
基于社交网络和决策树的中国电影产业研究
2019-11-09 02:01杨秀璋于小民
电影文学 2019年5期
杨秀璋 夏 换 于小民 李 娜
(1.贵州财经大学 信息学院,贵州 贵阳 550025;2.贵州财经大学 贵州省经济系统仿真重点实验室,贵州 贵阳 550025;3.中国船舶工业系统工程研究院,北京 100036)
一、中国电影产业基于社交网络和可视化技术分析的必要性
随着人们生活质量的提高,精神文化需求也在不断增加,观看电影已成为人们重要的娱乐消费之一。中国电影市场在近几年飞速发展,电影产量、票房和人次持续增长,2017年全国电影总票房为559.11亿元,同比增长13.45%;城市院线观影人次16.2亿,同比增长18.08%[1]。目前,国内外利用数据挖掘或机器学习算法深层次分析电影数据的研究相对较少,而传统的电影数据分析方法主要是基于简单的票房和时间维度,基于剧情表现手法和视听特效的方法,其分析方法比较单一,不足以发现并直观地呈现电影数据深层次的规律,缺乏利用社交网络构建演员关系图谱并智能化推荐符合观众口味的电影[2],没有结合机器学习算法挖掘影响电影票房和质量的相关因素。
针对这些问题,本文提出了一种基于社交网络和决策分类的电影数据分析方法,并结合可视化技术直观地反映影响电影票房和质量的多种因素。本文旨在分析出影响中国电影市场票房和质量的电影类型、演员阵容、制作团队等,从多个维度挖掘中国电影市场的特点,利用决策树分类算法预测电影的口碑,寻找电影票房、电影质量和市场影响力之间的关系,并通过可视化技术进行直观的展现。
本文实验数据集是豆瓣网评分前250部的电影,中国电影网票房前500部的电影以及近十年中国电影市场的相关数据。主要步骤是:采用Python、Selenium和XPath技术自定义爬虫抓取电影网站的相关数据,构建词云、决策树等模型分析电影信息,从多种角度挖掘影响电影票房和质量的因素,根据所提取的特征预测电影的观众口碑。实验结果表明,本文提出的算法有效地挖掘出中国电影市场有价值的信息,包括具有票房号召力的演员,拍摄电影质量较高的演员和电影公司等;该方法可以给投资方和导演们提供电影拍摄的题材、演员和上映时间建议,具有重要的理论研究意义和实际应用价值,可广泛应用于电影市场分析和数据挖掘领域,更好地优化中国电影产业,为观众提供更好的精神食粮。
二、中国电影产业相关研究进展
中国电影产业在过去取得了飞速而持续的增长,新闻出版广电总局电影局数据显示,2017年中国电影总票房为559.11亿元,同比增长13.45%,而同一时期北美增长只有7%,全球仅为5%,中国电影市场已成为仅次于北美地区的全球第二大电影市场。2017年全国生产电影共计970部,其中故事片798部、科教电影68部、动画电影32部、特种电影28部、纪录电影44部。中国电影市场整体朝着多题材、多样化、多类型的创新格局发展,全年共有13部国产影片票房超过5亿元,6部国产影片票房超过10亿元,其中影片《战狼2》以56.8亿元票房和1.6亿观影人次创造了多项市场纪录,成为国产电影的突出亮点,显示着中国电影新力量不断成长壮大[3]。
与此同时,由于电影具有生命周期短暂、呈季节性波动等特点,影响电影票房和质量的因素多种多样,包括国民经济增长速度、民众消费水平、导演和主演的影响力、剧本的好坏、电影制作水平及电影在网络中的口碑等;而国内关于电影市场的研究相对较少,传统的分析方法不足以发现并直观地呈现电影数据深层次的规律,市场上也缺乏一个关于中国电影市场的数据分析和可视化展示体系[4]。
近年来,以互联网、大数据和人工智能为代表的技术不断应用于各行各业,互联网引发的评论口碑和影评分数极大影响了后续消费者的购买决策,因此通过大数据等技术来优化中国电影市场,探究电影评论信息和评分对电影票房的影响备受关注[5]。本文希望通过对国内外相关研究进行综述分析,结合机器学习算法分析影响电影市场的主要因素,通过社交网络和时间维度获取影响电影票房和提升电影质量的内核,从而为国内电影市场的深入研究提供借鉴,挖掘出中国电影市场的规律[6]。
目前国内外常见的一些电影分析方法是基于市场规律、机器学习和情感分析的。在电影数据分析上,龚晓等[7]基于SPSS工具利用层次聚类算法对20部电影数据进行聚类分析。王铮等[8]基于Logit模型分析影响电影票房的因素。周静等[9]运用社交网络分析方法对中国电影圈近十年主要的导演和演员之间的合作网络进行了描述和分析,运用双模网络分析方法得出中国电影江湖中存在“派系”的特点,即同一地区的导演与演员更愿意在一起合作。Jedidi等[10]利用有限混合回归方法对影片的周票房进行了聚类分析,把电影划分为四大类。李波等[11]对我国电影市场的生命周期进行分析,建立了考虑季节性因素的Gamma需求模型,并应用于电影观众人数衰减研究。章胤等[12]基于k-means和关联度分析方法对数据进行聚类分析并挖掘关联词。
在影评情感分析上,侯乃聪等[13]从网络口碑的情感倾向、评论数量、有用性和有效性四个方面构建了系统的网络口碑评价指标体系。雷鸣等[14]提出了基于评论情感分析的协同过滤推荐算法,通过对电影评论进行情感分析,构建准确的用户兴趣模型。殷复莲等[15]提出了基于词向量的情感分析方法,该方法在短文本分类上效果较好,准确率有所提升。涂小琴[16]通过Python抓取豆瓣网站评论数据进行情感倾向性分析,获取PMI最高的15个词语。孙春华等[17]基于文本情感分析方法分析电影预告片在线投放对票房的影响。
在可视化分析上,张鑫等[18]提出了一种基于大数据的面向电影投资制作、营销推广、放映拍片的电影分析决策系统。许冰晗等[19]基于Movielens电影数据进行了可视化分析,设计了一系列相互关联的可视化视图,从多个角度发现电影流派的规律。陈豪[20]基于Hadoop大数据平台和Python语言,从多角度可视化分析电影数据。
这些传统方法通常是利用折线图来分析时间维度上票房的增长情况,通过相关模型来分析观众和评论之间的关系,或是从文学视角研究电影的规律,而没有从多个角度去深层次挖掘电影类型、电影评分、电影票房、电影质量和观众口碑之间的关联,没有深入剖析中国电影发展的影响因素。本文将引入社交网络、决策分类、WordCloud等方法,结合可视化技术从多个角度深层次挖掘电影数据的规律,更好地优化中国电影产业,为投资方和导演们提供决策。
三、中国电影产业分析及可视化研究过程
(一)系统架构
本文旨在对豆瓣网评分Top250部电影、中国电影网票房前500部电影及2018年热门电影进行数据分析,其算法系统框架如图1所示。主要包括数据抓取、数据存储、数据预处理、数据分析和实验评估五个步骤,具体流程如下:

图1 电影数据分析系统框架图
1.首先采用Python语言中的Selenium和XPath技术抓取电影数据。
2.提取电影相关的特征并存储至本地,包括演员阵容、电影名称、制作公司、电影票房、上映时间、电影类型、评论及评分等。
3.分别对数值数据和文本数据进行预处理操作,包括异常值处理、数据清洗、中分分词等。
4.数据分析主要包括可视化分析和机器学习分析两块,通过Echarts、社交网络、热点词云等直观地展示影响电影市场的因素,利用决策树分类算法挖掘深层次的电影规律。
5.最后对实验结果进行评估,并得出结论。
(二)数据采集
本文使用基于Python语言的Selenium、BeautifulSoup、Xpath技术抓取豆瓣网电影及中国电影网的电影信息,通过分析网页DOM树结构抓取指定的字段,再利用自动化测试技术模拟浏览器操作获取演员详情,并调用Python的第三方库将信息存储至本地Excel文件。图2是豆瓣网电影《肖申克的救赎》对应的页面,包括电影名称、导演、编剧、主演、评分、上映日期等字段,经过数据采集之后存储至本地如图3所示。中国电影网票房前10名的电影信息抓取至本地后如表1所示。

图2 豆瓣网电影《肖申克的救赎》信息
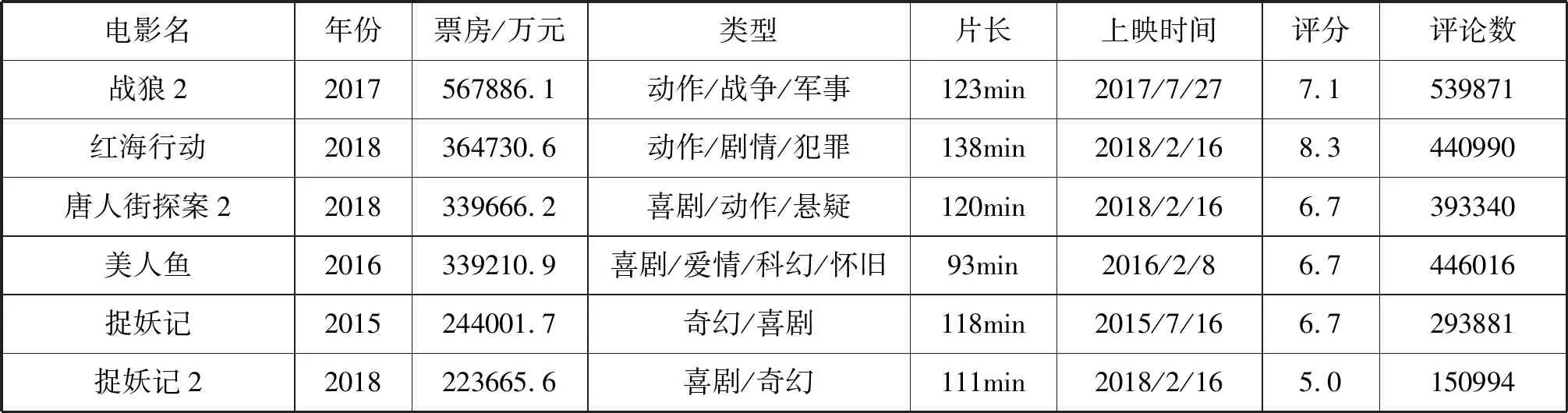
表1 中国电影网票房前10名的电影信息

续表
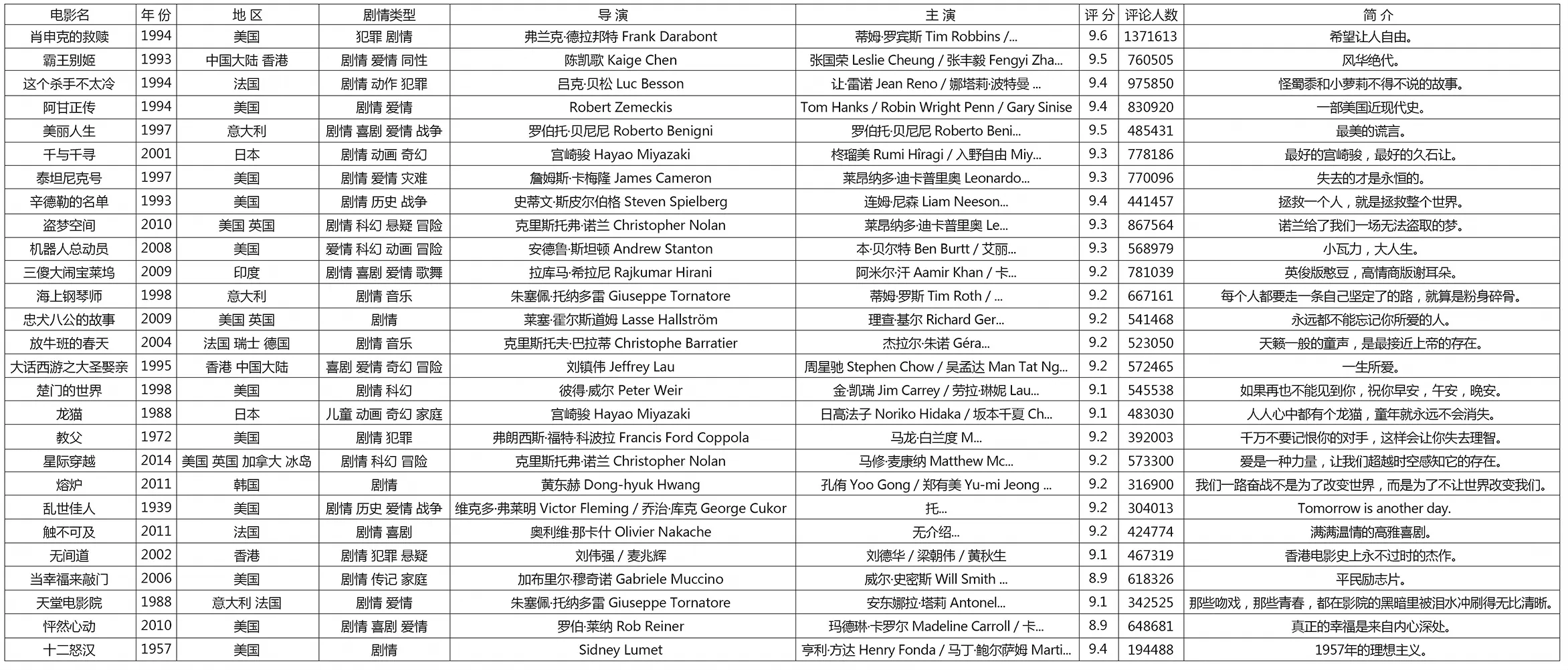
图3 数据采集豆瓣网电影评分前250部电影部分信息
(三)数据预处理
在进行数据分析之前,通常需要对所抓取的电影信息进行预处理操作,包括缺失值填充、异常值处理、数据清洗、中文分词、停用词过滤等步骤,其目标是为了得到高标准、高质量的数据,从而提升分析的结果。本文的数据预处理操作包括:
1.缺失值填充。在抓取电影信息实验中,存在电影片长、演员表等字段缺失的情况,这里采用Null标明缺失项,再进行数据定向抓取补全,部分字段采用手动填充。
2.异常值处理。所抓取的极少部分电影的票房信息不符合实际情况,比如《后来的我们》票房仅为2.1亿元,此时采用程序自动排序后定向校验。
3.数据清洗。原始数据中影片类型、导演、演员姓名存在特殊的符号,比如“·”“…”“/”等,此时需要定义停用词表对这些特殊的符号进行过滤。
4.中文分词。分词旨在将汉语句子切分成单独的词序列。本文所选用的工具是基于Python语言的结巴(Jieba)分词工具。同时,由于分词中会涉及固定词组或专有名词,如明星“潘长江”,它可能在分词之后会变成“潘”和“长江”两个名词,这会严重影响实验的效果。因此在使用结巴分词过程中,本实验添加了自定义词典,通过导入自定义词典实现专有名词和固定词组的分词,中文分词采用的是正向最大匹配方法。
(四)词云分析
“词云”是对网络文本中出现频率较高的关键词,予以视觉上的突出,使浏览网页者只要一眼扫过文本就可以领略文本的主旨,主要利用文本挖掘和可视化技术。个性化词云既是研究分析内容的一种表现方式,又是广告传媒的一种“艺术品”。在Python中,通过安装WordCloud词云扩展包可以形成快速便捷的词云图片。
本文主要对电影的演员姓名和幕后电影公司进行词云可视化分析,直观地形成热门关键词云层。其算法的分析流程如图4所示,包括导入数据集、读取文件、中分文词、特征词计算、词云可视化等步骤。

图4 词云分析流程图
(五)决策树算法
决策树(Decision Tree)是在已知各种情况发生概率的情况下,采用树状结构构建决策模型,判断每种可行性的概率。它是一种监督学习方法,常用来解决分类和回归问题。常见的决策树算法包括:分类及回归树(Classification And Regression Tree,简称CART)、ID3算法(Iterative Dichotomiser 3)、C4.5算法、随机森林算法(Random Forest)、梯度推进机算法(Gradient Boosting Machine,简称GBM)等。决策树构建的基本步骤如下:
第一步:开始时将所有记录看作一个节点。
第二步:遍历每个变量的每一种分割方式,找到最好的分割点。
第三步:分割成两个节点N1和N2。
第四步:对N1和N2分别继续执行第二步和第三步,直到每个节点足够“纯”为止。
本文将调用Sklearn.tree机器学习库中决策树分类算法对电影信息进行分类预测。
四、实验分析及结果评估
本文数据集采用Python自定义爬虫抓取豆瓣网电影及中国电影网的电影信息,所抓取的字段包括电影名称、导演、编剧、主演、评分、上映日期等,其中豆瓣网电影共抓取评分前250部的电影信息,中国电影网共抓取票房前500部的电影信息。紧接着进行异常值处理、数据清洗和中文分词,将缺失的数据填充,不符合逻辑的数据校正,不常用的词语和特色符号过滤,并导入专有名词词典进行中文分词,利用Jieba分词工具进行数据预处理。数据清洗为后面的分析提供良好的数据基础,接下来是详细的实验分析及结果评估。
(一)中国电影市场近十年综述分析
首先我们将对中国电影市场近十年的发展情况做一个概括性的可视化分析。表2是2008—2017年中国电影近十年的发展情况,包括国产故事片产量、国产片和进口片票房、票房过亿元影片数量。

表2 中国电影2008—2017年发展情况
实验使用Python的Pandas和Matplotlib库绘制如图5所示的柱状图。图中横轴为2008年至2017年这10年的时间流,纵轴为近十年国产故事片产量、国产片和进口片票房、票房过亿元影片数量。图5中每个类型的柱状图都有一定增长,其中,国产片票房从2008年的25.63亿元增长到2017年的301.04亿元,由此可见中国电影市场发展迅速。
(二)影剧情类型和产地的可视化分析
针对电影剧情类型和电影产地,本文使用Python和Echarts进行了可视化分析。图6是豆瓣网电影评分Top250的电影产地分析,其中产自美国的电影比例最高,占38.48%,近乎全球电影市场的半壁江山;其次是产自英国和日本的电影,占比均为8.94%;中国大陆占4.34%,中国香港占6.78%。总体而言,全球电影市场整体呈现“一超多强”的态势发展,我国在引进国外优秀电影的同时也需要提升自身的创新能力,吸取美国、英国、日本等影片的优点。
图7是中国电影网票房前500部电影的剧情类型饼状图,其中排名最高的三种类型分别是动作片、爱情片和悬疑片,分别占39.55%、23.91%和11.52%。这间接反映出我国的大部分观众对于这三种类型电影的喜爱程度较高,制片方或导演可以选择这三种类型,拍摄更为符合观众口味的电影。
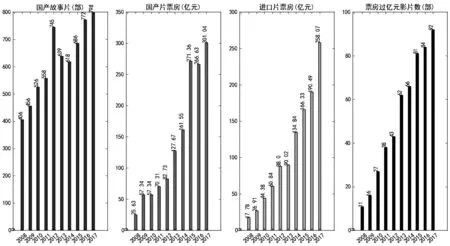
图5 中国电影近十年发展情况的柱状图
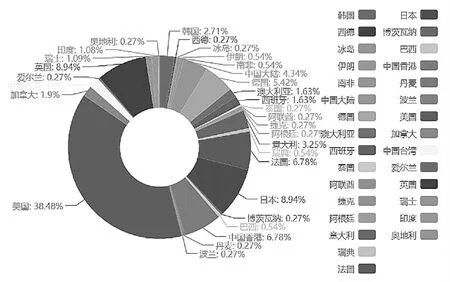
图6 豆瓣网评分Top250电影各地区的占比
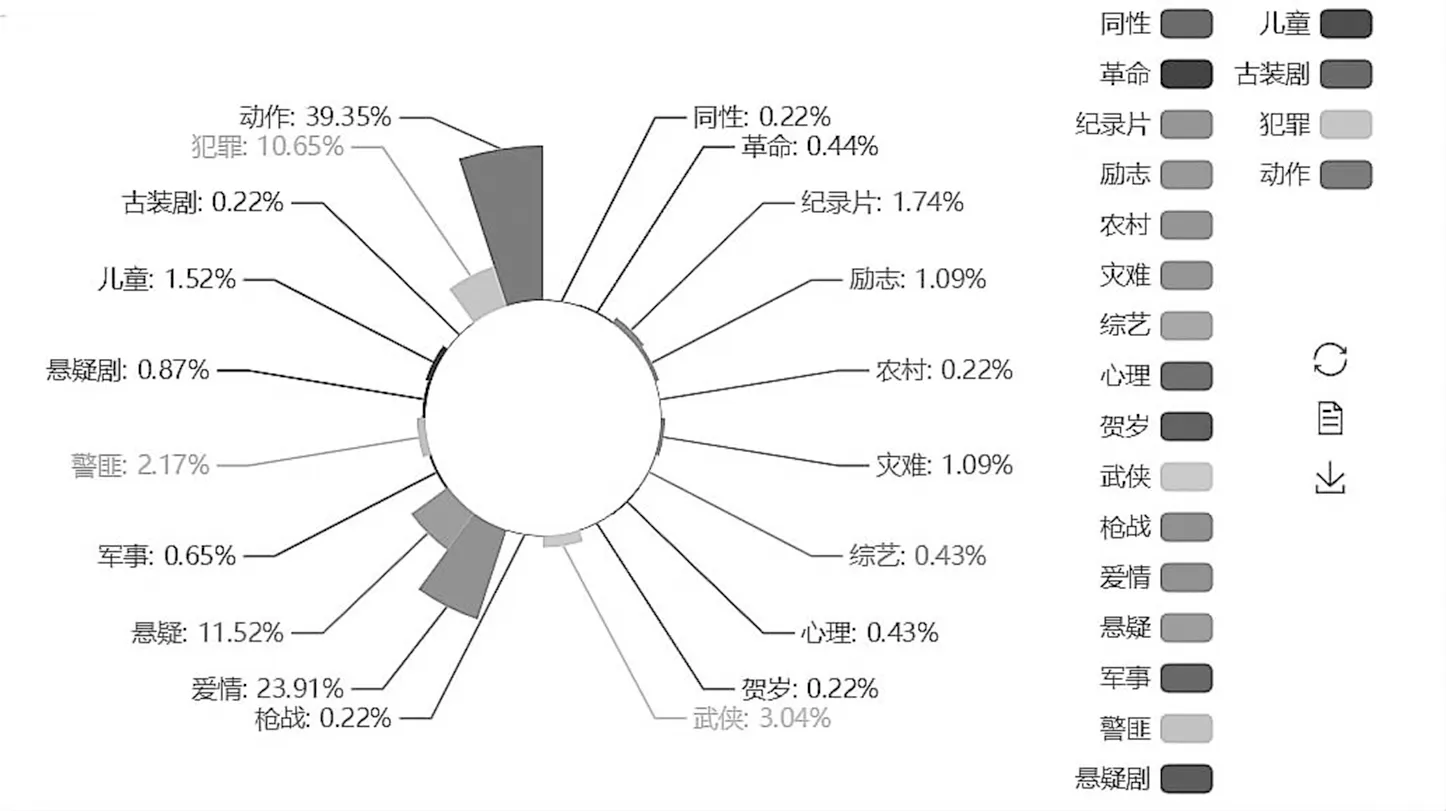
图7 中国电影网票房前500部电影剧情类型分析
(三)热门演员和幕后电影公司的词云可视化分析
本文调用词云技术,以票房最高的500部电影为样本,对热门演员和幕后电影公司进行词云可视化分析,得出如图8和图9所示的词云分布图。

图8 热门演员的词云图

图9 幕后投资公司的词云图
从图8中可知,演员“刘德华”“范冰冰”“张涵予”“杨幂”“成龙”“黄晓明”“柳岩”等词出现频数较高,直接说明了他们具有极高的票房号召力,更符合观众的口味。
表3是中国电影网票房前500部电影中,票房号召力最高的前十位演员,其方法是计算每名演员参演所有电影的平均票房。为防止个别演员参演数量较少,而票房较高的现象,本次统计结果均为参演十部以上电影的明星。
表3中最具票房号召力的演员包括吴京、井柏然、张涵予、周润发等,导演们可以考虑聘请这些演员来保证电影的基本票房。
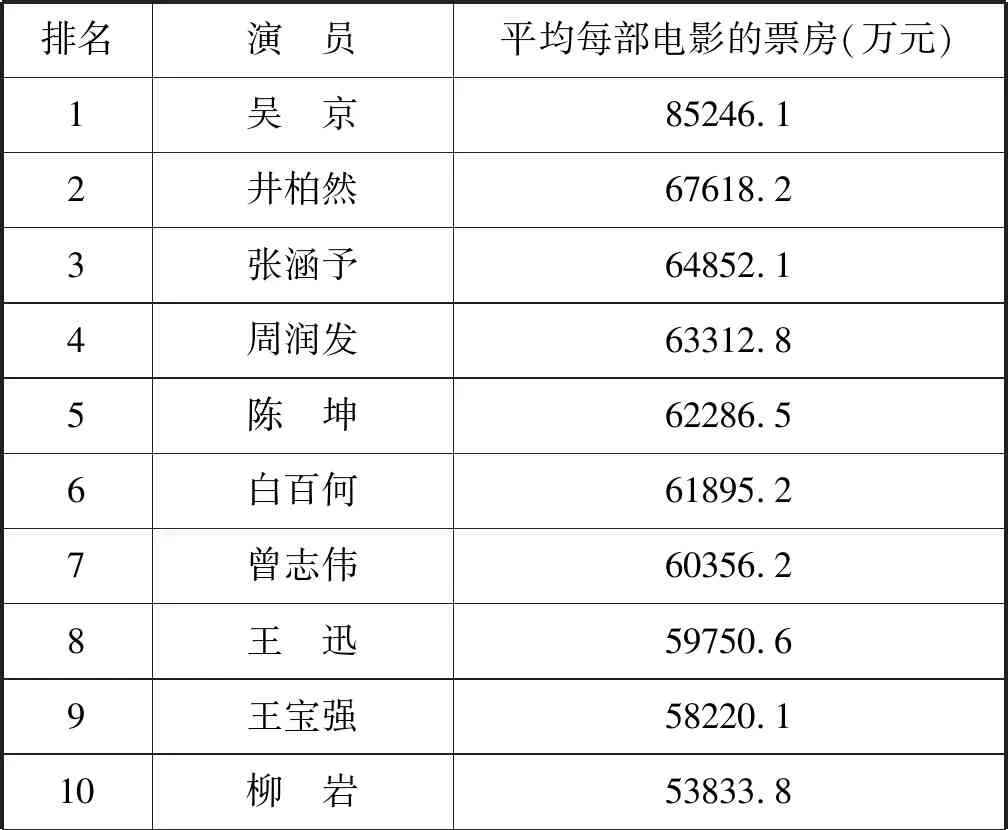
表3 最具票房号召力的演员表
表4是中国电影网票房前500部电影中,所参演电影评分最高的前十位演员,这间接反映出这些演员的演技不错。其方法是计算每名演员参演所有电影的豆瓣评分之和(满分为10分),再求平均数。其中排名最高的分别是陈坤、廖凡、徐峥、王学圻等。如果制片方或导演们追求电影的质量,一方面可以挑选更好的剧本,另一方面可以聘请这些“老戏骨”。
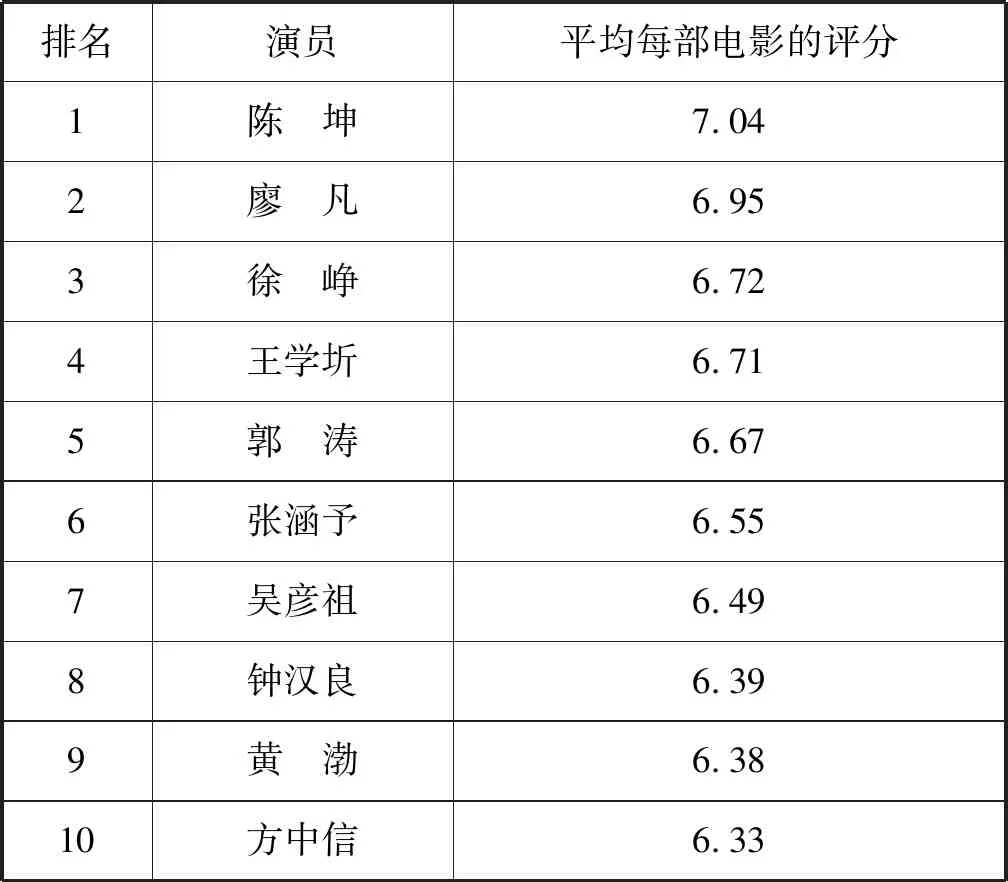
表4 平均每部电影评分最高的演员表
图9是幕后电影公司的词云分布图,其中“中国电影”“华夏电影”“万达影视”“华谊兄弟”四家公司的出现频数最高,分别为112次、77次、49次、49次,它们总共占据了中国电影市场的57.4%,这也符合Power-Law现象分布,即少数公司占据了极大数的中国电影市场。推荐演员们和这些电影公司合作,以提高参演率。
(四)黄金档期可视化分析
图10是中国电影网票房前500部电影的“时间—票房”分布情况,横轴为时间,纵轴为票房数。由图可见,电影票房在逐年递增,图中最高的点为《战狼2》在2017年7月27日创造的56.8亿元。
图10中部分区域散点比较密集,这其实是和中国三大黄金档期密切相关的。表5是2017年中国春节档期、暑期档期、国庆档期三大黄金档票房和观影人次的情况。
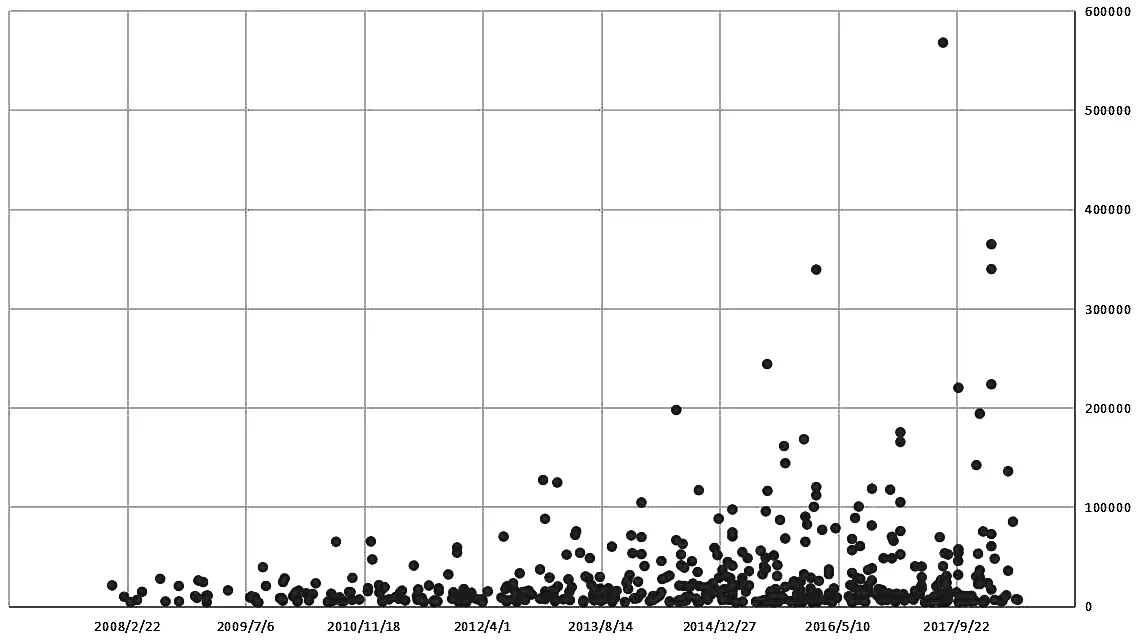
图10 电影“时间—票房”分布图
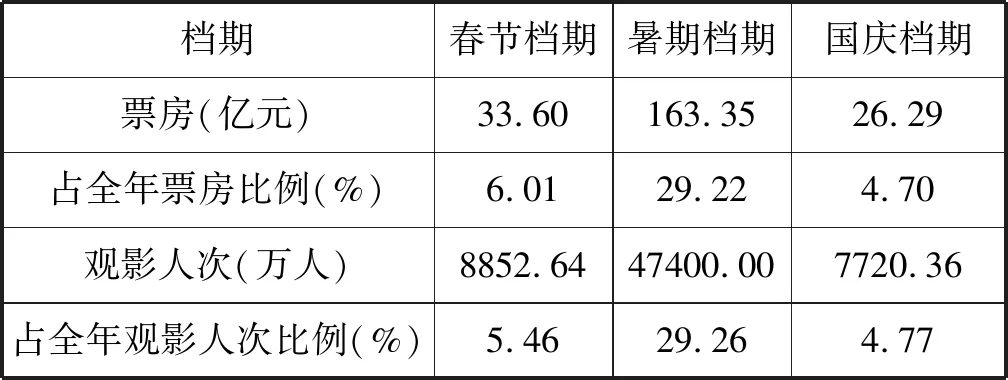
表5 2017年三大黄金档期观影情况
2017年我国三大电影黄金档期票房总产出约223.24亿元,占全年的40.00%;三大电影黄金档期观影人次约63973万人,占全年的39.49%。纵观全年中国电影市场,高票房的影片都于热门档期上映,“黄金档期”成为影视公司争夺的重要资源。同时,随着观众更加看重电影的质量和口碑,制作方应该逐渐从依赖档期向提升影片质量而转变。
(五)社交网络分析演员关系图谱
社交网络分析步骤如下:
1.首先计算中国电影网票房前500部的所有主演共现矩阵,其计算公式如下所示,当两名演员共同参演一部电影时,则认为共现并构建一条相关联的关系边,否则没有。

2.接着采用Gephi构建演员的关系图谱,构建的图形如图11所示。

图11 社交网络构建演员关系图谱
该演员关系图谱中共挖掘出1067名演员和8943条关系,它将具有相似关系的演员聚集在一起,比如图11左下角部分,放大后显示如图12所示。它展现了香港地区经常合作并且票房较高的演员之间的关系,包括“古天乐”“张家辉”“刘青云”“甄子丹”等主演以及“吴孟达”“秦沛”等经典配角。

图12 香港地区演员关系图谱
表6是中国电影网票房前500部电影参演前十名的演员信息,包括参演次数和参演的部分电影。
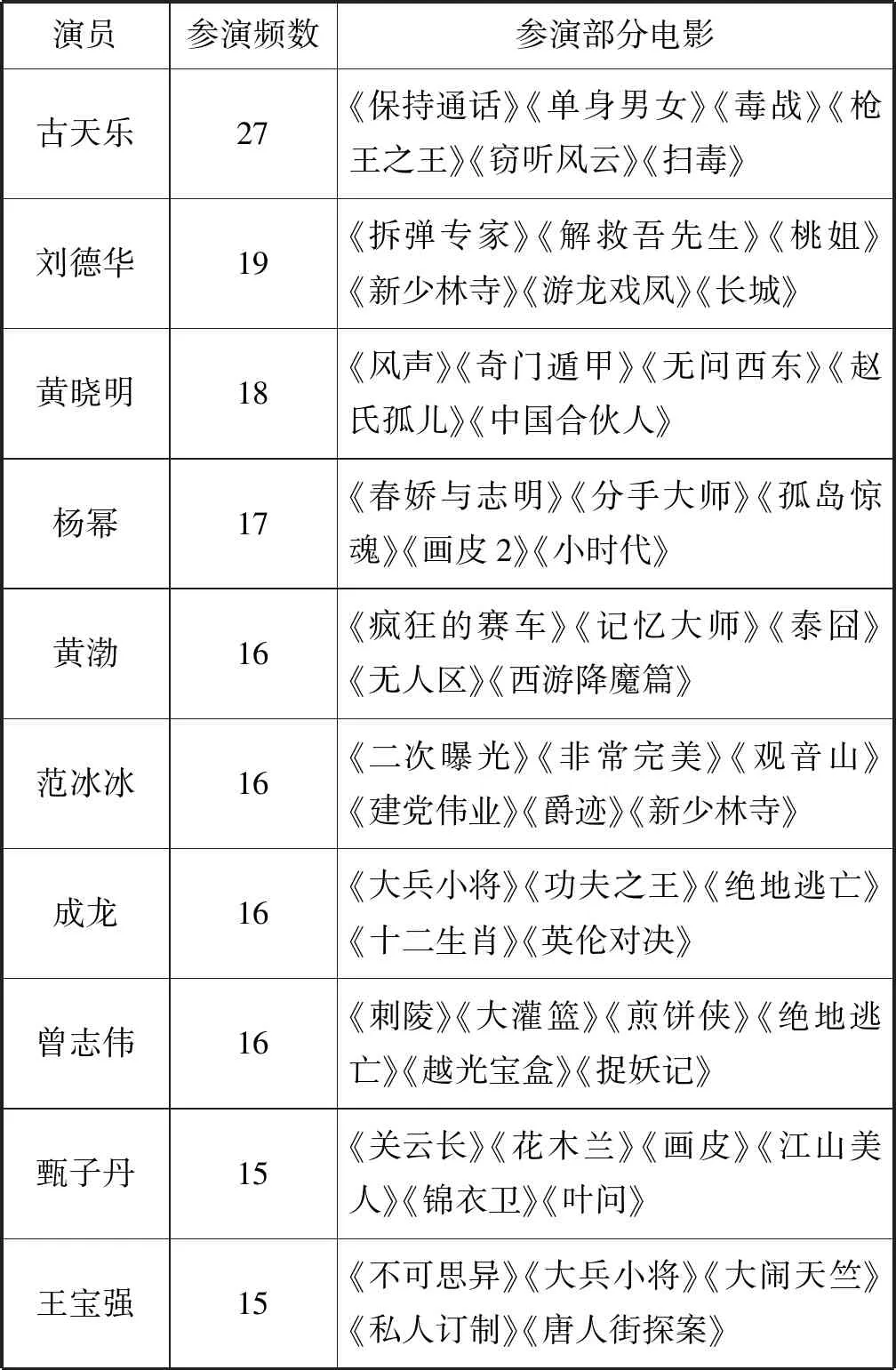
表6 中国电影网票房前500部电影参演前十名的演员信息
(六)决策树分类算法
本实验将对中国电影网票房前500部的电影进行决策树分类分析,根据电影的评分将其划分为口碑好和口碑差的电影,并预测电影的质量。本文将评分高于或等于6.0分的电影定义为口碑好的电影,而低于6.0分的定义为口碑差的电影(满分10分)。数据集包括八个特征,如下图所示。
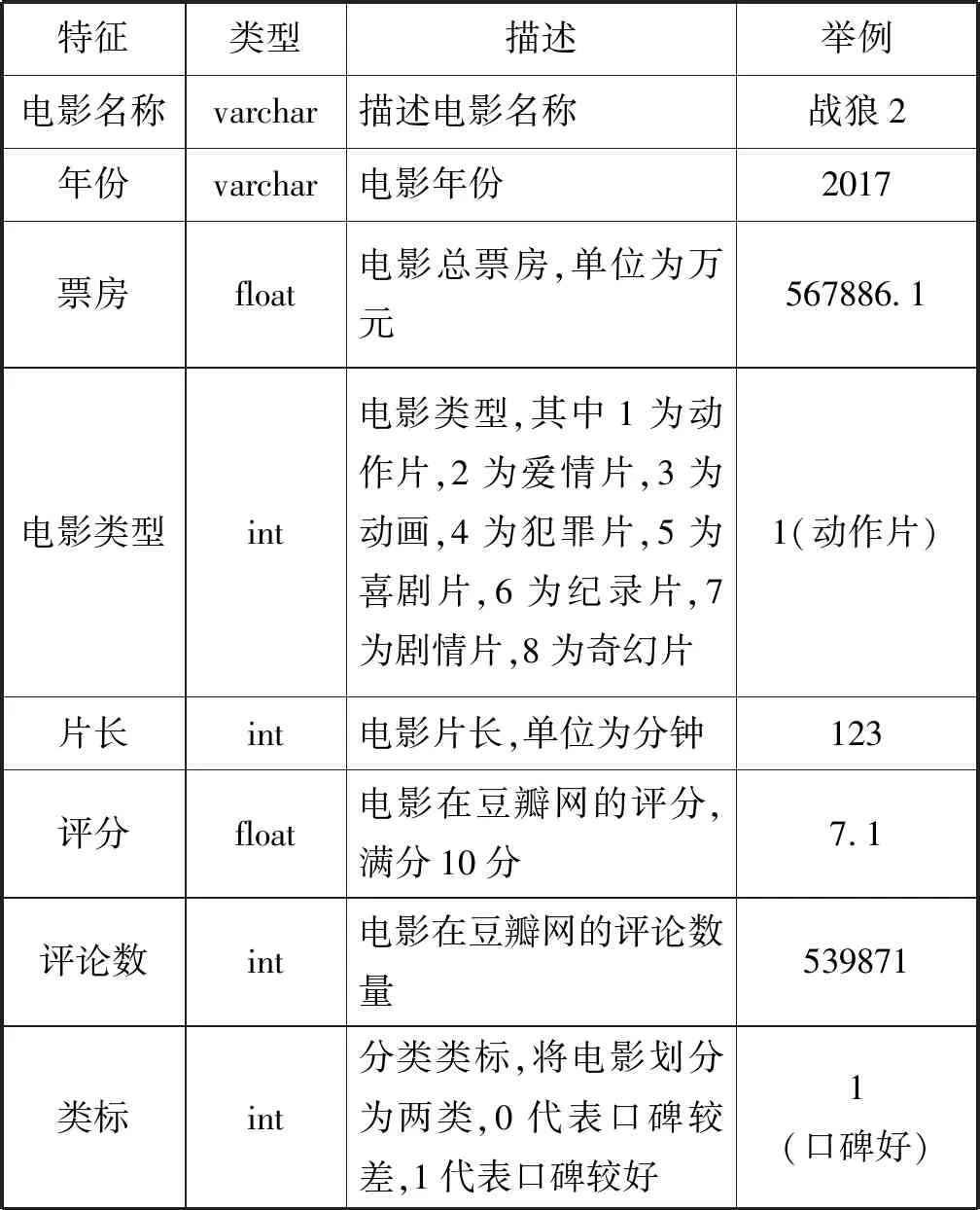
表5 数据集所包含的特征
本实验将数据集随机划分为训练集和测试集,其中训练集共350部电影,测试集共150部电影,实验采用准确率(Precision)、召回率(Recall)和F特征值(F-measure)进行评估,其计算公式如下:
(2)
(3)
(4)
其中,ni表示类别为i的文本数目,nj表示聚类j的文本数目,nij表示聚类j中属于i的数目。
决策树分析旨在对电影质量进行预测分类,划分为口碑好(类标为1)和口碑差(类标为0)的两类。实验结果如表6所示,其中口碑差的电影准确率、召回率和F值分别为0.9076、0.8429、0.8741,口碑好的电影实验结果更好,准确率、召回率和F值分别为0.9500、0.8941、0.9212。

表6 决策树分类实验结果
电影质量预测结果的部分电影如表7所示:

表7 决策树分类预测的电影结果
五、结 语
传统的中国电影市场分析方法较为单一,缺乏利用社交网络或机器学习算法分析电影信息,没有利用可视化分析直观地呈现电影深层次的规律。针对这些缺点,本文提出了一种基于社交网络和决策树的电影数据分析方法,并结合可视化技术多角度分析影响电影票房和质量的因素。得出如下结论:
1.中国电影市场近十年可视化分析得出:国产故事片产量、国产片和进口片票房、票房过亿元影片数量都有所增长,中国电影市场正迅速发展。
2.电影剧情类型和产地的可视化分析得出:我国在引进国外优秀电影的同时也需要提升自身的创新能力,吸取美国、英国、日本影片的优点。
动作片、爱情片和悬疑片是我国大部分观众喜爱的电影,制片方或导演可以多拍摄这三种类型的影片。
3.通过热门演员和幕后电影公司的词云分析,挖掘出最具票房号召力的演员表、最具演技的演员表;幕后电影公司“中国电影”“华夏电影”“万达影视”“华谊兄弟”共占据了中国电影市场的57.4%,符合Power-Law现象分布。
4.黄金档期可视化分析得出:全年中国电影市场,高票房的影片都于热门档期上映,“黄金档期”成为影视公司争夺的重要资源。
5.社交网络分析演员关系图谱共挖掘出1067名演员和8943条关系,它将具有相似关系的演员聚集在一起,并展现了各地区经常合作并且票房较高的主演和配角之间的关系。
6.决策树算法对中国电影网票房前500部的电影进行分类分析,根据电影的评分将其划分为口碑好和口碑差的电影,其算法的F值较高。
总之,本文提出的算法有效地挖掘出中国电影市场有价值的信息,该方法可以给投资方和导演们提供电影拍摄的题材、演员和上映时间建议。本文的研究成果具有重要的理论研究意义和实际应用价值,该算法可以广泛应用于电影市场分析、电影智能推荐、文本挖掘、社交网络等领域,更好地优化中国电影市场,为观众提供更好的精神食粮。
猜你喜欢
世界科学技术-中医药现代化(2022年3期)2022-08-22
云南化工(2021年8期)2021-12-21
电脑知识与技术(2021年13期)2021-07-19
海洋信息技术与应用(2020年1期)2020-06-11
成都信息工程大学学报(2019年3期)2019-09-25
传媒评论(2019年4期)2019-07-13
电子制作(2018年16期)2018-09-26
价值工程(2018年14期)2018-05-03
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
