
多标记不完备数据的特征选择算法*
2019-10-24 07:45钱文彬王映龙
计算机与生活 2019年10期
钱文彬,黄 琴,王映龙+,杨 珺
1.江西农业大学 计算机与信息工程学院,南昌330045
2.江西农业大学 软件学院,南昌330045
+通讯作者E-mail:wangylx@126.com
1 引言
当前,在社会生活和科学研究等各个领域中数据呈现爆发式增长,特别是多标记高维数据的广泛存在,传统的单标记分类将一个样本只归为某一个标记,导致无法描述当一个样本同时属于多个标记的问题,需利用多标记分类来描述多标记的数据资源,对于多标记数据的分析和挖掘已成为机器学习和数据挖掘领域中的重要研究内容。近年来,多标记分类问题引起了许多学者的广泛关注和深入研究,且已成功应用于图像分类[1-4]、情感分类[5-7]、生物分类[8-10]、文本分类[11-12]等领域。
多标记高维数据的维数灾难问题严重影响多标记分类器的分类性能。目前,对于多标记数据的特征选择研究取得了一些有意义的研究成果。张振海等[13]使用特征与标记集合之间的重要程度来设置合理的信息增益阈值,并根据阈值删除多标记数据中的不相关特征。Li 等[14]提出一种新颖的基于经典粗糙集的多标记属性约简算法。Liu等[15]利用特征与标记集合间的互信息将特征按其重要度从高到低排序,将特征空间划分为局部子空间,并根据采样比例选择冗余性小的特征。Lee等[16]设计了一种基于可扩展标准的多标记特征选择算法,上述多标记特征选择算法主要是面向离散型完备数据。但在现实生活应用中存在大量的连续型多标记高维数据,若对连续型数据进行离散化处理,将可能造成数据中信息的损失和增加计算的复杂性。
因此,针对多标记连续型数据的特征选择算法引起了众多学者的关注,并取得一些有意义的研究成果。Lee等[17]根据已选特征与标记集合的相关性,从多变量互信息的角度提出了一种多标记特征选择算法。Yu等[18]根据互信息和遗传算法提出一种多标记特征选择算法。Lin等[19]利用实例边界域来计算每个标签下的所有实例的邻域粒度以及用三种不同的测量方法来计算邻域互信息,在此基础上,设计了一种基于邻域互信息的多标记特征选择算法。Wang等[20]设计了一种基于信息粒化的多标记特征选择算法。Yang 等[21]通过映射函数,将高维数据映射到低维空间,设计出基于共享子空间的多标记学习方法。以上算法实现了对多标记完备数据的特征选择。而在许多应用领域中由于诊测成本或隐私保护等导致数据往往呈现不完备性,例如在医学智能诊断系统中,可能存在有些病人,由于经济条件有限,他们不能做所有的检查,因此不能获得这些病人的某些检查数据。目前对于连续型、不完备性多标记高维数据下的特征选择研究相对较少。
为此,本文提出了一种面向多标记不完备数据的特征选择算法。首先,在粗糙集模型上采用了两种不同的距离度量公式计算多标记不完备数据下的邻域粒度,并根据多标记不完备数据中特征的标准差和特征参数计算出合理的邻域阈值,其中参数阈值可根据标准差计算。然后,分析了一致性对象特征的重要性,给出了基于特征依赖度准则的特征重要性度量方法。在此基础上,根据特征的重要性排序设计了特征选择算法。最后,利用五个多标记分类器在Mulan 数据集上对特征选择结果进行实验比较和结果分析,且将本文算法与经典粗糙集方法以及基于信息熵的特征选择算法进行实验对比和分析。实验结果表明,不完备邻域粗糙集模型可直接处理连续型不完备数据,无需对数据进行填充和离散化,使得该特征选择算法对数据的描述更加客观合理,为不完备多标记高维数据的分析和挖掘提供了一种可借鉴的方法。
2 相关知识
在粒计算理论中,多标记数据可表示成一个多标记决策表MDT=(U,C⋃D,V,f),U为样本集{x1,x2,…,xn},也称为论域,C为条件特征集{c1,c2,…,cm},D为多标记决策特征{l1,l2,…,lk},且C⋂D=∅。V为全特征集的值域,其中V=⋃Vc,c∈C⋃D,Vc表示特征c的值域,f是U×(C⋃D)→V的信息函数。
定义1[22]当多标记决策表中存在缺失值时,记缺失值为“*”,即至少存在c∈C,x∈U,使得f(x,c)=∗,此时数据称为多标记不完备决策表IMDT=(U,C⋃D,V,f)。
定义2[22]给定多标记不完备决策表IMDT=(U,C⋃D,V,f),对于任意特征子集B⊆C,定义特征子集B的容差关系T(B)如下:
由定义2 可知,T(B)满足自反性和对称性,但不一定满足传递性。在特征子集B下,对象x具有容差关系的对象集合即在条件特征集下的容差类被定义为TB(x)={xi∈U|(x,xi)∈T(B)}。
定义3[22]给定多标记不完备决策表IMDT=(U,C⋃D,V,f),对于特征子集B⊆C所产生的容差类TB(x),对于ct∈B,若∃xi,xj∈TB(x),有f(xi,D)≠f(xj,D),则称特征子集B中产生不一致对象。若B=C,则称该多标记决策表为不一致决策表。
3 问题描述
由于基于粗糙集的粒计算方法主要是处理名义型或符号型数据,但在现实应用领域中多标记数据的数值类型往往较复杂。当需处理连续型数据,须先对数据进行离散化,而对数据离散化将可能导致重要的信息丢失,从而影响分类算法的分类性能,为此,需对连续型数值的多标记不完备数据开展特征选择的研究。
定义4[23]对于N维的实数空间Ω中,Δ:RN×RN→R,∀xi,xj,xk∈RN,则称Δ为RN上的一个度量,若Δ满足以下条件:
Δ(xi,xj)≥0,Δ(xi,xj)=0 当且仅当xi=xj成立;

其中,(Ω,Δ)为度量空间,Δ(xi,xj)为距离函数,表示元xi和xj之间的距离:

当p=1 时,称为曼哈顿距离;当p=2 时,称为欧氏距离;当p=∞时,称为切比雪夫距离。
定义5[23]给定实数空间上的非空有限集合U={x1,x2,…,xn},对于任意样本xi,若有特征子集B⊆C,则特征子集B上的邻域粒度为:
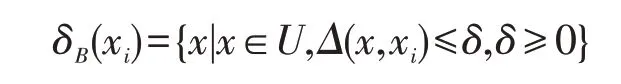
其中,δ为邻域的阈值大小。δB(xi)是由xi生成的δ邻域信息粒度,简称为xi的邻域粒子。根据度量的性质可得:
(1)δB(xi)≠∅,因为xi∈δB(xi);
(2)xj∈δB(xi)⇒xi∈δB(xj);
为了直接处理不完备连续数据,而无须对此类数据进行数据补齐或离散化等预处理,在邻域关系的基础上使用容差邻域关系。
定义6对于多标记不完备邻域决策表IMDT=(U,C⋃D,V,f),对于任意特征子集B⊆C,则特征子集B上的容差邻域关系记为:

下面以表1为例,若以曼哈顿距离作为邻域度量标准,根据定义4计算各样本之间的邻域大小。
利用曼哈顿距离度量公式,若特征c1、c2、c3、c4、c5的邻域阈值分别为0.18、0.15、0.21、0.22、0.24,根据定义6 以及表1 中的数据可计算所有样本的容差邻域关系,以KC(x1,x4)的计算为例:

其中,由于f(x4,c3)=*,在容差邻域计算过程中,令f(x4,c3)=f(x1,c3),由此可知样本x1、x4为容差邻域关系。同理,可计算所有样本在特征全集下的容差邻域关系。

Table 1 Multi-label incomplete neighborhood decision table表1 多标记不完备邻域决策表
根据定义5 计算包含所有特征的每个样本的邻域粒度:

同理,可计算每个特征下每个样本的邻域粒度。
定义7在多标记不完备邻域决策表IMDT=(U,C⋃D,V,f)中,假设U中包含N个样本空间,样本xi对应的标记集合用yi来表示,N个样本实例所对应的向量用y=(y1,y2,…,yn)来表示。样本xi中所对应的第k个标记值用lk来表示。若lk=1,则将lk标记加入yi集合。
以表1为例,根据定义7可计算每个xi样本所对应的标记集合yi为:

定义8在多标记不完备邻域决策表IMDT=(U,C⋃D,V,f)中,对于∀lk∈D,分别计算存在标记决策lk所对应的样本集合Dk:

其中,[x]lk为在标记决策lk下,标记决策的值分别为1和0所对应的对象集合。
以表1 为例,根据定义8 可计算存在标记决策lk所对应的样本集合Dk:

定义9[24]在多标记不完备邻域决策表IMDT=(U,C⋃D,V,f)中,将拥有类别标记lk的样本集合用Dk表示,将样本xi所具有的标记集合用yi来表示。给定B⊆C,多标记不完备邻域粗糙集的上下近似集为:
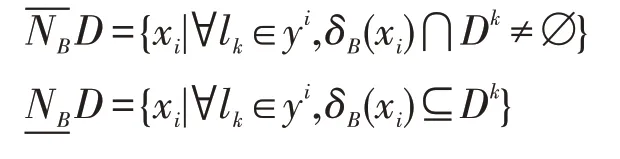
由定义9 可知,下近似集与邻域粒度相关,且下近似集将随邻域粒度的增大而减小。
以表1为例,根据定义9可计算特征全集C下的下近似集。具体计算过程如下:
由于样本x1所对应的标记是l1,因此只需判断δC(x1)⊆D1是否成立。若成立,则样本x1在正域范围。因为δC(x1)={x1,x4},δC(x1)⊄D1,所以。同理可得。由此可知特征全集C下的下近似集。
定义10在多标记不完备邻域决策表IMDT=(U,C⋃D,V,f),对于特征子集B⊆C,特征子集B对应的正域为:

由定义10 可知,正域将随下近似集的减小而减小。以表1 为例,根据定义10 可得特征全集C下的正域为。
定义11在多标记不完备邻域决策表IMDT=(U,C⋃D,V,f),对于特征子集B⊆C,特征子集B的特征依赖度为:
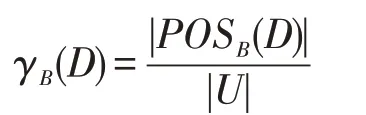
由定义11可知,正域与特征依赖度相关,特征依赖度随正域的增大而增大。
定义12在多标记不完备邻域决策表IMDT=(U,C⋃D,V,f),若特征子集B⊆C,对于任意特征ct∈C-B,特征ct在特征子集B基础上相对于决策D的重要度为:

根据定义12 可知,特征重要度随特征依赖度的减小而减少。且当特征选择后的特征子集和原特征集的特征依赖度一致或除特征子集外的特征重要度都为0时,说明特征子集外的特征是冗余的。
定义13[23]在多标记不完备邻域决策表IMDT=(U,C⋃D,V,f),存在特征子集B⊆C,若特征子集B是多标记不完备邻域决策表的一个特征选择结果,则B需满足:
(1)γB(D)=γC(D)
(2)∀ct∈B,γB-{ct}(D)<γB(D)
条件(1)使得特征子集B和全特征集C下的正域样本相同,条件(2)确保了特征子集B中没有冗余特征。
性质1在多标记不完备邻域决策表IMDT=(U,C⋃D,V,f),邻域阈值δ具有单调性,即若δ1≥δ2,则γδ1(D)≤γδ2(D)。
证明由定义5 可知,若δ1>δ2,则对于任意的xi∈U,使得δ1(xi)>δ2(xi)成立。当δ1(xi)>δ2(xi)时,并由定义9可知,使得(δ2(xi)⋂D)⊆(δ1(xi)⋂D)成立,由此可推导出----Nδ1D⊇----Nδ2D。同理可证,。当时,由定义10可推导出POSδ1(D)⊆POSδ2(D)。由定义11和前面推导可得γδ1(D)≤γδ2(D)。当且仅当δ1=δ2时,使得POSδ1(D)=POSδ2(D),γδ1(D)=γδ2(D)成立。□
性质2多标记不完备邻域决策表IMDT=(U,C⋃D,V,f)中,特征子集B⊆C,当∀ct∈B,γB-{ct}(D)≤γB(D),则有:
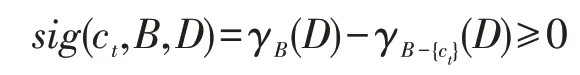
当sig(ct,B,D)>0 时,可知特征ct相对于特征子集B是必要的。若sig(ct,B,D)=0 时,说明特征ct是冗余特征。
证明由性质1 可知,对于任意ct∈B,使得γB-{ct}(D)≤γB(D) 成立,由定义12 可知,当γB-{ct}(D)≤γB(D)时,使得sig(ct,B,D)≥0 成立。当γB-{ct}(D)=γB(D),则sig(ct,B,D)=0 成立。由定义13 可知,若sig(ct,B,D)=0成立时,特征ct相对于特征子集B是冗余特征,否则为必要特征。 □
从性质1和性质2可知,邻域粒度随着邻域阈值δ单调不减,即当邻域阈值δ越大,邻域粒度将会越大或不变。
4 特征选择算法
根据上述分析可知,针对多标记不完备决策表的特征选择,首先根据邻域的阈值计算多标记不完备决策表中每个样本的邻域粒度,并计算每个标记特征的样本集合。在此基础上,得到多标记不完备决策表的正域样本集合。然后,分别计算每个条件特征下的邻域粒度和特征的依赖度,并根据特征的依赖度计算特征的重要度,每次将重要度最大的特征加入当前的特征子集中,直到特征子集下的正域样本集合等于全特征集下的正域样本集合,由此设计了一种面向多标记不完备决策表的特征选择算法,算法描述如下:
输入:多标记不完备决策表<U,C⋃D,V,f>,δ为邻域的阈值。
输出:特征子集Red。
步骤1初始化Red←∅。
步骤2对于∀xi∈U,计算在特征集C下每个样本的邻域粒度δC(xi)。
步骤3对于∀lk∈D,分别计算每个标记lk下的样本集合Dk。
步骤4若δC(xi)⊆Dk,则将样本xi存入正域POSC(D)←POSC(D)⋃{xi}。
步骤5对于∀cj∈C-Red,执行操作:
步骤5.1计算条件特征集Red⋃cj下每个样本的邻域粒度δRed⋃cj(xi);
步 骤5.2对 于 多 标 记∀lk∈D且lk=1,若δRed⋃cj(xi)⊆Dk,则POSRed⋃cj(D)←POSRed⋃cj(D)⋃{xi};
步骤5.3计算特征集的依赖度:
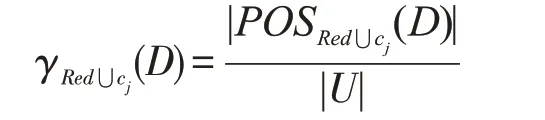
步骤5.4若ct=arg max{Sig(cj,Red,D)},则Red←Red⋃{ct},即计算加入条件特征cj的重要度Sig(cj,Red,D),选择重要度最大的条件特征ct存入Red。
步骤6若POSRed(D)≠POSC(D),则算法转至步骤5,否则执行步骤7。
步骤7输出特征子集Red,算法结束。
算法的时间复杂度分析:
算法步骤1 初始化一个变量存放特征选择后的特征子集,其时间复杂度为O(1);算法步骤2 在整个条件特征集下通过样本之间的比较计算得到每个样本的邻域粒度,其时间复杂度为O(|C||U|2);算法步骤3分别计算每个标记决策下的样本集合,其时间复杂度为O(|C||D|);算法步骤4 计算多标记不完备决策表的正域样本集,其时间复杂度为O(|U|2+|U||D|);算法步骤5对多标记不完备数据进行特征选择,最坏的时间复杂度为O(|C|2|U|2);算法步骤6判断约简后的特征子集下正域与整个论域的正域是否一致,最坏的时间复杂度为O(|U|)。综述分析,算法的时间复杂度为O(|U|2|C|2)。
5 实验与结果分析
5.1 数据集和性能指标
为了验证本文中提出的特征选择算法的有效性,从Mulan 数据集中选取了Emotions、Birds、Yeast和Scenes四个真实数据集进行实验测试和分析。四个数据集的相关信息如表2 所示。本实验的测试环境:CPU 为Intel®CoreTMi5-4590s(3.0 GHz),内存8.0 GB,算法编程语言为C++和Java,使用的开发工具分别是Visual studio 2017和Eclipse 4.7。
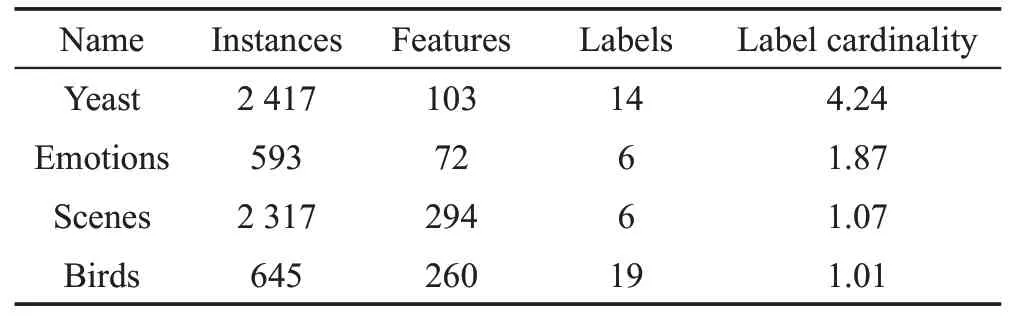
Table 2 Multi-label datasets表2 多标记数据集
在实验测试和分析的过程中,将每个数据集的训练样本和测试样本相结合,用随机函数对四个数据集进行5%的数据缺失处理,并采用10 倍交叉验证法对实验结果进行验证。在实验过程中,首先分别利用曼哈顿距离和欧式距离两种度量方法计算邻域粒度。在此基础上,根据特征重要度对每个数据集进行特征降维。然后将特征降维后的特征子集通过五种多标记分类器(又称多标记分类算法)基于随机k标记集的多标记分类[25](randomk-label sets,RAkEL)、基于依赖多标记k近邻的多标记分类[26](dependent multi-labelk-nearest neighbor,DMLkNN)、基于实例的逻辑回归多标记分类[27](instance-based logistic regression for multi-label classification,IBLRML)、基于二元相关的k近邻多标记分类[28](binary relevancek-nearest neighbor,BRkNN)和基于多标记k近邻的多标记分类[29](multi-labelk-nearest neighbor,MLkNN)验证了算法的性能,并从平均分类精度(average precision,AP)、汉明损失(Hamming loss,HL)、覆盖率(coverage)、1 错误率(one error,OE)和排序损失(ranking loss,RL)这五种多标记评价性能指标评估和对比分类器的分类性能。其中平均分类精度越大越好,汉明损失、覆盖率、1错误率、排序损失越小越好。
5.2 λ 特征参数的分析
对于多标记不完备邻域决策表,邻域参数的选择直接关系到特征选择的结果和分类器的分类性能。为此,在曼哈顿距离的度量方法中,邻域参数的计算方式为δ=stdai/λ,其中stdai为通过本文算法进行特征选择之后的每个特征的标准差。欧氏距离度量的邻域参数计算方式为δ=(stdan/n)/λ,其中stdan/n是通过本文算法进行特征选择之后的所有特征的平均标准差。由于每个数据集在不同的距离度量方法下其特征值的标准差是固定的,λ的取值直接关系到邻域参数δ的值[30]。通过实验分析发现,λ的取值范围从0.1到2.0的特征选择结果所对应的分类性能较好。为了详细分析λ值对特征选择结果和分类器的分类性能影响,在实验过程中将λ值每次变化0.1进行实验分析和结果对比。
下面将以scene 数据集为例,详细分析在曼哈顿距离和欧氏距离这两种度量标准下λ(在图中用Lambda 表示λ)变化对于特征选择的个数和分类器的分类性能影响,实验结果如图1和图2所示。
由图1可知,对于scene数据集来说,在曼哈顿距离度量标准下,由图1(a)可知,当λ=0.1 时,本文算法将特征个数由294 减少至4 个,但5 个分类器的平均分类精度较低;当λ的取值为0.3~0.4 时,5 个分类器的平均分类精度的上升趋势显著,由图1(b)可得,汉明损失在这个区间的变化趋势较为平缓,由图1(c)、(d)和(e)可看出,5个分类器的覆盖率、1错误率和排序损失的值都呈下降趋势。当λ的取值在0.4~0.9时,特征选择的个数下降明显,5个分类器的平均分类精度、汉明损失、覆盖率、1 错误率、排序损失的值较好。当λ的取值在1.0~2.0 之间,由图1(a)的变化曲线发现特征选择的个数和5 个分类器的平均分类精度变化并不明显,且由图1(b)、(c)、(d)和(e)对应的汉明损失、覆盖率、1错误率、排序损失的值呈现出平缓上升。

Fig.1 Size of feature selection and classification performance with varying λ under Manhattan distance图1 曼哈顿距离度量下特征选择的个数和分类性能随λ 值的变化
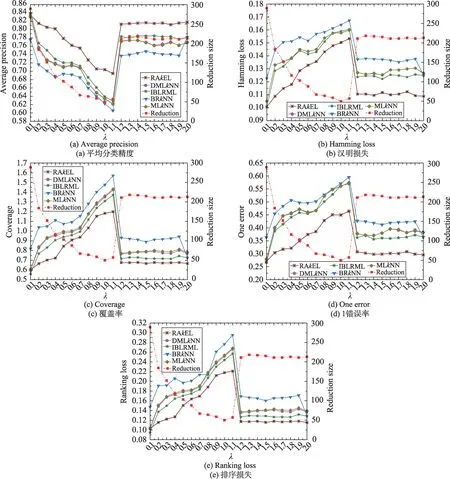
Fig.2 Size of feature selection and classification performance with varying λ under Euclidean distance图2 欧氏距离度量下特征选择的个数和分类性能随λ 值的变化
由图2 可知,在欧氏距离度量标准下,当λ的值在0.1~1.0范围内,特征选择个数随λ单调递减,且分类器的平均分类精度也呈现递减趋势。由图2(a)中曲线的变化趋势可知,5个分类器的平均精度明显下降,而由(b)、(c)、(d)和(e)中的曲线变化可知,汉明损失、覆盖率、1错误率和排序损失的值都呈上升趋势。其中,当λ=1.0时,特征选择的效果最优,特征个数由原有的294 减少至50。当λ=0.6 时,5 个分类器的平均分类精度、汉明损失、覆盖率、1 错误率、排序损失的值较优。当λ的取值在1.2~2.0 时,随着特征选择的个数增加,由(a)可知,5个分类器的平均分类精度得到明显改善,且由图2(b)、(c)、(d)和(e)对应的汉明损失、覆盖率、1错误率、排序损失的值也越来越小。
另外,将图1 和图2 进行对比可以发现,平均精度、汉明损失、覆盖率、1 错误率和排序损失在图1 中的变化区间分别约为40%、10%、180%、60%和35%,而在图2 中分别约为26%、7%、110%、35%和22%。通过数值对比发现,图1中的5种多标记分类器的分类性能的变化幅度趋势大于图2,由此可得,以欧氏距离作为邻域度量标准与以曼哈顿距离作为邻域度量标准相比,降维后的特征子集分类性能的稳定性更好。
综上可知,以scene数据集为例,把欧氏距离作为邻域度量标准,算法的特征选择效果较好,且5 个分类器的分类性能也都较优。且从特征降维的效果及分类器的5个性能指标来看,对于scene数据集,在曼哈顿度量标准下λ的取值为0.9较优,在欧氏距离度量标准下λ的取值为0.6较好。
同时通过确定λ特征参数的实验可知,当λ的值越大,则δ邻域阈值将会越小,邻域粒度也越小。此时,多标记邻域数据的下近似集将随邻域粒度的减小而增大,正域中的对象将随下近似集的增大而增大,特征依赖度也随正域的增大而变大。
5.3 实验比较与分析
为进一步验证本文算法的有效性,下面将以RAkEL 分类器为例,将两种距离度量标准下的本文算法与MLFSIE(multi-label feature selection based on information entropy)[17]、MLFSPA(multi-label feature selection based on positve approximation)[31]和MLFSDM(multi-label feature selection based on discernibility matrix)[32]这3种算法对4个数据集进行了实验分析和对比。其中,MLFSIE是基于信息熵的多标记特征选择算法,MLFSPA是本文对数据离散化后基于正区域思想改造的多标记特征选择算法,MLFSDM 是本文对数据离散化后基于差别矩阵思想改造的多标记特征选择算法。Manhattan distance 和Euclidean distance分别表示本文算法使用曼哈顿距离方法和欧氏距离方法作为邻域度量标准时,根据特征重要度进行特征降维后,所获得的特征子集的分类性能。另外,由于上述4 个数据集的特征值均是连续型数据,但MLFSIE、MLFSPA 和MLFSDM 算法处理的是离散型数据,因此在实验中需先利用等距离散化方法对4 个数据集进行离散化处理。实验结果如表3~表6 所示,加粗字体表示所对应数据集及5 个性能指标下算法的最优值。
从表3~表6 中的5 项多标记分类性能指标实验结果可知,与其他3 种算法相比,本文算法的分类性能总体较优。另外,在RAkEL分类器下,邻域度量方法使用欧氏距离度量方法时得到的降维后的特征子集的分类性能总体优于使用曼哈顿距离度量方法。
由表3的实验结果可知,针对Yeast数据集,使用本文算法降维后的特征子集的分类性能优于其他3种算法。例如,其在两种度量方法下AP的均值分别比MLFSIE、MLFSPA 和MLFSDM 算 法 提 高 了2.05%、0.55%和2.50%,且HL、Coverage、OE 和RL 的均值也明显低于其他3 种算法。此外,在Yeast 数据集中,两种邻域度量方法的Coverage 和RL 值相等,且其AP 的值也仅相差0.000 1 的方差。由此可知,RAkEL分类器的分类性能与邻域度量方法的相关性较小。

Table 3 Comparison of experiments in Yeast dataset表3 Yeast数据集的实验结果对比

Table 4 Comparison of experiments in Emotions dataset表4 Emotions数据集的实验结果对比

Table 5 Comparison of experiments in Scenes dataset表5 Scenes数据集的实验结果对比

Table 6 Comparison of experiments in Birds dataset表6 Birds数据集的实验结果对比
由表4中Emotions数据集的实验结果可得,使用本文算法降维后的特征子集的分类性能显著优于其他3 种算法,其中分类性能差值最大的是MLFSIE算法。以曼哈顿距离度量方法的本文算法与MLFSIE算法在五大性能指标的比较为例,其AP的值提高了15.45%,且HL、Coverage、OE 和RL 的值也分别降低了12.41%、81.07%、24.79%和17.72%。另外,在曼哈顿距离度量方法下,HL、Coverage和RL的值较优,在欧氏距离度量方法下,AP和OE的值更优。
从表5中Scenes数据集的实验对比结果可得,该数据集适用于使用欧氏距离作为邻域度量标准。同时,将本文算法与其他3 种算法相比,与其分类性能最为相近的是MLFSPA算法,其AP、HL、OE和RL的差值都相对较小,分别为1.57%、0.83%、1.45%和1.61%,相差较为明显的是Coverage,其差值为8.52%。
由表6可看出,在Birds数据集中,分类性能较优的是MLFSDM算法,其AP的值最优,为61.64%。将MLFSDM 算法与欧氏距离度量方法的本文算法相比,其AP、Coverage、OE 和RL 的值相对较优,但其HL值在本文算法更优;同时通过实验的结果可发现,利用欧氏距离的度量方法要优于曼哈顿距离的度量方法,其中最为明显的两个指标分别为AP 和Coverage,差值分别为4.45%和36.39%。本文算法与MLFSDM 算法相比,其降维后的特征子集的分类性能相对较差,本文算法与MLFSIE、MLFSPA 这两种算法相比,本文算法效果较优。
综上所述,将本文算法与3种不同的多标记特征选择算法在真实数据集上进行实验对比和分析可知,本文算法总体上提高了分类器的分类性能。为此,本文研究结果为多标记不完备数值数据的处理和分析提供了一种可借鉴的分析方法。
6 结束语
由于数据存在获取限制、理解有误和数据遗漏等问题,且在生活中连续型数据往往较多,为此针对多标记数据中存在缺失值和连续值的问题,提出了一种面向不完备特征邻域决策表的多标记特征选择算法。算法无需对缺失数据进行填充,且可直接处理连续型数据。通过两种不同的距离度量标准对不完备特征邻域决策表进行邻域粒化,在此基础上设计了特征的重要性度量方法,并采用启发式搜索策略对多标记不完备决策表进行特征选择。通过不同的多标记分类器对算法进行实验以及与3 种经典的多标记特征选择算法对比分析说明了本文算法的有效性。由于现实生活中许多复杂问题的不同标记之间存在相关性,下一步工作将研究复杂数据中多标记之间的相关性问题。
猜你喜欢
大数据(2022年4期)2022-07-25
农业工程学报(2022年7期)2022-07-09
中学生数理化(高中版.高一使用)(2021年9期)2021-12-02
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
逻辑学研究(2021年3期)2021-09-29
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
数学教学通讯·初中版(2015年5期)2015-06-17
