
基于深度学习BCCM模型的网上用户画像识别分析∗
2019-10-08 07:12周晓华
计算机与数字工程 2019年9期
周晓华
(西安医学院信息技术处 西安 710021)
1 引言
目前,智能手机的普及率快速提高,对于人们的日常生活方式产生了显著影响,不断朝着网络化趋势的方向发展,这些收集互联网用户进行上网活动时产生的网络数据也呈现指数性的爆发式增加现象[1~6]。用户可以通过多种方式参与网络活动,包括以普通网页的形式进行信息浏览与数据传输或在社交平台上进行资料转发并获得粉丝关注,也可以参与到点评网站的评论活动,在电商交易网站购买所需商品及提交退换申请,这些不同的网络行为过程使得各项数据表现出实时性、多样性、大数据量的特点[6~8]。如何选择合适的方法对各类海量网络数据进行高效处理已经成为当前需要解决的紧迫问题。例如,可以将用户画像分析方法应用于大数据的处理过程,已有很多学者对这方面开展了深入研究。在最初阶段,都是从商业层面考虑对用户画像进行研究,根据用户的消费习惯、年龄、资金额度、性别等对用户消费层次进行综合分析,为实现后续的精准营销提供依据[9~12]。目前,各类大数据技术技术呈现快速发展趋势,用户画像在许多领域都获得了非常广泛的应用。比如,可以利用音乐平台系统来收集用户的操作行为,分析出各个用户的听歌模式、选歌种类等,从而精确判断出特定用户对于歌曲的喜好性[13~15]。
本文主要研究了股吧用户是否可以被归为感性投资者的用户画像任务,设计了专门的算法来实现对股吧用户发文的表示学习过程,完成了实证分析与比较研究,可以将本文研究结果作为大数据分析领域进行用户画像分析的一个重要参考依据。
2 研究方法
2.1 深度学习模型
对噪音投资者进行识别时需根据用户的内容特征来分析用户的发帖与评论内容。具体处理过程是先把单独用户的各项发帖内容与评论时形成的文本进行整合获得段落文本,再利用这些段落文本获得语料库,之后通过这些该语料库完成用户的表示学习过程。
本文设计的用户表示学习方法是建立在词向量学习方法基础上的一种数据分析方法,可以根据词向量对一个句子的后续单词进行预测。我们按照上述处理思路将其应用于用户表示学习过程中,构建得到图1所示的用户表示学习架构。根据图1可知,各用户都被映射到矩阵U的一个列向量,各单词都被映射为矩阵W的特定列向量。通过对用户向量与词向量的串联与平均处理来预测得到特定语境产生的后续单词。本文选择平均方法作为组合向量处理模式,根据以上语料训练得到下述向量与参数。
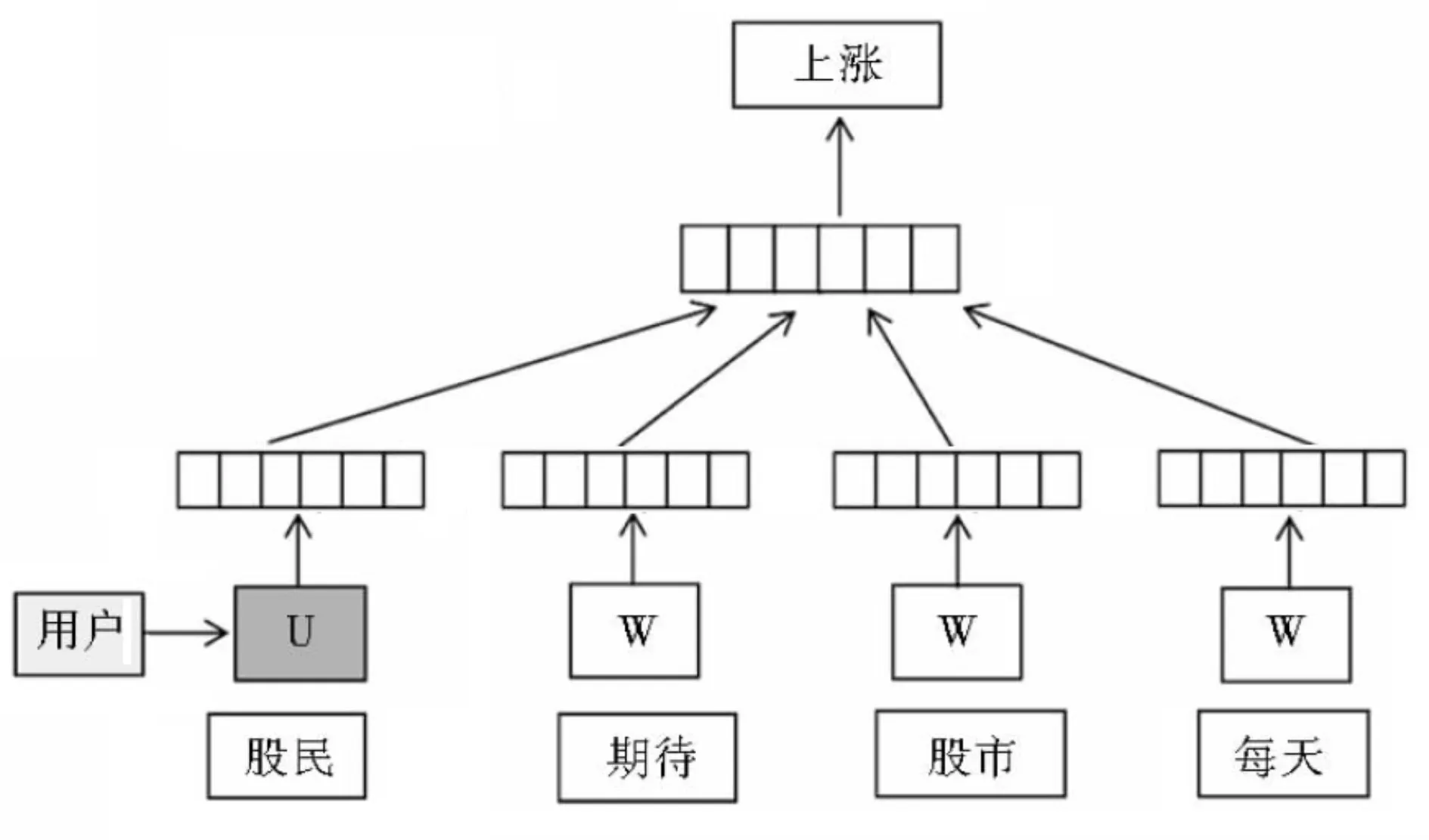
图1 用户向量框架
2.2 行为与内容融合的BCCM模型
以爬取方式获得用户在股吧网站上留下的数据信息总共包含了8类行为方式:粉丝数、关注度、评论量、发帖量、访问量、影响性、股吧年龄、自选股。粉丝数指的是一个用户被其他用户关注的数量;关注量指的是用户对其他用户进行关注的数量;影响性是对用户在股吧中的影响力进行评价的一个重要指标,根据星级不同将其表示为0~5星;吧龄指的是用户在股吧中处于活跃状态的时间;自选股表示用户实际关注的股票数量;评论量代表用户在各个帖子中参与评论的总数量;发帖量是指在股票主题下发布的总帖数;访问量指的是用户个人主页被其他人访问的次数。
根据以上用户表示学习过程与各项用户行为特点,本文构建得到一种行为-内容融合模型,可以有效识别来自股吧的噪音投资者。图2显示了此模型的具体实现步骤,如下所示:
1)先通过深度学习方法来得到用户评论与发帖内容的用户表示,由此得到对应的用户向量;
2)根据上述用户向量来完成Kmeans聚类的过程;
3)把聚类标签也看成是一个特征,并将其归为与8个行为特征相同的参数。

图2 BCCM模型的基本思路
3 实验数据
本文分析的所有数据都从东方财富网的股吧论坛中抓取得到,同时根据其它社交媒体对用户画像方面的研究结果以及股吧论坛方面的信息资料,同时以粉丝数、关注度、评论量、发帖量、访问量、影响性、股吧年龄、自选股作为用户的行为特点,选择用户发帖内容与评论文本信息作为分析对象。通过爬取方式获得关于8500位用户的约8万条网络评论数据,也包含了各用户的自选股数和关注度等指标。从时间上看,用户发表评论的数据来自2012~2017年期间。
根据以上原始数据,我们以随机方式从8500位用户中抽出2800位用户,同时采用人工方式进行标注。由两名硕士研究生进行人工标注,两人系统性学习了金融学、证券投资、经济学等课程,并获得了证券从业资格证,具备对感性投资者进行识别的基础理论。
在标注期间,只有同时被两人标注成感性投资者的对象才会被归类到标注语料数据库内。对于先被一人判断为理性投资者,但另外一人做出相反的判定结果,则把标注语料库中的这一用户数据去除,此类用户占到2800条数据的比例约为15%。当出现不一致的标注结果时,即两人依次判定为理性与感性投资者时,需考虑加入更多标注者进行分析,不过采用这种方法无法有效消除歧义。根据原始语料的观察结果可知,此类用户做出的评论与行为方式通常表现为同时包含理性与感性投资者的两种特征,因此导致标注者无法做出一致判断。根据以上分析,为确保测试数据符合有效性要求,需把标注语料库中存在不一致的人工标注数据全部去除。
4 实验结果与讨论
以5∶1的比例把上述通过人工标注方式得到的数据集依次分类为分训练集和测试集,同时引入决策树(DT)、朴素贝叶斯(NB)、神经网络(ANN)、K邻算法(KNN)和逻辑回归(LR)方法共8个行为特征建立得到二分类器,计算出的F值见表1。

表1 5种基线处理法的F值结果展示%
根据表1可知,以上各项基线处理法中,KNN算法达到了最高的精度(100%),之后是DT基本都在80%左右;对比各方法的召回率数据可以发现,LR达到了最优效果(召回比例为48.88%),之后依次为DT(45.85%)与 ANN(44.53%)。对以上各项实验结果进行比较分析可知,在识别以行为特征为依据的感性投资者时,采用LR、DT与KNN这三类基线分析方法可以获得更优的效果。
通过比较以上各类基线处理法可以发现DT方法可以实现最佳的综合效果,并且与其他算法相比也具备更好的解释性,因此本文主要探讨了以DT方法来分析感性投资者的过程,得到表2所示的结果。

表2 感性投资者行为刻画表
根据表2可知,可以对感性投资者行为进行描述的因素主要包括4类,包括评论量、粉丝数、自选股数量与主贴量,对于其他各项行为特征指标并没有进行详细分析。感性投资者的行为画像通常表现为下述三类特点:第一,粉丝数不超过20位;第二,粉丝数在20~800之间的评论量达到100以上,并且自选股的数量也至少达到了20;第三,主贴量达到580以上。同时,理性投资者的行为画像表现出如下三项特点:第一,粉丝数在50~800之间的评论量达到了100以上,同时自选股的数量不高于20,主贴量不超过600;第二,粉丝量超过800,同时评论数达到100以上;第三,粉丝数超过20,同时评论量低于100。
通过分析内容特征可以有效获得用户情感信息,并从文字信息中获得理性数据,可以利用深度用户表示学习方法来生成用户表示向量,同时采用Kmeans算法来聚类分析用户发帖和评论过程产生的文本信息。在基线模型中加入文本聚类数据,总共采用8个特征包括自选股数量、粉丝量、关注量、访问数、聚类编号、评论数、影响力、主贴量为以上基线处理法构建得到二分类器,宝库DT-W、NB-W、KNN-W、ANN-W,同时将这些模型算法和BCCM模型实施了比较分析,结果见表3。
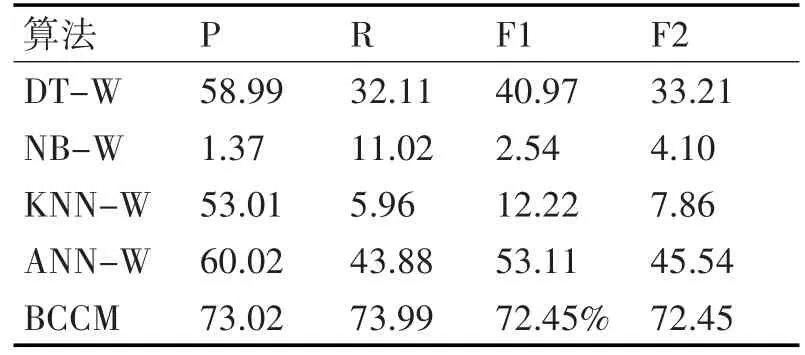
表3 基线处理法加入文本特征后的F值比较 %
根据表3数据可知,BCCM模型具有最高的召回率,达到73.99%,比ANN-W模型高出了近30%,比DT-W模型高出了约40%;从F1值的情况看,采用BCCM模型处理得到的数值最大,为7.45%,相对于ANN-W模型提高了约20%,相对于DT-W模型提高了约30%;从召回率角度分析,采用BCCM模型处理得到的数值达到最大,等于72.45%,相对于ANN-W模型提高了约28%,相对于DT-W模型提高了约40%;从准确率角度考虑,BCCM模型的取值等于100%,但高于其他模型计算的结果。通过分析以上四项参数指标可以发现,本文设计的BCCM模型可以实现良好的综合处理性能。由此可见,采用深度表示学习方法在模型中添加用户内容特征之后,可以显著改善对样本非均衡测试集合的感性投资者进行分辨的效率。
5 结语
本文主要研究了对金融领域的感性投资者与理性投资者进行识别的用户画像分析方法,综合运用了传统机器学习方法与深度用户表示学习方法,构建得到了一种通过分析内容和行为特征来识别感性投资者的模型,得到BCCM模型。之后对此模型有效性进行了验证,分别对原始非均衡标注集以及采样得到的均衡标注集开展了相应的对此测试。根据实际测试结果可以发现,采用BCCM模型处理非均衡数据集时,得到的R、F1、F2值都比决策树、逻辑回归、朴素贝叶斯传统模型的数值更高;通过处理均衡数据集可以发现,BCCM模型达到了比传统基线分类模式更优的结果。对各个实验结果进行综合分析可以发现,对于识别感性投资者的用户画像进行研究时,可以采用深度用户表示学习方法并加入特定的文本内容数据,有助于促进用户画像评价指标的全面提升。
猜你喜欢
华声文萃(2022年6期)2022-07-05
小哥白尼(神奇星球)(2022年3期)2022-06-06
文萃报·周五版(2022年16期)2022-04-28
新高考·高一数学(2022年3期)2022-04-28
马克思主义哲学研究(2021年2期)2021-06-05
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
非公有制企业党建(2020年10期)2020-10-27
瞭望东方周刊(2017年7期)2017-03-01
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
