
一种通过语音识别和音频分割来自动生成字幕的解决方案
2019-10-15 06:55胡中毓宁波市肯特学校
数码世界 2019年10期
胡中毓 宁波市肯特学校
引言
随着网络科技的发展,人人都有机会在网络上发布自己的原创视频。字幕的存在可以让观众更轻松地获取视频的信息。两种字幕形式较为常见:直接集成在视频图像中的内嵌型,和以srt 文本文件为格式临时导入视频的外挂型。视频字幕的制作通常比较繁琐,现有的一些方法需要使用者进行较为复杂的操作:创作者可以通过专业软件,在与视频内容进行对比的同时将字幕同步时间轴内嵌;或者在任意文本编辑器中分别输入每一段字幕的起始时间,结束时间以及字幕文字,然后直接改后缀名使其成为srt 外挂字幕文件。
为了简化字幕制作的过程,笔者对现有的语音识别和音频分割技术进行整合,在调取语音识别库对视频语音进行转换以及运用k-means 聚类算法来进行较为精准的语音片段分割之后,整合生成srt 格式外挂字幕文件,可以直接在视频文件中加载,方便使用。
1 软件实现
1.1 视频预处理
Ffmpeg 是一个可以通过命令行即可运行的免费音视频处理工具。笔者用Python 的subprocess 库调用ffmpeg,将待处理视频(如mp4)转换成合适的音频格式(wav)。
1.2 语音分割
自动字幕生成方案很重要的一点就是对语句的精确分割。成功分割后可以用现成的语音识别技术将每句话单独识别即可。语句的分割,一般可用静音间断来作为分割依据,但有一段较为低分贝的音频时,可以认为是一句话与另一句话的分割处。
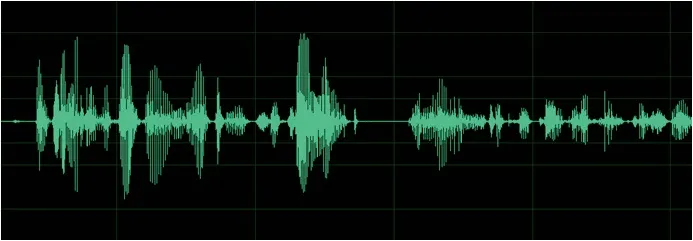
从上图可以看出,静音段可能是句与句之间的间断,但也可能只是两个词之间的间断。将静音段长度设为L 秒,将该段是句与句之间分割段的概率设为α,则两者有以下关系:
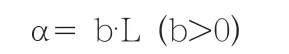
也就是说,一个静音段越长,越可能是两句话之间的分割。
由于计算机中音量概念与物理学概念不同,默认当音量低于-16分贝时,此音频段为静音段。
初步设定当静音片段长度达到700 毫秒时,程序将对音频语句作出分割。介于人与人的说话方式都有不同,用户能够自行对此数值进行修改。
通过k-means 聚类算法来分析音频中静音段的平均时长从而来确定分割的基本标准。

上图展示了一段音频中静音片段的长度。我们可以发现静音片段的长度大概聚集在0.5 秒~1.0 秒之间,只有部分处于10 秒左右。使用k-means 算法,排除特例之后,将主要的静音片段判断标准定为0.6秒左右
1.3 语音识别
使用百度、讯飞等开源语音识别库将语音转化为文字
语音文字识别技术在当下已经非常成熟,故而本方案直接采用了百度和讯飞的双重语音文字识别引擎,双引擎增加可靠性,同时互相对比可以增加识别准确率。
将分割后的音频逐个上传到百度和讯飞的服务器[6],并将返回的结果比对,如有不同,则可以标注该段,让用户自行选择。
1.4 处理过长字幕
设l 为最适合一段字幕的字符数(l=20)。当一段字幕大于l,通过分割来让其接近l。我们通过python 中的jieba 库进行中文分词使单独的词语不作为分割点,从而保证语意不变。对于一段字幕,从长度l 的地方开始向前进行索引直到jieba 分词的分词点并在此处进行分割。
1.5 合并时间轴与字幕
将语音识别后的字幕段落与时间轴合并,输出成srt 文件。
2 实验结果和分析
选取语句较为清晰,背景声音不嘈杂的视频测试。将运行后得到的字幕结果与工听写所得的字幕进行对比。
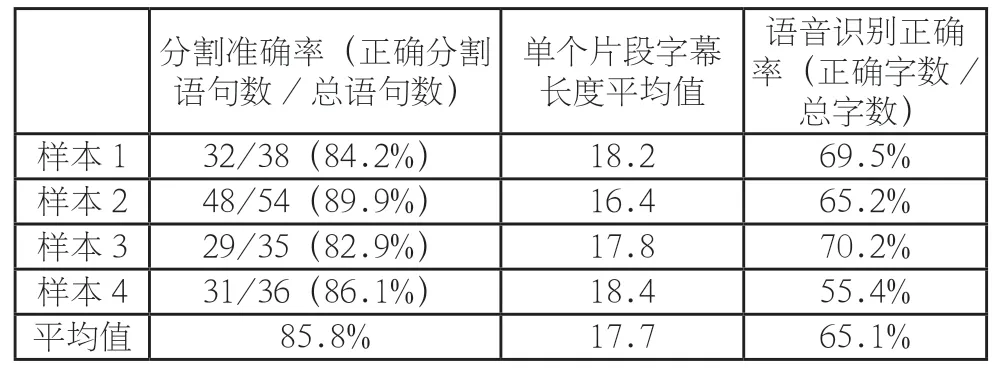
通过对吐字清晰的视频进行测试,结果令人满意。语音分割准确率较高,平均值约85%;单个片段的字符数稳定在20 字以内,使每段文字不过长也不过短;但是受制于现有语音识别技术,字幕正确率仅有半成。
3 总结语
字幕制作有许多方式,但使用起来大多费时费力。本人通过整合现有语音识别和音
分割技术制作的自动字幕工具在分割方面有较好的效果,但是语音识别正确率不是很高。不过由于能够自动划分时间片段并生成srt 文件,使用者可以在生成之后进行手动的简单修改即可达到较好的效果。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
意林(2020年15期)2020-08-28
电脑报(2020年50期)2020-03-10
金桥(2019年12期)2019-08-13
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
发明与创新(2016年34期)2016-08-22
中国新通信(2016年4期)2016-03-24
南方周末(2014-01-02)2014-01-02
海外英语(2013年7期)2013-11-22
