
静态软件缺陷预测研究进展*
2019-10-24 07:45吴方君
计算机与生活 2019年10期
吴方君
1.江西财经大学 信息管理学院,南昌330013
2.江西财经大学 数据与知识工程江西省高校重点实验室,南昌330013
+通讯作者E-mail:wufangjun@jxufe.edu.cn
1 引言
软件缺陷(fault),又称为错误(error)、故障(defect)、失效(failure)、bug、问题(problem)等[1-5],是软件如影随形的特有成分。虽然无法完全杜绝缺陷,但可以对其进行分析与监测,以尽量减少缺陷[1-5]。软件缺陷预测是一种能够有效地挖掘软件中可能还遗留而尚未被发现的潜在缺陷及其分布情况的技术。通常利用数据挖掘、机器学习和统计学习等通过对软件产品属性、过程属性和已经发现的缺陷数据等各种历史数据进行综合挖掘和分析,从而预测软件系统中存在的缺陷模式。在提高软件质量、开发过程的可控性和用户需求的满足程度,降低软件开发成本和开发过程的风险,改进软件开发过程等方面起着非常重要的作用,是近年软件数据挖掘领域的研究热点之一[6-15]。软件缺陷预测从20 世纪70 年代发展至今,一直受到来自软件产业界和学术界两方面的关注。
在产业界,项目经理和软件工程师发现随着软件系统的规模越来越大,系统的复杂程度也越来越高,相应地花费在软件缺陷修正上的费用也越来越昂贵,消耗的时间也越来越多。既然完全消除缺陷是不可能的,那么借助于缺陷预测对其进行预测分析以尽量减少也是不错的选择。产业界的项目经理和软件工程师早已意识到软件缺陷预测在改善系统质量方面起着重要作用,也迫切希望将其作为软件项目开发管理的重要环节,运用到软件工程实践活动中。在学术界,学者们提出了众多软件缺陷预测方法,进行了一系列实证,取得了斐然的成绩[6-33],尤其是基于软件度量的软件缺陷预测成果丰硕。
为了对现有的软件缺陷预测研究进行深入细致的分析对比和总结,在中国知网、Elsevier、Wiley、Springer、ACM、IEEE 等数据库中,以中文关键词“软件缺陷预测”和英文关键词“software defect prediction”进行检索,截止到2019 年4 月17 日,检索结果如表1所示。由于相关文献太多,因此选择了其中一些经典的文献(侧重于国内的研究工作)进行论述。

Table 1 Search results表1 检索结果
本文从静态软件缺陷预测的四个关键要素,即软件度量指标的筛选、测评数据资源库、缺陷预测模型的构建和缺陷预测模型的评价,综述了现有的研究工作;指出了静态软件缺陷预测面临的挑战和新问题,展望了进一步的研究方向。
虽然近年来有同类的工作[10,15,21],但本文的侧重点与它们有所不同。(1)在软件度量指标方面,文献[10,15,21]侧重于从代码复杂度、程序模块间依赖性、软件开发过程、开发人员经验和项目团队组织架构等多个角度总结已有的度量指标;而本文认同度量指标存在冗余的观点,因此更侧重于度量指标的筛选(即特征选择)。(2)在缺陷预测模型构建方面,文献[10]将缺陷预测分成倾向预测、数量/密度预测和严重等级预测,相应的方法有统计方法(如K最近邻、线性回归)、有监督方法(如随机森林、模糊方法、信念网络、支持向量机)、半监督方法(如最大期望法)和无监督方法(如模糊聚类、K均值);文献[15]将缺陷预测分成倾向预测和数量/密度预测,相应的方法有机器学习方法和基于缓存的方法;文献[21]侧重考察跨项目软件缺陷预测,相应的方法有基方法(如朴素贝叶斯、逻辑斯蒂回归)、优化方法(如装袋、提升、遗传算法)和复合方法;本文将缺陷预测分成倾向性预测、数量/密度预测和模块排序,除了总结机器学习方法之外,也总结了复杂网络、多目标优化和深度学习等方法。此外,本文还就缺陷预测模型的评价方面进行了总结,从如何将缺陷预测模型运用到产业界角度出发,重点考虑了缺陷的严重等级。
2 软件缺陷预测的分类
软件缺陷预测的研究与应用,自1971 年Akiyama[1]提出至今,受到了学术界和软件产业界的高度重视,取得了可喜的成就[6-33]。
根据数据来源不同,软件缺陷预测可分为[19-20]:(1)版本内缺陷预测,只使用软件系统的某个特定版本的数据进行缺陷预测;(2)跨版本缺陷预测,使用软件系统的几个不同版本的数据进行缺陷预测;(3)跨项目缺陷预测,使用一个软件系统的数据预测另外一个软件系统的缺陷;(4)混合项目缺陷预测,借助于辅助软件系统的大量数据,再结合目标软件系统的少量数据,预测目标软件系统的缺陷。跨项目缺陷预测和混合项目缺陷预测主要采用迁移技术[19-33],如吴方君[19]将迁移学习方法TrAdaBoost(transfer Ada-Boost)和代价敏感AdaC2 相结合,提出了AdaC2Tr-AdaBoost 方法;Limsettho 等[22]指出数据分布不均衡和源数据集与目标数据集的分布不一致是造成跨项目缺陷预测效率低下的原因;戴翔等[23]在Burak过滤法和SMOTE(synthetic minority over-sampling technique)法的基础上用投票方式来集成七种分类方法的预测结果;Chen 等[24]提出了DTB(double transfer Boosting),使用数据引力法重塑了源数据集的整体分布,使之与目标数据集的分布相匹配,在部分已标记的目标数据的基础上借助迁移增强方法来消除源数据中起消极作用的数据;Xia 等[25]提出了HYDRA(hybrid model reconstruction approach)方法,遗传算法阶段利用遗传算法为多个分类器分配权重,进而生成一个组合遗传分类器,集成学习阶段利用AdaBoost 从多个遗传分类器生成最终的分类器;毛发贵等[26]基于TrAdaBoost 提出了MergeTrAdaBoost和MultiTrAdaBoost 法,用迁移学习和自适应增强技术,寻找源数据集中与目标数据集关联性高的数据;程铭等[27]提出了加权贝叶斯迁移学习法,使用数据引力法将源数据集与目标数据集间的差异转化为训练数据的权重,在此基础上建立分类器;何吉元等[28]提出了半监督集成跨项目软件缺陷预测方法S3EL(search based semi-supervised ensemble learning),该方法依据每个特征的均值将源数据集划分成两部分来构建多个朴素贝叶斯弱分类器,再借助于遗传算法来组合上述弱分类器,进而构建出最终的分类器;李一露等[29]先利用版本级训练数据选择方法rTDS(release-level training data selection)从候选的跨项目训练数据集中选择与目标数据集距离近的源数据集,然后再利用实例级训练数据选择方法iTDS(instance-level training data selection)为目标数据集中的每个目标实例返回k个最近的实例,从而构成多粒度数据选择方法mTDS(multi-granularity training data selection);杨杰等[30]通过多个源项目分别对目标项目进行预测,然后加权得到最终的预测结果,权重同时考虑预测准确度以及源项目与目标项目间的KL散度;Chen 等[32]提出了一种多角度迁移的软件缺陷预测方法MTDP(multiview transfer learning for software defect prediction),首先构建异构迁移模型,然后通过迁移异构实例来生成模拟实例,再通过协同训练来标记模拟实例,进而扩展训练集,最后构建分类器;陈翔等[20]对跨项目软件缺陷预测进行了综述;Herbold 等[31]不仅对跨项目软件缺陷预测进行了综述,而且开发出了跨项目软件缺陷预测实验平台Cross-Pare(https://crosspare.informatik.uni-goettingen.de/)。有关混合项目缺陷预测更详细的总结烦请参考文献[20-21,31]。
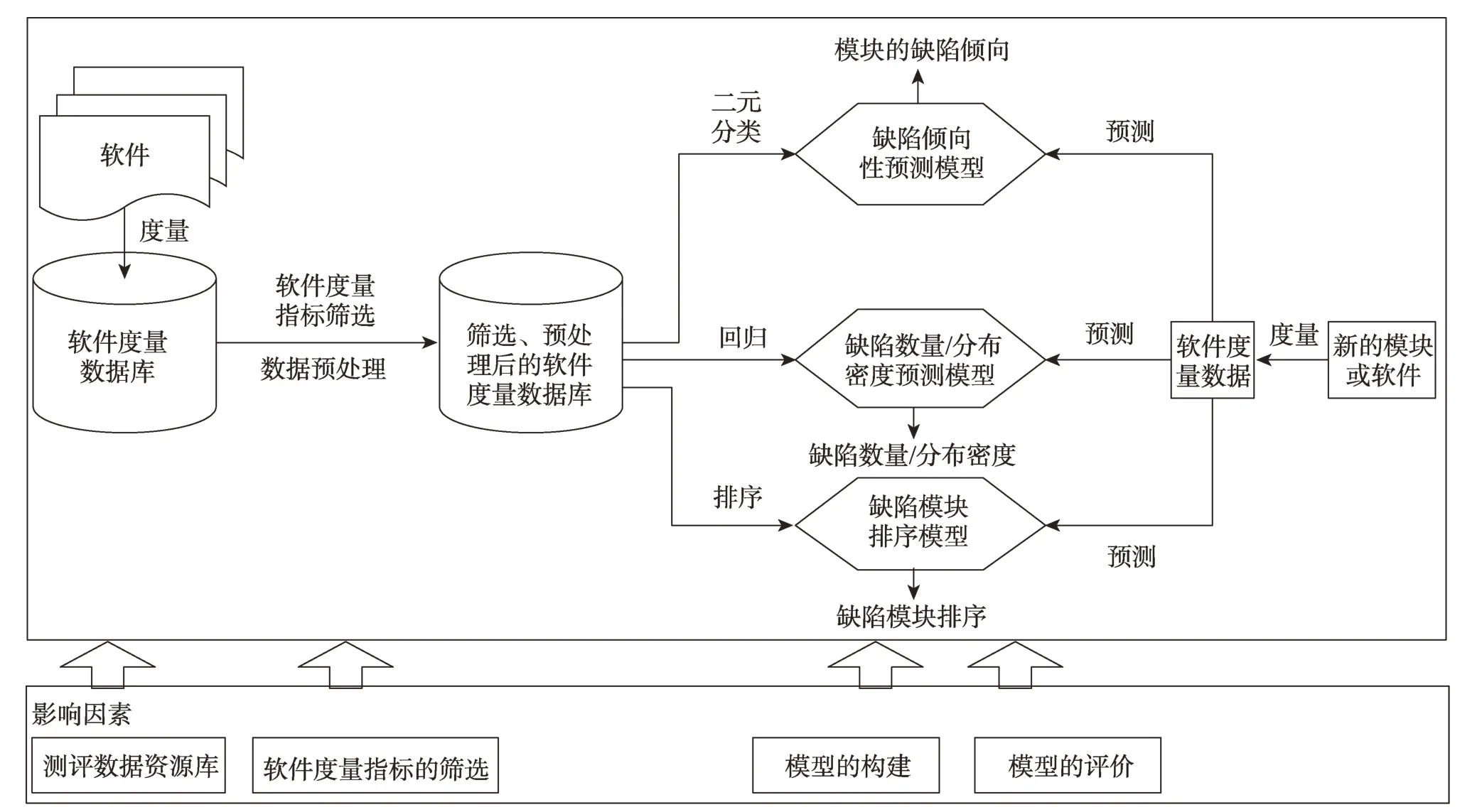
Fig.1 Research framework of static software defect prediction图1 静态软件缺陷预测研究框架
根据是否与软件生命周期有关,缺陷预测可分为静态预测和动态预测,后者预测缺陷分布随软件生命周期的变化情况,如Rayleigh 分布模型、以Littlewood模型为代表的指数分布模型和S曲线分布模型等。
根据预测目标的不同,静态缺陷预测又可细分为:(1)缺陷倾向性预测,即预测模块是否含有缺陷,是一个二元分类问题;(2)缺陷的数量/分布密度预测,即预测模块中含有的缺陷数量/密度,是一个回归分析问题;(3)缺陷模块排序预测,即先预测模块中含有的缺陷数量或缺陷倾向性概率,然后降序排列,将排名前K(Top-K)的模块推荐给开发人员进行审查/测试,是一个排序问题。后者介于前两者之间,适用于测试资源未知的情况。如果人力和物力资源有限,则只审查/测试Top-K模块;如果人力和物力资源充足,则可以审查/测试全部模块。研究框架如图1所示。
根据预测粒度不同,软件缺陷预测可分为[34]:(1)模块级预测,即预测模块含有的缺陷;(2)文件级预测,即预测文件含有的缺陷;(3)变更级缺陷预测,也称即时缺陷预测,当开发者每次提交变更代码时,预测其是否存在缺陷,由Kamei等[35]首次提出此概念。
目前,基于软件度量的静态软件缺陷预测是比较成熟和流行的技术,包含四个关键要素[15,19]:软件度量指标的筛选、测评数据资源库、缺陷预测模型的构建和缺陷预测模型的评价。因此,本文第3~6章将分别综述上述四方面的现有工作。
3 软件度量指标的筛选
3.1 软件度量指标筛选的研究现状
软件度量指标主要包括刻画软件产品属性的指标和刻画软件开发过程的指标[15,36]。前者包括代码行数(line of code,LOC)、McCabe 着色图法、软件科学法、功能点法、Chidamber 与Kemerer 提出的度量集(简称CK 度量集)、Abreu 提出的度量集(metrics for object-oriented design,MOOD)和Bansiya等提出的度量集(quality model for object-oriented design,QMOOD)等经典的基于代码的度量指标[36]。后者包括有关代码修改特征的度量、有关模块间依赖性的度量、有关开发时间/开发人员/开发方法的度量,以及有关项目团队组织架构的度量等。
面对如此众多的度量指标,如何进行筛选是构建高质量软件缺陷预测模型的第一个关键。如果不加筛选地采用全部度量指标,会造成三方面的问题。(1)收集全部度量指标需要花费大量的人力和物力,代价太大,有时也是做不到的;(2)部分度量指标间存在冗余,会增加构建缺陷预测模型的时间;(3)部分度量指标与缺陷不相关,会降低缺陷预测模型的性能。
目前,研究者已经对度量指标存在冗余达成统一共识。例如Emam 等[37]在一个电信软件系统上发现6 个OO(object-oriented)度量与LOC 都是高度相关的,分别是WMC(weighted methods per class)、CBO(coupling between object classes)、RFC(response for classes)、LCOM(lack of cohesion of methods)、NPAVG(average number of parameters per method)和NMA(number of methods added)。Zhou等[38]分析了6个Java 开源系统(Eclipse 2.0、Equinox 3.4、JDT core 3.4、Lucene 2.4.0、Mylyn 3.1 和PDE UI 3.4.1),发现LOC、NMIMP(number of methods implemented in a class)、NumPara(number of parameters in the methods implemented in a class)、NM(number of methods)、NAIMP(number of attributes implemented in a class)、NA(number of attributes)和Stmts(number of statements)等类规模与大部分OO度量存在强相关。
因为度量指标间存在冗余[39-43],Gao 等[40]指出移除85%的度量指标可能会提高预测效果,Shivaji等[41]发现在大部分情况下最多只需要使用10%的度量指标,因此对其进行筛选是非常必要的。Xu 等[42]将度量指标筛选方法细分为5种。(1)过滤式排序法,例如Khoshgoftaar 等[43]比较了包括信息增益法IG(information gain)、卡方法CS(Chi-squared)和信噪比SNR(signal to noise ratio)在内的7种度量指标选择方法,结果表明IG和SNR更有效。(2)过滤式子集选择法,例如,杨晓杏[44]提出了一种改进的最小冗余、最大相关度量元分析方法来筛选度量指标,并发现度量指标和个数的选择很大程度上依赖于数据集。(3)包裹式子集选择法[45-49],例如,Liu 等[45]提出了3 种代价敏感的度量指标选择方法,即CSVS(cost-sensitive variance score)、CSLS(cost-sensitive Laplacian score)和CSCS(cost-sensitive constraint score)。Laradji等[46]提出了一种集成方法选择度量指标。陈翔等[48]提出了一种基于多目标优化算法NSGA-II(non-dominated sorting genetic algorithm-II)的软件缺陷预测指标选择方法MOFES(multi-objective optimization feature selection),分别将最小化指标子集规模和最大化AUC(area under the ROC curve)作为两个优化目标,在Promise 和ReLink 数据集上的实验结果表明MOFES方法在大部分情况下可以筛选出更小规模的指标子集,并获得更好的缺陷预测性能。Turabieh等[49]提出了一种分层循环神经网络(recurrent neural network)方法选择度量指标,随机迭代选择二元遗传算法(binary genetic algorithm)、二元粒子群优化(particle swarm optimization)和二元蚁群优化(ant colony optimization)对度量指标进行提取,在19 个Promise 数据集上进行了实验。(4)基于聚类的方法,例如,刘望舒等[50]提出了一种基于聚类分析的度量指标选择方法FECAR(feature clustering and feature ranking),首先将具有冗余关系的度量指标聚于簇中,然后对每一个簇中的度量指标按照它们与缺陷的相关性降序排列,最后从每一个簇中选取指定数量的度量指标。在Eclipse和NASA数据集上的实验结果表明集成少数度量指标的缺陷预测模型的性能优于集成所有度量指标的。Xu等[51]也提出了一种基于聚类分析的特征选择方法MICHAC(maximal information coefficient with hierarchical agglomerative clustering),该方法采用最大信息系数对候选指标进行排名,进而过滤掉不相关的特征;然后采用层次凝聚法对指标进行聚类,只保留每组中的一个指标,去除冗余指标。(5)基于抽取的方法,例如,朱朝阳等[52]提出了基于主成分分析的软件度量指标选择方法。
上述度量指标筛选方法虽然考虑了度量指标间的相关性,考虑了度量指标与软件缺陷间的相关性,也考虑了类规模与软件缺陷间的相关性,但却忽略了类规模对度量指标与软件缺陷间关联的混和效应,即度量指标与软件缺陷之间的相关是真相关,还是由于类规模的原因引起的伪相关。
在类规模的混和效应分析方面,Emam等[37]在一个电信软件系统上对WMC、DIT(depth of inheritance tree)、CBO、RFC、LCOM、NPAVG 和NMA 等7 个OO度量进行了LOC 的混和效应分析,研究结果表明:LOC对WMC、CBO、RFC和NMA的软件缺陷预测能力具有强的混和效应。Zhou 等[38]在6 个Java 开源软件系统上对55 个OO 度量进行了7 个类规模(LOC、NMIMP、NumPara、NM、NAIMP、NA和Stmts)的混和效应分析。研究结果表明:类规模对OO度量的混和效应广泛存在,并且大多数过高地评估了OO度量的软件缺陷预测能力,并提出了一种基于线性回归的混和效应剔除方法。
此外,卢红敏等[53]在102 个Java 开源软件系统上检查7 个类规模(LOC、NMIMP、NumPara、NM、NAIMP、NA和Stmts)对55个OO度量的易变性预测是否存在混和效应。随机效应元分析结果表明:类规模对大多数的OO度量具有混和效应,甚至在许多情况下会导致虚假相关。
吴方君[54]在Eclipse的两个版本2.0和2.1上检测了3个类规模(LOC、NMIMP和NumPara)对55个OO度量的易变性预测是否存在混和效应。实验结果表明:在软件易变性预测中类规模对大部分OO度量存在混和效应,个别不存在混和效应。
3.2 软件度量指标筛选面临的问题
虽然类规模的混和效应分析工作为软件度量指标筛选开启了一个新窗口,但是纵观先前的工作发现:或者只分析了少量的软件系统,最多也只分析了6 个软件系统;或者只分析了开源系统,得出的结论能不能推广到其他更多的系统中尚存疑问。为此,非常有必要在大量学术界、开源界和产业界软件系统的基础上甄别OO 度量与软件缺陷间相关性的真伪,帮助人们正确认识OO度量和软件缺陷之间的关系,是否有必要将类规模作为混和变量考虑进来。
4 测评数据资源库
4.1 测评数据资源库的研究现状
目前测评数据资源库可划分为三大类:(1)公共专业数据资源库,如NASA(https://github.com/klainfo/NASADefectDataset)、Promise(http://promise.site.uottawa.ca/SERepository/datasets-page.html)、Softlab(https://github.com/klainfo/DefectData)和NETGENE(https://hg.st.cs.uni-saarland.de/projects/cg_data_sets/repository)。(2)公共非专业数据资源库,如Harvard 数据资源库(https://dataverse.harvard.edu/)。(3)个人专业数据资源库,有部分学者在版本控制系统,如CVS(concurrent versions system)、Git(Georgia Institute of Technology)、SVN(subversion),以及缺陷追踪系统,如Bugzilla(bug-tracking system)、JIRA、Mantis、Trac,和开发人员的相关往来邮件等的基础上自行组建个人专业数据资源库,如Zimmermann数据集(https://www.st.cs.uni-saarland.de/softevo/bug-data/eclipse/)、AEEEM数据集(http://bug.inf.usi.ch/)和ReLink 数据集[55]。Jing 等[56]和陈翔等[20]分别从数据来源、度量指标等方面对比分析了部分测评数据集。
此外,由于在软件系统中缺陷服从帕累托(Pareto)原则[3],即20%的模块包含了80%的缺陷,真正含有缺陷的模块是少数,因此会出现类不平衡问题。国内外学者针对不平衡分类问题相继提出了各种解决方案,大体上可以分为:数据预处理层面的重采样方法和划分方法,特征层面的特征选择方法,分类算法层面的分类器集成、代价敏感方法和单类学习方法。有关不平衡数据分类更详细的总结烦请参考文献[57-59]。
4.2 测评数据资源库面临的问题
目前测评数据资源库主要存在三方面的问题。(1)测评数据资源库较少,在此基础上得出的实验结论具有一定的偏颇性,是否具有通用性,值得进一步检验。(2)部分测评数据集是从开源项目收集的,而开源软件的开发方式与产业界商业软件的开发方式存在着比较大的差异,前者一般由多人分布式开发,后者由多人集中式开发。在开源软件数据上构建的缺陷预测模型在产业界的实用性比较差,甚至不如随机猜想,是否与测评数据有关,值得进一步验证。(3)大部分数据资源库描述了模块的缺陷倾向性,或者缺陷的数量,只有少数刻画了缺陷的严重等级,无法满足软件产业界的需求。有了缺陷的严重等级数据,项目经理就可以将有限的人力和物力资源合理、高效地分配在真正需要审查/测试的软件模块上。
5 缺陷预测模型的构建
5.1 缺陷预测模型构建的研究现状
缺陷预测模型的构建方法随着预测目标的不同而各异。
5.1.1 缺陷倾向性预测模型的构建
当预测目标是缺陷倾向性时,经常采用分类法。最初是经验预测阶段,研究人员在软件规模和软件复杂度的基础上凭经验预测软件缺陷;后来逐渐进入到智能预测阶段,Malhotra[14]指出机器学习方法是使用频率最高的。典型的缺陷预测模型构建方法如逻辑斯蒂回归分析(logistic regression,LR)、朴素贝叶斯(naïve Bayes,NB)、决策树(decision tree,DT)、人工神经网络(artificial neural network,ANN)、随机森林(random forest,RF)、泊松回归(Poisson regression,PR)、负二项回归(negative binomial regression,NBR)和支持向量机(support vector machine,SVM)等。
Hall 等[12]总结了2000—2010 年发表的208 篇文献,指出LR和NB是最优的;陈翔等[20]统计了2016年7月以前发表的56篇文献,指出LR、NB、DT、SVM和RF 使用频率最高,同时指出分类方法中参数取值的不同会影响预测性能;Tantithamthavorn 等[60]也分析了分类方法中不同的参数取值对预测性能的影响,建议把这种影响纳入考虑范围。
Jiang等[61]提出了一种半监督的软件缺陷预测方法ROCUS(random committee with under-sampling),该方法利用半监督学习来解决标记样本数量少的问题,利用欠抽样方法解决数据不均衡问题,并在8 个NASA数据集上进行了实证。
王铁建等[62]提出了一种基于核字典学习的软件缺陷预测方法,该方法利用核方法将数据映射到一个高维空间,之后采用核字典基选择策略学习得到核字典,最后预测模块的缺陷倾向性,并在NASA 数据集上进行了实证。
杨杰等[63]提出了基于Boosting 的代价敏感软件缺陷预测方法,该方法用随机属性子集选择法降低Boosting重抽样过程中的维度灾难,为漏报和误报增加不同的代价敏感因子,并在NASA数据集上进行了实证。
傅艺绮等[64]提出了基于组合机器学习的软件缺陷预测,该方法将LR、DT、NB和ANN等几种算法的预测结果作为新的度量指标加入数据集,之后运用Stacking集成学习方法再次预测缺陷,在Eclipse数据集的实证验证了其有效性。
虽然软件缺陷预测方法大多是基于机器学习的,但是也有研究人员从复杂网络[65-67]、多目标优化[68-75]和深度学习[76-80]等方面入手。
(1)基于复杂网络的软件缺陷预测方法比较少。例如,Wu[65]通过UML(unified modeling language)类图将软件系统映射为有向复杂网络,之后研究了软件网络复杂性度量与典型的OO度量之间的关系,指出虽然两者不显著相关,但是前者从不同侧面对OO度量起到一个较好的补充;虽然软件网络复杂性度量对软件缺陷预测方面有提高作用,但提高的程度不显著。刘庆山[66]通过函数间的调用关系将软件系统映射为有向复杂网络,之后采用网络度量指标数据对缺陷进行预测,并指出网络度量是有效的。Ma等[67]在软件网络度量指标的基础上进行缺陷预测,并指出网络度量在不同的系统上表现差异比较大,并在6 个Firefox 版本、5 个Eclipse 版本、9 个开源系统(JEdit、Ant、Camel、Ivy、Poi、Lucene、Xalan、Xerces 和Tomcat)的28个版本上进行了实证。
(2)基于多目标优化的软件缺陷预测方法也较少。Khoshgoftaar 等[68]提出了一种以误分代价最小化、决策树复杂度最小化和可用资源最优为目标的缺陷预测方法;Carvalho等[69]提出了一种以高缺陷检测率和低误报率为目标的粒子群优化方法MOPSO(multi-objective particle swarm optimization);杨晓杏[44]提出了一种结合代码敏感SVM和多目标优化策略的非支配排序遗传算法NSGA-II-based SVM 来对缺陷模块序列进行排序,其中高缺陷检测率和低资源浪费率是两个优化目标,并在17个Promise数据集上验证了其高效性;Canfora 等[70]提出了一种以高缺陷检测率和LOC 最小化为目标的缺陷预测方法MODEP(multi-objective defect predictor);Shukla 等[71]提出了一种以误分代价最小化/召回率最大化为目标,或者可用资源最优/召回率最大化为目标的缺陷预测方法;Ryu 等[72]提出了一种以高缺陷检测率、低误报率和高整体性能为多目标的朴素贝叶斯缺陷预测方法;Chen 等[73]在NSGA-II 的基础上提出了一种以高缺陷检测率和低资源使用率为多目标的缺陷预测方法。
(3)基于深度学习的软件缺陷预测方法也比较少。例如,甘露等[78]通过叠加多层限制玻尔兹曼机(restricted Boltzmann machine,RBM)对度量指标进行集成,在此基础上进行深度学习,之后提出了基于深度信念网(deep belief networks,DBN)的软件缺陷预测模型DBNSDPM(deep belief network software defect prediction model),并在5个NASA 数据集上进行了实证,实验结果表明缺陷预测准确性有显著提高。针对特征冗余和高维性,周末等[79]提出了一种基于深度自编码网络的软件缺陷预测方法,并在6 个NASA、Promise 和NETGENE 数据集上进行了实证。针对特征冗余和数据不均衡性,徐海涛等[80]提出了一种结合稀疏自编码神经网络(sparse autoencoder neural networks)和过采样技术SMOTE 的软件缺陷预测方法,并在NASA数据集上进行了实证。
针对分类任务的缺陷预测时,有少数研究者考虑缺陷严重等级。Zhou等[81]将缺陷严重等级划分为高低。Singh等[82]将其划分为高中低。Tian等[83]将其划分为Trival、Minor、Major、Ctritical 和Blocker。Zhang等[13]将 其 划 分 为Trivial、Minor、Normal、Critical 和Blocker。Chen等[84]通过模块间的依赖关系将软件系统映射为有向复杂网络,之后在软件网络度量指标的基础上进行高危缺陷预测,其中高危缺陷是指严重等级是Major、Critical 或Blocker,指出基于网络度量指标的高危缺陷预测性能可以与基于代码度量指标的高危缺陷预测性能相媲美,并在Firefox、Eclipse、Ant 和Hbase 上进行了实证。喻维[85]采用主动学习和半监督学习相结合的方法预测缺陷的严重程度。
5.1.2 缺陷数量/分布密度预测模型的构建
当预测目标是缺陷的数量或分布密度时,通常采用多元线性回归分析MLR(multiple linear regression)[1,6,86-89],例如Akiyama[1]提出了Akiyama 模型,用于刻画LOC与缺陷数量之间的关系;Gao等[6]比较了以NBR 和PR 为代表的8 种广义线性回归模型的性能。此外,也有研究人员从其他方面入手解决上述问题。例如,Livshits 等[86]开发了一个缺陷检测工具DynaMine,利用关联规则挖掘那些因为未配对使用某些程序构造(如方法调用等)而造成的缺陷,并在Eclipse 和JEdit 上进行了验证;Nguyen 等[87]基于模块间的相似性来预测缺陷的数量,K个近邻模块所含的缺陷数量的均值就是模块所含缺陷数量的预测值;简艺恒等[88]依据缺陷模块和无缺陷模块的比例,借助SMOTE多次过采样得到多个数据集,之后利用回归分析得到多个软件缺陷数量预测模型,将上述多个模型的预测值的均值作为最终的预测值。
5.1.3 缺陷模块排序模型的构建
当预测目标是缺陷模块排序时,一般采用分类法和回归分析技术,例如采用最小二乘法或最大似然法预测的多元线性回归、RF、以NBR 为代表的广义线性回归和SVM等,也有研究人员从聚类、排序学习(learning to rank,LTR)方面入手解决该问题。
杨明[90]提出了一种基于聚类的缺陷模块排序预测方法LSDB(largest-cluster started distance based),该方法在代码级度量数据的基础上,首先利用Kmeans 或者X-means 等算法对模块进行聚类,然后进行簇间排序,最后进行簇内模块排序。进行簇间排序时,作者将包含模块最多的簇排在第一位,计算剩余簇的中心点到第一个簇的中心点的欧式距离,按照距离升序排列。进行簇内模块排序时,计算模块与该簇中心点的欧式距离,按照距离升序排列。LSDB 方法预测出来的缺陷模块序列是按照缺陷概率升序排列的。
随后赵东晓[91]也提出了四种基于聚类的缺陷模块排序预测方法,基本框架与杨明方法[90]一样,不同之处在于簇间排序和簇内模块排序方法,不仅根据软件缺陷服从Pareto 原则[3],而且还参考软件模块包含缺陷的概率与其规模成反比[4]来设定排序方法。第一种方法MSSB(minimum-size-cluster started size based)进行簇间排序和簇内模块排序时均按照LOC升序排序。第二种方法SSDB(smallest-cluster started distance based)进行簇间排序时,将包含模块最少的簇排在第一位,剩余簇的中心点到第一个簇的中心点的欧式距离升序排列;对于簇内模块排序时,按照模块与该簇中心点的欧式距离升序排列。第三种方法SSSB(smallest-cluster started size based)进行簇间排序时,按照簇包含的模块数量升序排列;对于簇内模块排序时,按照模块的LOC 升序排列。第四种方法SSDSB(smallest-cluster started distance and size based)进行簇间排序时,将包含模块最少的簇排在第一位,按照剩余簇的中心点到第一个簇的中心点的欧式距离升序排列;对于簇内模块排序时,按照模块的LOC升序排列。四种方法预测出来的缺陷模块序列均是按照缺陷概率降序排列的。
田青青[92]提出了一种多次迭代的、基于反馈的图像检索框架的半监督协同缺陷模块序列排序方法SSADP:首先将未标记缺陷倾向性的模块按照LOC升序排列;然后选择排在前面的2%模块手工标记上缺陷倾向性类标签,作为初始的训练数据集;最后训练分类器,并预测剩余模块的缺陷倾向性,根据预测值降序排列软件模块,返回给用户。
近年来,越来越多的研究者借助于多目标优化和机器学习中的排序学习[93]来解决缺陷模块排序预测问题。杨晓杏等[44,94]在线性模型的基础上提出了一种软件缺陷模块排序预测方法,该方法以FPA(faultpercentile-average)为优化目标,利用组合差分进化(composite differential evolution,CoDE)算法[95]来获得参数,并在6 个Zimmermann 数据集和5 个开源系统(Eclipse JDT core、Eclipse PDE UI、Equinox framework、Mylyn 和Apache Lucene)的数据集上验证了其有效性。随后,Priya 等[96]引入玻尔兹曼机来增强排序学习的能力。Nguyen 等[87]将经典的排序学习算法RankSVM 和RankBoost 应用于缺陷模块排序预测中,并在5 个开源系统(Eclipse JDT Core 3.4、Eclipse PDE UI 3.4.1、Mylyn 3.1、Equinox framework 3.4 和Apache Lucene 2.4.0)的数据集上验证了其有效性。You 等[97]在多元线性回归分析的基础上提出了一种软件缺陷模块排序预测方法ROCPDP(rankingoriented approach to cross-project defect prediction),利用梯度下降法来获得参数,并在5 个AEEEM 数据集和34个Promise数据集上验证了其有效性。
5.2 缺陷预测模型构建面临的问题
学者们从不同角度、采用不同方法和技术,针对不同的软件缺陷预测问题展开了深入、细致的研究和应用,取得了丰硕的成果,为后续研究和应用奠定了扎实的基础。虽然在缺陷管理领域考虑严重程度和优先级的工作开展得比较多[98-99],但是在缺陷预测领域考察缺陷严重程度研究相对少[9,81-85],两者的区别在于前者已经通过代码审查/测试等途径知道了缺陷的存在,只不过严重程度的标识可能由于提交者初步确定时存在一些错误,需要进行修正;而后者是不知道哪些模块存在缺陷,需要通过预测为项目经理和软件工程师合理分配物力、人力资源在真正需要审查/测试的模块上提供指导和帮助。针对分类任务的缺陷预测,只有少数学者考虑了缺陷严重等级[9,81-85];针对排序任务的缺陷预测,只有You等[97]将缺陷严重等级纳入考虑。软件产业界中的真实情况是软件不仅包含缺陷,而且缺陷还有等级之分。如缺陷追踪系统Bugzilla 和Eclipse 工程师不仅将缺陷划分成Blocker(系统崩溃)、Critical(部分主要功能缺失,影响系统使用)、Major(部分功能缺失,不影响系统使用)、Normal(部分功能存在缺陷)、Minor(系统功能齐全,但存在瑕疵)、Trivial(小问题)、Enhancement(需要完善)等7个等级,而且还设置了优先级Priority指标,从最高优先级P1到最低优先级P5。
根据软件缺陷服从Pareto[3],而且模块包含缺陷的概率与其规模成反比[4]的原则,在此举了一个比较符合软件产业界真实情况的例子。如表2 所示,3 个模块包含了不同严重程度、数量不等的缺陷。表3给出了3个模块在不同情况下的排列顺序。
表3 中,当进行缺陷模块排序预测时,在考虑代码审查/测试工作量的情况下,3 个模块的审查/测试顺序是C、A、B。简而言之,按照C、A、B 的顺序对3个模块进行代码审查/测试最符合软件产业界的真实情况。因为致命的缺陷会导致系统崩溃,严重的缺陷使系统主要功能丧失,这两种类型的缺陷是一定要修改的,不管缺陷所在模块的规模大小;一般缺陷使系统部分功能无效,这种类型的缺陷也是需要修改的,但是需要考虑缺陷所在模块的规模大小;提示只是警告,这种类型的缺陷可以在人力和物力资源充足的条件下修改。从成本收益的角度来讲,模块C、A、B的排序是最好的。
6 缺陷预测模型的评价
6.1 缺陷预测模型评价的研究现状
目前,模型评价标准可划分为针对分类预测能力的评价标准和基于代码审查/软件测试工作量感知的评价标准。评价分类预测能力的标准比较多,如准确率(accuracy)、查准率(precision)、召回率(recall)、F值、G-Mean(geometric mean of precision and recall)、AUC 和MCC(Matthews correlation coefficient),它们的值越大越好;I型错误率和II型错误率,它们的值越小越好。上述指标的使用需要满足一个前提条件,即项目经理和软件工程师有充足的人力和物力资源可以审查/测试所有的代码模块,但是在软件产业界却是不现实的,为此研究者们提出了基于代码审查/软件测试工作量感知的评价标准,如基于代码行的Alberg 图(也称为累积提升图(cumulative lift chart,CLC))[8]、平均缺陷百分比FPA[11]和成本收益曲线下面积(area under the cost-effectiveness curve,AUCEC)[100]及PofB20指标[101],它们的值越大越好。特别地,CLC和FPA线性相关[44,94],且FPA更简单、更易理解。
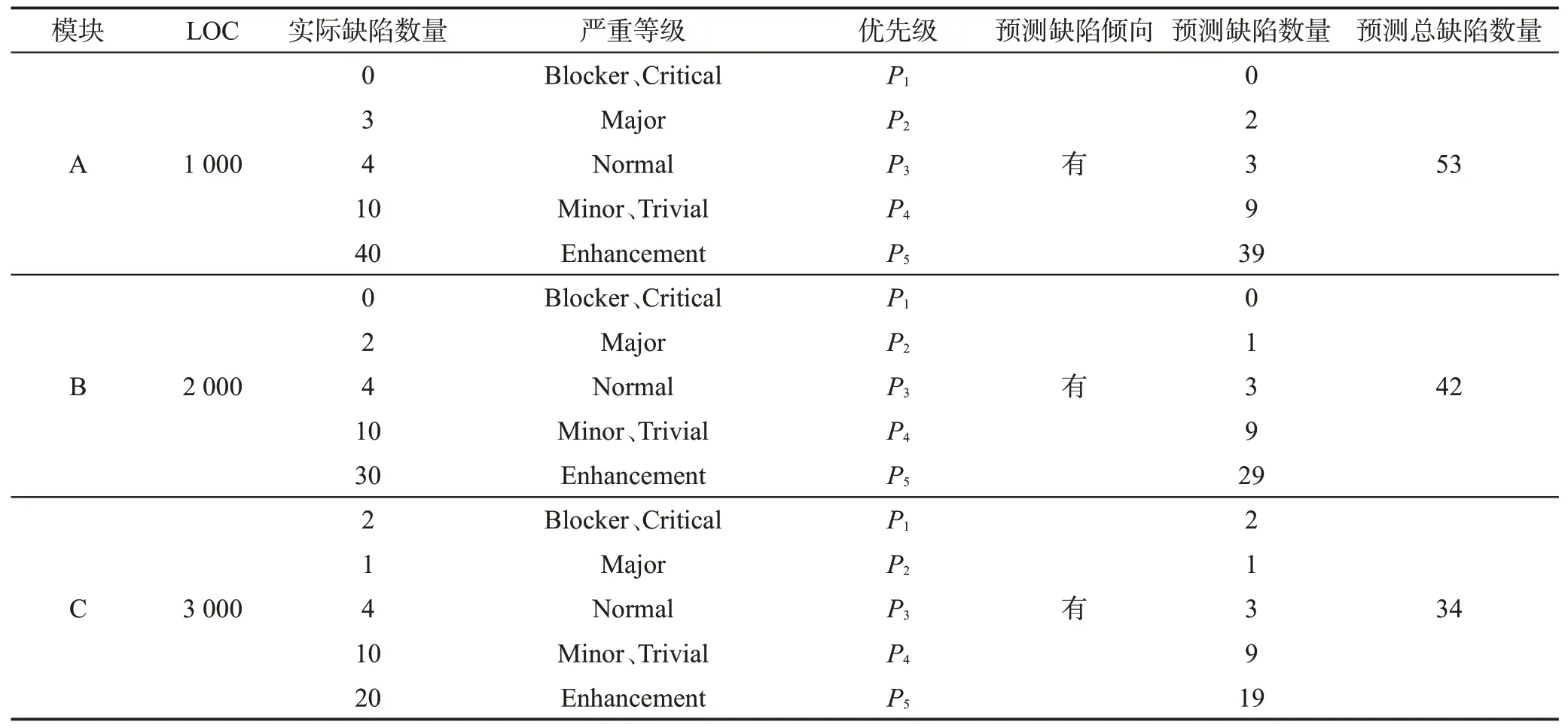
Table 2 Example表2 示例

Table 3 Sequence表3 排列顺序
6.2 缺陷预测模型评价面临的问题
虽然基于代码审查/软件测试工作量感知的评价标准更符合软件产业界的现实状况,但是它们只评价了缺陷倾向性,而没有评价缺陷的严重等级。
7 研究展望
在国内外众多学者和软件开发人员的努力之下,基于软件度量的静态缺陷预测取得了斐然的成绩,但仍存在一些问题有待于进一步地研究和探讨,特别是:
(1)针对排序任务的软件缺陷预测进行度量指标筛选的工作欠缺。在软件度量指标筛选方面,研究者已经对度量指标存在冗余达成统一共识,因此有必要对其进行筛选。虽然已经存在若干度量指标筛选方法,但大部分是针对分类任务的软件缺陷预测开展了度量指标的筛选,针对排序任务的度量指标筛选比较少。度量指标在不同任务的软件缺陷预测时性能可能有所差异,可能会存在某些度量指标在分类任务时性能良好,但是排序任务时性能差的情况,因此有必要针对排序任务的软件缺陷预测进行度量指标的筛选,深度学习中的自编码网络可能是个不错的选择。
(2)未将缺陷严重等级纳入全面考虑。①已有的大部分测评数据资源库记载了模块的缺陷倾向性,或者缺陷的数量,只有少数记载了缺陷的严重等级,无法满足软件产业界的需求。②大部分软件缺陷预测只考虑了有无缺陷,较少考虑缺陷严重等级,这不符合产业界追求成本收益的目标。③虽然有若干软件缺陷预测模型的评价标准,但它们只评价了缺陷倾向性,而没有评价缺陷的严重等级,不符合软件产业界的现实状况。
(3)随着云计算技术的发展,互联网软件开发出现了一些新的范式,如微服务架构软件[102]、无服务架构软件等。微服务架构是Amazon、eBay和Netflix等公司建立的一种软件体系设计模式,将复杂系统拆分成多个独立的小系统,具有敏捷开发、持续交付、持续集成等特点;无服务架构是微服务架构的一种表现形式,将代码放到谷歌Cloud Functions、微软Azure Functions、亚马逊AWS Lambda 等平台上,由平台来处理与服务器相关的具体细节问题,具有运行维护简单、开发效率高等特点。这些互联网软件开发的新模式随之带来了一些新问题和新挑战,例如一个复杂系统可能由多个采用不同的程序设计语言来编码的独立小系统组成,它们的基于代码的度量数据存在较大差异;由于代码存放在平台上,因此通过日志来定位缺陷就比较困难。诸此种种导致传统的软件缺陷预测的技术和经验不适用,即时缺陷预测可能是个不错的处理办法。
(4)近年来,如何解决缺陷预测在产业界实际软件开发中所面临的各种问题,提升软件缺陷预测的实用性和经济性,为管理人员分配有限的人力和物力资源提供指导,以便在付出最小代价的前提条件下,审查/测试出尽可能严重、尽可能多的软件缺陷,进一步把软件缺陷预测从学术界推向产业界,这是目前亟待解决的问题。
虽然产业界的项目经理和软件工程师已经意识到软件缺陷预测在改善系统质量方面起着重要作用,迫切希望将其运用到软件工程实践活动中,也已有研究人员在微软[16]、谷歌[17]和思科[18]等软件产业界的知名公司进行了软件缺陷预测的实践,但是却发现它们实用性比较差,甚至不如随机猜想,与学术界开展的如火如荼的软件缺陷预测理论研究形成了鲜明对比。原因在于:①在产业界,软件开发成本是有限的,不能把所有的人力和物力资源全部投入到代码审查/软件测试中。②在整个软件生命期中,发现和修正缺陷占用了50%~75%的费用[2],如何把发现和修正缺陷的费用尽量降低,这是产业界所关心的。③真正含有缺陷的模块是少数,软件缺陷服从帕累托(Pareto)原则[3],即20%的模块包含了80%的缺陷。④项目经理和软件工程师不仅关心系统中是否含有缺陷和缺陷的数量,更关心缺陷的严重程度。事实上,缺陷严重程度不仅有等级之分,它们造成的后果也是不同的:致命的缺陷会导致系统崩溃,严重的缺陷使系统主要功能丧失,一般缺陷使系统部分功能无效。缺陷严重等级影响了代码审查/软件测试工作,致命(blocker)缺陷和严重(critical)缺陷是一定要修改的,一般(normal)缺陷是需要考虑缺陷所在模块的规模大小来加以修改的,提示(enhancement)类型的缺陷可以在人力和物力资源充足的条件下修改。⑤学术界构建的软件缺陷预测模型大部分是基于开源项目数据,而开源软件的开发方式与产业界商业软件的开发方式存在着比较大的差异,前者一般由多人分布式开发,后者由多人集中式开发,在前者上构建的缺陷预测模型在后者的实用性比较差,甚至不如随机猜想。已有的软件缺陷预测方法和技术侧重于缺陷的预测能力,未将产业界的实际情况加以深入考察。因此如何将有限的人力和物力资源合理、高效地分配在真正需要审查/测试的软件模块上是非常值得研究和非常经济实用的,缺陷排序预测可能是个有效的措施。
(5)软件缺陷预测研究工作的再现性和可复制性至关重要,只有可再现性和可复制的工作才有可能运用到软件工程实践活动中去;然而,现有研究工作的再现性和可复制性却比较差。Mahmood等[103]选取208 项高引用的软件缺陷预测研究工作进行再现性和可复制性实验,发现只有13 项(6%)是可复制的,而且有1项的结果与原始结果不一致。下一步的研究工作需要注重可再现性和可复制性。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
名家名作(2021年4期)2021-05-12
科普童话·学霸日记(2020年1期)2020-05-08
中国科技财富(2019年12期)2019-12-27
江西教育B(2019年2期)2019-04-12
小天使·一年级语数英综合(2019年2期)2019-01-10
中国诗歌(2018年6期)2018-11-14
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
通信产业报(2016年47期)2017-04-17
