
基于卷积网络的意图识别
2019-10-20 17:42张子轩
大东方 2019年12期
摘 要:意图识别是自然语言处理中一个重要部分。在人工智能热潮前,对于文字信息特征提取的方法非常有局限性,数据分析中文字信息往往被舍去。在深度神经网络取得突破后,自然语言处理向前跨越了一大步。意图识别就是其中一个重要应用,它通过某人一段评论或一段话识别其意图。本文在卷积神经网络模型基础上,加入注意力机制,将正确率从60%提升到了63.8%。
关键词:意图识别;注意力机制;卷积神经网络;GRU网络
随着人工智能的兴起,文本数据挖掘受到了人们的广泛关注。文本的情感分析、意图识别是其中重要的应用。识别语言中的意图,难点在于如何提取句子中的特征。Harris Z S提出的Bag-of-Words模型,有三个问题:一是丧失了词语之间先后顺序信息;二是每个句子中都有很多无用词语,对建模造成干扰;三是语言中词的个数有很多,在建模时存在维数爆炸和矩阵稀疏问题。Kim Y首次将卷积神经网络应用在文本分类上,是卷积神经网络在自然语言中的有效应用。
一、研究设计
(一)模型建立
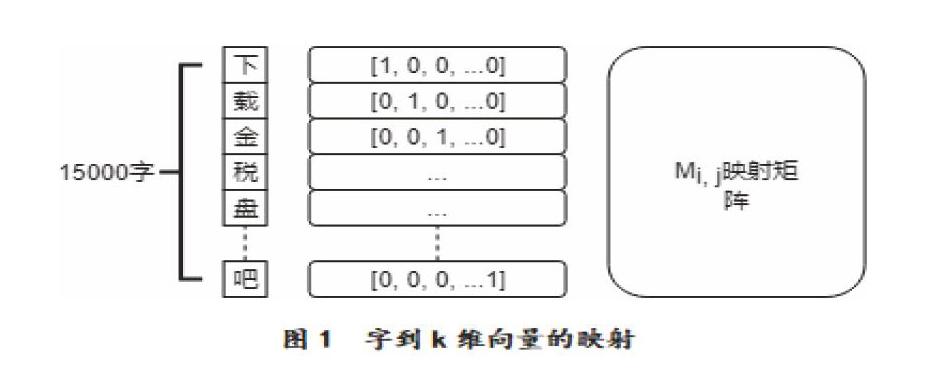
对文字进行分析处理,首先要将文字转化成可以计算的数字,然后才能建模分析。先定义一个汉字字典,本文采用的是15000字的汉字字典,几乎涵盖所有简体字。将每个字按照某种顺序转化成独热编码,也就是一个由0-1组成的长度为15000的向量,在各自的维度上为1,其他维度都为0。通过独热编码与映射矩阵Mi,j相乘可以得到各自的k维向量(见图1),例如“下”字映射后的向量为M1,j。M为模型的参数,最初是给定的随机值。这个映射矩阵的好处在于降低了维度和独热编码的稀疏性。
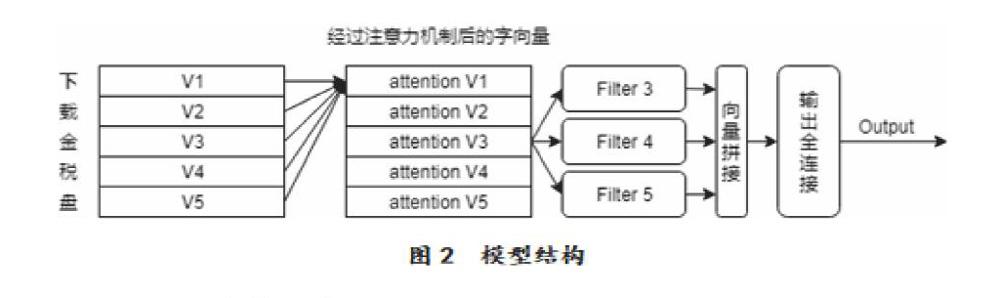
模型的主体结构是Kim Y的卷积结构的变形。V∈Rk是一个k维的矩阵(见图2),这个矩阵是通过Mi,j矩阵映射而来,每个字都对应了自己的一个向量Vi。相比于Kim Y直接进行卷积的方式,本文加入了注意力机制。V1不再完全由映射矩阵得到,而是与整个句子中的每个字都进行了相似度的计算,通过加权和的方式,V1得到了重新的表征。这样做的好处在于每个字都包含了句子的部分信息,并且不同的字对于句子中的不同部分关注程度不一样,每个字都更加关注与自己相似的部分,向量的表达能力更强。经过了注意力机制之后,相比于Kim Y的单层卷积,本文采用了3种不同的卷积核,分别在相邻的3个字、4个字和5个字进行了卷积和池化运算,再将他们的结果进行拼接,通过一个全连接进行分类输出,计算模型的损失。最终的损失函数采用的是一个交叉熵的变形,多分类的交叉熵只用了标签为1的那个维度上的值与1进行比较来计算损失,在其他维度上的损失都是0,不参与损失计算的。本文的损失函数将其他维度的损失与0进行比较,同样参与了损失的计算。
n表示一个batch的数量,m表示类别的数量,样本进入模型经过最后一层输出全连接后为一个大小为[n,m]的矩阵。m列中,当样本标签为真的那一列,j值为1,其他列的j值都为0,是一个样本在各个类别的得分,经过softmax函数后得到的得分分布。S是对正确类别的一个微小惩罚因子。loss计算的是一个batch下的平均损失。
(二)参数设定
字向量维度设置为512维。句子长度设置为64个字,大于64个字的句子进行截断处理,小于64个字的句子padding到64个字。卷积核选用3*3、4*4和5*5方阵,卷积核深度为128,池化层采用最大值池化。惩罚因子s取0.2。为了提高模型泛化能力,损失函数中加入了参数的L2范数正则项。
二、实验过程
本文的数据来源于XXX公司智能客服业务线上的真实数据,通过对用户的真实提问进行意图分类标注,并经过去重和简单预处理处理,得到3w条共197个类别数据。数据集存在两个方面的问题:一是线上真实数据的噪音会比较大,并且分布非常不均衡,存在一些类别有上千条数据,另一些类别只有几十条数据的情况。二是人工标注的时候会出现统计误差,对模型性能存在一定的影响。数据采用随机抽样的方式选取了90%的数据作为训练集,剩下的10%的数据作为测试集。句子长度的选取上,既要考虑到客服系统大多数用户提问时字数的分布情况,又要考虑到模型的性能,最终长度采用了64个字。
在最初的试验中,本文采用的是分词的预处理的方式。映射矩阵为词向量的映射矩阵。词对于句子来说更具有意义,就像一个“下”字,根本看不出句子的意图,而“下载”则已经具备了基本的意义。但是从试验的结果来看,字向量的准确率往往比词向量要高2%-3%。并且字向量的扩展性能更加强大,因为常用词的个数远远大于字的个数,15000个字几乎可以涵盖所有的字,但是即使只是常用词都已经是十几万了。因此,在测试集中的部分词语在训练集中是没有出现过的,只能用unknown表示,这样就降低了模型的泛化能力。在卷积过滤器Filter的选择上,尝试了在3个Filter的基础上继续增加,实验结果表明无法继续提高模型的准确性。可能的原因是Filter增加导致参数的增加相对于3万多个样本过多,因此继续增加Filter也没有效果了。惩罚因子分别尝试了0.1、0.2和0.3,在0.2的时候效果最好,在测试集上能提高1.5%的准确率。
三、结论
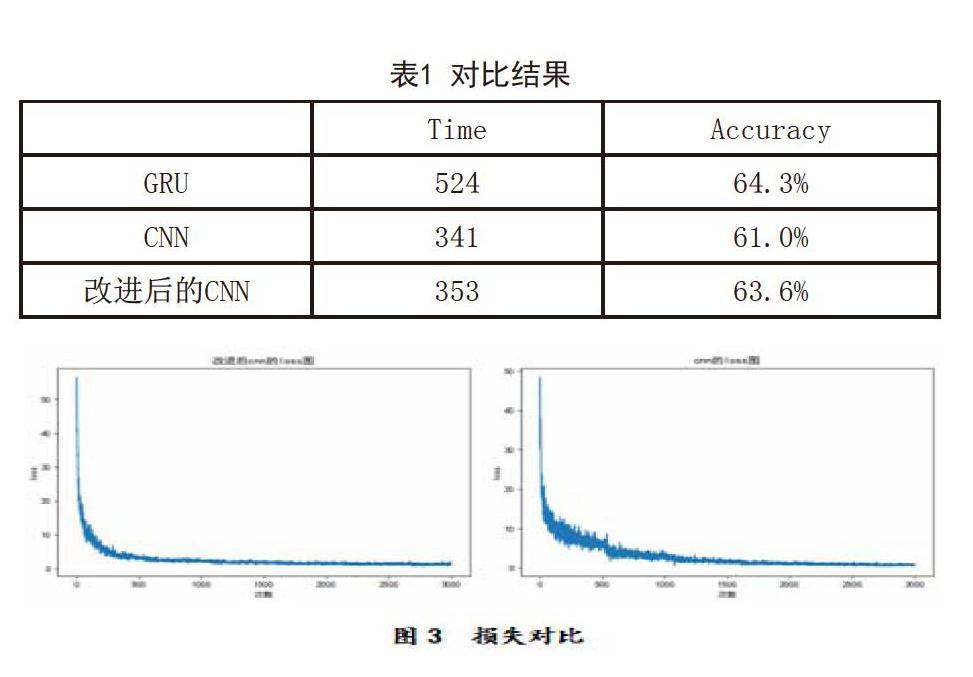
本文选择了GRU模型和Kim Y论文中的CNN模型作为baseline进行对比。试验结果为3次后的平均值(见表1)。GRU模型在处理序列问题上准确率确实比较高,但由于每次计算都依赖于上一次计算结果,无法并行运算。在Batch数为64,总训练次数为3000次的情况下,花费时间是CNN模型的1.5倍。本文采用模型加入了注意力机制,并且微调了损失函数的模型,与CNN对比几乎没有增加时间成本,但准确率提高了2.6%,几乎与GRU持平。通过损失函数对比图可以看出,改进后的CNN模型收敛更快,并且在收敛过程中相比于CNN模型更加稳定,波动性更小。因此,改进的损失函数在效果上有所提升。
参考文献
[1]丁兆云等.微博数据挖掘研究综述[J].计算機研究与发展,2014,51(4):691-706.
[2]张仰森等.基于双重注意力模型的微博情感分析方法[J].清华大学学报:自然科学版,2018,(6):11-13.
[3]Le Q,Mikolov T.Distributed representations of sentences and documents[C].International conference on machine learning.2014:1188-1196.
作者简介:
张子轩(1994.01-),男,汉族,燕山大学理学院应用统计专业硕士在读,主要研究方向:应用统计。
(作者单位:燕山大学理学院)
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20
软件导刊(2019年1期)2019-06-07
数字技术与应用(2019年2期)2019-05-14
现代电子技术(2018年8期)2018-04-13
软件工程(2017年11期)2018-01-05
智能计算机与应用(2017年5期)2017-11-08
科技创新与应用(2016年35期)2017-02-21
计算机应用(2016年12期)2017-01-13
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
