
小样本深度学习方法实现LED TV屏缺陷检测
2019-12-02 07:13
计算机测量与控制 2019年11期
(1.河源职业技术学院 电子与信息工程学院, 广东 河源 517000; 2.惠州学院 信息科学技术学院, 广东 惠州 516007; 3.惠州学院 电子信息与电气工程学院, 广东 惠州 516007)
0 引言
当前,液晶显示已广泛应用于电子生产与消费领域,液晶屏的质量直接关乎电子产品的整体品质。因此,在液晶屏的生产过程中,由工艺及环境导致液晶屏显示的诸如包括亮点、漏光、白点、异物、斑纹、BLOB(几何形态)、MURA、黑点、颜色不均、划伤、气泡、褶皱等缺陷问题。随着机器视觉在智能制造领域的进一步应用,目前的缺陷检测一改往日的人工检测手段,采用基于机器视觉的液晶屏检技术,大大地提升检测的效率及准确性。因此在智能制造企业,为保证制造企业顺利、高效且智能地完成各生产任务,投入了大量的工业机器人,并引入具有识别、定位与检测技术的视觉系统就显得至关重要。
当前,从事工业自动化应用之机器视觉领域的研究备受业界广泛关注,并取得了一定的成果。包括日本学者研究的弧焊机器人,澳大利亚大学机构研制的六自由度工业机器人,以及瑞典 ABB 公司推出的“第II代”拾取机器人等,都属于工业自动化应用之机器视觉技术的实践[1]。鉴于此,我国也陆续研制了码垛机器人和卸垛机器人等。然而,在电子制造业利用机器视觉实现LED自动化屏检的应用并不多见,与已有的技术应用仍存在一定的局限[2-4]。一般地,提高生产率、增加检测的精度与节省人力成本仍是制造企业首要考虑的重要议题[5],而机器视觉技术在工业机器人的应用正是当前智能制造的趋势之一。与已有检测技术不同,借助工业机器人在工业生产过程中智能屏检样例的积累与学习,对于BLOB(几何形态)、亮暗点、横竖线等三大缺陷进行检测,设计并实现了一种基于深度学习理论的增量检测算法,旨在发挥深度学习在计算机视觉技术检测方面的优势,业以提高工业机器人在智能制造检测效率与精度,并节省人力成本,最终提高企业的生产效率与产品质量。
1 检测思路
通常,深度学习是通过主动训练数据获取特征模型。然而,在缺陷检测中,考虑到缺陷种类的多样性,决定对已标注小样本数据集进行训练,得到具有初始参数值的粗特征模型进行缺陷识别。接着对已识别的缺陷产品保存到样本集,针对原有模型多次采用增量学习方法对参数进行调整,得到更为精确的模型,提升识别率。具体识别流程如图1所示。

图1 小样本缺陷检测与识别流程
2 数据集缺陷特征分类
一般地,在LED屏的工艺制造过程中,受外力挤压,很容易导致LED屏在灰度或色度显示不均匀出现污渍的Mura现象[6];而受静电或工艺参数等影响,易导致其电学特性发生变化,或电源线信号线发生断裂,使得屏幕在点亮时出现亮暗点。
为消除人类视觉存在的误区,可以采用光学检测方法[7],通过数字相机像素级光点的参数计算来改善LED TV生产在自动化屏检过程的准确性。因此,要实现基于机器视觉的智能屏检,必需完成液晶屏的点灯和外观检测过程,在像素级层面对LED TV的液晶屏出现的亮点、漏光、白点、异物、斑纹、MURA、黑点、颜色不均、划伤、气泡、褶皱等完成缺陷的检测。因此从宏观、微观的角度,依据缺陷的形状,可以将缺陷划分为点缺陷(像素缺陷)、线缺陷和面缺陷几类。图2为关于点、线、面形状缺陷类别。
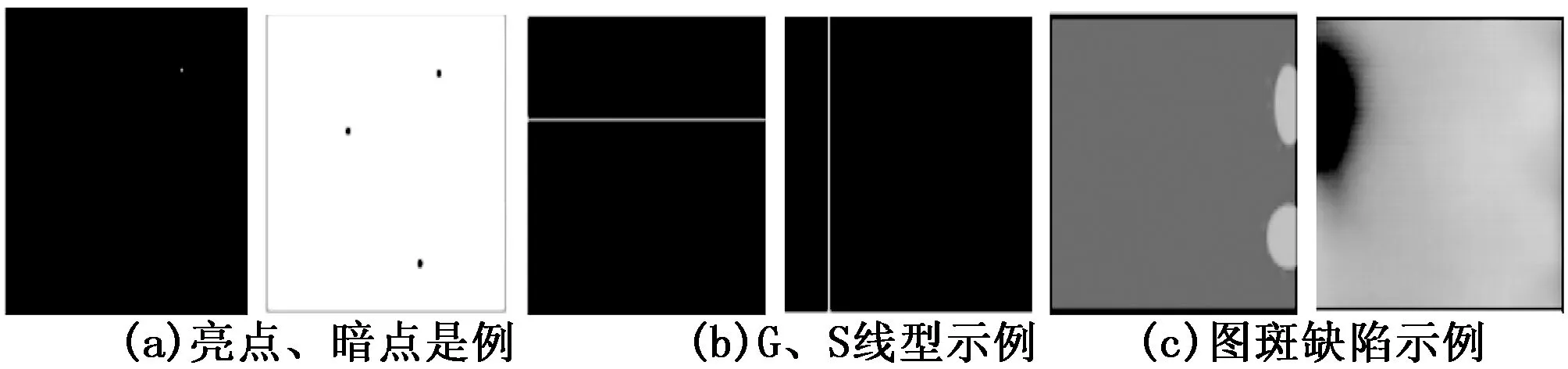
图2 点、线、面形状缺陷类别
3 融合迁移学习与FCNet的学习策略
较之以往的机器学习、人工智能,近年来深度学习引起了广泛关注,其沿用了神经网络分层结构,主要采用CNN卷积神经网络卷积层和池化层,根据需要串联多个卷积、非线性变换和池化有监督地训练所有过滤器中的权值参数,获得特征模型。深度学习是一种深层次的大规模网络结构, 针对海量数据进行训练,不断调整参数, 是一种主动学习行为,所以深度学习模型需要更长的训练时间,由此,研究模型的收敛速度就显得至关重要[8]。
众所都知,深度学习是机器学习中一种基于对数据进行特征学习的方法。卷积神经网络(CNN)属于深度学习的监督学习方法,同样是一种高效的特征提取方法。以往的机器学习,需要对数据先进行标注,将投入大量的人力、物力,如果能对小样本数据集进行深度学习进而获取特征模型,必将节约大量资源,因此很有必要研究一种面向小样本数据集的深度学习分类算法。算法主要包括两个阶段:一是基于迁移学习策略的深度特征提取阶段;二是使用全连接神经网络(Fully Connected Neural Network, FCNet)作为分类器的分类阶段[7]。通过迁移学习,获得更利于分类的特征模型。由此,迁移学习的特征提取采用深度学习的方法具有显著优势。当前,由于训练数据有限,可能会由于训练不足导致参数不准确而影响深度学习的模型。
通常,构成深度学习的网络框架层数越多,需要训练的数据越多,当然取得的分类效果就越好。然而在LED TV缺陷检测中,已标注的样本数量有限,要获取更多的样本需要通过不断地增量存取。为了在有限的样本数据集中能更好地提高分类性能,引入包含3个全连接层的FCNet分类器,如图3所示。在FCNet输入单幅图像采用迁移学习方法提取的4 096维全连接层的特征数据集合[9],为消除过拟合现象,在网络全连接层应用DropOut策略,为应对梯度衰减问题,在全连接层后引入修正的线性化单元(Rectified Linear Units,ReLU)层[10]。因此,FCNet模型的损失函数定义为:
(1-yn)log(1-σW,b(xn))]
(1)
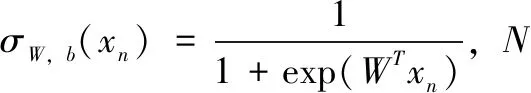
(2)
由此,给定被检测样本xj,由公式(3)可得到其分类情况。
[p,C]=max(WTxj+b)
(3)
其中:W,b是在训练过程中得到的参数,p表示样本xj属于类别C的概率。
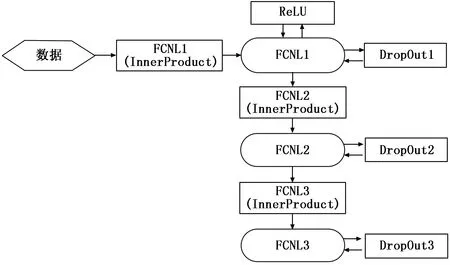
图3 FCNet分类器结构
4 缺陷特征增量学习
一般地,一个模式识别系统包括特征模型和分类器两个主要部分[11]。然而,针对已标注样本的特征分类,包括点缺陷、线缺陷和面缺陷样本的充分训练,加入增量数据后(不是时序模型问题)除了将算法在全量数据(历史样本数据+增量数据)上重新运行一遍外,在全量数据上更新算法模型将浪费大量资源,还影响系统的性能。由此可以采用在线学习算法,每过来一个样本,更新一次参数,并将该样本保存到训练数据集,甚至不需要储存历史样本数据,但可以达到和跑全量数据差不多的效果。图4所示为新增样本的缺陷特征学习网络模型,有(A,B)、(A,C)2个训练样本输入节点以及2个特征模型输出节点(X,Y),经过模型融合,形成新的特征增量学习网络。

图4 具有3输入2输出的增量学习演变示例
为应对高速变化和实时特性的大量数据,必然要求使用的特征学习算法支持增量动态更新,且具有实时学习高速动态变化数据的特征,包括新数据实例更新模型的参数与结构,能够快速学习新数据的特征;且尽力保持模型的原始知识[12]。支持增量更新的深度学习模型包括预训练和参数微调两个阶段。通过各基础模块的训练,构建增量式深度计算模型;使用已标注的数据对整个模型的参数进行微调,获得参数解,从而提升模型的准确度。在参数微调时,要尽量使得更新的模型融入新数据的特征,保持模型的原有的特性,新模型能够有效学习历史数据的特征,即特征模型适应性与保持性。因此对于给定训练的新增数据X,定义基于权重的适应性的误差函数如公式(4)所示。
(4)
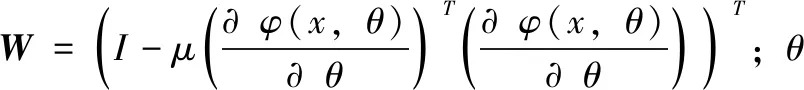
为衡量参数更新后模型的连续性,定义参数更新误差Epers函数如公式(5)所示。
(5)
为顾及参数更新的适应性与连续性,定义了代价函数如公式(6)。
P(x,θ+Δθ)=Eadp+Epers
(6)
为计算参数的增量Δθ,利用泰勒定理对φ(x,θ+Δθ)展开,可求得:
可见,Δθ的这个近似解与在线梯度下降算法具有相似的形式。不同的是θ和Δθ是参数张量及其增量的向量表示。
5 实验验证
为了更好地完成自动屏检,必需给出屏幕覆盖的范围,取单个相机的可视范围,计算出针对平面、曲面LED屏的相关测试参数。如图5所示,假定LED液晶屏的长宽比为16:9,测试的最大尺寸为65 英吋。则有:
24 MP,(16x)2+(9x)2=652→x=3.54 Inch,
即可计算单相机可视范围σ为:
依据经验,现分别设定水平LED屏检的测试参数:其中的测试机架的上下相机中心安装距离为405 mm;水平相机安装距离为520 mm。进而设定LED(4000R)曲面屏检的测试机架参数,其上下相机中心安装距离为405 mm;水平安装的相机需变形为4000R的曲面;其中心安装距离则为500 mm。
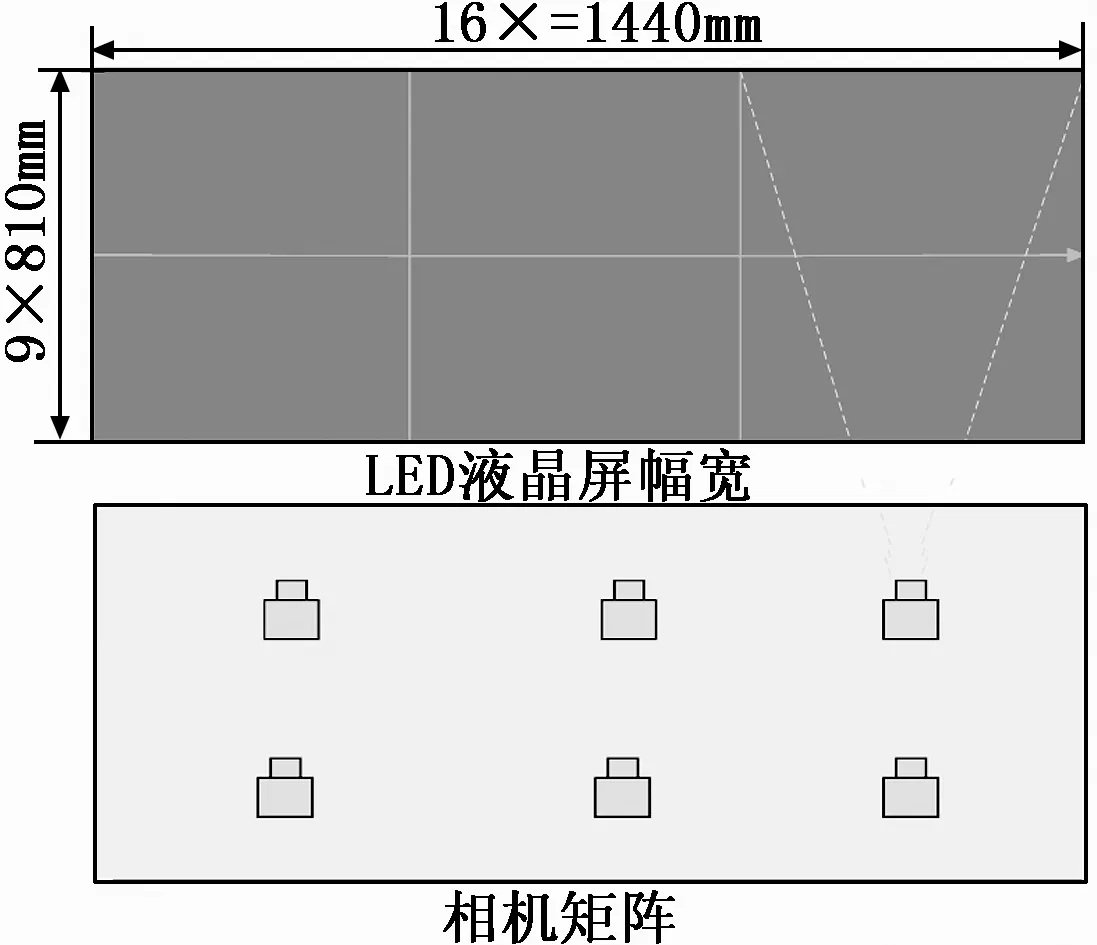
图5 16:9幅宽相机矩阵参数
为验证前面提出的小样本深度学习的智能屏检算法,将LED屏幕缺陷划分为亮/暗点、横/竖线、亮/暗斑三大类,在可视区域内进行全方位的检测。表1列出了以往生产过程中对应尺寸大小不同的LED TV屏检测试参数。
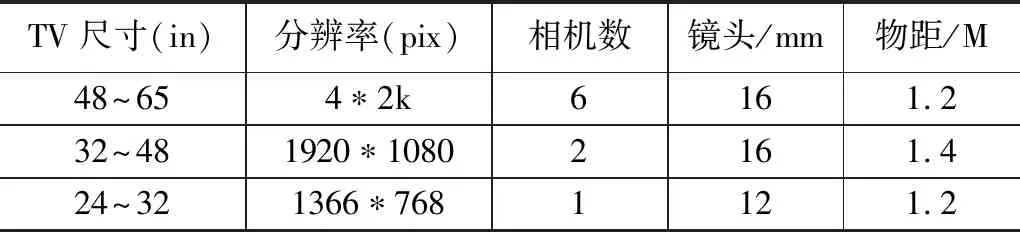
表1 不同屏检尺寸对应的测试参数
实验伊始,对已标注缺陷样本采用机器学习获得融合3类特征模型;接着对上位机采集的图像采用特征模型进行边检测边增量学习的策略,并对特征模型依照适应性和连续性进行参数调整。
在缺陷检测中,缺陷图像的分割是非常关键的环节。由于缺陷具有边缘模糊、对比度低以及图像背景不均匀等特点,因此必须针对3类缺陷进行多级训练获得特征模型,从而更好地进行识别。即,通过算法检测了5个缺陷标识,包括点状、线状以及图斑。特征提取自30个样本数据块,包括了10个区域、3种尺度以及RGB或者灰度。而后我们训练生产了60个FCNets网络,每一个都从某一个面部块及其水平对称图像中提取了两个160维特征。最后,我们得到了19200维的特征(160×2×60)。
在实际生产中只要满足缺陷特征模型范围值就能达到检测的目的,据不完全统计,缺陷检测的识别率可达到97%以上。具体的3种缺陷特征的现场实验对应的实验结果见图6所示。

图6 三类缺陷样本示例
考虑到训练样本集和测试集数据特征相对较稳定,亦或微调参数,使得更新的网络模型学习新检测数据的特征,因此除验证检测效率与准确性外,本文还进一步验证参数増量式更新算法的有效性。通过适应性、连续性和更新效率进行验证。现取已标注的100张有缺陷样本图片作为训练集,记为S0;并从600张测试样本中选100张历史数据(含新保存的检测数据)作为増量式训练数据集,记为S1;剩余测试样本数据集记为S2。对上述3个数据子集训练如下4个参数:
1)在S0上训练获得特征参数P0;
2)以P0作为原始参数,在S1上执行增量学习算法,获得增量更新参数P1;
3)在数据集S0,S1上执行基本的深度学习算法,获得参数P2;
4)在数据集S2上执行基本的深度学习算法,获得参数P3;
从图7可以看到,融合了迁移学习与FCNet深度学习策略能较大的改进基于图像的LED TV缺陷特征模型。另一方面,与传统机器学习相比,平均误差将随着样本数量的增加,我们提出的模型平均误差最小。这也表明我们的学习模型可以非常有效地从不同的特征空间中学到知识,能改善缺陷识别率。
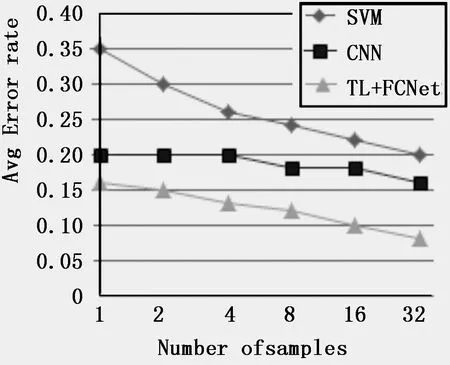
图7 融合迁移学习与FCNet的误差率情况
根据S2的MSE检验上述4个参数对分类的正确性,包括新参数模型对动态变化数据的适应性。MSE越小,说明新参数模型的适应性越强。实验结果如图8所示。
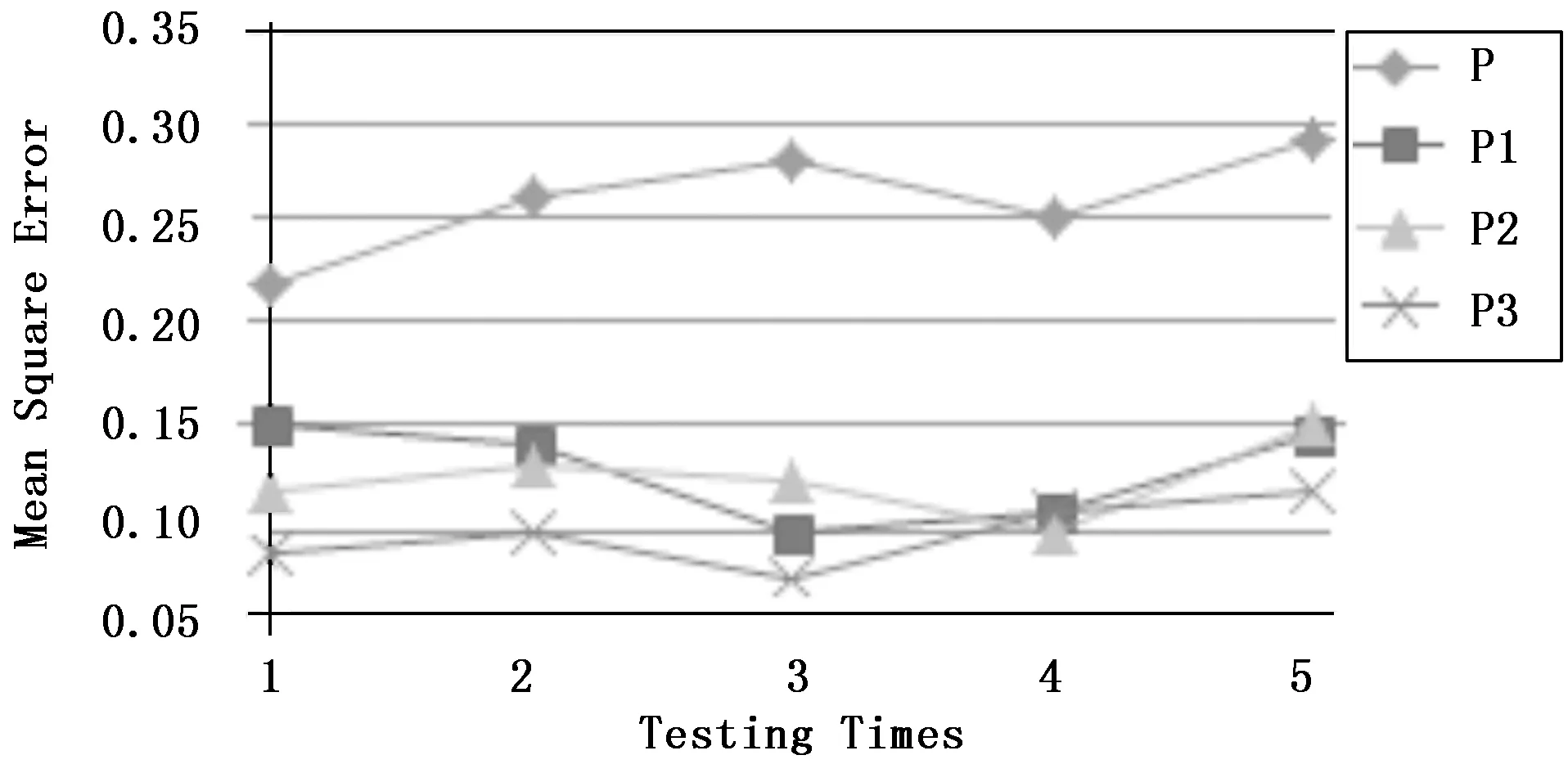
图8 测试数据集实验结果
均方误差MSE统计结果如表2所示。实验数据表明,θ作为参数对数据集进行分类得到的均方误差MSE最大。主要原因是基本的深度学习模型属于一种静态学习模型,而增量学习能有效学习新数据的特征,因此当P1作为参数对数据集S2进行分类时,得到的MSE明显小于0,同时我们注意到,P2作为参数进行学习,其分类结果与P1比较接近,因为新数据实例与原始数据整体执行基本深度学习获得了较好的结果。因而P3作为参数对S2进行分类时,获得的MSE最小。
接着需要验证4个参数对测试数据集S0进行分类的有效性。主要是检验4个参数对样本数据的连续性,即保持性,MSE越小,表明更新模型对样本库数据的保持性越强。连续实验10次,实验结果如图9所示,MSE统计结果如表3所示。
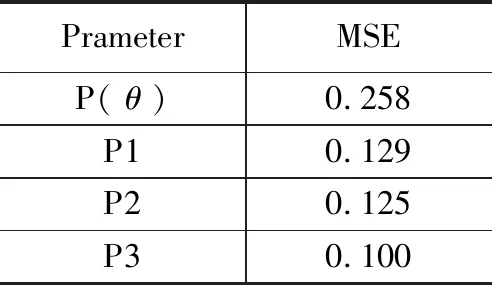
表2 自适应均方差统计结果
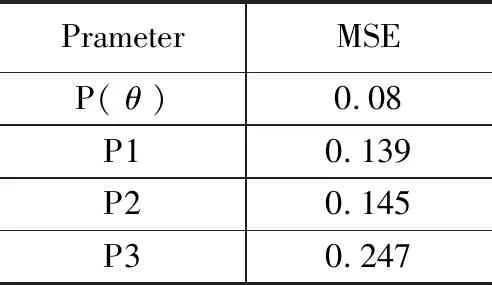
表3 可持续性均方差统计结果
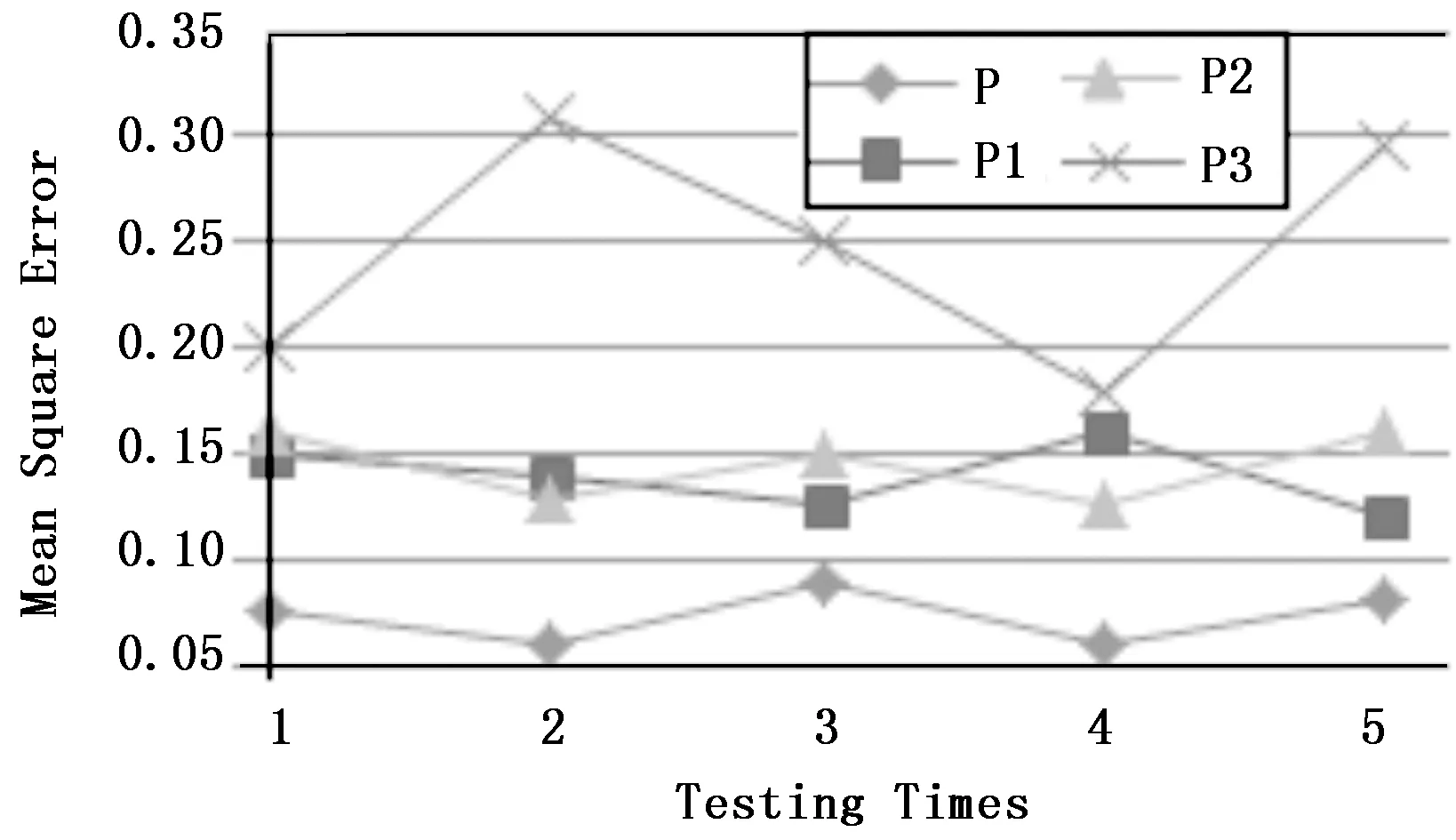
图9 测试数据集连续性实验结果
以上实验结果表明,用参数θ对S0分类的MSE最小。主要是因为参数θ是通过原始学习获得,获得了较好的分类效果,具有很强的连续性。且使用参数P1,P2进行分类,MSE值仍比较小,表明其对历史数据的特征学习具有良好的保持性。图10描述了采用传统机器学习、深度学习网络以及本文提出的应用融合迁移学习与FCNet的深度学习策略缺陷检测的准确率。图示结果说明了本文提出的学习策略优于其他2种识别算法。
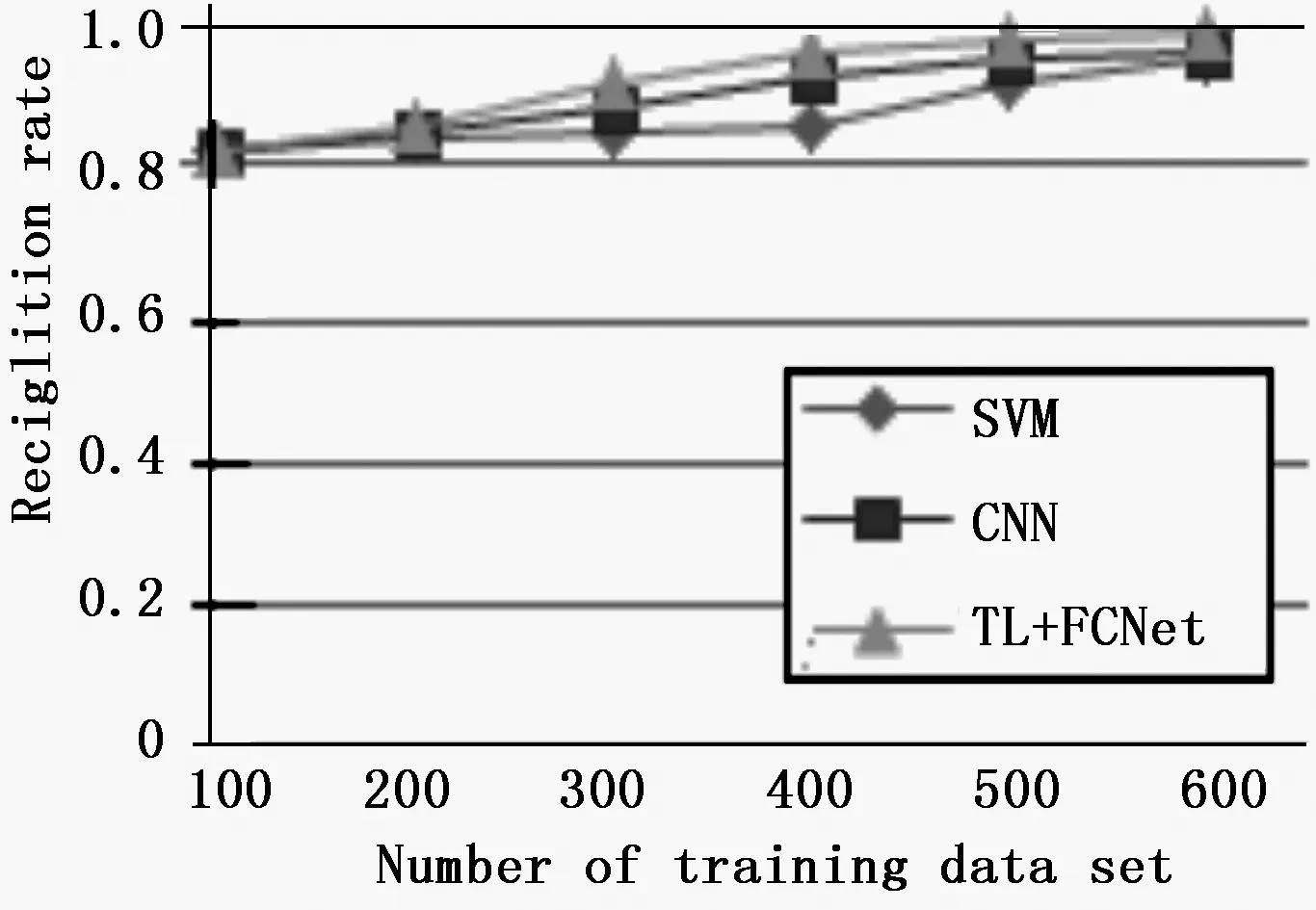
图10 缺陷检测准确率比较
6 结束语
工业自动化生产过程中采用机器视觉为基础的机器人,为工业4.0在企业的智造转型升级提供了保障。文章首先对亮暗点、横竖线、BLOB(几何形态)等几类产品缺陷进行了特征分析,尤其是对已标注图像的样本学习所获得特征模型,进行缺陷识别,且对已识别的图像保存为样本数据,通过多次增量学习进而调整识别模型参数,最终改善LED TV屏检的准确度。本学习策略已部署在TCL液晶产业园的自动化生产线并已投入使用,整个检测过程不需要操作人员干预,仅需单个人就能同时完成两套测试系统测试产品的准备工作,人力可减少50%,并能提高检测效率。此外,还一定程度地提高了产品的生产质量,大大减少返工率,获得了一定的经济效益。考虑到检测目标及其产品缺陷的差异,通过样本学习,模型参数的获取,机器视觉识别算法的准确度也将有一定的影响。因此,针对样本学习模型的准确度未能进行相关比较,期待今后能更进一步的探讨[13-16]。
猜你喜欢
北京航空航天大学学报(2022年5期)2022-06-06
快乐学习报·教育周刊(2022年16期)2022-05-01
新高考·高三数学(2022年3期)2022-04-28
当代陕西(2022年6期)2022-04-19
当代水产(2021年8期)2021-11-04
中学生数理化(高中版.高一使用)(2021年2期)2021-03-19
福建基础教育研究(2019年6期)2019-05-28
妇女生活(2019年1期)2019-01-17
领导决策信息(2018年16期)2018-09-27
数学学习与研究(2017年3期)2017-03-09
