
使用动态增减枝算法优化网络结构的DBN模型*
2019-10-24 07:45张士昱王晨妮郑珊珊
计算机与生活 2019年10期
张士昱,宋 威,王晨妮,郑珊珊
江南大学 物联网工程学院,江苏 无锡214122
+通讯作者E-mail:songwei@jiangnan.edu.cn
1 引言
在人工智能领域,深度学习目前受到了广泛关注[1],特别是深度学习的分类能力对工业界产生了巨大的影响[2]。因为这种学习体系具有多层网络结构的优点,可以避免所谓的维数灾难或降低其危害;而且可以有效提取原始数据的主要特征,这些数据比原始数据更具鉴别性,方便对数据做进一步的应用研究。限制玻尔兹曼机(restricted Boltzmann machine,RBM)[3]是一种无监督学习方法,能够很好地表示输入数据集的概率分布。深度信念网络(deep belief network,DBN)[4]由多个顺序堆叠的RBM组成。
目前DBN 仍有许多问题值得研究。例如,当DBN 要解决高复杂度的问题时,如果隐藏层和隐藏层神经元不足,则会导致训练失败[5]。这是因为DBN缺少隐藏层和隐藏层神经元来拟合数据,并且无法有效提取数据的主要特征。而如果隐藏层和隐藏层神经元过多,则会大幅增加DBN的训练时间,并且可能会导致网络过拟合。因此,针对不同的问题,DBN需要选择合适的网络结构来准确地提取数据的主要特征。但是,DBN 的网络结构目前是通过人工实验选择的,并且在训练过程中总是固定的[6]。Shen 等[7]通过反复实验法确定DBN 的网络结构,但通过这种方法确定结构是耗时且不合理的,会导致DBN 运行时间长,准确度差。因此,如何使DBN可以根据不同的问题以及自身的训练情况,自动调整为最合适的网络结构,对DBN 在人工智能领域的应用研究具有重要的意义。
近年来已经研究出许多动态结构调整算法来解决神经网络的结构确定问题[8-9]。例如,文献[10]提出了一种模糊神经网络(fuzzy neural network,FNN)的分层在线动态结构用于解决函数逼近问题。文献[11]提出了一种具有动态结构的径向基(radial basis function,RBF)网络用于解决非线性动力系统辨别问题。文献[12]提出了一种用于二值图像去噪任务的量子多层动态神经网络(dynamic neural network,DNN)。这些动态结构调整算法有效提高了神经网络的学习效果。受此启发,DBN 的结构设计问题已经成为学术界关注的焦点[13-14]。文献[2,15]提出了一种自适应DBN(adaptive deep belief network,ADBN)学习方法,该方法使用隐藏神经元权重和偏置的变化量作为调整网络结构的条件。但ADBN 算法相对单一,缺乏对结构调整的全局把握,不具备一定的鲁棒性。文献[6]提出了一种自组织DBN(self-organizing deep belief network,SODBN)模型,利用隐藏神经元的尖峰强度值(spiking intensities,SI)和训练阶段的均方根误差来调整网络结构。SODBN 可以获得良好的网络结构和准确性,但由于其复杂的算法,SODBN的训练时间也更长。本文提出了一种使用动态增减枝算法的动态DBN模型(dynamic deep belief network,DDBN),可以有效地优化DBN的网络结构。DDBN新的特性如下所述:
如果DBN没有足够的隐藏层神经元来映射输入样本,那么即使经过长时间的迭代,权重矩阵仍会大幅波动[15]。因此,对于增枝策略,本文提出了一种称为权重距离(weight distance,WD)的方法,并从局部和全局的角度来描述神经元的权重变化趋势,然后提出一条神经元的综合权重变化曲线来寻找不稳定的神经元,为了提高网络的局部描述能力,将不稳定的神经元分成两个神经元,并且新神经元各参数为0;此外,本文通过计算网络与所有训练样本相对应的平均能量来评估网络的稳定性,以此来确定是否需要增加新的隐藏层,提高网络稳定性。对于减枝策略,为了减少网络的冗余并获得一个紧凑的结构,本文通过利用隐藏层神经元对所有训练样本激活概率的标准差来测量神经元提取特征的离散程度,进而找出具有鉴别性的神经元,并移除其余神经元。
更重要的是,虽然DDBN 的训练是一个动态过程,但对其收敛性进行分析后证明是可实现的。在实验中,将本文提出的DDBN模型在3个基准图像数据集上进行了测试,包括MNIST[16]、USPS[17]和CIFAR-10[18],并与多种网络模型进行对比,包括传统的DBN、降噪自动编码机(denoising auto-encoder,DAE),以及ADBN[2]和SODBN[6]。相应的实验结果表明,DDBN比现有的一些DBN结构调整方法具有更好的性能。
2 深度信念网络
DBN由多个顺序堆叠的RBM组成,如果要解决分类问题,则需要在最后增加一层分类器。DBN 的训练过程分为两个阶段:预训练(无监督学习)和微调(监督学习)。第一,使用对比散度(contrastive divergence,CD)算法训练每一层RBM,并且把当前RBM的输出作为下一层的输入,除此之外,每一层的RBM 都是单独训练,确保特征向量被映射到不同的特征空间,从而提取更多的特征信息。第二,将最后一层RBM 的输出作为分类器的输入,使用误差反向传播(back-propagation,BP)算法训练整个网络,对其进行微调。
2.1 RBM结构分析
RBM 由可视层和隐藏层组成,其中可视层即为输入样本,而隐藏层的输出表示了输入样本的概率分布,即提取的输入样本的主要特征。RBM 的结构如图1所示。
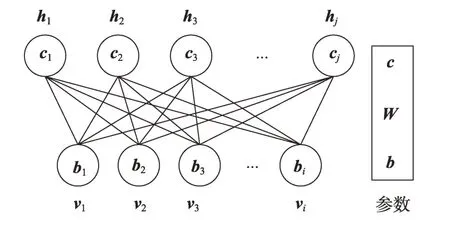
Fig.1 Structure of RBM图1 RBM结构
图中,vi(1 ≤i≤I)和hj(1 ≤j≤J)分别表示可视层神经元和隐藏层神经元,W是可视层和隐藏层之间的权重矩阵,b和c分别是可视层神经元和隐藏层神经元的偏置。
RBM是一种基于能量模型的随机网络。给定参数集θ={W,b,c},则能量函数E(v,h;θ)以及可视层和隐藏层神经元的联合概率分布P(v,h;θ)为:

其中,Z是配分函数,表示所有可能的可视层和隐藏层神经元的和。利用贝叶斯公式的原理,根据式(2)可以求出可视层神经元v的边缘概率分布:

RBM 网络训练的目标就是求解θ={W,b,c},使得在该参数下RBM 能够极大地拟合输入样本,使得P(v;θ)[19]最大,即求解输入样本的极大似然估计。然而,为了获得最大似然估计,需要计算所有可能情况,计算量是指数增长的,因此RBM使用Gibbs采样进行估算[20]。在Gibbs 采样过程中,可视层神经元v和隐藏层神经元h的条件概率分布为:

然而,Gibbs 采样是十分耗时的,特别是当训练样本具有大量特征时。因此目前通常使用CD 算法训练RBM[21]。CD 算法主要有两个特点:(1)使用从条件分布中得到的样本来近似替代计算梯度时的平均求和。(2)只进行一次Gibbs 采样。通过CD 算法,可以快速得到{W,b,c}等参数的更新,从而完成对RBM网络的训练。
2.2 微调
RBM是一种无监督的学习方法,在DBN的最后增加一层分类器,使用反向传播算法训练整个网络,对其进行微调,可以实现对整体网络的参数优化和分类。
微调阶段是把多层RBM训练得到的网络参数作为整体网络参数初始化给BP网络,利用有监督的学习方法训练,并将网络的实际输出与期望输出产生的误差逐层向后传播,完成对整个DBN 网络参数的微调。预训练过程可以看作是RBM训练得到的参数对BP网络的初始化过程,它能克服随机初始化BP网络而导致的训练时间长,容易陷入局部最优解的缺点。
3 动态DBN模型
DDBN通过动态增减枝算法,可以在训练过程中根据当前训练情况自动构建网络结构。增枝操作包括增加新的隐藏层和隐藏层神经元,而减枝操作为移除冗余神经元。本章将介绍DDBN的主要思想。
3.1 动态增减枝算法
动态增减枝算法从局部和全局,即从网络对单个训练样本和所有训练样本的角度考虑网络结构的动态调整,可以避免网络结构陷入局部最优。从局部角度来考虑,在一次迭代训练完成后,找出每个隐藏层神经元对应于某个训练样本的最大的WD 值。从全局角度来说,在一次迭代完成后,计算出使各个隐藏层神经元的WD 值变大的样本占所有训练样本的比例,并与局部条件相结合,描述神经元的综合权重变化趋势。若大于阈值,则将该神经元分为两个神经元。在当前RBM 训练完成后,首先通过隐藏层神经元对所有输入样本激活概率的标准差测量神经元提取特征的离散程度。若标准差大于阈值,则表明神经元提取的特征是具有鉴别性的,并移除其余神经元。然后通过计算网络对所有训练样本的平均能量来评估网络的稳定性,若平均能量大于阈值,则增加一层新的RBM,并且各参数的初始化与初始结构相同。动态增减枝算法的具体描述如下。
3.1.1 动态增枝算法
DDBN 的增枝操作包括增加隐藏层神经元和隐藏层的数量,这分别取决于WD值和能量函数。
首先介绍隐藏层神经元的增长。WD如式(6)所示:
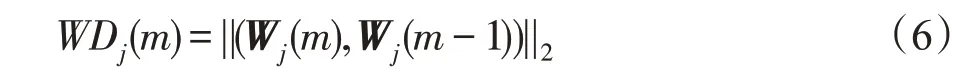
其中,Wj(m)是隐藏层神经元j在经过m次迭代后的权重向量。WD 的值反映了两次迭代中隐藏层神经元j的权重向量的变化情况。一般而言,神经元j的权重向量在训练一段时间后会收敛,即WD的值会越来越小。如果某些神经元的权重向量波动幅度较大,即WD的值较大,应该考虑到这是缺少隐藏层神经元来映射输入样本导致的。在这种情况下,需要增加神经元的数量来提高网络的局部描述能力。本文从局部和全局两方面来描述神经元的权重变化趋势。局部条件定义为:


其中,N是输入样本的个数,N'是与上一次迭代相比使第j个神经元的WD 值增大的样本个数,即。全局条件即计算出使各个神经元的WD值增大的样本占所有训练样本的比例。然后将这两个条件相乘即得到增加隐藏层神经元的条件:
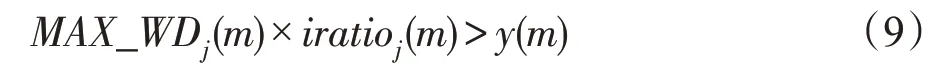
其中,y(m)是一条曲线,用来作为可变阈值,其定义为:
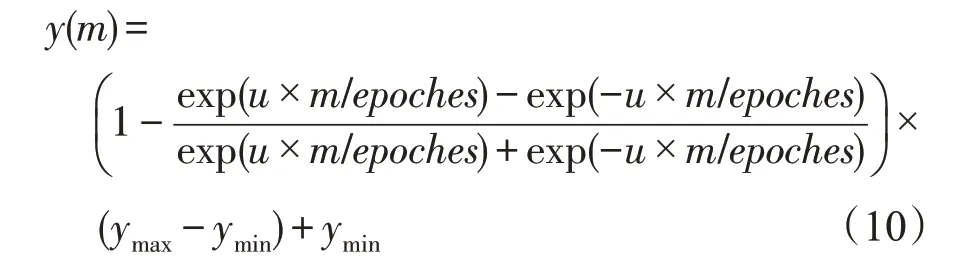
其中,m是当前迭代次数,epoches为最大迭代次数,u表示曲线的曲率,ymax和ymin分别是曲线的最大值和最小值。
在训练过程中,如果网络向好的方向发展,则MAX_WD和iratio的值会越来越小。因此提出一条曲线y(m)来拟合神经元的综合权重变化趋势,并且当u>1 时,y(m)是一条单调递减的凹曲线,u越大,曲线的曲率越大。如果第j个神经元满足式(10),则该神经元将被分成两个神经元,并且新神经元的各参数都为0,如图2所示。
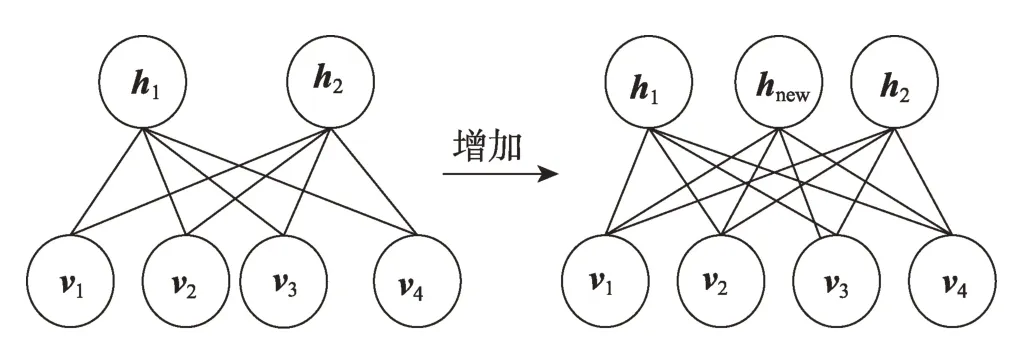
Fig.2 Growth of hidden neurons图2 增加隐藏层神经元
接下来介绍隐藏层的增长。根据式(3)可以发现:

如果想最大化P(v;θ),那么能量函数E(v,h;θ)应该尽可能得小。同时,为了消除训练数据集规模不同对网络的能量计算产生的影响,本文使用的是整体网络与所有训练样本相对应的平均能量。增加隐藏层的条件为:
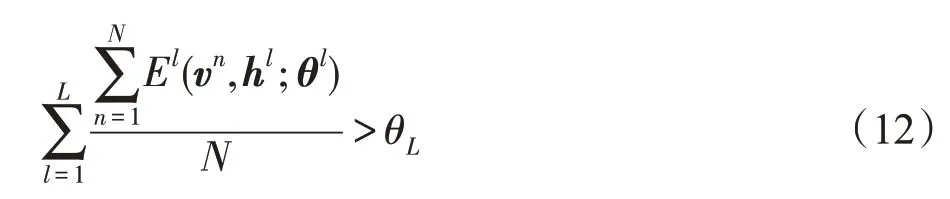
其中,l表示第l层RBM,l=1,2,…,L,L是DDBN 当前的层数,n表示第n个训练样本,θL是阈值。如果整体网络的平均能量满足式(12),则增加一层新的RBM,并且新RBM 各参数的初始化与初始结构相同,如图3所示。
3.1.2 动态减枝算法
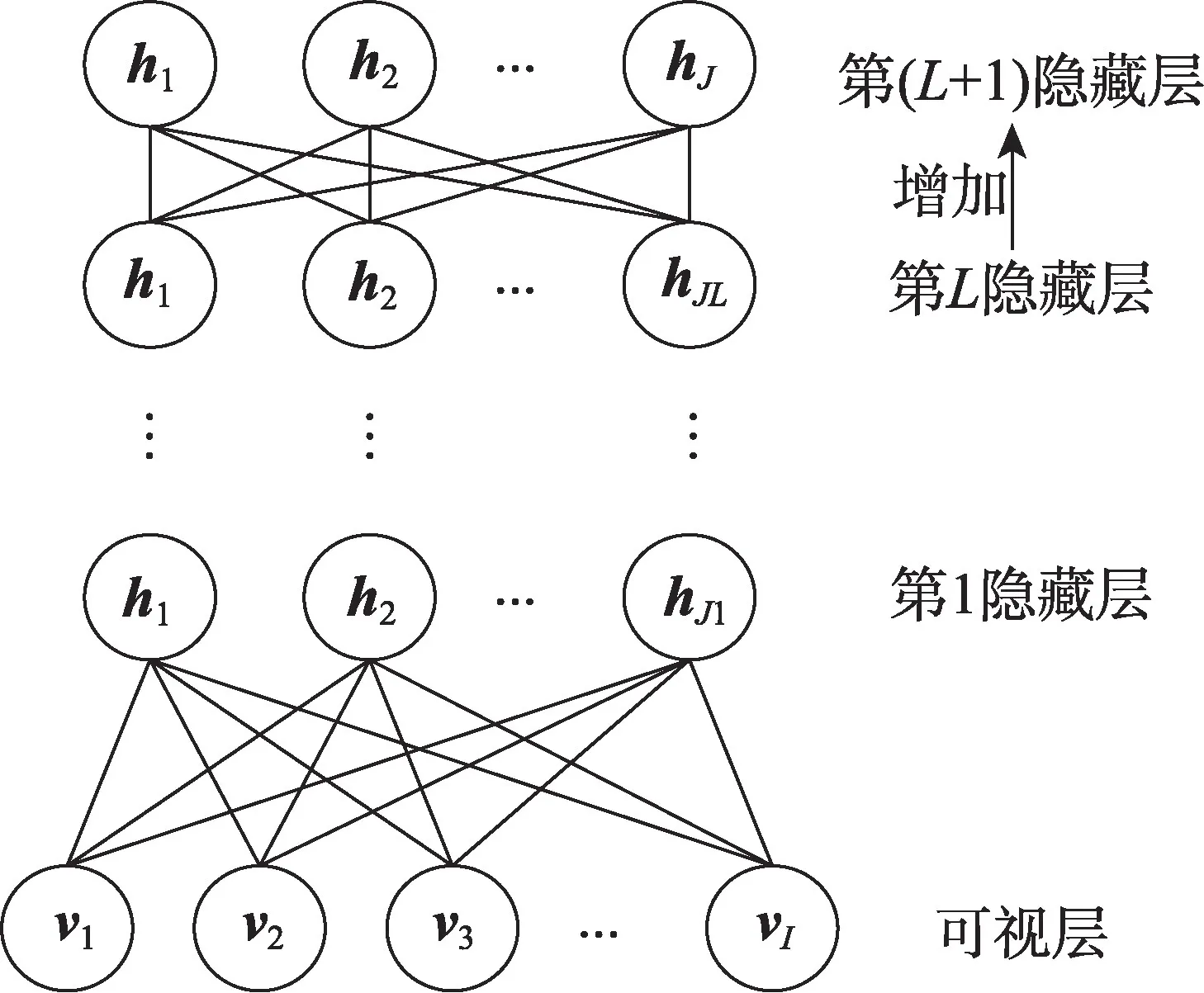
Fig.3 Growth of hidden layers图3 增加隐藏层
RBM 的目的是提取样本的主要特征,即隐藏层神经元的激活概率。这些特征都是有鉴别性的,方便对数据做进一步的应用研究。如果某个神经元的激活概率对所有样本都接近平均值,则说明该神经元提取的特征不具有鉴别性,即冗余神经元。为了减少网络的冗余并获得一个紧凑的结构,需要移除这些冗余神经元。本文使用标准差测量同一隐藏层神经元对所有样本激活概率的离散程度,标准差公式为:
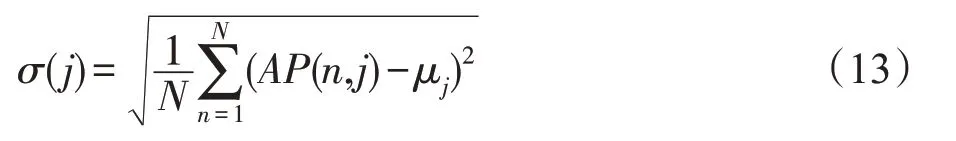
其中,AP(n,j)表示第j个神经元对第n个样本的激活概率,μj表示第j个神经元对所有样本的平均激活概率。一个较小的标准差意味着这些值接近平均值,即这个神经元提取的特征不具有鉴别性,因此需要移除这个冗余神经元。减枝条件为:

其中,θA是一个阈值。关于阈值的取值,做了一条关于减枝率和分类准确率之间的权衡曲线,根据此曲线选择θA的值,使移除更多的冗余神经元的同时保留原始准确率。如果第j个神经元满足式(14),则移除该神经元,包括其所有参数,如图4所示。

Fig.4 Pruning of hidden neurons图4 移除隐藏层神经元
此外,在减枝后,重新训练当前的RBM使剩余的神经元能够补偿被移除的神经元。这一步至关重要,减枝后再重训练为一次迭代。迭代减枝每次都移除较少的神经元,并且进行了多次重训练以进行补偿。经过多次这样的迭代,可以找到一个更高的减枝率并且不损失准确率。每次迭代根据式(15)更新阈值θA:

通过δ(iter)来更新每次迭代减枝中的阈值以移除更多的神经元。每次减枝都是一次贪心搜索,即在上一次减枝最优结果的基础上进行下一次减枝。根据每次减枝中的权衡曲线,可以在不损失准确率的情况下找到最佳减枝率,因此δ(iter)被设置为使θA满足此次迭代减枝所需的减枝率。
3.2 DDBN的训练过程
本文使用CD算法来训练RBM,该算法进行一次Gibbs采样就可以重构样本的分布,大大缩短了训练时间。算法主要思想是:用输入数据初始化可视层的状态,得到v1,通过式(5)计算隐藏层神经元的状态为0或1,得到h1;然后再利用h1和式(4)计算可视层神经元的状态,从而得到可视层的重构v2;最后利用v2和式(5)计算隐藏层神经元的激活概率,得到h2。具体过程如图5所示。
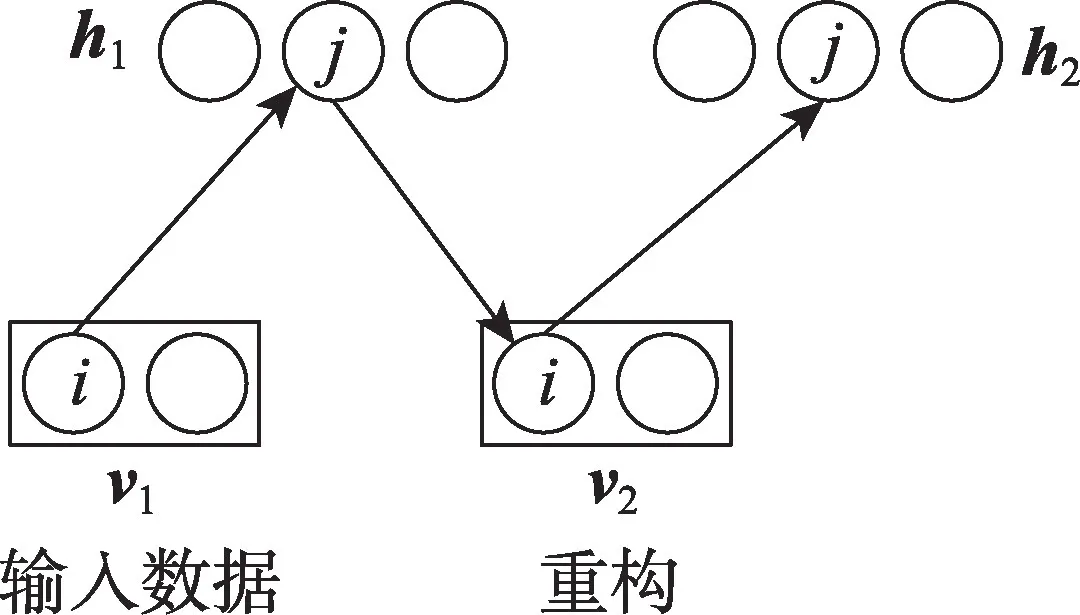
Fig.5 CD algorithm图5 CD算法
然后根据下列公式更新参数:

其中,η为学习率。
综上所述,本文提出的DDBN的训练过程如图6所示。

Fig.6 Training process of DDBN图6 DDBN训练过程
为了使网络应用更广泛,在DDBN 的最后加入Softmax 分类器用于图像分类。对于输入样本{(x(1),y(1)),(x(2),y(2)),…,(x(N),y(N))},标签y取K个不同的值,表示有K个类别。设P(y=k|x)表示在输入x的情况下,样本判别为类别k的概率。对于一个K类Softmax分类器,输出为:

其中,x(n)为第n个输入样本,y(n)表示第n个输入样本的标签,P(y(n)=k|x(n);θ)表示第n个输入样本属于第k类的概率,θ是一个包括权重和偏置的参数矩阵,每一行看作是一个类别所对应分类器的参数,共K行。是对概率分布进行归一化,从而使所有的概率之和为1。Softmax分类器的代价函数为:
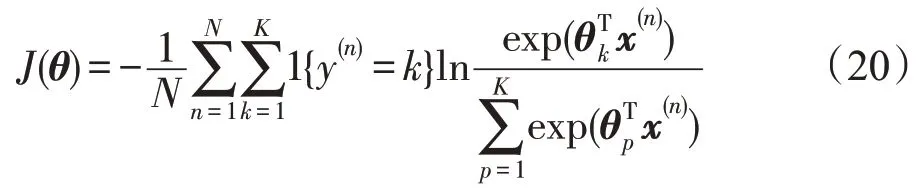
其中,1{} 是一个特征函数,即当y(n)=k为真时,1{y(n)=k}的值为1;当y(n)=k为假时,1{y(n)=k}的值为0。随后,使用反向传播算法,微调整个网络以调整网络参数,最终实现整个DDBN模型的训练。
3.3 收敛性分析
DDBN 的收敛性是一个重要的问题。DDBN 在训练过程中,网络结构是动态变化的,因此网络收敛对DDBN的稳定性和成功应用至关重要。本节将为DDBN动态训练过程的收敛提供理论依据。
3.3.1 增加神经元阶段
在增加神经元阶段,假设第l层隐藏层有J个神经元,则重构误差为。当第j个神经元满足神经元增长条件时,该神经元将被分成两个神经元,因此当前神经元个数为J+1 个,则此时的重构误差为。需要指出的是,重构误差会影响DDBN在结构变化阶段的收敛性,当DDBN 在结构非变化阶段时可以忽略[6]。
在这种情况下,DDBN模型的误差为[11,22]:

其中,eg(n)是网络误差,g()和f()分别是实际函数和理想函数,W为初始权重,W∗为理想权重,grow()表示神经元增长算法,L是隐藏层的层数。
提出假设[11]:

其中,ec>0,因为f()是一个连续函数[11,22],所以f()是有界的。同时,g()是由神经网络构建的,因此g()也是有界的。从而,这个假设是可以成立的。
定理1在增加神经元阶段,如果本文提出的神经元增长算法是有效的,则误差eg(n)可以收敛到一个有限的向量||eg(n)||2<em。同时,随着输入样本的增加,误差eg(n)一致最终有界(uniformly and ultimately bounded,UUB)。
证明根据Lyapunov函数法:

V的导数为:
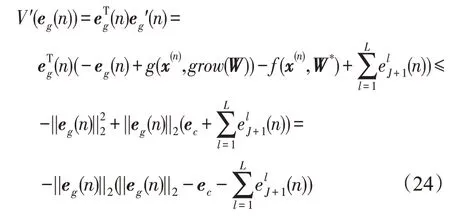
根据式(24)证明误差eg(n)一致最终有界,则得到:
因此,根据Lyapunov稳定性定理,可以证明误差eg(n)一致最终有界,即证明了定理1,并且理论上证明了增加神经元阶段的收敛性。 □
3.3.2 减枝阶段
由于减枝是增加神经元的逆向步骤,并且增加神经元阶段的收敛性已被证明,因此根据定理1,可以得到ep(n)一致最终有界。
同时,预训练过程是通过训练多个叠加的RBM来实现的,这已经被证明是一致最终有界[20],因此也保证了增加隐藏层过程中的收敛性。此外,微调是基于梯度的监督学习,理论上保证了稳定性和收敛性[23-26]。
综上所述,DDBN的收敛性已被证明。
4 实验结果及分析
本文实验使用了3个图像数据集,相应的实验结果将用于验证DDBN 的有效性。同时,DDBN 的各个参数在不同的数据集上是独立选取的,以便实验结果能够验证DDBN 的最佳性能。实验是在Matlab R2014a 下进行,操作系统为Windows 10,CPU 为Intel®CoreTMi3+3.70 GHz,4 GB内存。
4.1 实验数据集
本实验使用了3 个基准图像数据集,MNIST[16]、USPS[17]和CIFAR-10[18]。MNIST 是一种流行的手写数据集,该数据集所含样本为0~9 的阿拉伯数字,均为手写体,拥有60 000 个训练样本和10 000 个测试样本,每个图像由28×28个像素组成;USPS是美国邮政服务手写数字识别库,包括9 298 个0~9 数字的手写数字图像,拥有7 291 个训练样本和2 007 个测试样本,均为16×16 像素;另外,CIFAR-10 数据集含有60 000个彩色图像,包括50 000个训练样本和10 000个测试样本,它们被分为10类。CIFAR-10中的原始彩色图像使用灰度化进行预处理,每个图像由32×32个像素组成。
4.2 参数讨论
本节将讨论动态增减枝算法中的参数选择,包括拟合曲线y(m)的曲率u,动态减枝算法中的阈值θA和δ(iter),以及增加隐藏层的阈值θL。本文使用图像的分类准确率测量DDBN 的性能。此外,这些参数在不同的数据集上是独立选取的,以便实验结果能够验证DDBN 的最佳性能。在预训练阶段,批量大小为100,动量参数设为0,学习率为0.1,最大迭代次数设为100,每层RBM初始神经元个数为10;在微调阶段,批量大小为100,学习率为0.1,最大微调次数设为100。
首先讨论的是拟合曲线y(m)的曲率u。当u>1时,y(m)是一条单调递减的凹曲线,并且u越大,曲线的曲率越大,从而使RBM 更容易增加新的神经元。此外,ymax和ymin的值分别为1.2 和0.4。3 个数据集的实验结果如图7 所示。可以看到,当u的值较小时,由于缺乏隐藏层神经元,网络的特征提取能力较差;当u的值较大时,过多的神经元可能会导致过拟合,这两种情况都会导致准确度下降。比较了多组实验结果并选择使实验结果最优的u的值,此时,RBM 有适当的隐藏层神经元来提取特征。因此,在MNIST 数据集中u=3.9,在USPS 数据集中u=3.5,在CIFAR-10数据集中u=4.0。

Fig.7 Different values of u图7 u的选取
然后讨论的是动态减枝算法中的阈值θA和δ(iter)。需要说明的一点是,减枝不能提高分类准确率,但它可以避免网络的过拟合并且减少网络的冗余并获得一个紧凑的结构。关于阈值的选取,做了一条关于减枝率和分类准确率之间的权衡曲线。在每次迭代减枝中,将隐藏层神经元激活概率的标准差进行排序,通过移除标准差最小的x%个神经元来获得这条曲线,并选择最优的减枝率。再使用CD算法对剩余神经元进行重训练,重训练迭代次数设为50,然后对剩余神经元进行下一次减枝,即在本次减枝最优结果的基础上进行下一次减枝。实验结果如图8所示。
在MNIST 数据集中,可以看到,在iter-1 中移除20%的隐藏层神经元而没有损失准确率,并且iter-2在iter-1 的基础上又多移除10%的神经元。但是,如果没有进行重训练而使用直接减枝,只能移除10%的神经元。因此,加入重训练后的减枝移除的冗余神经元数量是直接减枝的2.8 倍。同理,在USPS 数据集中,iter-1移除40%的神经元,iter-2又多移除10%的神经元,移除的冗余神经元数量是直接减枝的1.5倍;在CIFAR-10 数据集中,iter-1 中移除20%的神经元,iter-2中又多移除20%的神经元,移除的冗余神经元数量是直接减枝的1.8倍。同时,对比iter-1和直接减枝,可以发现在减枝率相同的情况下,iter-1的分类准确率都要高于直接减枝,说明重训练能够有效保留原始准确率。实验结果证明重训练的有效性,并且阈值也可以根据权衡曲线选取最优值。
最后讨论增加隐藏层的阈值θL。在DDBN 中,只有在当前RBM训练完成后才考虑增加新的RBM,并且新RBM 各参数的初始化与初始结构相同,实验结果如表1所示。
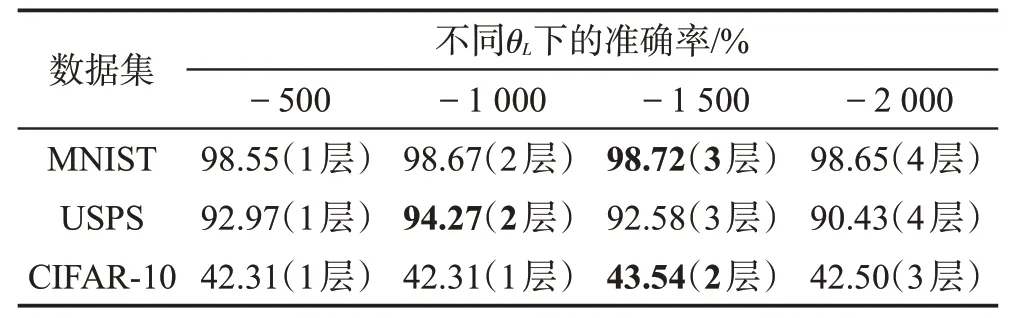
Table 1 Experimental results of different values of θL表1 不同θL 取值的实验结果
根据实验结果,可以发现隐藏层的数量并不是越多越好,因为过多的隐藏层可能会导致过拟合和特征消失的问题,并且降低准确率。在MNIST 和CIFAR-10数据集中,θL的值都为-1 500,隐藏层层数分别为3 和2;在USPS 数据集中,θL的值为-1 000,隐藏层层数为2。
4.3 实验结果
根据4.2节的实验结果选择DDBN的最优参数,然后将DDBN 与多种网络模型进行对比,包括传统的DBN、DAE,以及ADBN[2]和SODBN[6]。3 个数据集的实验结果分别如表2、表3和表4所示。
在这3个实验中,DDBN的分类准确率比传统的DBN、DAE 以 及ADBN 和SODBN 都 要 高,说 明DDBN 模型可以更好地提取到原始数据的主要特征。在隐藏层层数相同时,DDBN 的测试时间最短,这表明通过动态减枝算法得到了一个更加紧凑的网络结构。DDBN中每一层RBM的初始神经元个数都为10,因此训练时间比初始固定结构的DBN和DAE都更短,并且准确率更高,说明DDBN在训练时间上有了进一步的提升,加快了训练的收敛速度。由于ADBN的算法结构比较单一,缺乏对结构调整的全局把握,因此不能得到一个最佳的网络结构,但其训练时间最短。而DDBN 加入了重训练等操作,导致其训练时间比ADBN 更长,但分类准确率要明显高于ADBN。SODBN也可以得到较好的网络结构和分类准确率,但由于其复杂的算法,训练时间也最长。

Fig.8 Trade-off curve of pruning phase图8 减枝权衡曲线

Table 2 Comparison of experimental results of 5 models(MNIST)表2 5种模型的实验结果对比(MNIST)

Table 3 Comparison of experimental results of 5 models(USPS)表3 5种模型的实验结果对比(USPS)

Table 4 Comparison of experimental results of 5 models(CIFAR-10)表4 5种模型的实验结果对比(CIFAR-10)
训练过程中,DDBN 各层RBM 的神经元数量变化情况如图9所示。从图中可以看出,在相同数据集中每层RBM的神经元数量变化趋势大致相同。通过增枝算法增加到最大值后,神经元数量保持不变直到达到最大迭代次数,说明本文选取的阈值是合理的,不会导致神经元无限增长而造成无法收敛。然后再通过多次减枝和重训练,得到最终的网络结构。
综上所述,DDBN 比现有的一些DBN 结构调整方法具有更好的性能。
5 结束语
针对DBN无法根据不同的问题自动调整为合适的网络结构这一情况,本文提出了一种使用动态增减枝算法的动态DBN模型,可以有效优化DBN的网络结构。该模型能够根据不同的问题以及自身的训练情况,从局部和全局的角度考虑,在训练过程中动态调整网络结构,包括隐藏层神经元和隐藏层,从而增强网络的特征提取能力,获得更高的图像分类准确率。3 个基准图像数据集的实验对比显示:DDBN模型的分类准确率明显高于传统的DBN、DAE 模型以及现有的一些DBN 结构调整方法,说明DDBN 可以自动调整为合适的网络结构,更准确地提取数据的主要特征,从而提高了分类准确率。但是DDBN的参数较多,算法操作复杂,导致其缺乏了一定的鲁棒性,并且时间复杂度也要高于某些DBN结构调整方法。同时,本文提出的动态增减枝算法也可以应用到其他的深度学习模型,如自动编码机(autoencoder,AE)。因为AE 的训练过程及网络结构都与DBN 相似,所以动态增减枝算法也可以用来调整AE的网络结构,从而增加网络的特征提取能力。但是本文算法并不适用于卷积神经网络(convolutional neural network,CNN)。

Fig.9 Changes in the number of each RBM neurons图9 各层RBM神经元数量变化
在接下来的研究工作中,将尝试使用神经元的输入和输出这个统一指标来控制神经元的增加或移除,获取更佳的网络结构,并探索在不降低准确率的前提下简化学习算法的方法,降低算法的空间复杂度和时间复杂度。
猜你喜欢
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
电子产品世界(2021年8期)2021-01-16
智能计算机与应用(2020年4期)2020-08-31
计算机系统应用(2019年9期)2019-09-24
中国计算机报(2019年49期)2019-02-07
中国新闻周刊(2017年36期)2017-10-21
科技视界(2016年18期)2016-11-03
创新时代(2016年8期)2016-10-21
