F-measure的考察,从表5可以明显看出,GUS方法的结果在6组实验数据上都是最优的,特别是在balance、mf-zernike和housing这三组数据上的值远远高于其他方法。说明GUS算法在处理不平衡数据的分类问题上的查全率和查准率都非常高。
从表6观察G-mean值,不难发现除了在mf-zernike数据集上的结果略低于EasyEnsemble方法,在剩下的5组不平衡数据集上的结果都高于别的方法。
通过与其他方法在三个评估指标上的比较,可以看出GUS算法在F-measure和G-mean上的值普遍高于其他方法,在AUC上的值也不低。整体上而言,GUS算法在研究不平衡学习的问题上取得了可观的结果。
4 结语
对于二分类不平衡学习,本文提出了一种新的下采样算法,通过高斯混合模型对多数类样本进行拟合,得到多数类样本的数据分布模型,利用各个子模型中数据的概率分布区间,按照样本所占比例在每个区间内进行随机下采样,从而获得新的多数类样本集,以达到平衡整个数据集分布的目的。通过在6组具有不同应用背景的不平衡数据集上进行实验,并与其他几种常用的方法进行比较,以AUC、F-measure和G-mean值作为评价指标。从实验结果上看,GUS算法取得了可观的结果,说明了GUS算法在处理不平衡数据问题上具有很大的优势。
猜你喜欢
现代装饰(2022年5期)2022-10-13
数码世界(2020年4期)2020-06-18
科学与信息化(2019年28期)2019-10-21
小天使·二年级语数英综合(2019年4期)2019-10-06
小学生学习指导(低年级)(2019年6期)2019-07-22
小学生学习指导(低年级)(2019年6期)2019-07-22
小学生学习指导(低年级)(2018年3期)2018-01-31
科学与财富(2016年32期)2017-03-04
电影故事(2015年16期)2015-07-14
决策与信息·下旬刊(2013年1期)2013-03-11
