
基于Hadoop的大规模网络安全实体识别方法
2019-11-09 03:42秦娅申国伟余红星
智能系统学报 2019年5期
秦娅,申国伟,余红星
(1. 贵州大学 计算机科学与技术学院,贵州 贵阳 550025; 2. 贵州大学 贵州省公共大数据重点实验室,贵州 贵阳 550025)
近年来,随着信息技术的快速发展,逐步进入了大数据[1]时代,网络空间安全面临全新的挑战,因此网络威胁情报这一新的安全技术应运而生。威胁情报[2](threat intelligence),主要是通过大数据、分布式系统或其他特定收集方式收集的用于评估和应用的数据集,针对一个现存的或新兴的威胁,可用于做出相应决定的知识。从2014年开始,威胁情报逐渐成为网络安全领域的热点,成为一种新的网络安全技术[3-4]。
当今社会正处于大数据时代,同时具有信息碎片化的特征,从而赋予了网络安全信息海量化与碎片化特点,导致网络威胁情报分析人员很难对信息进行获取和整合。因此,针对网络安全信息的碎片化和海量化的特点,将其进行过滤、分类以及关联,从而形成一个网络安全知识体系,衍生成为网络安全知识图谱。网络安全知识图谱构建的前提就是对信息进行抽取,信息抽取是网络安全知识图谱构建的最为关键的一步,其中最为关键就是网络安全实体识别。
网络安全实体识别是命名实体识别[5]中一种特定领域的实体识别,其目的是对网络安全领域专业的词汇进行分类;而通用领域的命名实体识别,主要识别文本中具有特定意义的实体,主要包括人名、组织名和地名等。目前,常见的是英文网络安全实体识别,针对中文的网络安全实体的识别研究工作很少。Jones等[6]在Bootstrapping算法指导下,实现了网络文本中的安全实体和关系自动识别;Joshi等[7]实现了一种网络文本数据的信息识别方法,利用CRF算法来识别网络安全相关实体及关系;Lal[8]提出了一种基于SVM算法的信息识别方法,实现了从网络文本数据中识别网络安全相关概念和术语;Mulwad等[9]设计了基于SVM算法的信息识别系统,检测和识别网络文本中的漏洞与攻击信息。
总的来说,网络安全实体的识别方法主要分为基于规则和基于统计的实体识别方法[10-12]。基于规则的实体识别方法对于较小规模的数据具有效果好和速度快的特点,但是规则的编写十分困难,且移植性较差。基于统计的识别方法利用人工标注语料进行训练,对具体语言特性依赖相对较少,移植性强,主要识别方法有隐马尔科夫模型[13](hidden Markov mode,HMM)、最大熵模型[14](maximum entropy markov model,MEMM)和条件随机场模型[15-16](conditional random fields,CRF)等。
目前,网络安全实体的识别主要存在以下难点:
1)网络安全实体数量众多且类型多种多样,难以满足自然语言处理领域中的命名实体定义,且不断地会有未登录词作为新的安全实体出现。
2)网络文本数据中的实体具有不同的结构,比如网络安全实体出现大量的嵌套、别名、缩略词等问题,没有严格的构词规律可以遵循。
3)在大规模数据条件下,基于机器学习模型的算法运行效率较低,单机上的安全实体识别算法难以满足安全实体识别需求。
针对上述问题,本文提出了基于Hadoop的Map/Reduce分布式计算框架,提出了与规则相结合的改进CRF算法实现对安全实体的高效、准确识别。本文的主要工作包括:
1)针对网络安全实体识别,对安全实体识别进行问题抽象及形式化描述,给出了基于Hadoop的网络安全实体识别框架。
2)分析网络安全数据中的实体结构特征,给出了网络安全实体识别规则,并进一步提出了改进的CRF算法,对算法进行分析。
3)在真实的数据集上,针对提出的网络安全实体识别方法,结合评测标准进行对比实验,结果表明本文提出的方法在准确率和效率上都有所提高。
综上所述,针对网络安全实体识别问题,本文基于Hadoop分布式计算框架提出改进的CRF算法,对数据集进行有效分割,解决网络安全实体识别的问题,实现准确识别网络安全实体的意义。
1 问题定义
网络安全威胁情报分析可为复杂网络环境下的网络攻防提供情报支撑。在网络威胁情报分析中,网络数据主要识别黑客组织、单位、漏洞、恶意程序等类型网络安全实体,如图1所示。

图1 Web文本数据中的安全实体识别Fig. 1 Security entity recognition in web text data
本文重点分析17类网络安全实体,图2给出了网络安全实体的本体模型[17-18],通过人工编写的方式构建了网络安全领域的本体模型,通过JSON语言实现。该模型是一个基于多维标签的网络安全本体模型,其中多维标签包括来源信息、属性信息、元信息等标签信息。

图2 网络安全实体的本体模型Fig. 2 Ontological model of network security entity
2 基于Hadoop的安全实体识别框架
针对海量的网络安全数据,本文提出基于Hadoop平台的网络安全实体识别框架,利用Map/Reduce[19]分布式计算模型实现高效的数据处理。本文针对大规模数据的网络安全实体识别的工作,主要运用了Hadoop中的HDFS和MapReduce这两个组件,对数据进行并行化处理。具体的抽取过程为:首先,将预处理的数据存储在HDFS中,HDFS会将这些数据切分成许多独立的小数据块,存储到若干个节点上,这些小数据块就会被多个Map任务并行处理;其次,在Hadoop上提交任务进行网络安全实体识别,MapReduce会为每个任务输入一个数据子集,同时调用CRF算法进行网络安全实体识别,Map任务生成的结果会继续作为Reduce任务的输入;最后,由Reduce任务输出最后结果,并写入HDFS。本文除了将识别出的网络安全实体存入HDFS,也将网络安全实体存入图数据库Neo4j,为将来构建网络安全知识图谱奠定基础。图3为网络安全实体识别的框架图。
1)数据预处理
本文主要对网页文本数据进行实体识别,因此在抽取之前要对数据预处理,处理过程如下:
①使用正则表达式对网页文本进行预处理,去除网页中的关于HTML的标签。
②通过使用Stanford CoreNLP提供的分词工具,将去除标签后的文本数据进行分词。
③构建语料库,由于网络安全领域没有统一的语料库,因此在对安全实体识别前,需要对其构建语料库。对已经分词的文本数据进行实体标注,特征实体时,可以通过程序先将所有实体标注为O,O表示未识别实体;然后进行网络安全实体标注,由人工判断手动标注为En,En表示安全实体。
④最后,训练网络安全实体模型。在训练过程中,根据训练工具的格式要求将前面的所有标注后的数据转化成特定的数据格式,然后利用CRF算法进行模型训练。
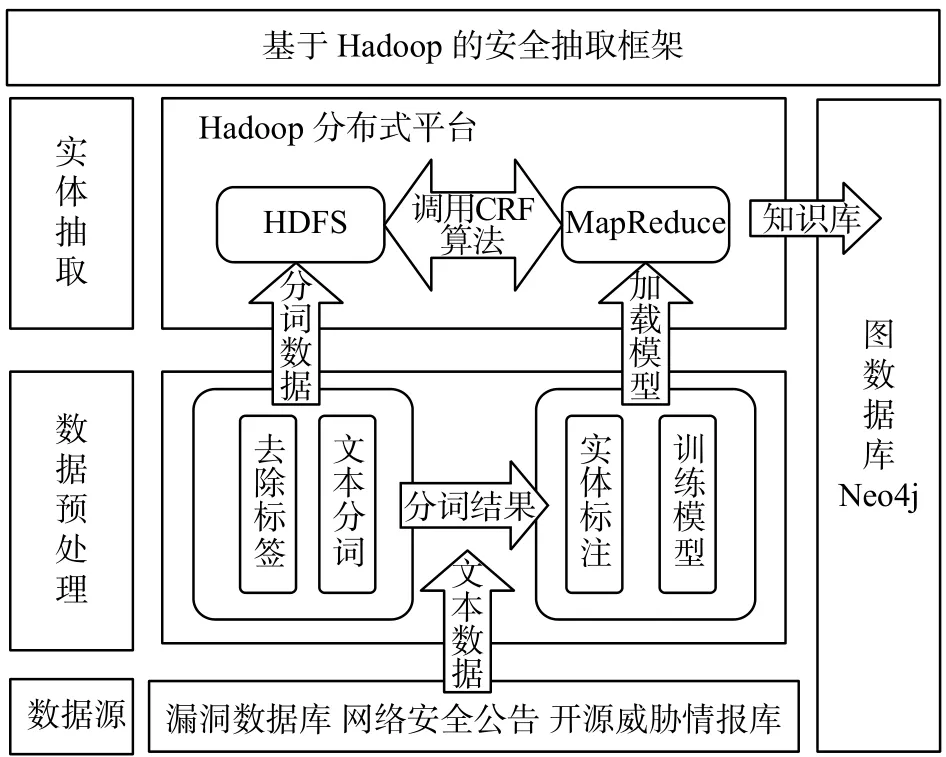
图3 网络安全实体识别框架Fig. 3 Network security entity recognition framework
2)中文网络安全实体识别
本文主要是针对中文网络文本数据的安全实体识别,数据的输入为中文分词文本数据,在此之前,需要利用CRF算法进行模型训练,训练数据主要来自于部分网络安全文本数据。对于中文网络安全实体数据,进行人工手动标注,标注完成后,将其放入训练工具中进行训练,实现中文网络安全实体模型的建立,最后通过CRF算法实现网络安全实体的识别。
在对网络文本数据进行分词的过程中,对于网络攻击事件,一般都是由“动词+名字”组合,才能完整而清楚描述一次攻击,如:XSS跨站脚本攻击、木马攻击、蠕虫蔓延等。所以在攻击事件名的分词上,本文采用基于规则进行识别,不进行分词,因为分词会导致对攻击事件的整体叙述在语义上描述不清楚,无法理解到底发生了什么样的攻击事件。
3 基于Hadoop的CRF改进算法
3.1 Hadoop算法描述
本文采用基于Map/Reduce的CRF算法并行化处理以缩短识别时间,实现大量数据的网络安全实体识别。MapReduce模型两个核心函数为Map函数和Reduce函数,它们的输入都为<key,value>键值对,按一定的映射规则转换为另一个或一批<key,value>。Map和Reduce任务函数有下列通用格式:
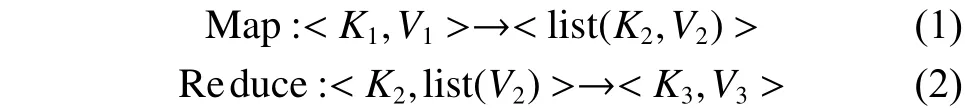
式中:Map函数将输入的数据元素转换成<K1,V1>形式的键值对,K1和V1的类型是任意的。每一个输入的<K1,V1>都会输出一批<K2,V2>,<K2,V2>是Map计算的中间结果,然后输入到Reduce 函数进行处理,输入形式为<K2,list(V1)>,输出为<K3,V3>。
在网络安全实体识别的过程中,对于每一个要进行安全实体识别的文本数据,首先将训练好的模型加载进来,然后在Map阶段调用CFR算法识别网络安全实体,最后在Reduce阶段将数据存储到HDFS和图数据库Neo4j。具体的基于Hadoop的网络安全实体识别算法如算法1所示。
算法1 基于Hadoop的网络安全实体识别核心算法:
1)调用Map函数;
3)CRFClassifier(Di) //调用CRF算法识别网络安全实体;
5)调用Reduce函数;
8)EntityStore.CreateNeo4j(key)//存储到Neo4j
实际上,在对网络安全实体识别进行评测时,不需要一个合并的输出,因为合并输出后会影响最后的评测结果,因此可以在对网络安全实体进行评测时省去Reduce阶段,那么Map函数的输出将不会有中间输出,数据将直接存储至HDFS。
3.2 CRF算法描述
在算法1中,CRF是网络安全实体识别的核心,分别对应算法1中的3)~6)步。CRF又称为马尔可夫随机域,最早由Lafferty等[20]于2001年提出,是一种对有序数据进行标注和切分的条件概率模型,拥有HMM和MEMM的特点。从形式上来讲,可以将CRF看作一种概率无向图模型,定义一个无向图G=(V,E),节点和边用v和e表示,在图G中,v∈V表示G中的节点,V表示节点集合,e∈E表示G中的任意一条E为边集合;X、Y是两个随机变量,P(Y|X)是定义在X的条件下的条件概率分布。如果在图G上,每个基于X的随机变量Y都服从马尔可夫特性,即
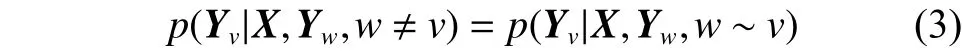
式中对任意节点v成立,则称条件概率分布P(Y|X)为条件随机场,式(3)中w~v表示两个节点w和v之间存在连接边,表示两个节点G=(V,E)在中位置相邻。Yv,Yw为节点v和w所对应的随机变量。
最常用和最简单的CRF图结构是线性链结构,可用于序列标注等问题,图4为线性链CRF。由图4可知,线性链CRF在各个输出序列节点之间做了一阶马尔可夫独立性假设,在给定一个输入序列X的标注序列的情况下,令表示被观察的输入序列,表示有限状态的集合。根据线性链CRF,线性链的Y的条件概率分布的形式为

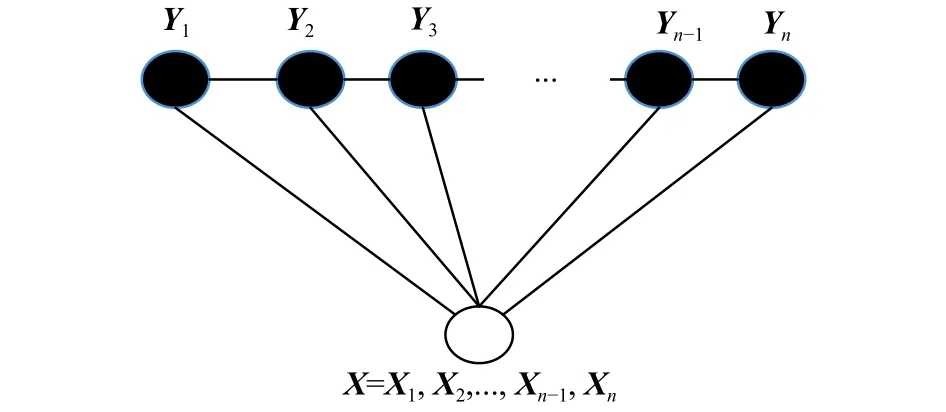
图4 链式条件随机场Fig. 4 Chain conditional random field
因此,线性链CRF可表示为
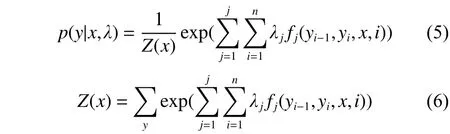
在CRF算法中主要有3个关键的问题,分别为特征函数的选择、参数估计和模型推断。CRF模型中特征函数的形式定义为,它是状态特征函数和转移特征函数的统一形式表示。

参数估计是条件随机场最为关键的问题,主要是从已经标注好的训练数据集学习条件随机场模型的参数,即各特征函数的权重向量λ,通常可以通过最大似然估计来实现。目前对于CRF模型参数进行估计的方法有3种,其中基于IIS和GIS两种算法是属于迭代的方法。目前广泛使用的条件随机场参数估计算法是L-BFGS算法,它是一种近似的二阶方法。与传统的迭代梯度方法相比,此方法的收敛速度更快。下面是LBFGS算法的计算公式:
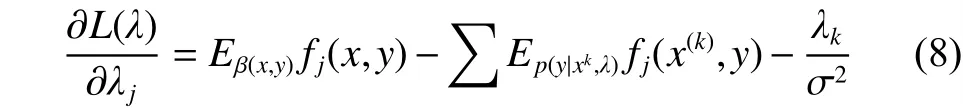
模型推断是在给定条件随机场模型参数λ下,预测出最可能的状态序列。
4 实验及分析
4.1 实验环境及数据集
本实验是在Windows环境下的Eclipse下进行开发的,使用Java编程语言。由于本实验是基于Hadoop的网络安全实体识别,Hadoop集群环境部署在实验室所提供的5台服务器上,Hadoop平台的拓扑图如图5所示,其中服务器使用的是Linux操作系统——CentOS 6.8,表1为5台服务器的硬件配置。
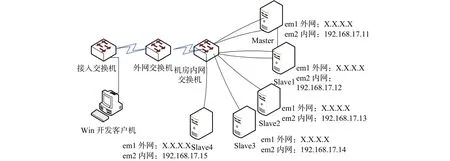
图5 Hadoop平台的拓扑结构Fig. 5 Topological diagram of the Hadoop platform
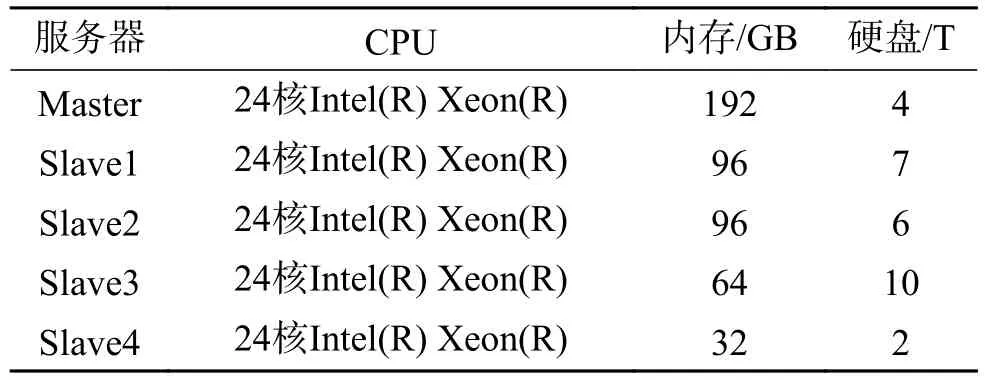
表1 服务器的硬件配置Table 1 Server hardware configuration
本实验采用的数据集主要来自于乌云漏洞数据库,数据主要包括2010~2016年公开的漏洞数据,共有40 292条漏洞数据。这些数据主要包括漏洞标题、漏洞缺陷编号、漏洞类型、漏洞作者、攻击事件名以及漏洞公开时间。本实验先对乌云漏洞数据集进行去标签,再进行分词,然后进行实体标注,形成了语料库。
为了对算法进行有效的测试,本文对网络安全实体进行人工标注。在实验中用语料库中的70%进行训练,30%进行测试,采用CRF算法,以词为单位进行网络安全实体识别。通过Hadoop平台,本实验对30%的语料库数据进行测试,对漏洞数据中的8种网络安全实体类型进行识别,图6为8种网络安全实体类型在语料库中的统计信息。

图6 语料库统计信息Fig. 6 Network security entity types
4.2 小规模识别率对比实验
本文以准确率P、召回率R和F值作为评价指标,具体的定义如下:

式中:N2表示识别正确的网络安全实体的总个数;N1表示识别出来的网络安全实体的总个数。

式中:N2表示识别正确的网络安全实体的总个数;N表示测试语料的网络安全实体的总个数。

本文利用CRF算法识别网络安全实体,将识别出来的网络安全实体作为候选网络安全实体,然后利用基于规则的方法,对候选网络安全实体进行修正,将修正过的结果和未修正的结果进行对比。本文利用基于规则的方法对基于CRF的网络安全实体的识别进行修正,实验过程中首先建立简单的规则,然后将规则加入到网络安全实体的识别中进行比较。本文制定了以下几条规则:
规则一:如果词的前缀是“腾讯”“优酷”“微软”等厂商名,且该词带有“漏洞”结束符,那么该词应标记为漏洞名称,例如“腾讯某分站地址跳转漏洞”。
规则二:如果词的前缀是“WooYun”,将此类词标记为漏洞缺陷编号。
规则三:如果词的前缀出现“SQL”“XSS”等词,且该词带有“注入”“攻击”“传播”“泄露”等结束符,那么该词应标记为漏洞类型,例如:“XSS跨站脚本攻击”。
经过以上规则对结果进行纠正,网络安全实体的识别效率都有所提高。图7是对修正和未修正结果的准确率的对比,图8是召回率的对比,图9是F值的对比。
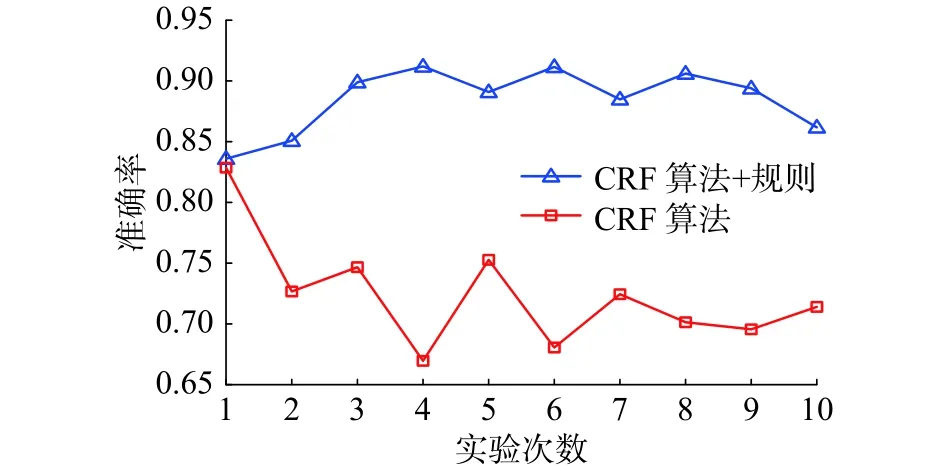
图7 准确率对比结果Fig. 7 Comparisons of precision of results
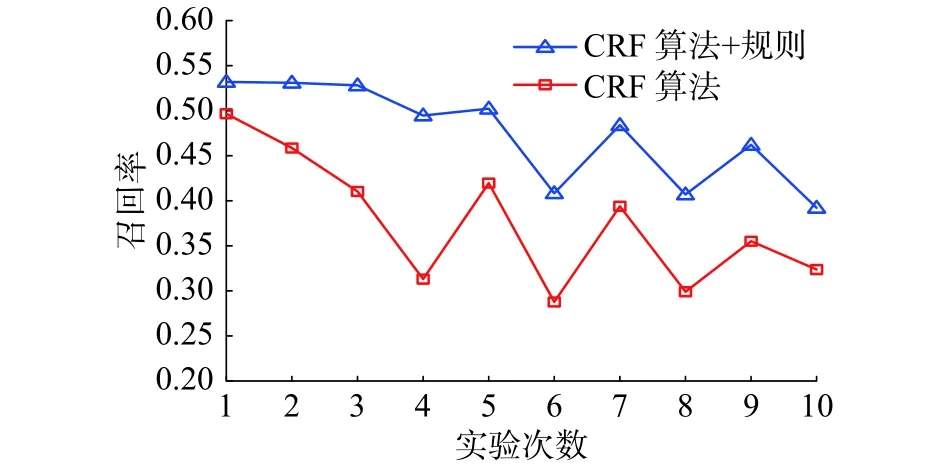
图8 召回率对比结果Fig. 8 Comparisons of recall results

图9 F值对比结果Fig. 9 Comparisons of F-value results
图7 ~9列出了网络安全实体10次实验的识别结果,从实验结果可以看出,在使用规则对于基于CRF算法的网络安全实体识别的结果进行修正,识别效果有了一定的提高。就准确率而言,基于CRF算法与规则相结合的准确率能达到85%以上,10次实验中准确率最高达到了91%。但是就召回率而言,从实验结果来看,识别效果比较低,主要是因为CFF模型泛化能力不够和训练的语料库非常小。
4.3 大规模对比实验
本实验采用Hadoop框架,主要利用MapReduce对大规模数据进行分割,对网络安全实体的识别并行化处理。本文将Hadoop安装在5个节点的集群中,文本数据块的大小为128 MB。为了更好地说明分布式计算效率,本实验在不同的数据规模下,基于不同的节点个数测试网络安全实体识别时间。实验中分为3个节点、4个节点以及5个节点,同时加上伪分布式集群。在Hadoop集群上,运用4组数据进行实验,4组数据大小分别为1.3 GB、6 GB、13 GB、28 GB。实验结果如图10所示。

图10 不同节点数下的运行时间对比结果Fig. 10 Comparison of running times for different node numbers
从图10可以看出,随着计算节点个数的增加,网络安全实体的识别时间也随之加快。在数据量为1.3 GB的时候,随着节点数的增加,网络安全实体识别时间变化不大,识别效率提高不明显。随着数据量的增大,在伪分布式的情况下,28 GB数据耗时近55 h,5个节点耗时近13 h,识别效率明显提高。
4.4 算法的可扩展性分析
本文提出的基于Hadoop的CRF算法的网络安全实体识别算法具有很好的扩展性。图11展示了28 GB数据的运行时间,从图中可以看出随着计算节点数的增加数据运行时间逐渐下降。实验证明,增加节点数可以有效增加网络安全实体识别效率,因此本文基于Hadoop的网络安全实体识别算法具有良好的可扩展性,适用于大规模数据的集群计算。
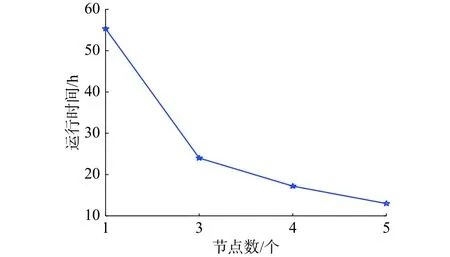
图11 28 GB数据运行时间对比Fig. 11 Comparison of 28 GB data running times
4.5 网络安全实体识别实例分析
为了进一步直观展示本文算法在网络安全实体识别方面的结果,安全实体词云图如图12所示。“DDOS攻击”“SQL注射漏洞”等网络安全实体,具有典型的中英文混合结构,传统的命名识别方法较少关注中英文混合结构的命名实体识别。通过词云图可以直观地看出,本文提出的基于规则的CRF算法能够有效处理中英文混合的网络安全实体,进一步提升了安全实体识别的准确率,为基于网络安全知识图谱的威胁情报分析奠定了基础。

图12 网络安全实体词云图Fig. 12 Word cloud map of network security entity
5 结束语
本文对网络安全实体识别的常用算法进行了总结,详细分析了基于CRF算法的网络安全实体识别方法,并针对大规模数据在Hadoop框架下对网络安全实体识别进行并行化处理。实验表明,本文采用基于Hadoop的CRF算法的网络安全实体识别,取得了良好的效果,并大大地缩短了识别时间。在后续的工作中,会考虑融合更多网络安全领域的知识使得安全实体识别具有更好的泛化能力,从而提高实体的识别率,并扩展至多机分布式平台,进一步提高性能。
猜你喜欢
今日农业(2022年13期)2022-09-15
文化创新比较研究(2020年13期)2021-01-14
天津外国语大学学报(2020年1期)2020-03-25
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
儿童时代(2016年6期)2016-09-14
中国卫生(2015年12期)2015-11-10
外语教学理论与实践(2014年4期)2014-06-13
