
基于U-Net和BGRU-RNN的实用歌声检测系统
2019-10-23 03:20陈志高张旭龙肖寒肖川
微型电脑应用 2019年10期
陈志高, 张旭龙, 肖寒, 肖川,2
(复旦大学 1.计算机科学技术学院, 上海 201203;复旦大学 2.计算中心, 上海 200433)
0 引言
歌声检测任务是指在一段音乐或者混合音频信号中检测出包含人声的部分。近年来在音乐信息检索(Music Information Retrieval, MIR)领域中,歌声检测得到了越来越多的关注,因其在许多歌手相关的检索任务如歌手识别[1]、旋律提取[2]、哼唱检索中能够起到关键的作用。
在[3]中,作者使用HPSS方法把单声道音频给分解成谐波部分和冲击波部分,然后提取相应的特征来进行实验,取得了显著的效果提升。HPSS方法实际上是歌声分离的方法,引入歌声分离作为前处理可以将混合信号聚焦于歌声部分。深度卷积网络[4]在歌声分离中表现出良好的性能,将U-Net作为前处理可以获得更加干净的歌声片段。
为简化特征选择,本文直接组合了四个经典的特征,来自于语音处理领域的MFCC、Mel-filter Bank[3]和LPCC,以及来自音乐信息检索领域的Chroma[5]。以上的这些特征可以较为全面地刻画音频的特性,剩下的工作交给神经网络分类器来完成,生成歌声检测中所需的d-vector。
最近的研究中,文献[3,6]使用了LSTM-RNN作为分类器,取得了良好的效果。GRU与LSTM比较类似,其提出都是为了解决RNN的梯度消失问题。但 GRU结构更简单,更适合用来进行实时计算,实验[7]显示GRU的收敛速度往往比LSTM要快。与GRU相比,BGRU可以在时序上双向处理信息,这样可以充分利用上下文信息以做出决策。
综上所述,本文提出了一个可实用的三步走的歌声检测方法。首先使用深度U-Net卷积网络来进行歌声分离。其次提取MFCC、Mel-filter Bank、LPCC和Chroma作为混合特征。最后使用BGRU-RNN网络作为分类器。
本文的结构如下。第2节是相关工作,第3节简要阐述本文用到的方法,第4节为实验部分,第5节为结论。
1 相关工作
较早的研究中,Rocamora和Herrera[8]在统计分类器上做了特征对比的实验。实验显示,MFCC效果最好,正确率为78.5%。
Ramona[9]使用支持向量机(support vector machine, SVM)作为分类器,用隐马尔可夫模型(Hidden Markov Model, HMM)来做时域平滑。实验正确率为82%。
Mauch等人[10]使用了四种音色和旋律特征与SVM-HMM分类器,正确率为87.2%。其发布了102首歌曲的数据标注,其中100首歌来自RWC数据集的流行音乐部分。
Lehner[11]使用了MFCC特征,用随机森林作为分类器,用中值滤波做了时域平滑。经过一系列手动调优,其获得了82.36%的正确率。
Eyben等人[12]提出了基于LSTM-RNN和RASTA-PLP特征的模型。LSTM-RNN的主要优点在于它能够模拟出输入数据之间的长期依赖关系。实验显示,LSTM-RNN的效果好于所有统计方法。
Lehner在[6]中引入了LSTM-RNN。其使用了包括30维MFCC及其差分以及其他一些频谱特征在内的共111维特征。实验在RWC-Pop音乐数据集上取得了业界最高水平。
Leglaive[3]使用BLSTM-RNN作为分类器,BLSTM-RNN能够同时考虑过去和未来的时域信息来对歌声的存在与否进行决策。使用了通过HPSS方法处理得到的Mel-filter Bank特征。其在Jamendo数据集上正确率为91.5%。
Schlüter[13]的研究首先使用了音高偏移、时序拉伸和随机频率过滤来增加训练数据量。然后使用梅尔频谱作为输入特征、CNN作为分类器来组成歌声检测系统。在RWC-Pop上错误率约为9%,与业界最高水平相当。
2 提出的方法
本文提出的方法包括三个步骤,分别为歌声分离、特征提取和模式识别。音频信号首先经过歌声分离的预处理,然后提取一定的特征,最后输入到分类器中去。系统框架如图1所示。
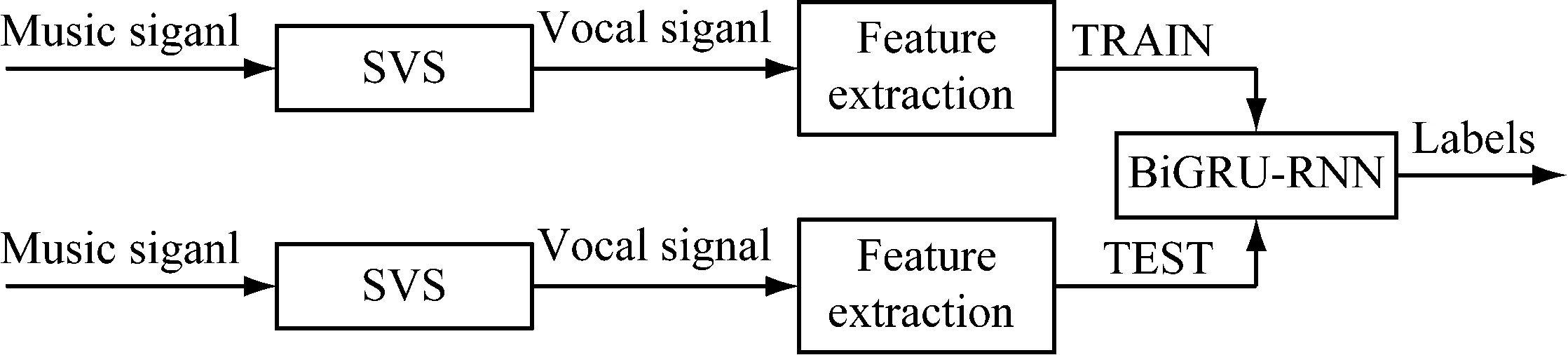
图1 系统框架
2.1 歌声分离
2.1.1 U-Net
在[4]中,Jansson等人使用深度U-Net卷积网络来进行歌声分离,取得了很好的效果。此处使用了[4]中的深度U-Net卷积网络,用iKala[14]和MedleyDB[15]进行训练,然后将训练好的U-Net网络应用到需要分离的音频中去。
主要步骤如下。首先分别针对歌声和伴奏训练两个U-Net网络,处理信号频谱的幅值。其次使用训练好的U-Net来对原信号的频谱进行掩蔽得到新的幅值。最后使用新的幅值和原相位重建信号。
2.1.2 NMF
非负矩阵分解(Non-negative Matrix Factorization, NMF),也被称为非负矩阵近似,是多元数据分析的一种算法。
使用NMF算法进行歌声分离步骤如下。首先把原信号从时域转换到频域,这样以后才可以被NMF进行分解。其次在成分选择之前进行NMF操作。再次为成分选择,即如果选中的成分包含从伴奏中提取出来的频率,就用滤波器来消除这些成分。最后,重建信号。
2.1.3 RPCA
鲁棒主成分分析(Robust Principal Component Analysis, RPCA)是广泛使用的统计方法主成分分析的改进版本。RPCA由Candes[16]提出,并且被认为是恢复少部分数据被损坏的低秩矩阵的凸规划。
使用RPCA的歌声分离步骤如下。首先用短时傅里叶变换来计算音乐信号的频谱,表示为矩阵X。然后进行RPCA操作,得到低秩矩阵A和稀疏矩阵E。其中E对应于语音,A对应于伴奏。最终加上原始信号的相位信息,通过短时傅里叶逆变换来得到时域信号波形。
2.2 特征提取
本文选择了来自语音领域和音乐领域的四个经典特征。它们分别是MFCC, Mel-filter Bank, LPCC和Chroma。以上四种特征可以较为全面地刻画出音频的特性,然后通过神经网络分类器来生成歌声检测中所需的d-vector。
实验中,帧长设为40 ms,帧移设为20 ms。最后的对比实验中,提取了20维的MFCC特征、20维的Mel-filter Bank特征、12维的LPCC特征以及12维的Chroma特征,组成了64维的混合特征。
2.3 BGRU-RNN
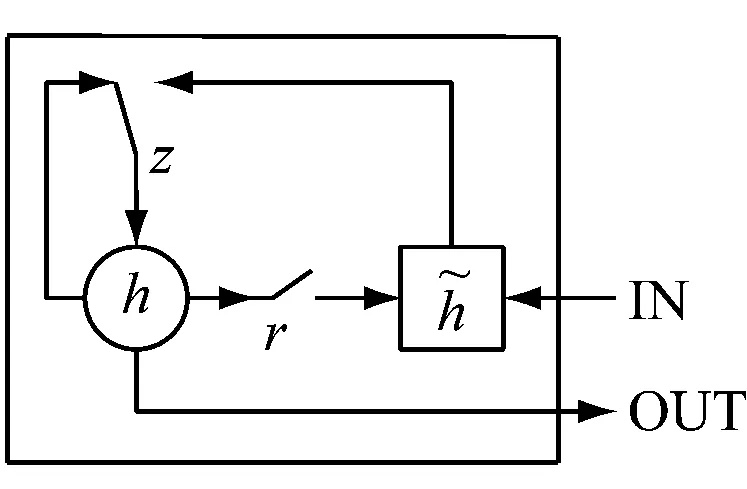
LSTM[18]和GRU[19]单元的提出都是为了解决循环神经网络(Recurrent Neural Network, RNN)难以训练、难以捕获长期依赖[20]的问题,结构如图2所示。

(a)
(b)
最近的研究工作中,使用了LSTM-RNN作为歌声检测任务的分类器。
GRU和LSTM共同点在于,它们都会将t到t+1时刻的更新保留下来,而传统的单元则会用新值替换旧值。不同点在于,GRU并未如LSTM一般使用单独的记忆单元。
LSTM控制着记忆单元,而GRU则把对单元内部的操作全部暴露出去。LSTM中信息流添加到记忆单元独立于遗忘门,而GRU信息流的更新则与更新门绑定在一起完成。因此GRU相比于LSTM,结构更简单透明,矩阵乘法更少,运算效率就更高。
根据[7]的研究,很难对GRU和LSTM哪个更好下定论,但其实验表明结构更简单的GRU收敛速度往往更快,实验结果也倾向于更优。这是将GRU应用到歌声检测上面来的主要动机。为了更好的利用上下文信息,最终选取BGRU-RNN作为分类器。
本文使用了一个包含120个GRU单元的双向RNN网络作为分类器,其中包含一个隐层。输入数据的结构是特征的维度乘上帧块时长,帧块时长的调整会在实验部分详细介绍。输出层是一个sigmoid函数,输出的类别是1或0,其中1代表歌声,0代表非歌声。Dropout被设为0.2。使用Early Stopping策略,如果验证集上的实验效果在10次之后没有得到改进,模型就会停止。
3 实验部分
3.1 数据集
本文选择了使用较多的RWC-Pop数据集。RWC-Pop数据集包含100首流行音乐,Mauch等人在[10]中对其进行了标注。包括80首日文歌曲和20首英文歌曲。数据集分布比较均衡,其中歌声片段的长度约占51.2%,非歌声片段约占48.8%。
本文进行了五折交叉验证实验,数据被分成五份,一份用来测试,其余的四份用来训练。验证数据从训练数据中取,占比为20%。以上3个部分相互独立。
3.2 评价指标
本文使用4个常用的评价指标[21],基于帧的正确率(Accuracy)、准确率(Precision)、召回率(Recall)和F1-measure。
3.3 实验及讨论
3.3.1 歌声分离前后效果对比实验
此处使用U-Net来做歌声分离,如图3所示。

图3 RWC-Pop上歌声分离前后效果对比
由图3看出,歌声分离后实验效果得到了大幅度的提升。在正确率和F1-measure两个关键指标上,提升了约10%。因此证明,歌声分离能够切实提高歌声检测任务的表现。
3.3.2 不同歌声分离方法对比实验
此处使用U-Net、NMF和RPCA分别进行了歌声分离。选取20维MFCC特征,模型采取BGRU-RNN,帧块时长为25帧,即520 ms。如图4所示。
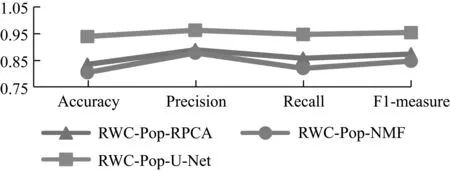
图4 RWC-Pop数据集上不同歌声分离算法的对比
此处主要比较正确率和F1-measure这两个核心指标。由图4可以看出,U-Net表现最好,后续将会使用U-Net作为歌声分离的方法。
3.3.3 帧块时长的调整对比实验
先前的研究工作中所使用的帧块时长不尽相同,实验中发现不同的帧块时长对实验效果的影响很大,因此对这个参数的确定进行了实验对比,如表1所示。
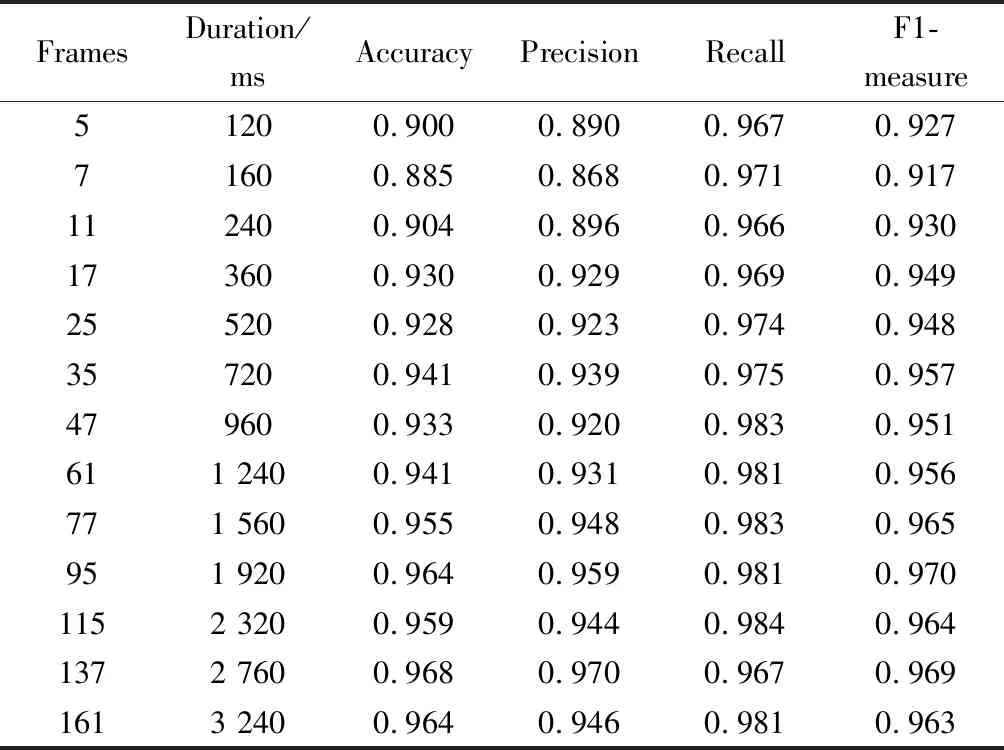
表1 RWC-Pop数据集上的帧块时长
结果显示,实验表现和帧块时长有显著的关联性。帧块时长越长,实验表现就越好。最佳的帧块长度为95帧,该影响可能的原因如下。
第一,帧块时长越长,模型得到的上下文信息就越多,判断就更为准确。第二,由于模型的输入为连续的帧块,且这些帧必须为同样的标注,如果有混杂的数据,就无法给出其确定的标签。因此模型的输入要不都是连续的歌声,要不都是连续的非歌声,其他零碎的帧就会被丢弃。帧块时长越大,被丢弃的帧就越多,实验的精度也就会相应降低。另外,标注精度随着帧块时长的增加而减小,帧块时长越大,标注的结果就越粗糙。业界对于标注精度并没有明确的规定,一般按照经验来确定。
[6]在RWC-Pop上得到了最好的实验结果,[3]在Jamendo上得到了最好的实验结果。[6]的帧块时长为140 ms,[3]的帧块时长为800 ms。根据本文实验的情况,选取了两个比较接近且略小的情形,分别是120 ms和720 ms。
3.3.4 与其他研究的对比
歌声分离使用深度U-Net网络,特征为前文所述的64维混合特征,模型方面采取BGRU-RNN,结构依照前文阐述。模型中帧块时长分别为120 ms和720 ms,用BGRU-RNN-1和BGRU-RNN-2如表2所示。

表2 RWC-Pop上的实验对比
表2给出了RWC-Pop上的实验结果。在RWC-Pop数据集上,BGRU-RNN-2比业界最高水平大约高出2%。且所使用的GRU在结构上要比LSTM更加简单,有着更高的运算效率,因此提出的方法比Lehner[6]更适合用来做实时计算。
4 总结
本文提出了一个基于U-Net和BGRU-RNN的实用的三步走的歌声检测方法,在RWC-Pop数据集上得到了与业界最高水平相当或者更好的表现。
三个步骤分别是歌声分离、特征提取和模式识别。使用深度U-Net神经网络进行歌声分离。使用了四种经典特征进行组合,对音频信号的特征做出了全面的刻画。BGRU能够更好地利用上下文信息,且比LSTM结构更简单运算效率更高。总体来说,实验表现更好、结构更简单、运算效率更高,因此更为实用。
[13]中使用音高偏移、时序拉伸和随机频率过滤来增加训练数据量,然后用简单的梅尔频谱特征加CNN分类器也取得了非常好的实验效果。鉴于数据量多少对深度学习的影响很大,因此亦可在本文实验基础上借鉴该思路做尝试,可作为未来的一个研究方向。
6 致谢
本项目由国家自然科学基金NSFC 61671156资助。
猜你喜欢
医学食疗与健康(2022年3期)2022-04-23
电子产品世界(2022年4期)2022-04-21
计算机研究与发展(2022年1期)2022-01-19
计算机系统应用(2021年2期)2021-02-23
计算机应用(2020年12期)2020-12-31
计算机测量与控制(2019年4期)2019-05-08
软件(2018年1期)2018-02-05
家教世界·创新阅读(2016年11期)2016-12-27
故事会(2016年15期)2016-08-23
文苑(2015年9期)2015-09-10
