
基于大数据的图书馆网络安全风险评估量化模型
2019-11-08 02:04张旭森
数字通信世界 2019年10期
张旭森
(长春工业大学人文信息学院,长春 130122)
系统中在对数字图书馆中各信息资产、薄弱点和威胁的风险赋值环节中单纯的采用人工赋值的定性评估方式,主观性太强,可能会影响最终的评估结果[1]。给出了风险评估结束后,各资产所面临的风险大小,并未给出各种资产所面临的风险的控制措施。因此量化模型对信息安全风险评估和其相关标准的研究就显得尤其重要。
1 基于大数据的量化模型设计
1.1 移动平均量化设计
首先设计移动平均量化模型。简单移动平均是最简单的技术分析工具[2]。计算简便可能会使它后续被广泛使用。某个区间的数量简单移动平均值可以通过这种方法进行计算。公式如下:

式中,q代表某个区间的图书总数;k代表区间;n代表图书在某一区间的相对位置。
移动平均量化是对某一区域的网络安全进行风险评估,能够迅速的了解这个区域的风险值。
1.2 因子去极值与标准化设计
移动平均量化后的数据为了能够方便数据进行统一的分析,还需要标准化和去除极值两个方面处理[3]。其主要的目的是使得不同因子之间风险度可以保持一致,方便放在一起进行回归,更好地进行分解。首先通过标准化将各个值在所有因子上进行标准化,再将超过三倍标准差的值赋值为3,这样做的好处是可以消除极端值的影响。公式如下:
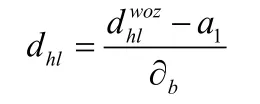
式中,dhl表示标准化后的序列,表示原始序列,a1表示原始序列的均值,表示原始序列的标准差。
因子去极值与标准化是计算风险值的平均值,通过平均值与标准值的比较来判定网络安全风险的大小。
1.3 波动量化设计
因子去极值与标准化后的数据即可用于风险评估,波动量化是用来衡量风险性的一个指标,波动数值越大风险越高;反之,波动数值越小风险就越小。公式如下:

可以看出,通过以上三个步骤的处理后,图书馆网络数据的安全风险评估已经完成,通过波动大小评估风险的高低。
2 与传统模型对比
在经典的CPPI模型之中,设某一时刻,根据图书馆网络自身的风险,设定了一个最低风险值,希望最低风险不低于设定值,并以最低风险值进行增加,实现无风险。公式如下:


表1 量化模型的对比
图书馆网络在同等访问量情况下,基于大数据的网络安全风险评估对比传统的模型评估更加准确、及时、便捷,也更贴近实际使用情况。
3 结束语
基于大数据对图书馆网络安全风险评估量化模型进行探讨,依托精准的计算,通过使用大数据建立网络安全风险的评估量化模型。研究论证表明,这几种量化模型对于评估图书馆网络安全风险具有快速、准确的特性。未来还需要设计更多更便捷的量化模型以便图书馆更高效的评估风险。
猜你喜欢
新世纪智能(数学备考)(2021年10期)2021-12-21
口腔护理用品工业(2021年4期)2021-11-02
河北理科教学研究(2020年3期)2021-01-04
语数外学习·高中版中旬(2020年10期)2020-09-10
中学数学杂志(2019年1期)2019-04-03
中国生殖健康(2019年10期)2019-01-07
小学生必读(中年级版)(2018年4期)2018-07-05
中国公路(2017年9期)2017-07-25
互联网天地(2016年1期)2016-05-04
汽车维修与保养(2015年8期)2015-04-17
