
基于三维卷积神经网络的虫音特征识别方法
2019-10-31 09:21万永菁王博玮娄定风
计算机应用 2019年9期
万永菁 王博玮 娄定风


摘 要:进口木材蛀虫检疫是海关的一项重要工作,但其存在着虫声检测算法准确率低、鲁棒性差等问题。针对这些问题,提出了一种基于三维卷积神经网络(3D CNN)的虫音检测方法以实现虫音特征的识别。首先,对原始虫音音频进行交叠分帧预处理,并使用短时傅里叶变换得到虫音音频的语谱图;然后,将语谱图作为3D CNN的输入,使其通过包含三层卷积层的3D CNN以判断音频中是否存在虫音特征。通过设置不同分帧长度下的输入进行网络训练及测试;最后以准确率、F1分数以及ROC曲线作为评估指标进行性能分析。结果表明,在交叠分帧长度取5s时,训练及测试效果最佳。此时,3D CNN模型在测试集上的准确率达到96.0%,F1分数为0.96,且比二维卷积神经网络(2D CNN)模型准确率提高近18%。说明所提算法能准确地从音频信号中提取虫音特征并完成蛀虫识别任务,为海关检验检疫提供有力保障。
关键词:三维卷积神经网络;短时傅里叶变换;语谱图;虫音识别;声学信号处理
中图分类号:TP391.4
文献标志码:A
Insect sound feature recognition method based on three-dimensional convolutional neural network
WAN Yongjing1, WANG Bowei1*, LOU Dingfeng2
1.School of Information Science and Engineering, East China University of Science and Technology, Shanghai 200237, China;
2.Shenzhen Customs, Shenzhen Guangdong 518045, China
Abstract:
The quarantine of imported wood is an important task for the customs, but there are problems such as low accuracy and poor robustness in the insect sound detection algorithm. To solve these problems, an insect sound detection method based on Three-Dimensional Convolutional Neural Network (3D CNN) was proposed to detect the presence of insect sound features. Firstly, the original insect audio was framed and pre-processed, and Short-Time Fourier Transform (STFT) was operated to obtain the spectrogram of the insect audio. Then, the spectrogram was used as the input of the 3D CNN consisting three convolutional layers. Network training and testing were conducted by setting inputs with different framing lengths. Finally, the analysis of performance was carried out using metrics like accuracy, F1 score and ROC curve. The experiments showed that the test results were best when the overlap framing length was 5 seconds. The best result of the 3D CNN model on the test set achieved an accuracy of 96.0% and an F1 score of 0.96. The accuracy was increased by nearly 18% compared with that of the two-dimensional convolutional neural network (2D CNN) model. It shows that the proposed model can extract the insect sound features from the audio signal more accurately and complete the insect identification task, which provides an engineering solution for customs inspection and quarantine.
Key words:
Three-Dimensional Convolutional Neural Network (3D CNN); Short-Time Fourier Transform (STFT); spectrogram; insect sound detection; acoustic signal processing
0 引言
我國进口原木的数量逐年上升,其携带的有害生物造成的疫情也不断加重,其中小蠹科、长小蠹科、天牛科、吉丁虫科、长蠹科等钻蛀性昆虫为进口原木中的主要害虫[1]。进口原木中的这些害虫对我国的生态环境、林业生产和公众生活构成极大的威胁。在口岸检疫时,通常采用破坏性的检查方法对原木进行目视和剖检,其检出效率不高,费工费时[2]。近年来,随着声学、信号处理、计算机技术的发展,出现了无损的检测方法。如Sutin等[3]利用震动传感器获得木材表面的振动信号,提出了一套基于时域的害虫检测方法;害虫在进食、活动和交流时都会有声音信号的产生,所以利用声音信号来检测也是一个不错的选择:祁骁杰等[4]通过采集声音信号,采用时频结合的方法对木材内的害虫数量进行识别。尽管以上研究取得了不错的效果,但使用的方法均基于时频域手工提取的特征,带来的设备成本和对环境的要求都严重限制了其在边境检疫中的推广。随着近些年来深度学习的快速发展,它在图像处理、语音识别、自然语言处理等领域的成功应用也为解决这个问题带来了新的研究方法和思路。
将深度学习应用在动物的声学识别和分类最早可以追溯到本世纪初期蝙蝠回声定位的相关研究中[5]。随后也不断涌现出了许多基于传统特征提取的识别方法。利用动物的声音信号来进行识别在害虫控制[6]、物种多样性检测[7]等方面都有着重要的作用。传统的声音识别主要包括三个阶段:首先是预处理,然后是特征提取,最后是模式识别。预处理通常包括标准化、降噪等,虽然目前降噪技术在某些数据集上能够有效工作,但是在复杂环境下的处理仍然是一个挑战。然后会进入到特征提取环节,将数据转换为适合分类器输入的形式进入到最后的判决阶段。通常,特征提取指的是应用信号处理的不同方法提取时频域的各种特征。常见的提取方法包括梅尔频率倒频系数(Mel Frequency Cepstral Coefficients, MFCC)[8],线性频率倒频系数(Linear Frequency Cepstral Coefficients, LFCC)[9]。这些方法不仅在语音识别领域均取得了不错的效果,在其他音频信号处理中也得到了广泛的应用。除此之外,利用短时傅里叶变换(Short-Time Fourier Transform, STFT)、小波变换(Wavelet Transform, WT)以及希尔伯特黄变换(Hilbert-Huang Transform, HHT)等方法得到语谱图的特征提取也有着不错的效果[10]。常见的分类方法包括支持向量机(Support Vector Machine, SVM)、隐马尔可夫模型(Hidden Markov Model, HMM)、高斯混合模型(Gaussian Mixture Model, GMM),以及最近的深度神经网络(Deep Neural Network, DNN)。深度神经网络通过使用视觉上的某些信息进行相关的训练。音频通过二维的语谱图作为输入,卷积神经网络(Convolutional Neural Network, CNN)模型能够捕获时域和频域的某些能量变换从而实现分类判决任务。但是使用二维输入将会使CNN模型更多地关注背景噪声而不是声音事件,且其性能受数据集大小影响较大。
为了解决传统信号处理在高噪声背景下难以提取微弱信号以及二维卷积神经网络(Two-Dimensional Convolutional Neural Network, 2D CNN)不能充分利用时频信息的问题,本文提出了基于声学的三维卷积神经网络(Three-Dimensional Convolutional Neural Network, 3D CNN)以识别木材中的害虫。CNN在各种视觉识别任务中都有着出色的性能。最近,CNN在声学信号处理方面有了一些新的尝试:牛津大学的Kiskin等[11]提出基于小波变换的2D CNN以识别热带家蚊且达到了0.925的F1分数,该方法也同样被证实在鸟类的分类任务中有着出色的表现;Zhou等[12]通过快速傅里叶变换(Fast Fourier Transform, FFT)和n-gram语言模型提取特征,使用CNN混合模型在自动语言识别(Automatic Speech Recognition, ASR)上也取得了不错的成果。考虑到木制品中害虫活动规律的周期性,本文提出了基于3D CNN的虫声检测方法。该方法相比二维能够更好地提取虫音特征,在F1分数和准确率两个指标上均优于2D CNN模型,在低信噪比环境下也能够实现较高的准确率,为边境检验检疫部门提供检测害虫的有效工具。
1 卷积神经网络
1.1 二维卷积神经网络
卷积神经网络是一种典型的深度学习方法,近年来的飞速发展使得其在图像识别领域有了巨大的进步。深度卷积神经网络通过模仿生物神经网络,低层表示细节,高层表示语义,能够通过大量的數据自动地训练出模型[13]。二维卷积神经网络的计算公式如式(1)所示:
yxy=f(∑i∑jwijv(x+i)(y+j)+b)(1)
其中:yxy是位置(x,y)的特征图,wij是卷积核的权重,v(x+i)(y+j)是在(x+i,y+j)的输入值,b是偏差[14]。
一个典型的神经网络通常包括卷积层、池化层和全连接层。CNN网络的核心功能在卷积层完成,在每一层都会计算输入与当前层权重的点积。在图像处理中,为了确保能从图像信息中得到所有的颜色信息,接受层的深度必须和颜色通道个数一致。卷积层的输出叫作特征图,而特征图的个数也由深度决定。卷积层后会有激活层,通常会使用非线性函数对上一层数据进行激活。在卷积层后通常也会有池化层,池化层的作用是在保证输入不变的情况下进行降采样以减少计算量。
1.2 三维卷积神经网络
三维卷积神经网络和二维卷积神经网络类似,是二维卷积神经网络的一种拓展。在二维卷积神经网络中,卷积层的输入是二维的空间信息;而在三维卷积神经网络中,时间和频域信息能够被更加充分地利用。三维神经网络的卷积核有三个维度,有时还考虑颜色通道为第四个维度。其计算公式如式(2)所示:
yxyt=f(∑i∑j∑kwijkv(x+i)(y+j)(t+k)+b)(2)
其中:yxyt是在(x,y,t)处的特征图,f是激活函数,wijk是核权重,v(x+i)(y+j)(t+k)是在(x+i,y+j,t+k)位置的输入值,b是偏差[14]。
正如前面所描述的那样,三维卷积神经网络是对二维卷积神经网络的一种拓展。模型的输入也会根据需要修改为合适的三维形式。
2 基于3D CNN的检测方法
2.1 方法概述
本文以短时傅里叶变换(STFT)得到的语谱图作为3D CNN的输入搭建了模型,应用到害虫的声学识别中。首先,对获取到的音频数据进行标准化的预处理;其次,需要提取音频数据的特征,本文利用短时傅里叶变换(STFT)提取虫声的时频特征并进行分帧处理;最后,将二维的频谱特征数据变换到合适的三维形式作为3D CNN的输入进行训练。
2.2 数据来源和预处理
本文的音频数据来源于深圳市出入境检验检疫局,覆盖了在2017年到2018年期间不同环境下录制的67段音频。其中785个片段为31种害虫在木材中活动和进食的音频,1534个片段为各种实际检疫环境中的非虫音(分帧长度n=5s时)。存在害虫的音频被标记为1,包括环境噪声在内的非虫音被标记为0。木材中的害虫已经通过昆虫分类专家鉴定,因此可以认为数据标定是准确的。
同时,特征的提取还受到录音设备、发声响度的影响,本文使用了式(3)对音频进行标准化处理,其中x[k]表示声音序列,K表示音频的长度。
x[k]=x[k]∑kx2[k]/K(3)
2.3 特征提取
为了将训练数据转换为适合神经网络训练的形式,本文采用短时傅里叶变换(STFT)提取时频特征。离散短时傅里叶变换方法如式(4)所示:
STFT{x[k]}≡X(m,ω)=∑∞k=-∞x[k]w[k-m]e-jωk(4)
根据害虫的发声规律,对音频信号作短时傅里叶变换得到语谱图,然后将语谱图以50%的重叠分帧为n秒的片段,其中n取3、4、5、6、7、8,在不影响原始数据的基础上扩大了实验样本。因为数据集的采样频率fs=44100Hz,最大可辨识频率被限制在22050Hz。本文选择了20ms的Hanning窗,重叠率为50%,1024点的FFT来计算短时傅里叶变换。最后,原始语谱图(80×100×n)作为2D CNN的输入并将原始语谱图规范化为80×100×n作为3D CNN的输入(n=4时)。
3 CNN结构
3.1 3D CNN
本文使用的三维CNN是对二维CNN的一种扩展。具体而言,3D CNN包括三个卷积层(Kernel):第一层卷积层包括8个3×3×3的卷积核;第二层卷积层有32个3×3×3的卷积核;第三层卷积层有40个3×3×3的卷积核。均采用SAME的补零方式,步长为1。
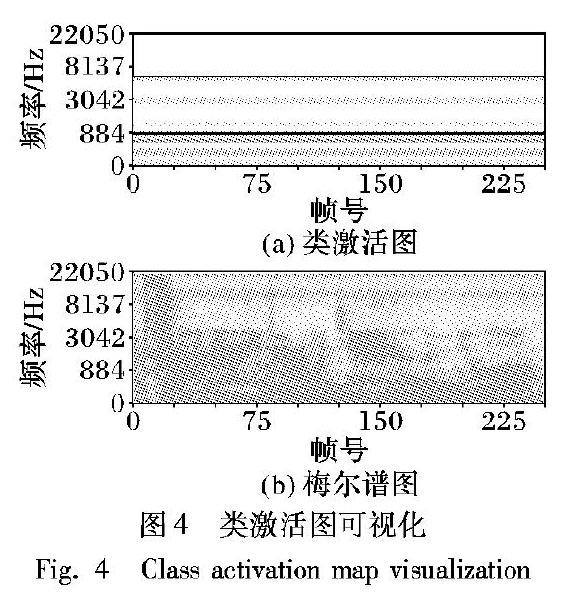
另外在每层卷积层后还包括批规范层[15]、激活函數层、最大池化层(Max Pooling)和Dropout[16]层。其中批规范层将前一层的值重新规范化,使得其输出数据的均值接近0,标准差接近1,在提高学习速率的同时防止其过拟合。批规范层的参数设置均相同,动量参数为0.99,epsilon为0.001。而激活层的激活函数均选用线性整流函数(Rectified Linear Unit,ReLu)。最大池化层均采用SAME补零方式,池化层各层的窗口大小分别为1×2×2、2×2×2、3×2×2,步长与窗口大小相同。为了防止过拟合,将Dropout层速率均设置为0.5。在进入全连接层之前,Flatten层将特征向量整合为一维。最后一层节点个数为2,用Softmax函数激活以预测有虫或无虫。详细结构如图1所示(n=5时)。
3.2 2D CNN
为了准确评估3D CNN的性能,本文搭建了与3D CNN类似的2D CNN模型。不同之处在于,2D CNN均采用二维的卷积核和池化窗口。卷积核大小均为3×3,步长为1;池化层窗口大小均为2×2,步长为2。其他参数设置与3D CNN相同。
4 实验结果与分析
4.1 实验平台
所有的实验均是在Google Colab平台上完成的。该平台搭载有一颗Intel Xeon @2.20GHz的处理器,13GB RAM以及一块20GB的Nvidia Tesla K80图形处理器,操作系统为Ubuntu。深度学习框架是以Python和Tensorflow[17]为后端的Keras。
4.2 评估指标
本文的性能通过准确率、F1分数以及受试者工作特征(Receiver Operating Characteristic, ROC)曲线[18]来进行评估。F1分数能够综合准确率(Precision)和召回率(Recall)两个性能指标综合评判,F1分数越高,则模型的效果越好。准确率、召回率和F1分数的计算方法如式(5)(6)(7)所示。所有的指标均在测试集上计算。
Precision=正确有虫标签数预测有虫标签数(5)
Recall=正确有虫标签数实际有虫标签数(6)
F1=2×Precision×RecallPrecision+Recall(7)
4.3 参数选择
训练过程中,2D CNN和3D CNN模型均使用了AdaDelta优化器[19],损失函数为分类交叉熵(Categorical Crossentropy)函数。其中AdaDelta学习速率设置为1.0,epsilon参数设置为10-8。将整个数据集按90%、5%、5%的比例分为训练集、验证集和测试集。验证集用于超参数调节以及筛选最后的模型,测试集用于对模型最后的评估。为了避免训练过程中的过拟合现象,在训练66代(epoch)后停止训练。
4.4 不同分帧长度的网络性能
本文首先研究了不同分帧长度的输入对网络性能的影响。选择合适的分帧长度在本文中至关重要:过长会导致可训练的数据集减少,网络容易出现过拟合现象;过短则不能保证帧内有虫,从而导致标签错误。不同的分帧长度的网络性能以准确率、F1分数、真阳率(True Positive Rate,TPR)和真阴率(True Negative Rate,TNR)来表示(表1);6种分帧长度的ROC曲线如图2所示。结果表明在n=4、5、6时,网络性能较好。本文将准确率、F1分数和ROC曲线折中考虑,在n=5时模型性能达到最佳。
4.5 与2D CNN的比较
本文将3D CNN模型与2D CNN模型从准确率、F1分数和ROC曲线三个指标进行了比较。两种模型的详细配置如表2所示(“—”表示该层没有这个参数)。从表3可以看出,在准确率和F1分数两个指标上,3D CNN模型均胜过2D CNN模型。图3给出了两种方法的ROC曲线,可以看到3D CNN模型效果较好。
[6]YAZGA B G, KIRCI M, KIVAN M. Detection of sunn pests using sound signal processing methods [C]// Proceedings of the 2016 5th International Conference on Agro-Geoinformatics (Agro-Geoinformatics). Piscataway, NJ: IEEE, 2016: 1-6.
[7]ZILLI D, PARSON O, MERRETT G, et al. A hidden Markov model-based acoustic cicada detector for crowdsourced smartphone biodiversity monitoring[C]// Proceedings of the 23rd International Joint Conference on Artificial Intelligence. Palo Alto, CA: AAAI Press, 2013: 2945-2951.
[8]LIKITHA M S, GUPTA S R R, HASITHA K, et al. Speech based human emotion recognition using MFCC [C]// Proceedings of the 2017 International Conference on Wireless Communications, Signal Processing and Networking. Piscataway, NJ: IEEE, 2017: 2257-2260.
[9]POTAMITIS I, GANCHEV T, FAKOTAKIS N. Automatic acoustic identification of crickets and cicadas[C]// Proceedings of the 9th International Symposium on Signal Processing and Its Applications. Piscataway, NJ: IEEE, 2007: 1-4.
[10]DONG X, YAN N, WEI Y. Insect sound recognition based on convolutional neural network [C]// Proceedings of the IEEE 3rd International Conference on Image, Vision and Computing. Piscataway, NJ: IEEE, 2018: 855-859.
[11]KISKIN I, ZILLI D, LI Y, et al. Bioacoustic detection with wavelet-conditioned convolutional neural networks [J]. Neural Computing and Applications, 2018, Online: 1-13.
KISKIN I, ZILLI D, LI Y, et al. Bioacoustic detection with wavelet-conditioned convolutional neural networks [EB/OL]. [2018-12-28]. https://link.springer.com/article/10.1007/s00521-018-3626-7.
[12]ZHOU X, LI J, ZHOU X. Cascaded CNN-resBiLSTM-CTC: an end-to-end acoustic model for speech recognition [EB/OL]. [2019-02-01]. https://arxiv.org/pdf/1810.12001.pdf.
[13]SCHMIDHUBER J. Deep learning in neural networks: an overview[J]. Neural Networks, 2015, 61: 85-117.
[14]HUANG J, ZHOU W, LI H, et al. Sign language recognition using 3D convolutional neural networks[C]// Proceedings of the 2015 IEEE International Conference on Multimedia and Expo. Piscataway, NJ: IEEE, 2015: 1-6.
[15]IOFFE S, SZEGEDY C. Batch normalization: accelerating deep network training by reducing internal covariate shift [C]// Proceedings of the 32nd International Conference on International Conference on Machine Learning. Brookline, MA: JMLR, 2015, 37: 448-456.
[16]SRIVASTAVA N, HINTON G, KRIZHEVSKY A, et al. Dropout: a simple way to prevent neural networks from overfitting [J]. Journal of Machine Learning Research, 2014, 15(1): 1929-1958.
[17]ABADI M, BARHAM P, CHEN J, et al. TensorFlow: a system for large-scale machine learning [C]// Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation. Berkeley, CA: USENIX Association, 2016: 265-283.
[18]DOWNEY T J, MEYER D J, PRICE R K, et al. Using the receiver operating characteristic to asses the performance of neural classifiers [C]// Proceedings of the 1999 International Joint Conference on Neural Networks. Piscataway, NJ: IEEE, 1999: 3642-3646.
[19]ZEILER M D. ADADELTA: an adaptive learning rate method [EB/OL]. [2019-02-01]. https://arxiv.org/pdf/1212.5701.pdf.
[20]SELVARAJU R R, COGSWELL M, DAS A, et al. Grad-CAM: visual explanations from deep networks via gradient-based localization [C]// Proceedings of the 2017 IEEE International Conference on Computer Vision. Piscataway, NJ: IEEE, 2017, 1: 618-626.
This work is partially supported by the National Natural Science Foundation of China (61872143), the National Undergraduate Innovation and Entrepreneurship Training Program of China (201810251064).
WAN Yongjing, born in 1975, Ph. D., associate professor. Her research interests include intelligent information processing, image processing, pattern recognition, audio signal processing.
WANG Bowei, born in 1997, undergraduate student. His research interests include signal processing, data mining, machine learning.
LOU Dingfeng, born in 1960, professorresearch fellow. His research interests include entomological bioacoustics.
