
基于深度学习及核典型相关分析的多特征融合说话人识别∗
2019-10-08 07:12陆璐璐
计算机与数字工程 2019年9期
卜 禹 陆璐璐
(江苏科技大学计算机学院 镇江 212000)
1 引言
随着音视频处理技术的不断进步,利用音视频特征融合技术进行说话人识别成为了说话人识别领域的研究热点。在当代社会,身份识别的重要性越来越为人们重视,利用人的声音、面部、虹膜等生理特征以及笔迹、步态等行为特征来进行身份鉴别,具有真实、稳定等特点[1]。利用单一模态进行说话人识别存在许多不足,如易受干扰,准确率波动大,鲁棒性差。然而人们在实际判断一个说话人时,声音和图像都是重要依据,往往根据两者的信息进行综合判断,即利用说话人多模态特征进行信息融合,为我们的判断提供依据[2~3]。说话人识别方法也可以借鉴这一信息融合策略。
目前信息融合分为三个层面,数据层面融合、特征层面融合、决策层面融合[4~5],在特征层面融合,充分利用了不同模态的原始信息,对音视频两种特征进行优化融合,既保留了两者有效的鉴别信息,又消除了它们之间的冗余信息,性能最好[6]。
本文在特征级层面,利用深度信念网络(deep beliefnetwork,DBN)对音频信息进行处理,提取出音频特征,利用卷积神经网络(convolutional neural network,CNN)进行图像处理,提取出图像特征。孙权森[7]等率先将典型相关分析(canonical correlation analysis,CCA)方法用于特征融合。文孟飞[8]等提出了一种基于典型相关分析的异构多模态特征融合的目标识别方法。但典型相关分析方法不能精确地提取多模态特征之间的非线性相关关系,它是一种线性的特征提取方法,不能充分利用说话人非线性信息,语音特征和图像特征之间的融合恰好是典型的非线性特征融合。为了解决此问题,本文提出一种基于深度学习及核典型相关分析(kernel canonical correlation analysis,KCCA)的异构多模态特征融合说话人识别方法。
本文使用BANCA数据库对算法进行了实验,并和基于单一模态以及CCA的方法进行了对比,实验结果表明基于深度学习和KCCA的多特征融合说话人识别方法优于基于单一模态特征和CCA的方法,能显著提高说话人识别的准确率。
2 异构深度学习模型
2.1 基于DBN的深度学习模型
深度信念网络(Deep Belief Network,DBN)是深度神经网络的一种代表模型,是深度学习和人工神经网络不断发展并结合的产物。DBN由许多层的受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)堆放叠加构成,逐层训练,其中每层都是捕捉底层隐藏特征的一个高阶相关过程,然后对权重和偏置等参数进行反向传播(BP)调整。
DBN的训练过程分为两个阶段[9]:第一阶段是无监督预训练,传统的神经网络都是随机初始值,深度神经网络采用无监督特征学习的方法预先学得一部分初始值,不仅缩短了后期参数调整时间,而且让大多数参数到达最优值附近,更有利于参数调整。DBN网络是在RBM的基础上搭建,逐层训练,对连接权重以及节点偏置等参数进行训练。其中,受限玻尔兹曼机(RBM)[10~11]是具有双层结构的随机神经网络模型,主要由可视层(v层)和隐藏层(h层)所组成,其层与层之间通过权值全连接,而层内无连接,其结构如图1所示。根据CD-k算法[12],首先将v层输入矢量通过网络权重映射到h层输出矢量,之后对h层输出矢量进行Gibbs[13]采样,并利用所得到的采样结果重建v层目标矢量,最后将这些新的v层矢量再次进行映射,得到新的h层输出矢量,反复执行以上过程,进行k步交替采样完成对模型分布数学期望的近似,由低到高逐层训练每个RBM,使模型得到一个较优的初始参数值;第二阶段是有监督微调,利用带标签的训练样本计算误差,通过误差反向传播(BP)算法对DBN性能进行优化调整。

图1 受限玻尔兹曼机结构图
一个典型的含有两隐藏层DBN的训练过程如图2所示。
线性预测倒谱系数(LPCC)反映了说话人的声道特性,但它对噪声比较敏感。人耳之所以能够从听到语音信号中辨别出说话人的身份,是因为人耳对不同频率的敏感程度不同,梅尔频率倒谱系数(MFCC)正是利用了人耳听觉对频率的非线性特性,在含有噪声环境中比LPCC具有更好的鲁棒性。本文把线性的LPCC与非线性的MFCC两种方法融合起来,得到线性预测梅尔倒谱系数[14](LPCMCC),该参数既能表征声道特征,还考虑到了人耳听觉特性,可以更好地描述说话人的声纹特征,具有较好的鲁棒性,更适合用于声纹辨别。因此本文将线性预测梅尔倒谱系数输入DBN模型中进行无监督预训练和有监督微调。
2.2 基于CNN的深度学习模型
卷积神经网络(Convolutional Neural Network,CNN)是从生物学当中演变而来。HUBEL[15]等在20世纪60年代探究猫脑皮层中用于选择方向和局部敏感的神经元时,发现它拥有的奇特网络结构能够非常有效减地少反馈神经网络的复杂成度,继而提出CNN。
一般地,CNN的基本结构包括两层[16]。一层是特征提取层,每一个神经元的输入部分和前一层的部分接受域进行连接,并且提取其特征。一旦提取了该局部特征后,它和其他特征间的位置关系也将被确定。另一层是特征映射层,多个特征映射组成网络的每个计算层,而每一个特征映射平面上所有神经元的权值都相等。特征映射结构,采用的是sigmoid函数作为卷积网络激活函数,所以能够使得特征映射具有位移不变特性。除此之外,网络自由参数的减少得益于一个映射面上的神经元权值共享。卷积神经网络中,每个卷积层都紧跟着两次提取特征的独有结构,一个用于求局部平均和二次提取的计算层,这种结构减小了特征分辨率。具体的结构图如图3所示。

图3 卷积神经网络多层卷积运算和采样过程图
本文将视频帧输入到CNN模型进行模型训练并提取待识别视频帧的最高隐层特征。
3 核典型相关分析
3.1 典型相关分析
1936 年,Hotelling[17]提出了研究两组变量之间相关关系的一种多元统计方法,典型相关分析,它能够揭示出两组变量之间的内在联系。

典型相关的基本思想即是找X(1)、X(2)的一组线性函数,以使得它们的相关系数达到最大。若存在常向量,在的条件下,使得达到最大,则称是的第一对典型相关变量。求出第一对典型相关变量以后,能够类似地求出各对之间互不相关的第二对、第三对等典型相关变量。这些典型相关变量就反映了X(1)、X(2)之间的线性相关情况。
3.2 核典型相关分析
通常当我们发现特征的线性组合效果不够好或者两组集合关系是非线性的时候,会做出改进尝试核函数方法[18]。语音特征和图像特征之间恰好是典型的非线性特征关系。核典型相关分析,其基本思想是将原始空间的样本通过一个非线性映射映射到一个特征空间,进而在特征空间利用线性相关分析算法,隐含地实现了原始空间非线性问题的求解。


其中:

核矩阵中心化对训练样本进行零均值化:
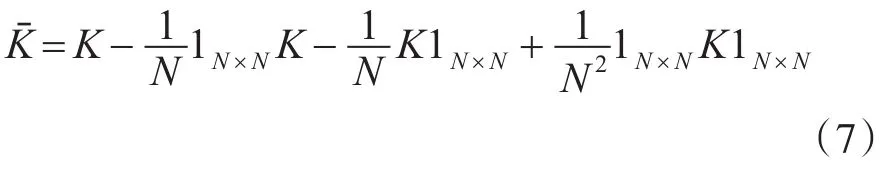
KCCA的目标是寻找投影方向αφ和 βψ,使得如下准则函数式最大:
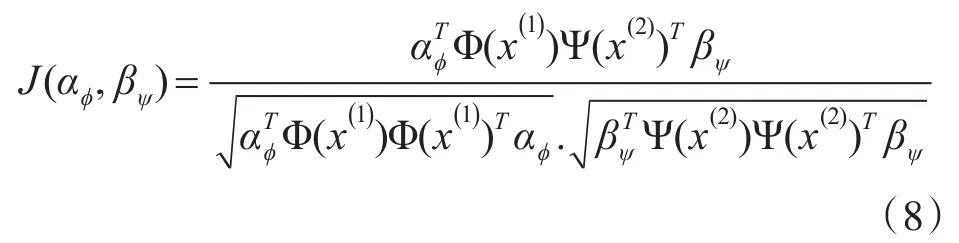
向量αφ位于样本张成的空间,根据核再生理论,则存在N维向量ξ使,同理,存在 N 维向量 η使得 βψ=,带入式(8)中得到:
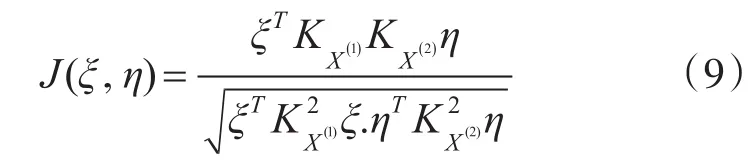
为防止产生没有意义的典型相关向量,需要引入正则项对式(9)进行约束:

式中,0≤τ≤1。因此,KCCA转化为关于ξ,η的约束优化问题,目标函数为
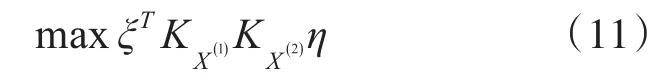
约束条件:
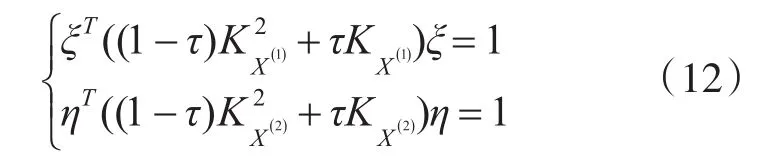
利用拉格朗日乘数法求解上述带约束的极致问题,则相应的拉格朗日方程为

式中,λ1和λ2为拉格朗日乘数。

从而,KCCA等价于求解如下广义特征方程对应的特征向量问题,即
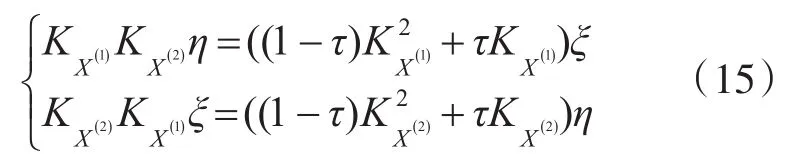
求解出ξ,η,提取 X(1)和 X(2)之间的非线性相关特征:

式中,u和v是变换后的特征分量。
将其线性变换:
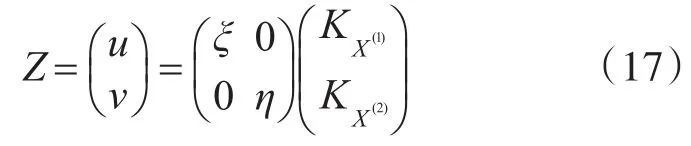
得到投影后的组合特征,用于后续的说话人识别的建模与分类。
3.3 KNN说话人识别分类器
K近邻算法(k-Nearest Neighbor,KNN)具有精度高、对异常值不敏感等优点[19]。算法如下:
Step1:计算已知类别数据集中的特征融合向量与当前特征融合向量Z之间的距离;
Step2:按照距离递增排序;
Step3:选取与当前特征融合向量Z距离最小的k个特征融合向量Z1,Z2,…,Zk;
Step4:确定前k个特征融合向量所在类别出现的概率;
Step5:返回前k个特征融合向量出现频率最高的类别作为当前特征融合向量预测分类。
待识别融合特征向量Z的K个近邻分别为Z1,Z2,…,Zk,那么KNN的分类判别函数为
3.4 基于深度学习及KCCA的多特征融合说话人识别方法架构
完整的基于深度学习以及KCCA的多特征融合说话人识别方法整体架构图如图4所示。将语音片段经过预处理得到的线性预测梅尔倒谱系数(LPCMCC)特征以及视频帧分别输入到DBN和CNN模型,两个模型分别逐层提取线性预测梅尔倒谱系数以及视频帧的特征,将提取的两个模型的最高隐层特征利用KCCA方法进行特征融合,将融合后的特征输入到KNN分类器得到说话人识别结果。
4 实验与分析
4.1 数据来源与实验环境
本文选用BANCA[20]数据库作为实验数据来源,该数据库以人面部图像和声音两种模式用四种欧洲语言拍摄,拍摄时使用高质量的麦克风和摄像机。被拍摄者在三个月的12个不同时间段内在三种场景下接受录制,共拍摄了208人,其中男女比例各占一半。每种语言52个志愿者,其中26男26女,每人录制12段音视频,平均每段视频长约20秒。视频包含志愿者随机说的12个数字、他们的名字、地址及出生日期。本文实验环境配置如表1所示。
4.2 核函数的选择
核函数的选取对KCCA的识别结果特别重要,当前常用的核函数有高斯核函数、多项式核函数、分数幂多项式核函数等。表2是不同训练样本个数情况下各核函数的平均识别率。由表2可知在不同训练样本情况下,高斯核函数具有最高的识别正确率,因此,本文选取高斯核函数作为KCCA的核函数进行特征融合。
高斯核函数为
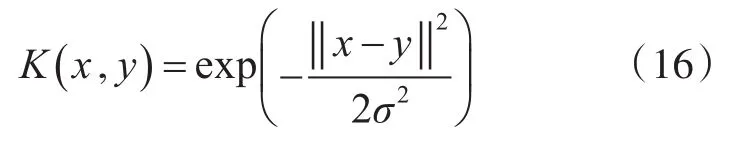
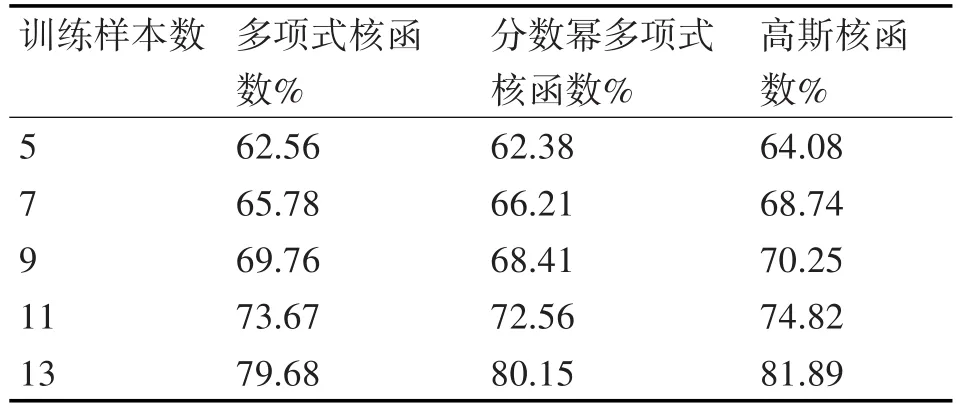
表2 不同核函数平均识别率比较
4.3 实验过程与分析
为了说明基于KCCA的多特征融合说话人识别方法的有效性,将其与基于单一模态的DBN网络和CNN网络算法以及未改进的CCA融合算法进行对比。在每个被测试对象的12段视频中选取其中8段作为训练组,4段作为测试组,对比结果如表3所示。由表3可以看出基于KCCA的多特征融合说话人识别方法比基于单一模态的神经网络架构的说话人识别结果有了显著提高,而基于CCA的多特征融合说话人识别方法结果提高并不明显,这是因为说话人面部特征和音频特征的特征空间上存在着非线性相关关系,而CCA是一种线性特征提取方法,对非线性特征信息利用较少,不能提取不同特征之间的非线性相关关系。而KCCA特征融合方法提取了两者的非线性相关特征,既进行了信息融合又去除了特征间冗余信息,可以取得较高的识别率。

表3 基于BANCA数据库的不同算法结果比较
5 结语
本文针对传统说话人识别方法中只利用单一模态进行说话人识别准确率低、鲁棒性差的问题以及CCA特征融合算法无法充分提取非线性特征相关关系的缺点,提出了一种基于深度学习及核典型相关分析的多特征融合说话人识别方法。本方法在特征级融合层面上结合DBN和CNN分别处理说话人的音频和视频信息,利用KCCA将两种网络提取的音频和图像特征进行融合,融合的特征送入KNN分类器进行识别。最后在BANCA数据库上的实验结果表明该方法的准确率较传统方法有了极大的提升,验证了方法的有效性。
猜你喜欢
小学生作文(低年级适用)(2022年10期)2022-10-31
汽车实用技术(2022年10期)2022-06-09
新高考·高一数学(2022年3期)2022-04-28
昆明医科大学学报(2022年3期)2022-04-19
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
现代临床医学(2021年1期)2021-01-26
中学生数理化·中考版(2019年11期)2019-09-10
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
