
基于竞争性协同表示的局部判别投影特征提取
2019-11-09 03:42李静陈秀宏
智能系统学报 2019年5期
李静,陈秀宏
(江南大学 数字媒体学院,江苏 无锡 214000)
特征提取(或降维)[1-3]在计算机视觉和模式识别领域起着非常重要的作用,它通过把原始数据投影到低维空间而得到最具代表性的特征,其中主成分分析(PCA)[4]和线性判别分析(LDA)[5]是两个最著名的算法,但是它们很难确定数据的流形结构。
为获得数据的局部结构,出现了许多基于图的降维算法[6-12],包括局部保持投影(LPP)[6]、边缘判别分析(MFA)[7]和局部判别嵌入(LDE)[8]等。LPP是一种无监督学习算法,它忽视了数据的判别结构;而MFA和LDE则是有监督学习,它们试图找到一个投影子空间,在该子空间中同类样本点相互靠近,而不同类样本点相互分离,因此它们不仅考虑了数据的邻域结构同时也考虑了数据的判别结构。在基于图的流形学习中,关键是如何通过构造图来获得数据的本质结构。图的构造通常包括两步:第一步是决定样本间的近邻关系,第二步是为每对样本设置权重。通常,可通过近邻和-球邻域确定样本的近邻,但此类算法均依赖于参数或的选择。
基于协同表示的分类(CRC)[13]近年来得到了广泛而深入的研究,它使用所有的训练样本来协同表示测试样本,其表示系数描述了相应训练样本对测试样本的贡献,再依据残差对样本进行分类。Yuan等[14]提出了基于分类的协同竞争表示(CCRC),在计算各训练样本表示系数的同时确定每类训练样本的竞争能力,从而实现对样本的分类,该算法能很好地权衡训练样本的协同表示和竞争表示之间的关系。Huang等[15]提出了基于协同表示的局部判别投影(CRLDP),它利用协同表示获得表示系数构造样本的关系图,克服了近邻参数设置难的问题。Yang等[16]给出的基于协同表示的投影(CRP)是通过L2范数最小化问题求表示系数,但是CRP是无监督的。为了充分地利用标签信息来提高分类性能,Hua等[17]又提出了基于协同表示重构的投影(CRRP),虽然该算法是有监督的,但是它仅使用了全局信息而忽略了各类别之间的竞争性。
在以上基于CRC的学习算法中,表示系数有正有负,其中正表示系数描述了训练样本对测试样本的正面作用,对重构样本呈正相关性,而负系数则起着负面作用,对重构样本呈负相关性。由于正表示系数可以提取样本的主要特征,且具有一定的判别能力,故本文利用正表示系数来构造类间图和类内图,然后在考虑每类样本的竞争性以及样本标签信息的基础上,给出一种基于竞争性协同表示的局部判别投影特征提取(CCRLDP)。该算法不仅考虑了样本间的协同能力和每类样本的竞争性,还利用了样本的类别信息,因此可在一定程度上提高识别效率。
1 协同分类与局部判别算法
1.1 基于协同表示的分类(CRC)
CRC(collaborative representation based classification)的目标是使用所有的训练样本来协同地表示测试样本,其表示系数可通过以下优化问题求得:

1.2 局部判别嵌入的投影
在LDE(local discriminant embedding)中,分别表示同类样本与异类样本的邻接图,其中顶点集对应训练样本集,和分别表示同类样本之间和异类样本之间相似性的权矩阵,其定义分别为

2 基于竞争性协同表示的局部判别投影(CCRLDP)
2.1 局部结构图的构造
为了能充分反映样本重构时不同类样本的差异性,对每个训练样本建立具有竞争性的协同表示学习模型,即
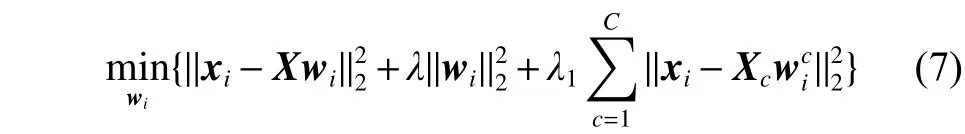
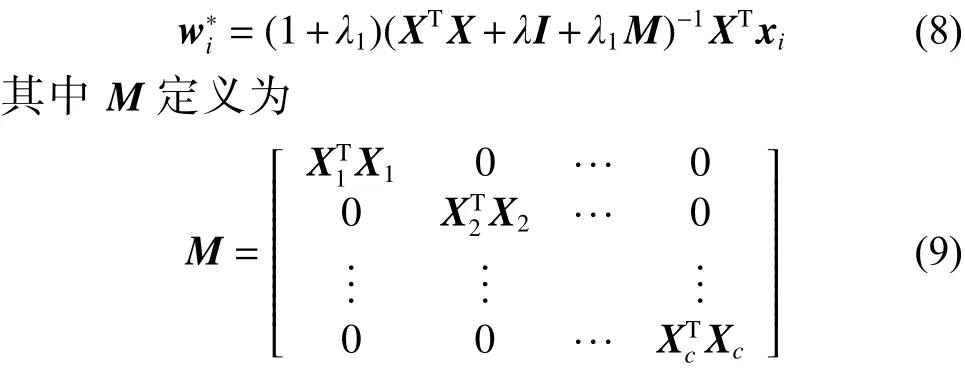
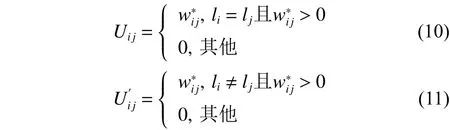
式(10)和式(11)表示保留样本间具有正相关性的系数,以此来得到两个稀疏矩阵和,这在一定程度上提高了算法的判别能力。由于样本对重构样本所做的贡献不同于样本对重构样本所做的贡献,所以权矩阵和一般情况下是不对称的。
2.2 CCRLDP的优化模型与算法
根据类内紧致图和类间分离图的权矩阵,定义类内紧致性和类间分离性:
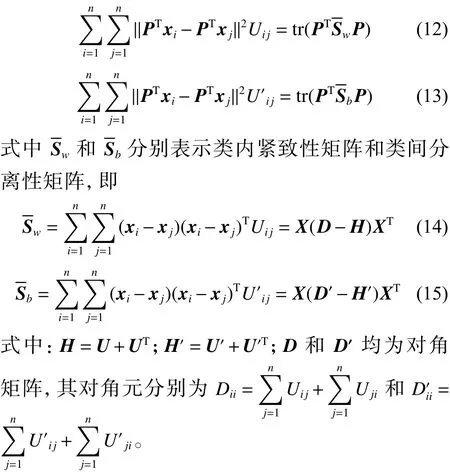
基于竞争性协同表示的局部判别投影法的目标就是找到一个最优投影矩阵,使得投影后样本的类间分离性极大而类内紧致性极小,即优化模型为
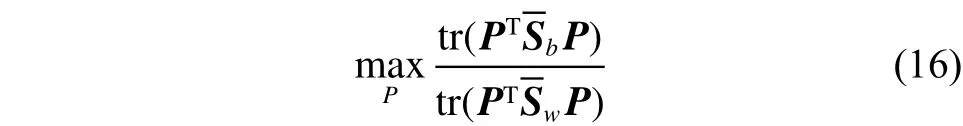
1)使用PCA降维;
2)求解式(7)或由式(8)得第 i 个训练样本的表示系数向量,再进行修正得到分量均非负的向量;
3 实验
为了验证算法的性能,本节选择数据集FERET、AR和Binalpha进行实验,并将本文CCRLDP算法与LPP、CRP、CRRP、CCRC和CRLDP等算法做对比,说明该算法的有效性和优越性。
3.1 数据集
FERET人脸数据集包含200个人的1 400幅人脸图像(每人有7幅图像),分别在不同光照、姿态和表情变化下采集的,每幅图像的大小为32×32。实验中,对图像加入密度为0.03的椒盐噪声。图1为样本集中部分人脸图像。

图1 加椒盐噪声FERET数据集部分样本Fig. 1 Partial sample of the FERET data set with salt and pepper noise
AR人脸数据集包含126人的4 000多幅人脸图像,它们分别是在不同光照、表情和部分遮挡情况下采集的。实验时随机选取40人,每人20幅图像,每幅图像的大小为32×32,并对图像分别加入大小为5×5、10×10和15×15的遮挡。图2为样本集中部分人脸图像。

图2 有不同大小遮挡的AR数据集部分样本Fig. 2 Partial sample of the AR data set with different size occlusions
Binalpha数据集包含10个手写数字和26个手写英文字母,总共1 404个图像,每幅图像的大小为20×16,图像中的像素值为1或0。图3为样本集的部分人脸图像。

图3 Binalpha数据集部分样本Fig. 3 Partial sample of the Binalpha data set
3.2 参数分析

表1 FERET数据集参数比较Table 1 Comparison of the FERET data set parameters%

表2 AR数据集参数比较Table 2 Comparison of the AR data set parameters%

表3 Binalpha数据集参数比较Table 3 Comparison of the Binalpha data set parameters%
3.3 实验结果分析
从上述数据集中每类随机选取L张图像作为训练样本,剩下的作为测试样本。对FERET数据集,L取5;对 AR数据集,L分别取5、8、10及 12;对Binalpha数据集,L分别取20、23及25。在LPP算法中近邻值取。对于FERET和AR数据集,子空间维数范围均设定为2~50;Binalpha数据集子空间维数范围设定为1~20。由前面的参数分析知,本文算法参数和在FERET数据集上设置为和;在AR数据集上为和;在Binalpha数据集上为和。将每个实验重复进行10次,并取平均值作为最终的识别率。为了提高计算效率,避免产生奇异问题,对原始数据利用PCA法做预处理,PCA的贡献率设置为98%,使用最近邻分类器(NN)进行分类。表4给出了本文算法(CCRLDP)与其他算法在有椒盐噪声FERET数据集上的最优识别率及其标准差,这里括号中数字为识别率最高时对应的特征维数。由表4可知,在加入椒盐噪声的FERET数据集上,CCRLDP的识别率远高于其他5种算法,这是因为CCRLDP算法充分利用了样本的标签信息和局部信息。另外,CCRLDP算法的标准差也较小,这意味着该算法比其他算法更稳定。表5为6种算法在Binalpha数据集上的识别率及标准差,这里的数据集没有任何噪声和遮挡。由表5可以看出,对于不同的训练样本数L,CCRLDP的识别率均优于其他算法,且识别率随着训练样本数的增加而增加;另外,有监督学习算法CRRP、CRLDP和CCRLDP的算法性能高于无监督学习算法LPP和CRP,因为无监督学习算法没有利用样本的标签信息,而在CRLDP算法中,由于没有考虑样本之间的竞争能力和正系数的作用,其判别信息较少,因此它的识别率低于本文算法。

表4 加噪FERET数据集上6种算法识别率及标准差Table 4 Recognition rate and standard deviation of six algorithms on the noisy FERET data set

表5 Binalpha数据集上不同训练样本数时6种算法识别率及标准差Table 5 Recognition rate and standard deviation of six algorithms on the Binalpha data set
由表6可见,在遮挡和训练样本数不同的情况下,CCRLDP算法的识别率均优于所有其他4种算法。在同一种遮挡之下,CRRP、CRLDP和CCRLDP这3种算法的识别率均随着训练样本数L的增大而增大;而对不同尺寸的遮挡,随着遮挡尺寸的增大,各算法的识别率在一定程度上均有所降低。CCRC是一种分类算法,直接通过测试样本求其系数,但是当输入图片的尺寸比较大时,算法的复杂度将会特别高,而且由表6可知CCRC的鲁棒性比较弱。表7给出各算法在不同数据集上的计算时间,在大多数情况下,本文算法的计算速度高于其他算法,个别算法的计算时间虽然少,但是其识别率远低于本文算法。综上考虑,本文算法优于其他对比算法。
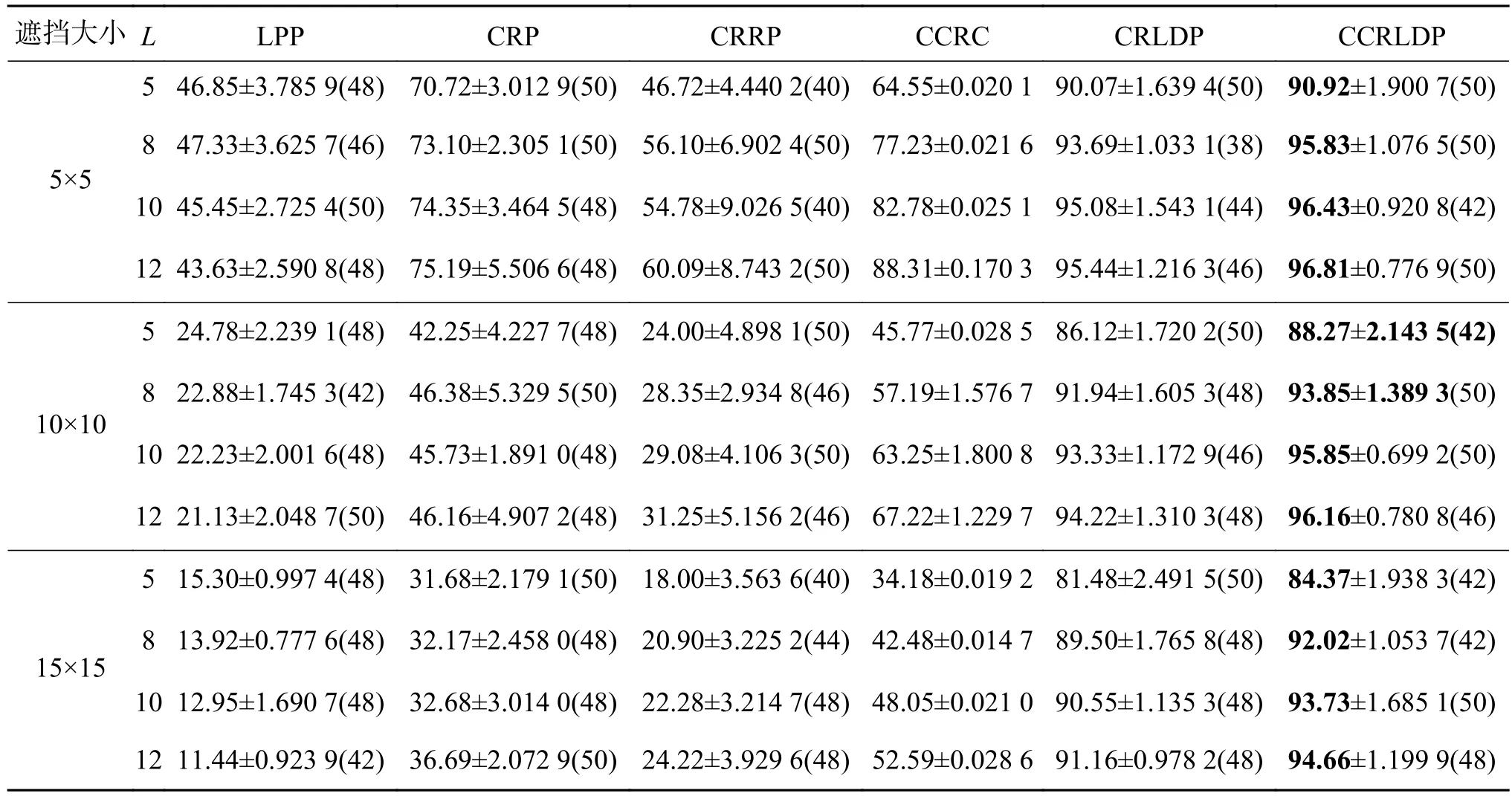
表6 AR数据集上不同大小遮挡和不同训练样本数时6种算法识别率及标准差Table 6 Six algorithms for recognition rate and standard deviation of different size occlusions and training samples on the AR data set %

表7 各算法在不同数据集上的计算时间Table 7 Calculation time of each algorithm on different data sets s
图4中描述了除CCRC算法之外其他5种不同算法在各数据集上的平均识别率随特征子空间维数变化而变化的曲线(因为CCRC直接对测试集原数据进行分类,没有涉及特征的提取,即不存在维度变化问题)。随着特征维数的增加,各算法的识别率也在逐渐上升,对于大多数数据集来说,在第20维之后,CCRLDP趋于平稳,性能比较稳定;虽然CRLDP和CRRP均使用协同表示重构来表示类间分离性和类内紧致性的有监督学习算法,但CRLDP考虑了相同标签样本的局部紧致性和不同标签样本的局部分离性,具有一定的判别结构,因此其性能高于CRRP;CRP和LPP均为无监督学习算法,但LPP需要手动构造图,不能有效选择数据的本质结构,所以LPP算法性能次于CRP;另外,CRRP能充分地利用样本的标签信息,故其性能优于LPP。
总之,CCRLDP既考虑了数据的局部结构,又充分地利用了样本的标签信息,因此在构造局部结构图时不需要手动选取k值。由于CCRLDP得到的是具有稀疏性的类间图和类内图,所以对噪声具有一定的鲁棒性,因此它具有较高的识别率。以上结果表明,该算法能提取更多具有区分能力的特征,从而能提升其识别性能。

图4 不同数据集上5种算法的识别率Fig. 4 Recognition rate of five algorithms on different data sets
4 结束语
本文通过考虑不同系数在对样本重构时的表现,采用竞争性协同表示的思想来构造类间分离图和类内紧致图,提出一种有监督的特征提取算法。该算法通过计算类内紧致矩阵和类间分离矩阵来刻画图像的局部结构并得其最优投影矩阵。与经典的基于流行学习的算法相比,以上算法不仅考虑了样本间的协同表示能力和每类样本的竞争性,还强调了正系数的作用,因此可大大提高其识别效率。
猜你喜欢
四川大学学报(自然科学版)(2021年6期)2021-12-27
科技创新与应用(2020年6期)2020-02-29
中国听力语言康复科学杂志(2019年3期)2019-06-24
听力学及言语疾病杂志(2019年3期)2019-05-24
中国交通信息化(2018年3期)2018-06-13
中国高新技术企业(2017年5期)2017-05-05
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
文苑(2015年9期)2015-09-10
新课程学习·中(2013年3期)2013-06-14
