
基于深度学习的视觉问答系统
2019-10-21 08:16葛梦颖孙宝山
现代信息科技 2019年11期
葛梦颖 孙宝山

摘 要:随着互联网的发展,人类可以获得的信息量呈指数型增长,我们能够从数据中获得的知识也大大增多,之前被搁置的人工智能再一次焕发活力。随着人工智能的不断发展,近年来,产生了视觉问答(VQA)这一课题,并发展成为人工智能的一大热门问题。视觉问答(VQA)系统需要将图片和问题作为输入,结合图片及问题中的信息,产生一条人类语言作为输出。视觉问答(VQA)的关键解决方案在于如何融合从输入图像和问题中提取的视觉和语言特征。本文围绕视觉问答问题,从概念、模型等方面对近年来的研究进展进行综述,同时探讨现有工作存在的不足;最后对视觉问答未来的研究方向进行了展望。
关键词:深度学习;人工智能;视觉问答;自然语言处理
Abstract:With the development of the internet,the amount of information available to human beings increases exponentially,and the amount of knowledge we can get from the data also increases greatly. Artificial intelligence,which had been put on hold,is radiate vitality. With the continuous development of artificial intelligence, in recent years,visual question answer (VQA) has emerged as a hot topic in the field of artificial intelligence. Visual question answer (VQA) system needs to take pictures and questions as input and combine these two parts of information to produce a human language as output. The key solution for VQA is how to fuse visual and linguistic features extracted from input images and questions. This paper focuses on the visual question and answer,summarizes the research progress in recent years from the aspects of concept and model,and discusses the existing deficiencies. Finally,the future research direction of VQA are prospected.
Keywords:deep learning;artificial intelligence;visual question answer;natural language processing
0 引 言
随着互联网科技的光速发展,网络信息变得越来越包罗万象、数量庞大。面对庞大的数据,如何筛选有用信息成为互联网发展的一项重要任务。视觉问答(VQA)是最近几年出现的一个新任务,视觉问答(VQA)系统能够參考输入的图片内容回答用户提出的问题,它运用了计算机视觉和自然语言处理两个领域的知识。在视觉问答中,计算机视觉技术用来理解图像,NLP技术用来理解问题,两者必须结合起来才能有效地回答图像情境中的问题。这相当具有挑战性,因为传统上这两个领域是使用不同的方法和模型来解决各自任务的。给定一张图片,如果想要机器以自然语言来回答关于这张图片的某一个问题,那么,机器对图片的内容、问题的含义和意图以及相关的常识都需要有一定的理解。在实际应用中,针对信息中大量的图片,采用视觉问答系统就可以使用机器来采集相应有用的信息,减少了人的工作量。
本文的贡献有3个方面:
(1)阐述了视觉问答近年来的相关研究现状;
(2)探讨现有视觉问答工作的不足;
(3)提出视觉问答技术的未来需要解决的科学问题及应用方向。
1 视觉问答研究现状及方法
视觉问答(VQA)是计算机视觉、自然语言处理和人工智能交叉的新兴交叉学科研究课题。给定一个开放式问题和一个参考图像,视觉问答(VQA)的任务是预测与图像一致的问题的答案。VQA需要对图像有很深的理解,但是评估起来要容易得多。它也更加关注人工智能,即产生视觉问题答案所需的推理过程。
在本节中,我们回顾了近年来的VQA研究的发展情况。
(1)传统分类方法。根据数据集中训练集答案出现的次数设定一个阈值,保留出现过一定次数的答案,作为答案的候选选项形成一个答案候选集。然后把每一个候选答案设置为不同的标签,将VQA问题作为一个分类问题来解决。该模型回答的答案大多都与图像无关并且随着数据集的不同会回答差别很大的答案。例如SWQA模型[1]:
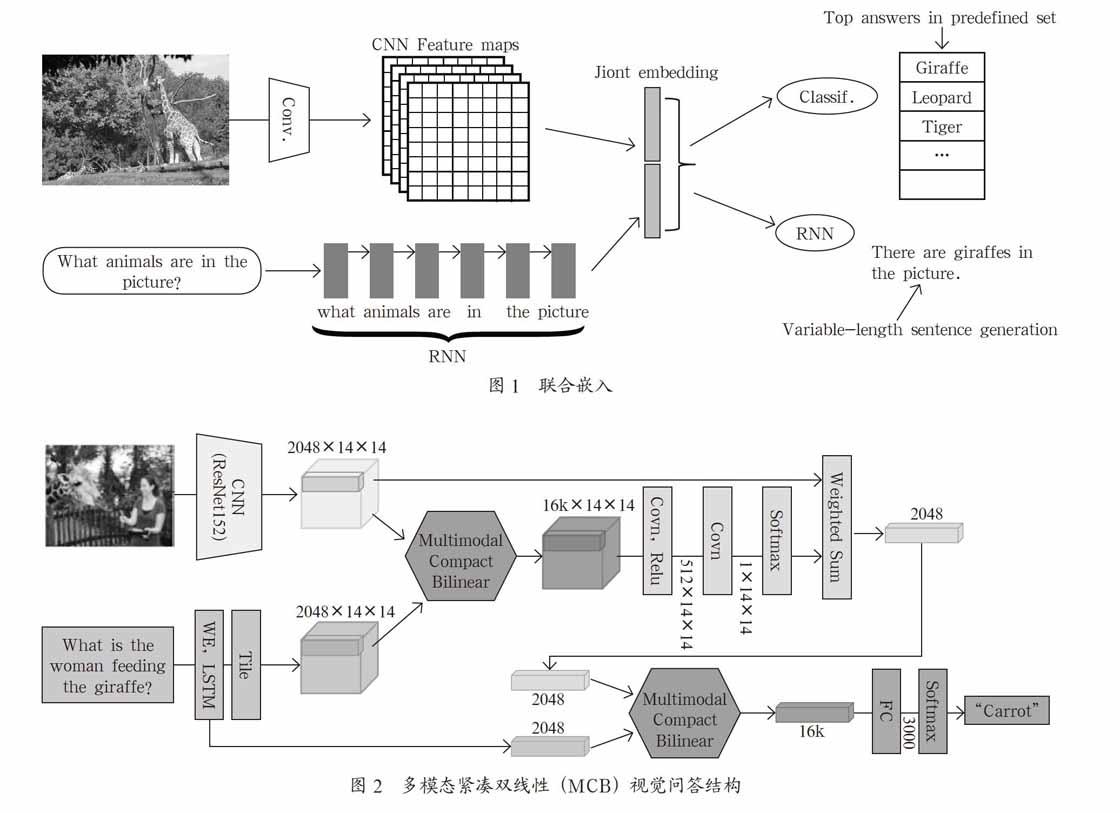
(2)联合嵌入。现有的方法主要是将VQA作为一个多标签分类问题。最近的许多方法探索了在深层神经网络中添加一个联合嵌入来表示图像和问题对。通常,图像特征是在对象识别数据集预先训练的卷积神经网络(CNNs)的最后一个全连通层的输出。文本问题分为序贯词,它被输入到一个递归神经网络(RNN)中,以产生一个固定长度的特征向量作为问题表示。图像和问题的特征是共同嵌入作为一个矢量来训练多标签分类器预测答案。如图1所示。
联合嵌入能够将相对独立的图片特征和问题文本表示结合起来,更能够根据图片来回答问题。但联合嵌入中大多都采用连接向量或矩阵相乘或点乘来直接连接图片和问题表示,虽然这产生了一种联合表示,但它可能没有足够的表达能力来充分捕捉两种不同方式之间的复杂联系。
(3)注意机制。与直接使用深度CNN全连接层的实体图像相比,注意力模型已经被广泛用于为VQA选择最相关的图像区域。早期的研究主要考虑了对图像区域的问题引导关注。在后来的研究中,另外考虑了注意力的相反方向,即对问题词的图像引导注意力。Lu等人[2]引入了共同关注机制,该机制产生并使用对图像区域和问题词的关注。为了缩小图像和问题特征的差距,Yu等人[3]利用注意力不仅提取空间信息,而且提取图像的语言概念。Z.Yu等人[4]将注意机制与图像与问题的新型多模态特征融合相结合。
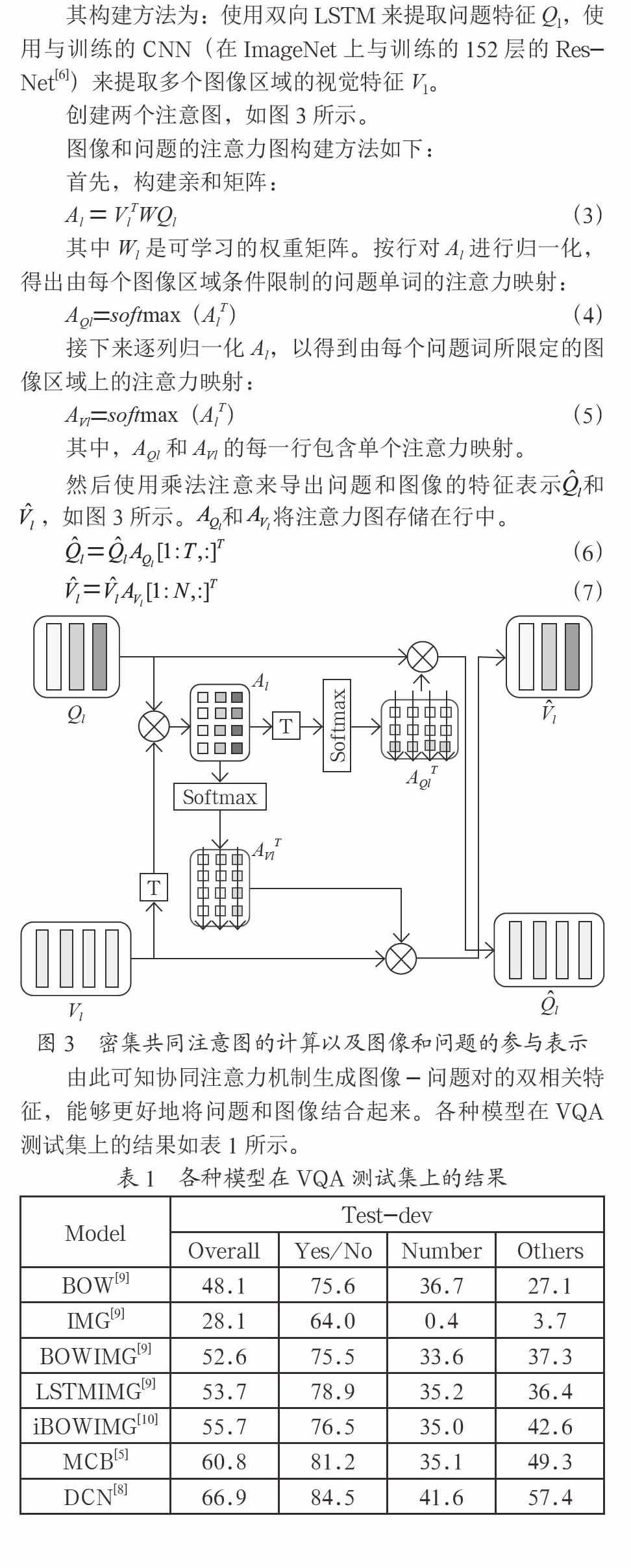
例如AkiraFukui等人的基于MCB的改进算法[5],如图2所示。
首先,使用基于ImageNet数据预训练的152层ResNet[6]提取图像特征[7]。输入问题首先被标记为单词,单词是一个one-hot编码,并通过一个学习的嵌入层传递。然后,再使用MCB将图像特征与输入问题表示进行合并。如图2所示,最后,经过全连接以及softmax预测得到问题答案。
MCB模型结构就是对图像进行关注的方法。基于MCB的联合嵌入方法有效地减少了参数的数量,并且该方法将文本表示作为注意机制来影响图像特征的权重,从而得到与问题相关的图像特征。
除了图像上的关注之外,最近的很多文章也提出了协同关注的机制。协同注意也考虑对问题单词的关注,但它是从整个图像创建的。应用多个共同关注机制来关注图像区域和文本中的问题。例如Duy-Kien等人的密集共同关注机制[8],如图3所示。
这其中,使用了多个协同注意机制来捕获问题和图像中的细粒度信息。应用现有的区域方案算法生成目标区域,并根据问题选择与问题最相关的区域来生成特征;应用双向LSTM网络来处理问题,根据图像区域生成与图像区域最相关的问题特征。所提出的机制可以处理任何图像区域和任何问题单词之间的每个交互,这可能使得能夠模拟正确回答问题所必需的未知的复杂图像-问题关系。
其构建方法为:使用双向LSTM来提取问题特征Ql,使用与训练的CNN(在ImageNet上与训练的152层的Res-Net[6])来提取多个图像区域的视觉特征Vl。
创建两个注意图,如图3所示。
2 存在的问题
总结来说,虽然目前的VQA研究取得了一些成就,但是就目前的模型达到的效果来看,如表1的数据显示,有以下几个问题:
(1)整体准确率并不高,除了在回答单一答案的简单问题(例如:Yes/No问题)上有较高的准确率外,其他方面模型(例如:Number问题)的准确率普遍偏低;
(2)当前的VQA模型结构还相对简单,答案的内容和形式比较单一,对于开放式的问题和稍复杂的需要更多先验知识进行简单推理的问题还无法做出正确的回答;
(3)在许多模型中发现当对图片背景的常识性推理错误、问题聚焦的物体太小、需要高层次的逻辑推理等问题出现时,模型往往无法给出正确的预测;
(4)许多用于VQA的模型往往直接使用ImageNet训练好的CNN模型,但由于用户的问题是开放式的,要正确回答开放式问题,这样一来就显得模型使用的特征过于单一,因此不能够很好的回答问题;
(5)还有一个问题是深度学习的共有问题,即缺乏可解释性,我们大多数都是根据实验结果来推测模型有效,但是找不到具体有效的地方及缺乏能够证明的原理。
3 未来发展方向
作为需要视觉理解与推理能力的,融合计算机视觉以及自然语言处理的视觉问答VQA,它的进步在计算机视觉的发展和自然语言处理的能力提高的基础上还有着更高的要求,即,对图像的理解——在图像处理的基础能力,如识别,检测等的基础上还要学习知识与推理的能力。需要提高模型的精度,提高回答问题的粒度。然而,这条路还有很长的距离要走,一个能够真正理解图像、学习到知识和推理能力的VQA模型才是最终目标。
参考文献:
[1] Malinowski M,Fritz M . A Multi-World Approach to Question Answering about Real-World Scenes based on Uncertain Input [J].OALib Journal,2014.
[2] Lu J,Yang J,Batra D,et al. Hierarchical Question-Image Co-Attention for Visual Question Answering [C].30th Conference on Neural Information Processing Systems(NIPS) in 2016,Barcelona,Spain,2016.
[3] Yu D,Fu J,Mei T,et al. Multi-level Attention Networks for Visual Question Answering [C]// 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). IEEE,2017.
[4] Yu Z,Yu J,Fan J,et al. Multi-modal Factorized Bilinear Pooling with Co-Attention Learning for Visual Question Answering [J].2017 IEEE International Conference on Computer Vision,2017(1):1839-1848.
[5] Fukui A,Park D H,Yang D,et al. Multimodal Compact Bilinear Pooling for Visual Question Answering and Visual Grounding [J].ScienceOpen,2016:457-468.
[6] He K,Zhang X,Ren S,et al. Deep Residual Learning for Image Recognition [J].2016 IEEE Conference on Computer Vision and Pattern Recognition,2016(1):770-778.
[7] Deng J,Dong W,Socher R,et al. ImageNet:a Large-Scale Hierarchical Image Database [C]// 2009 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2009),20-25 June 2009,Miami,Florida,USA. IEEE,2009.
[8] Nguyen D K,Okatani T. Improved Fusion of Visual and Language Representations by Dense Symmetric Co-Attention for Visual Question Answering [J/OL].https://arxiv.org/pdf/1804.00775.pdf,2018.
[9] Antol S,Agrawal A,Lu J,et al. VQA:Visual Question Answering [J].International Journal of Computer Vision,2017,123(1):4-31.
[10] Zhou B,Tian Y,Sukhbaatar S,et al. Simple Baseline for Visual Question Answering [J].Computer Science,2015.
作者简介:葛梦颖(1996.12-),女,汉族,安徽宿州人,硕士研究生,研究方向:自然语言处理、深度学习等;孙宝山(1978.10-),男,汉族,天津人,副教授,硕士生导师,工学博士,研究方向:机器学习、自然语言处理等。
猜你喜欢
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
小康(2017年16期)2017-06-07
计算机应用(2016年12期)2017-01-13
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
南风窗(2016年19期)2016-09-21
电脑知识与技术(2016年10期)2016-06-16
