
基于集成推理卷积神经网络的快速行人检测
2019-10-22 06:36谭论正丁锐
现代计算机 2019年23期
谭论正,丁锐
(1.中山职业技术学院信息工程学院,中山528402;2.中山火炬职业技术学院信息工程系,中山528436)
0 引言
行人检测是辅助驾驶系统的一个重要的研究课题,通常使用激光测距或基于视觉的方法来进行。激光测距需要在普通车辆中安装激光设备,成本高;而基于视觉的行人检测方法可以降低成本并确保高精度,最符合普通车辆的要求。基于视觉的行人检测方法使用车载相机记录的单帧或多帧图像进行分析检测。单帧方法能够实现实时检测,但是检测精度有待提高,因此单帧方法多与其他方法结合使用。多帧方法通过使用运动和上下文信息实现高检测精度,提取丰富的信息,但计算量大,实时性差。
行人检测需要匹配帧之间的对应特征点。文献[1]提出了基于级联分类器的快速行人检测,采用类似Haar 的特征进行帧之间的特征点跟踪,速度快,但特征过于简单准确率不高。文献[2-3]提出基于小区域的梯度信息或LBP 特征来训练SVM 分类器进行行人检测。HOG[4]特征侧重于局部区域的变化,并且对于姿势的微小变化具有鲁棒性。然而HOG+SVM 的方案计算量大,且对于遮挡问题不鲁棒,因此文献[5-6]提出了可形变组件模型(DPM)处理大的姿态变化,可以检测整个行人模型和部分区域的行人。DPM 在行人检测基准测试中获得了较好的性能,DPM 特征计算复杂高,计算速度慢。
传统的人体检测方法采用手工设计的特征提取和基于统计学习的训练分类。存在以下缺点:①特征设计需要人类知识来确保稳健性,耗费大量时间且掺杂人为因素,而实际应用场景背景复杂、行人服饰多样,还存在行人姿态及遮挡等问题,使得传统方法提取的特征难以满足实际应用的要求。②分类器的性能受训练样本的影响较大,需要大量的标注特征样本来训练概率模型,但在离线训练时的负样本无法涵盖所有真实应用场景。
近年来,深度学习的方法[7-8]引起了人们的注意,通过卷积神经网络(CNN)自动学习图像特征,把低层特征组合起来形成具有良好表示的高层特征,具有出色的特征表示和分类能力,在图像识别相关的任务中取得了很大成功。基于深度卷积神经网络(CNN)的行人检测实现了高精度的检测[9-10]。激活函数用来增加神经网络模型的非线性,主要有sigmoid 函数、tanh 函数和ReLU 函数,sigmoid 函数与tanh 函数输出有界,可能带来梯度消失问题,而ReLU 函数能解决梯度消失问题并加快收敛速度。泛化能力是神经网络的重要性能,ReLU 函数使用Dropout 机制来获得泛化,Dropout 随机丢失固定比例的单位,该比率通常设定为50%,所选单位的响应值为零。在训练过程的每次迭代中选择不同的单位,虽然使用Dropout 训练的网络表现出改进的泛化性能,但这种随机选择仅适用于训练过程。
为了实现更好的泛化,本文提出用于训练过程的随机丢失策略和用于分类过程的集成推理网络(EIN)。本文的随机丢失以灵活的概率随机选择丢失单位,而不是传统Dropout 中使用的固定概率。构建在完全连接层中的集成推理网络(EIN)是具有不同结构的多个网络。最后本文在一系列对比实验中验证了EIN 的架构,并将所提出的方法的性能与现有的方法进行了比较。
1 卷积神经网络
卷积神经网络(CNN)包括输入层、卷积层、池化层和分类层。除原始数据外,每个输入层采用边界填充对数据进行标准化。卷积层具有M 个大小为k*k 的内核,将输入数据进行卷积过滤,输出到池化层中进行二次采样,加快收敛和泛化。一系列交替出现的卷积层和池化层后,所有加权节点连接到分类层,通过Softmax 输出每个类的概率。CNN 利用监督学习,通过反向传播随机初始化和更新滤波器,通过如下公式(1)和公式(2)梯度下降最小化反向传播的估计权重E:

其中,n=1,…,N 是训练样本,η是训练比率,W(l)是在l 层连接到(l+1)层的权重,每个训练样本的误差En是输出值和标签之间差异的总和。△W(l)可由式(3)得到:

其中,y(l-1)是第(l-1)层的输出,e 是输出节点的误差。A(l-1)是从第(l-1)层中的所有节点连接到l层节点的累积值。式(4)计算得到局部梯度下降值,激活函数φ可以是sigmoid 函数,双曲正切函数或者ReLU函数[11]。整个网络中的连接权重按照预定的迭代次数同时更新,或者直到满足收敛条件。
2 改进的随机丢失策略
Dropout 是减少过度拟合和改进泛化的有效方法[8]。Dropout 通过忽略下面层级中的某些信息来产生稳健性,传统的Dropout 在每次迭代中随机选择设置为零的隐藏单位,以50%的概率将隐藏单元的输出设置为零。本文通过随机概率来扩展此Dropout 技术,即以随机概率将隐藏单元的输出进行丢失。图1 说明了本文使用灵活的随机丢失率获得泛化。Dropout 策略如式(6)所示:

其中,随机丢失概率介于30%和70%之间。例如,我们在第一次迭代中为每个图层设置比率为60%和30%,然后在第二次迭代中将此值更改为40%和70%。
3 集成推理网络(EIN)
集成推理网络(EIN)旨在从分类过程中删除与前一层的连接,EIN 在不同时间将输入值反馈到训练网络的完全连接层,完全连接层的一些单元被随机设置为零。本文通过随机选择不同的单元与原始训练的网络形成不同的网络。EIN 构建过程的步骤如下:
(1)特征映射:输入图像I 与滤波器V 进行卷积,采用激活函数φ生成特征映射,如式(7)所示。

其中,b 是偏差项。使用Maxout 激活函数[12],从每个单位的K 个特征映射中选择最大值,如公式(8)所示。

然后,采用最大池来选择每个特定区域中的最大值,通过公式(9)调整特征图的大小来获得对微小形变的鲁棒。尽管完全连接层中的单元将根据随机选择而改变,但是卷积层和池化层保持相同。因此,我们可以共享最终池化层的输出值。

(2)通过公式(10)进行网络构建:在完全连接层和分类层中,将随机选择的单元的响应值设置为零。

其中,x 为步骤(1)中定义的特征映射。Wl和bl是连接权重和第l 层的偏差。m 控制响应值,其值设置为0 或1,当m 设置为0 时,响应值为0,当m 设置为1 时,响应值为1。我们用随机选择的零响应单元构造N 网络。网络n 中每个类的概率由方程式(11)中的Softmax 函数给出。

(3)最终输出分类器值:从每个网络的每个类的概率Onc获得最终输出类的值。所有Onc存储到概率集Sc 中,并从中选出均值
在以上基础上,采用滑动窗口方法来检测不同规模的多个行人。在检测过程中,需要在大量窗口中判断是否存在行人。我们应用HOG+SVM 分类器来减少寻找行人候选区域的处理时间,然后才CNN 对候选区域进行行人判断。
4 实验
本文使用Caltech Pedestrian 数据库和Daimler Mono Pedestrian Benchmark 数据库评估随机丢失策略和和几种具有不同网络数量和不同最终输出决策(最大值或平均值)的EIN 架构的效率。使用Caltech Pedestrian Dataset 将本文方法与其他方法进行比较。
实验采用Python 语言引入TensorFlow 构建CNN,并调用了OpenCV 库实现了文中的数据扩展,测试的硬件环境为HP-EliteDesk-800-G4 内配2 块1080 NVIDIA 独立显卡的图形工作站一台,使用的测试平台是Ubuntu 16.04 操作系统。本文采用的CNN 结构如表1 所示。Caltech Pedestrian 数据集有4,000 个正样本和200,000 个负样本用于训练,8,273 个测试图像。本文通过移位、旋转、镜像和缩放从原件中增加了101,808 个正样本。对于Daimler Mono Pedestrian Benchmark 数据集,我们从31,320 个样本中增加了250,560个正样本;负样本数量为254,356 个。参数更新的总迭代次数为500,000,分5 个mini-batch,训练比率η设定为0.01。

表1 采用的CNN 结构
4.1 不同网络设置下的性能比较
首先,我们通过改变网络数量和最终输出的决定方式来衡量EIN 的最佳架构。我们评估包含从1 到23 层网络的EIN 体系结构。每个网络在卷积层和池化层中保持相同的结构,但是完全连接层根据单元的随机选择而变化。当网络数量为1 时,我们有一个传统的网络。我们从所有网络中选择平均概率。图1(a)和(b)分别显示了使用Caltech Pedestrian Dataset 和Daimler Mono Pedestrian Benchmark Dataset 的评估结果。首先,实线和虚线之间的差异表示Dropout 和Random Dropout 的性能。在Caltech Pedestrian 数据库中,我们可以看到Random Dropout 将准确度提高了约6%。具有23 个平均选择网络的架构达到了最佳精度,在Caltech Pedestrian 数据库的失败率为37.77%。从该评估中,在完全连接的层中具有多个网络和不同结构的EIN 获得了更好的检测精度。在Daimler Mono Pedestrian Benchmark 数据集中,CNN 的未命中率为35.78%,而本文方法在23 个集合网络中的平均失败率为31.34%,显著提高了命中率。

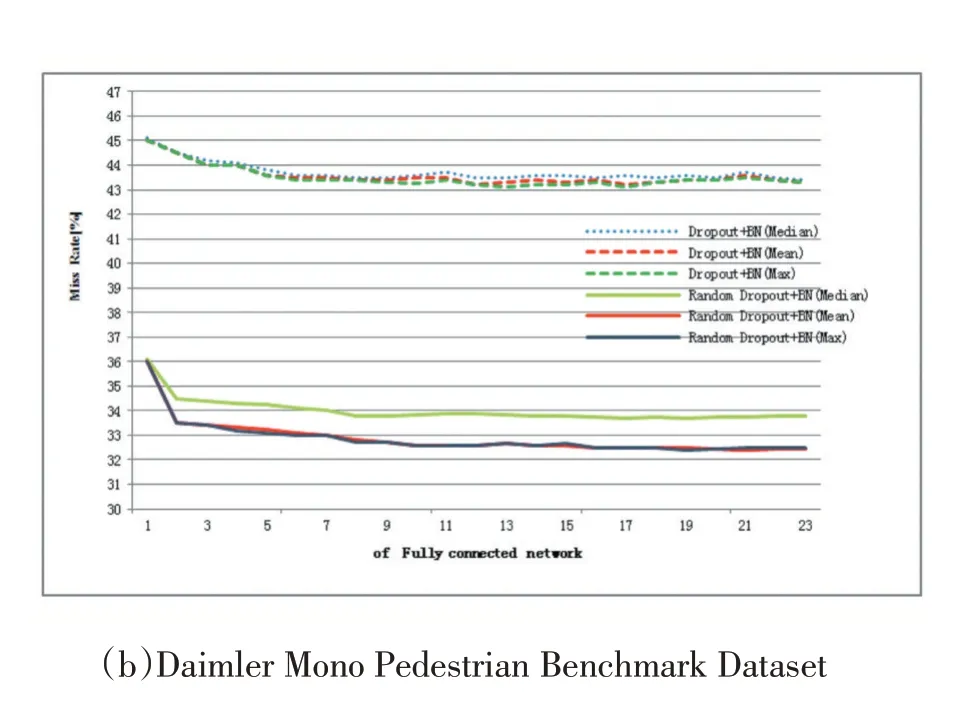
图1 不同网络性能比较
4.2 与其他方法的性能比较
本文在Caltech Pedestrian Dataset 上将所提出的方法与以下其他方法进行了比较:HOG[9]、传统CNN[11]、可切换深度神经网络[13]、Fast R-CNN[15]进行对比实验。如表2 所示,当每幅图像假阳性(False Positive per Image)FPPI 为0.1 时,本文方法的识别精度相对于传统CNN提高了15%。此外,本文所提出的方法实现了与可切换深度网络[13]类似的性能,然而可切换深度网络需构建复杂的网络结构,本文简单的网络架构足以在深度学习方法中实现最先进的性能。与目前图像检测性能最高的Faster R-CNN 相比,它将检测精度提高了约10.5%。Faster R-CNN 使用超像素方法确定图像中的感兴趣区域,并使用CNN 提取特征。将提取的特征传递给为每个对象训练的SVM,最后检测特定的对象位置。虽然Faster R-CNN 在目标检测上准确,但在尺寸较小的图像中,提出的行人特征没有什么区分能力,且在背景复杂干扰较大的环境中行人检测上效果一般。

表2 在不同数据库中不同方法的识别结果
图2 显示了Caltech Pedestrian Dataset 和Daimler Mono Pedestrian Benchmark 中的行人检测结果检测。第一列和第四列中的结果是通过HOG+SVM 检测的示例,第二和第五列是DPM 检测的示例。第三列和第六列中的行人检测结果是本文所提出的方法的结果。如图2 所示,传统方法不能检测到小面积行人,本文所提出的方法在同一场景中可以检测,此外本文方法能够检测诸如遮挡,各种姿势的困难情况,误报率更低。
5 结语
我们提出了两种通过基于Dropout 随机选择单元来改进行人检测的技术。本文的随机丢失策略以灵活的速率将单位的相应值随机设置为零。EIN 构造多个网络,在完全连接层中具有不同的结构,产生最终输出的决策方式。我们实现了与深度学习方法中先进方法相当的性能,而且提出的方法结构很简单。在未来的工作中,我们将尝试降低实时处理的计算成本。

图2 不同行人检测方法结果对比
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
意林(2021年5期)2021-04-18
扬子江(2019年1期)2019-03-08
电子制作(2019年24期)2019-02-23
