
基于改进YOLOv3算法的高密度人群目标实时检测方法研究
2019-10-10 07:00王思元王俊杰
安全与环境工程 2019年5期
王思元,王俊杰
(中国海洋大学工程学院,山东 青岛 266100 )
随着我国城市化进程的加快,越来越多的大型公共建筑应运而生,与此同时也出现了越来越多如车站、地铁、商场等人员密集场所,当发生灾害事故时,需要尽快将大规模人群进行疏散,而高密度人群疏散过程一旦出现问题,可能会造成重大的人员伤亡事故。因此,实时、准确的人群识别与检测对保证人员密集场所的交通安全及规划管理具有重要的应用价值。
传统的行人检测方法主要采用人工设计特征进行全局特征行人检测,通过Haar小波特征、HOG特征、Shapelet与Edgelte特征[1]、TED与轮廓版特征等训练分类器进行行人检测,并在现有的数据集上取得了许多令人瞩目的效果。如Hoang等[2]提出了基于可变尺度梯度特征直方图(Histogram of Oriented Gradient,HOG)的行人特征描述方法,并结合支持向量机(Support Vector Machine,SVM)进行图像分类,使得分类准确率有较大的提升;Armanfard等[3]将纹理边缘特征描述(Texture Edge Descriptor,TED)系统应用于视频中的行人检测,其特征包括纹理与边缘信息,并且对光照明显变化时的图像有很好的鲁棒性,可以较好地处理室内与室外光照变化对图像的影响;Dollar等[4]巧妙地将聚合通道特征(Aggregated Channel Features,ICF)与HOG特征相融合,用于背景复杂情况下的行人检测。人工设计特征始终难以有效地表达复杂环境下行人特征问题,且程序本身运算量高,其高复杂度也限制了目标检测的实时性。近几年,基于深度卷积神经网络(Convolution Neural Network,CNN)的算法凭借其在特征提取上的优势被广泛应用于目标检测任务中,大幅提高了目标检测的准确率。目前CNN算法较为广泛使用的方法可以分为三类:第一类方法是基于区域建议的目标识别算法,如Fast R-CNN[5]、Mask R-CNN[6]、Faster R-CNN[7]等,这类算法在目标识别方面效果很好,但是检测速度相对较慢,因而很难应用于实际;第二类方法是基于学习搜索的检测算法,如深化强度网络Q-Learning、AttentionNet模型[8]等,这类算法将图像识别提取任务转换为一个动态视觉搜索任务,与其他方法相比,其检测精度不甚理想;第三类方法是基于回归方式的目标检测算法,如SSD(Single Shot MultiBox Detector)算法[9]、YOLO(You Only Look Once)系列算法[10-11]等,此系列算法在保证目标检测准确率同时也提高了检测速度,基本可以满足实时性的要求。目前YOLO算法已经发展到第三个版本即YOLOv3[12],在目标实时性检测方面的表现尤为突出。
本文借鉴目标检测领域先进的研究成果,提出将YOLOv3网络应用于高密度人群目标检测中,通过对其层级结构及参数进行调整,调整后的网络(即YOLOv3-M网络)不仅能够准确识别目标人群位置,而且对于存在局部遮挡、背景复杂、光线不足、视线模糊等情况下的人群也具有很好的识别效果。
1 基本要求
1.1 YOLOv3算法
YOLO算法在2016年由Redmon等提出后,到2018年已经经历了YOLOv2、YOLOv3两个版本的改进。与前两个版本相比,YOLOv3算法主要做了以下几方面的改进:
(1) 借鉴ResNet残差网络思想。首先,残差网络保证了即使在很深的网络结构下,模型仍能正常收敛,网络越深,特征表达越好,分类与预测的效果皆有提升;此外,网络中1×1的卷积,压缩了卷积后的特征表示,减少了每次卷积中的通道,在减少参数量的同时也一定程度上减少了计算量。
(2) 采用多尺度融合预测方法。YOLOv3算法在3种不同尺度上进行预测,使用类金字塔网络[13]从这些尺度中提取特征,通过与上采样特征合并,从中获得了更好的细粒度特征及更有意义的语义信息,并且在训练过程中,随机改变输入图像大小,做到从多尺度训练网络模型,使得算法对小目标的敏感度与检测精度大幅度提升。
(3) 分类损失函数替换。YOLOv3算法替换了softmax cross-entropy loss损失函数对每一个候选框进行分类,考虑到当预测的目标类别很复杂、重叠标签较多时,该损失函数并不适用,而复合标签的方法能对数据进行更好地预测与分类,损失函数采用binary cross-entropy loss,使得每个边界框(Bounding Box)可以预测多个目标,同时也保证了每一个目标的预测准确率。
1.2 特征提取网络Darknet-53
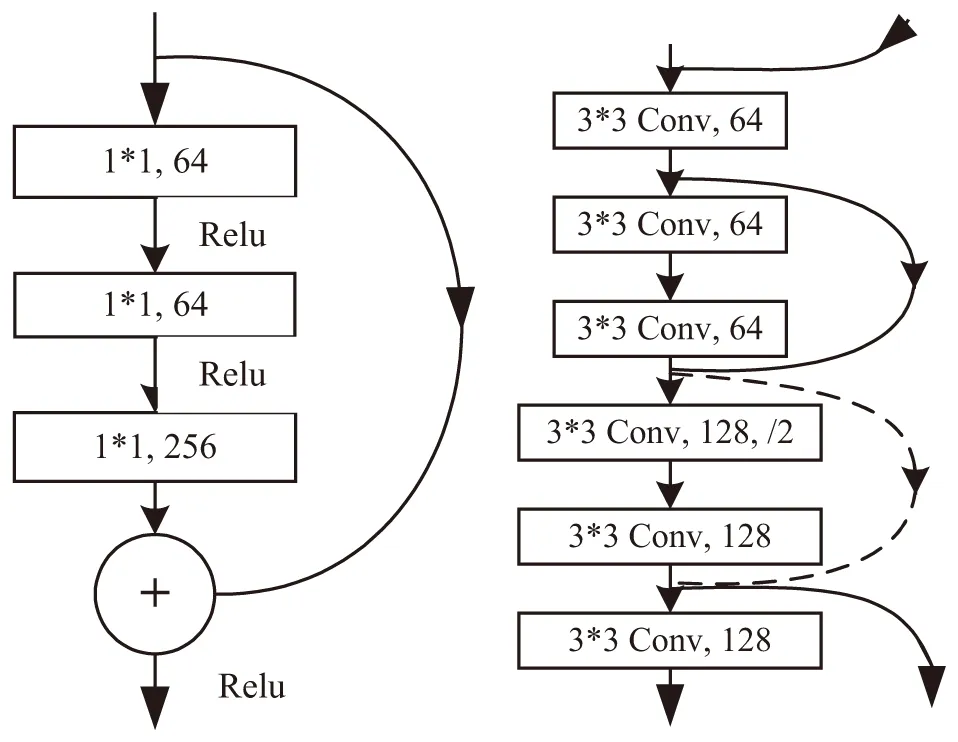
图1 残差网络和Darknet-53跳层连接示意图
YOLOv3算法采用Darknet-53作为特征提取的主要网络,Darknet-53网络共有53个卷积层,网络结构更深。该结构中采用一系列3×3和1×1等表现良好的卷积层,并使用LeakyReLu作为修正函数,在保持高检测速度前提下提升了目标识别的准确性;同时,YOLOv3算法采用类ResNet[14]跳层连接方式的快捷连接(Shotcut Connections),将原始数据跳过某些层而直接传到之后的层,起到降低模型复杂性及减少参数数量的目的,很好地解决了准确率随着网络结构加深而下降的问题。图1为残差网络(左)和Darknet-53(右)跳层连接示意图。表1为Darknet-53网络性能对比表,在保证每个网络具有相同设置情况下分别对其进行训练与测试。
由表1可知,Darknet-53网络在Top-1和Top-5识别的准确率可与ResNet-101、ResNet-152网络相媲美,浮点运算次数可达到1 457次/s,使得网络可以更好地利用GPU进行图像等的处理,且图像检测速度为78FPS,满足实时检测的要求。

表1 Darknet-53网络性能对比表
2 改进的YOLOv3算法
2.1 基于高密度人群目标数据重聚类
YOLOv3算法延续了Faster R-CNN的anchor boxes[15]机制,即先验框思想,anchor的个数及宽高比将影响目标识别的精度,在算法训练过程中,随着迭代次数的增加,候选框参数也在不断调整,使得其与真实框参数更接近。YOLOv3算法通过在COCO数据集上进行K-means[16]维度聚类,得到最优anchor的个数及宽高维度,与Faster R-CNN手工设置先验框相比,采用K-means聚类方法得到的先验框主观性较弱,更易于深度卷积神经网络(CNN)学习。本方法的目的在于增强对密集人群和小目标的识别效果,因此需要深度卷积神经网络从大量样本中学习行人特征。COCO数据集共有约80类目标数据,包含人、车、草地等多类数据[17],“扁长型”框较多而符合人群目标特征的“瘦高型”框相对较少。本文采集的实验用数据集候选框类型与COCO数据集相反,多为“瘦高型”数据,因此更具有代表性,所以通过对实验用数据集进行K-means聚类分析,可得到适合高密度人群数据集最优anchor个数及宽高维度。
传统K-means聚类通过度量样本间相似性进行间接聚类,通常使用欧式距离或曼哈顿距离作为度量公式,但会产生“大框优势”,使得较大边界框相对于较小边界框产生更多的错误。而YOLOv3算法采用重叠度交并比(Intersection Over Union,IOU)来反映候选框与真实框之间的误差,其距离公式为
d(cos,centroid)=1-IOU(box,centroid)
(1)
式中:box为样本聚类结果;centroid为所有簇的中心;IOU(box,centroid)为所有簇中心与所有聚类框的交并比。
通过对高密度人群目标数据集进行聚类分析,目标函数的变化曲线见图2。

图2 目标函数的变化曲线
由图2可见,随着聚类个数K值(簇值)的不同,目标函数曲线随之改变;当K值大于6时,目标函数曲线趋于平缓,因此选择K值为6,即anchor个数为6。此外,随着K值的不同,网络训练候选框初始规格也随之变化,具体见表2。

表2 实验数据集聚类结果
2.2 网络结构改进
深层卷积神经网络的卷积层数及更深的网络结构,对识别目标特征提取有很好的效果。考虑到高密度人群目标相对较小,以及算法自身结构深度,为了获得更高的语义信息,本文对YOLOv3算法的特征提取Darknet-53网络进行了改进,即在主干网络中额外增加2个1×1和3×3的卷积层。增加卷积层的优势主要体现在以下几个方面:①有利于降低卷积核通道维数与参数,使卷积神经网络得以简化;②增加的1×1和3×3卷积核可以在不损失分辨率的前提下增加非线性特性的表达,丰富信息的表现形式;③在获得相同的感受野与捕捉更多的语义信息的同时,较小的卷积核可以在加深网络的同时提高网络的表达能力[18];④使用较小卷积核的卷积层与较大卷积核的卷积层相比拥有更多层的非线性函数,可以突出判决函数的判决行。改进后的YOLOv3算法结构见图3。
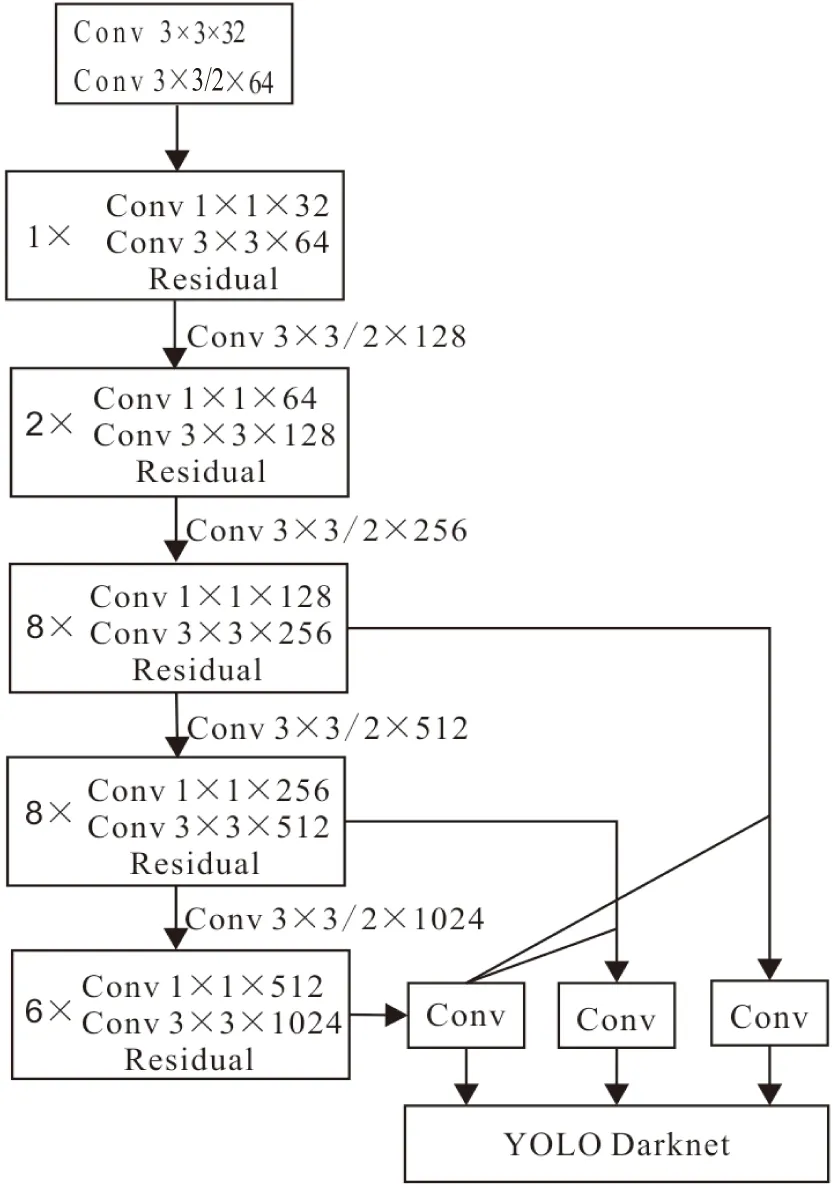
图3 YOLOv3-M算法结构
此外,为了从多个角度对比改进后算法的性能,将改进的YOLOv3算法分别进行命名,即:将只进行维度聚类后anchor个数改为6的算法称为YOLOv3-A,取YOLO与anchor的首字母进行命名;将进行维度聚类且更改算法结构后的算法称为YOLOv3-M,取YOLO与模型(Model)的首字母命名,以方便辨识。
3 实验验证与结果分析
3.1 实验平台与模型参数
实验平台软硬件配置情况见表3,所有训练均在该实验平台上进行。

表3 实验平台软硬件配置
初始模型参数设置如下:Learning_rate为0.001;Momentum为0.9;Decay为0.0005;Batch为16;Max_batches为50000;Policy为steps;Scales为0.1,0.1。
3.2 实验数据集
本文选取在工作中收集到的密集人群场景图片4 000张作为实验数据,并对实验数据集进行人工标注。行人数据集示例图片见图4。采集的数据集为日常生活中的场景,行人外貌姿态丰富、身处背景复杂、个体差异明显,并伴随不同程度的遮挡,符合实验用数据需求,其中包含训练集2 640张图片,验证集1 360张图片。此外,将500张图片作为测试数据集以便对训练结果进行测试。

图4 行人数据集示例图片
3.3 网络训练与结果分析
通过实验对本文提出的改进后的算法YOLOv3-M进行目标检测的训练与测试,并将实验结果与Faster R-CNN、YOLOv3、YOLOv3-A等算法进行对比分析。Faster R-CNN算法是目标检测方法中检测准确率最高的算法之一,其区域建议网络(Region Proposal Networks,RPN)直接训练生成候选区域,相比较传统的区域搜索方法如Selective Search、Edge Boxes等[19],可简化目标检测流程,大幅提高识别的准确率;YOLOv3是YOLO系列算法的最新改进版本,不论在检测速度与精度上都具有代表性,因此本文选择这两种具有代表性的算法作为实验对象进行对比分析。本次实验共分为以下四组:
(1) 使用本文提出的YOLOv3-M和Faster R-CNN分别在实验用数据集上进行20 000次、30 000次、50 000次迭代训练,观察其准确率,其训练结果见表4;同时,使用这两种算法对测试数据集中的数据进行测试,其测试结果见图5。
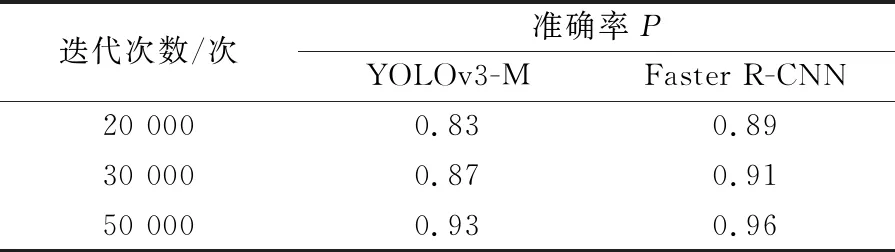
表4 YOLOv3-M和Faster R-CNN算法的训练结果

图5 Faster R-CNN和YOLOv3-M算法的测试结果
其中,准确率P的计算公式为
(2)
式中:TP表示预测结果为行人、真实结果也为行人的数量;FP表示预测结果为行人、真实结果为非行人的数量。
由表4可知:YOLOv3-M和Faster R-CNN算法在训练过程中随着迭代次数的增加准确率不断提升,并且随着迭代次数的增加,两种算法的差距逐渐减小;在50 000次迭代后,YOLOv3-M算法的准确率略低于Faster R-CNN算法,两者的差值为0.03,说明本文方法具有良好的目标检测能力。此外,由图5可见,YOLOv3-M算法在小目标检测方面稍逊于Faster R-CNN算法,这也是下一步需要进一步研究的重点内容之一。
(2) 分别使用YOLOv3、YOLOv3-A、YOLOv3-M算法在实验用测试集上进行测试,以召回率(Recall)和平均准确率(mAP)为检测指标,其测试结果见表5。其中,召回率R的计算公式为
(3)
式中:FN表示预测结果为非行人、真实结果为行人的数量。
平均准确率mAP的计算公式为
(4)
式中:∑AP表示单类图片平均准确率之和;NC为类别总数。
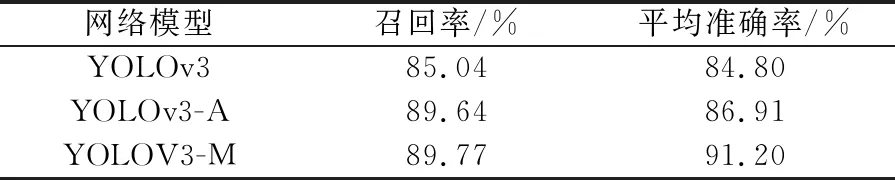
表5 不同算法在测试数据集上的测试结果
由表5可知,YOLOv3-M算法的召回率和平均准确率均高于YOLOv3和YOLOv3-A算法,其中在召回率方面,YOLOv3-M算法高于YOLOv3算法4.73%,高于YOLOv3-A算法0.13%;在平均准确率方面,YOLOv3-M算法高于YOLOv3算法6.4%,高于YOLOv3-A算法4.29%。测试结果表明:经过维度聚类后YOLOv3-M算法更好地囊括了不同尺度的行人,候选框宽高比更符合密集人群目标,被正确预测的行人数逐渐增多;另一方面,结构调整与重聚类后的网络整体性能指标得到了优化,增加的1×1和3×3卷积核使得网络获得更多语义信息,对小目标识别的准确率和定位的准确率相较于YOLOv3算法有所提升。因此,改进后算法的查全率、查准率性能得以证实。
使用上述三种网络模型对测试数据集中的样本进行测试,其测试结果见图6。所用算法从左向右依次为YOLOv3、YOLOv3-A、YOLOv3-M。
由图6可见,YOLOv3算法对密集人群目标的漏识状况较其他两种方法严重,对小目标人群定位准确性差,而YOLOv3-M算法的识别、定位结果相对更精准。
(3) 在1 080p的mp4视频上分别对YOLOv3、YOLOv3-A、YOLOv3-M算法进行图像检测速度(FPS)测试,其测试结果见表6。
由表6可知,经过维度聚类后的算法YOLOv3-A算法的图像识别速度略快,可达到22 FPS,其原因是YOLOv3-A算法维度聚类后所用anchor数目少,且宽高维度更加符合密集人群特征,因此在占用相对少的资源的情况下,图像识别速度快,且高于其他两类算法;而YOLOv3-M算法图像识别速度与YOLOv3算法持平,基本满足目标实时性检测的要求。
(4) 为了验证本文提出的改进后的算法YOLOv3-M可以提高检测器性能的有效性,以测试数据集作为实验数据,在阈值相同的情况下,以漏检率曲线(MR-FPPI曲线)作为评价指标,比较三种算法YOLOv3、YOLOv3-A、YOLOv3-M所训练的检测器的漏检率曲线,见图7。其中,MR(Miss Rate)为丢失率,FPPI(False Positives Per Image)为每张图片错误正例,MR-FPPI曲线主要考察FP(False Positives)出现的频率。
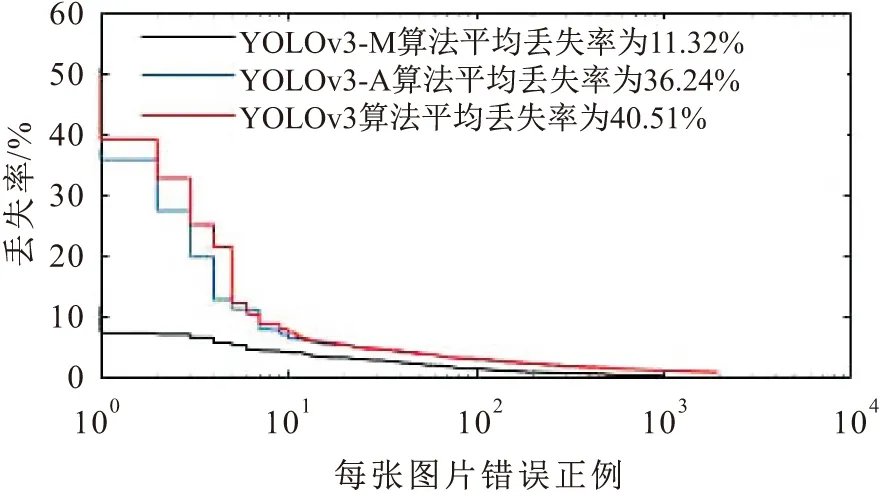
图7 不同算法所训练的检测器的漏检率曲线
由图7可见,在阈值同为0.5的情况下,YOLOv3-M算法训练检测器的漏检率为11.32%,较YOLOv3算法训练检测器的漏检率降低了29.19%,较YOLOv3-A算法训练检测器的漏检率降低了24.92%,进而改进的YOLOv3-M算法训练检测器的漏检性能得以验证。
4 结论与建议
本文以YOLOv3算法为基础,通过对数据集进行维度聚类分析、算法结构改进与参数调整等,提出了一种基于改进YOLOv3算法的密集人群目标实时检测方法即YOLOv3-M算法。实验结果表明:该方法具有较高的检测准确率与定位准确率,平均准确率从YOLOv3算法的84.8%提高到YOLOv3-M算法的91.20%,召回率从85.04%提高到89.77%,且在行人检测过程中漏检率低于改进优化前的YOLOv3算法。但是,本文提出的检测方法仍存在一些不足之处,如检测速度稍逊色于YOLOv3算法、对微小目标定位准确率不高等,主要原因是由于算法改进后,算法结构加深所致。如何进一步优化算法结构,在保证检测准确率的情况下进一步提高其检测速度及对微小目标的识别率,将是下一步研究的重点内容。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
意林(2021年5期)2021-04-18
电子制作(2019年13期)2020-01-14
铁道通信信号(2019年6期)2019-10-08
电子制作(2019年11期)2019-07-04
扬子江(2019年1期)2019-03-08
北京航空航天大学学报(2018年1期)2018-04-20
小天使·一年级语数英综合(2017年6期)2017-06-07
雷达学报(2017年6期)2017-03-26
汽车与安全(2016年5期)2016-12-01
