
基于不同深度识别算法的矿井水位标尺刻度识别性能分析与研究
2019-12-16 12:42曹玉超范伟强
煤炭学报 2019年11期
曹玉超,范伟强
(中国矿业大学(北京)机电与信息工程学院,北京 100083)
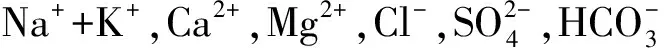
随着计算机技术的发展,图像识别技术越来越受到关注,图像识别水灾具有诸多优点:① 非接触,减少因为水流运动、水质、泥沙对传感器设备的破坏;② 可视化,可以在井上实时查看水位情况,及时排除误报影响;③ 复用性高,不用单独布置设备,可以采用井下已有摄像头进行监测;④ 可靠性高,摄像设备安装在防爆壳体内,不易受到矿井潮湿环境影响。为此,笔者提出一种基于残差神经网络的矿井水位标尺刻度识别方法。
残差连接的思想起源于中心化,将输入数据减去均值进行中心化转化,能加速系统的学习速度。文献[12]通过跳层连接(shortcut connection)分别将输入层,隐藏层单元激活值,梯度误差和权重更新中心化,大大提升了梯度下降算法的训练速度。文献[13]研究了在各种不同配置下,shortcut connections能提高随机梯度下降算法的学习能力和模型的泛化能力,并在图像分类和重构任务上进行了实验。文献[14]首次明确的提出了残差网络结构(Residual Neural Network),解决了深度神经网络中产生的退化问题。文献[15-16]实验验证了深层网络训练完成后随机去除某些层,网络性能不会有太多的退化。文献[17]深入的阐明了shortcut connections对训练深度网络的影响,模型的不可识别所造成的奇异性是训练深度网络的最大瓶颈,进而降低学习效率,shortcut connections能有效的消除这些奇异性,从而加快学习效率。但是这些算法对于神经网络的网络深度对整体识别效果影响却没有研究,识别率不能随着网络的加深而无限制提高,在特定数量的数据集上,具有最优的网络层数,过多的网络层数会导致参数训练不充分,进而导致网络性能退化,网络层数过少会出现过拟合现象,识别率降低。为此,笔者研究了不同深度算法对井下水位标尺刻度目标的识别率的影响。
1 网络设计及识别原理
图像的目标检测效果与深度学习网络的深度密切相关,但并不是网络层次越深,识别率越高。对浅层网络的优化无法明显提升识别效果情况下,越来越多的学者开始研究深层次网络,但是单纯堆叠加深网络时,梯度消失(在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降的现象叫做梯度消失)现象越来越明显,很容易影响识别效果,残差神经网络能很好的解决梯度消失的问题。
如图1所示两层网络结构,对于第1层网络,假设a[l]为第1层神经网络输入,a[l+1]为经过第1层神经网络之后的输出,w[l+1]为第1层神经网络的权重,b[l+1]为第1层神经网络的偏置,则有
z[l+1]=w[l+1]a[l]+b[l+1]
(1)
a[l+1]=g(z[l+1])
(2)
式中,z[l+1]为输入经过第l+1层后没有进入激活函数之前的输出值。
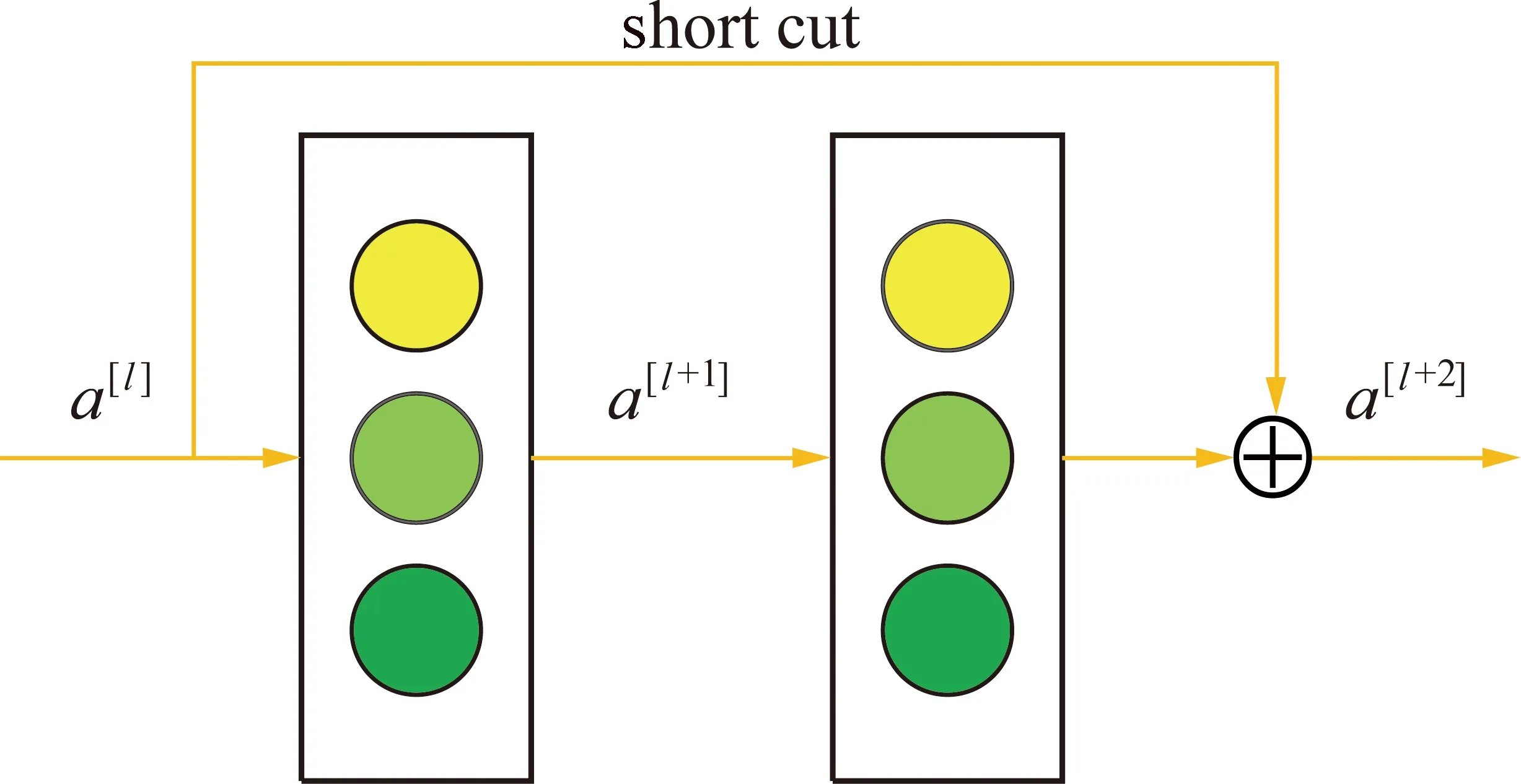
图1 残差网络结构示意
对于第2层则有
z[l+2]=w[l+2]a[l+1]+b[l+2]
(3)
a[l+2]=g(z[l+2])
(4)
按照如图1所示的short cut短连接,则有
a[l+2]=g(z[l+2]+a[l])
(5)
a[l+2]=g(w[l+2]a[l+1]+b[l+2]+a[l])
(6)
假设在大型网络的输出激活值
g(a[l])=a[l]
(7)
如果w[l+2]趋近于0,b[l+2]趋近于0,则
a[l+2]=g(a[l])=a[l]
(8)
如图1所示,由于shortcut存在,输入可以直接传递到后面的层,信息的完整性得以增强和保护,使得深层网络可以学习这些特征,避免了传统的卷积层在传递信息时,随着网络层次的加深,信息丢失或是损耗。
以R-CNN[18]为代表的候选区域(region proposal)方法,将检测过程分为2步,首先找到候选框,区分图像中的目标与背景,然后将候选框进行分类识别。Fast R-CNN[19]对损失函数进行了改进,使用了多任务损失函数,CNN网络训练中直接添加了边框回归,虽然识别效果提升,但是训练和测试速度仍然很慢,Faster R-CNN[20]改进了建议框的产生方式,采用卷积网络使得建议框数量大幅减少,检测效率大幅提升,但是和以YOLO[21-23]为代表的端到端的回归分析相比,在速度表现方面差强人意。虽然YOLO的检测速率较高,但是对小目标的检测精确度很低。据此,笔者设计了1种241层残差神经网络,用以检测煤矿水位标尺图像,网络结构如图2所示,网络由31个残差块构成,分别在第1,2,12,12,4个残差块进行步长为2的下采样,并分别加入1个padding层,1个卷积层,1个BN(Batch Normalliziton)层,1个Relu层,每个残差块由2个卷积层,2个BN层,2个Relu层,1个Residual层共7层组成,残差神经网络可以保证随着网络深度的加深,梯度不会消失。由于本文探测目标尺度较小,所以需要在较小的尺度下训练和识别,笔者分别在120层、208层引出张量和第240层进行融合,第120层卷积层张量的网格尺度为52×52,第208层卷积层的张量的网格尺度为26×26,第241层张量的网格尺度为13×13,网格划分越小对小物体的检测能力越好。
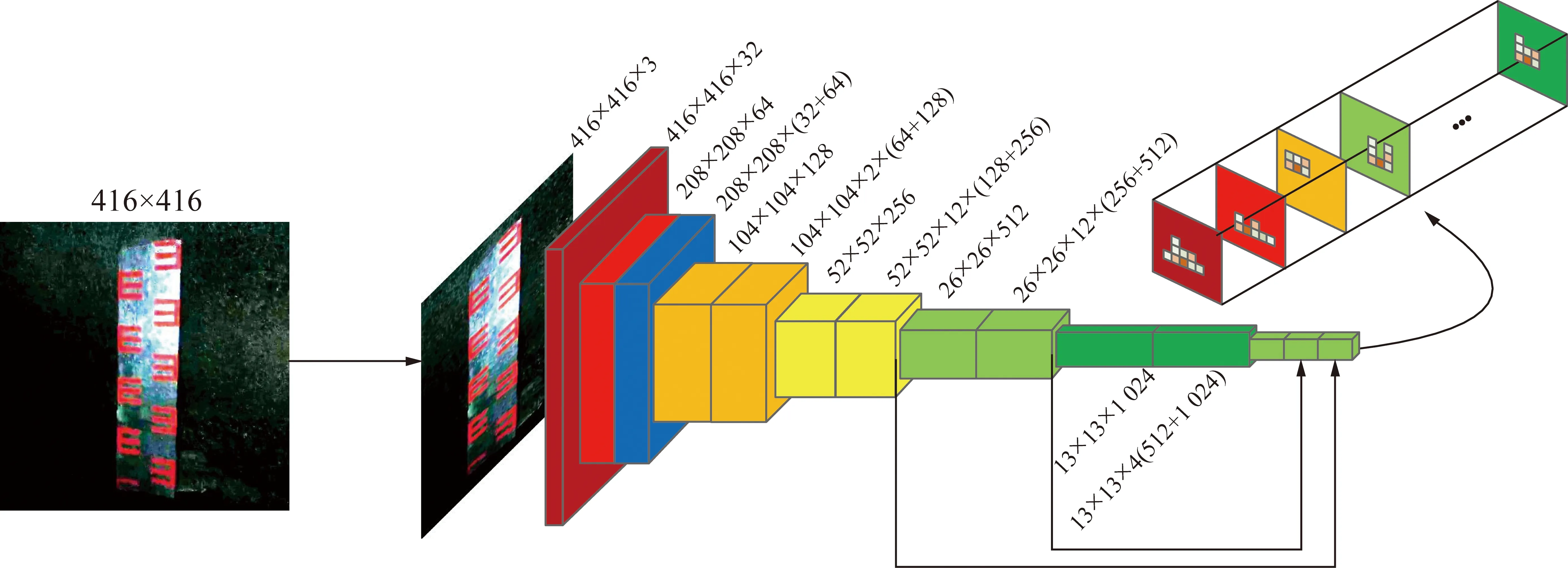
图2 网络结构
预测特征图如图3所示,每1个filter负责预测在特定尺度下目标的信息,共有1 792(256+512+1 024)个filter组成的特征图表示了在待检测特征图中待检测的目标的数量,目标的分类,目标的中心参数,目标的大小参数等关键信息。
图4为刻度目标识别的原理:刻度识别的任务分为3个层级,首先需要在待检测的图像中确定刻度目标的位置参数,其次需要确定刻度目标的形状参数,然后确定刻度目标的所属类别。将待测图像按照网格划分,通过卷积层不断的提取参数。图4中,tx,ty为刻度目标的中心位置参数;tw,th为形状参数;c1为左刻度的置信度;c2为右刻度的置信度;p0为是探测物体前景而不是背景的概率。
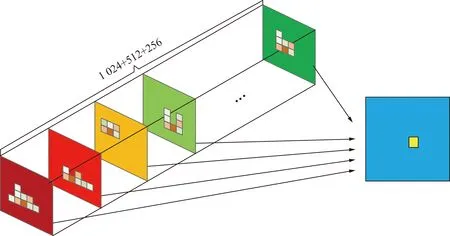
图3 特征向量
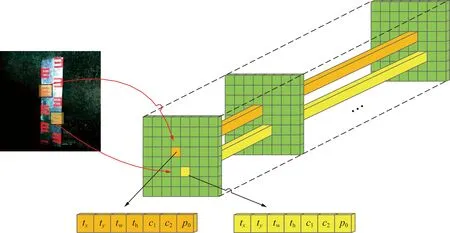
图4 检测原理
模型预测目标和真实值之间的关系可以用损失函数表述,本文采如式(9)所示的损失函数Loss。
(9)

2 模型的训练与调整
2.1 模型训练设置
笔者采用python编程,在Intel i7、十六核1.8 GHz、内存32 G、显卡GTX1080TI、64位ubuntu16.04操作系统上进行了模型的训练与调整,训练数据集图像来自神华宁夏煤业集团有限责任公司双马煤矿43煤辅用巷道,由1 000张960×544像素jpg格式图片构成,为了关注时间和空间的关联性,测试数据集由视频帧按照时间顺序逐帧分割为连续的100张图像组成。
2.2 模型的测试评估
如图5所示,模型的损失值从第3次开始迅速变小,到第100次左右开始走向平稳,在训练模型中,模型的优劣与迭代次数密切相关,但并不是迭代次数越多模型越好,训练次数越多时,容易导致过拟合的出现,需要对训练出来的模型进行评估调整,混淆矩阵(con fusion matrix)是判断分类器好坏的重要指标,见表1。
左侧刻度的识别率Preleft可以记为
(10)
式中,Aleft为测试集左刻度检测正确的个数(模型计算出来的IOU与阈值比较,如果大于阈值记为正确检测的个数);Bleft为测试集实际左刻度的个数,同样的右侧刻度识别率可以计为
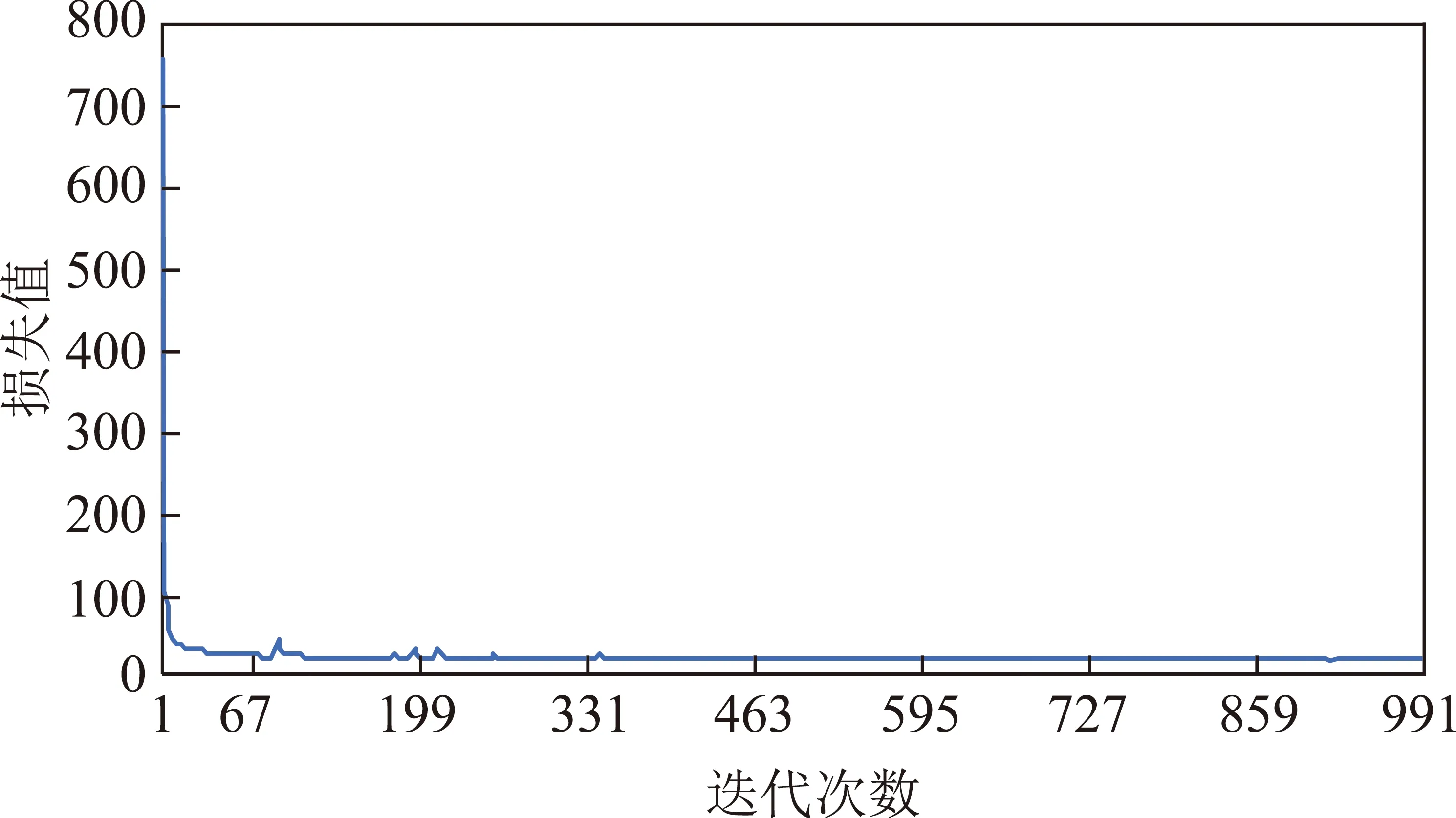
图5 损失值Loss随迭代次数的变化曲线

表1 混淆矩阵
(11)
式中,N为个数。
则平均识别率mAP:
(12)
召回率Recall表示样本中的正例被预测正确的比例:
Recall=TP/(TP+FN)
(13)
f1[24]值如下:
f1=2×mAP×Recall/(mAP+Recall)
(14)
图像识别效果如图6所示。

图6 识别效果
3 实验分析
3.1 识别率
不同置信度阈值下识别率、召回率、f1值如图7所示,图7(a),(b)为左、右刻度在不同置信度阈值下识别率、召回率、f1值,图7(c)为识别率、召回率、f1值的平均值。在置信度0.1,0.2附近整体的识别率都较低,随着阈值增长,左刻度的召回率逐渐升高,右刻度先升高然后降低,降幅较大,所以平均召回率趋势下降较大,左刻度的识别率在0.4阈值处较大,右刻度的识别率随着阈值的增大逐渐增大,f1值在3幅图中都是先增大后减小,按照识别率>召回率>f1值顺序可以看出在阈值0.4附近,识别率最高为97%,召回率最高为96%,f1值最高为97%。预测张量含有所有边界框的信息,低于阈值的边界框的相应向量值被置位为0,所以随着置信度的提高,一些比较低可能性的目标被筛选出去,所以TP和FP的值会逐渐变小,根据式(10),以左侧为例:如果TP为固定值,随着FP变小,Preleft逐渐变大;如果FP为固定值,随着TP的变小,Preleft会逐渐小。根据本文实验,在参数0.4的时候识别率最高。
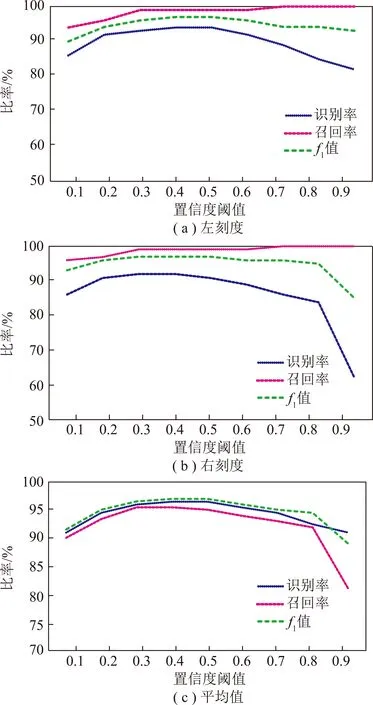
图7 不同置信度阈值下的识别率、召回率、f1值
3.2 损失值(Loss)分析
为了验证本文网络结构的性能,笔者分别对其他几种深度网络进行了实验,分别为RN59(59层残差网络),RN87(87层残差网络),RN129(129层残差网络),RN297(297层残差网络)。图8(b)为第2~52轮训练损失值,图8(c)为第950~1 000轮损失值。随着网络层数的加深,训练损失值减少的速度放缓,其中RN59,损失值下降速度最快,RN297为最慢。在1 000轮左右损失值平稳性如图8(c)所示,RN297的振幅较大,最大振幅达到21,本文算法和其他2种网络深度算法表现较好,损失值稳定在17左右。

图8 不同网络深度的Loss损失值
3.3 网络深度对识别影响比较分析
网络深度是指神经网络的层数,神经网络的层数越多,深度越深。图9表示不同网络深度在不同的置信度阈值下的识别率、召回率、f1值。图9(a),9(b),9(c)表示左刻度的识别率、召回率、f1值,本文算法在置信度0.4时最大分别可以达到94%,99%,97%;图9(d),9(e),9(f)表示右刻度的识别率、召回率、f1值,本文算法在置信度0.4时最大分别可以达到99%,92%,97%。图9(g),9(h),9(i)为平均识别率、平均召回率、平均f1值,本文算法在置信度0.4时最大分别可以达到97%,96%,97%。可以看出,识别率并不能随着网络的加深而无限制提高,深层网络会带来梯度不稳定,弥散,进而导致网络退化,虽然可以通过一定的方法进行优化,但却没办法从根本上消除。网络加深反而会导致性能开始下降。加深的模型导致某些浅层的学习能力下降,限制了深层网络的学习,识别率反而下降。
3.3.1PR曲线分析
图10表示不同网络深度的PR曲线,图10(a)表示左刻度的PR曲线,图10(b)表示左刻度召回率在0.1~0.9放大的PR曲线。可以看出本文采用的网络深度算法的PR曲线在所有曲线的最上方,性能优于其他网络深度;图10(c)表示右刻度的PR曲线,图10(d)表示右刻度召回率在0.1~0.9放大的PR曲线,本文采用的网络深度的算法虽然在召回率0.7~0.9时的识别率低于RN297和RN59,但是在其他召回率期间性能表现较好。
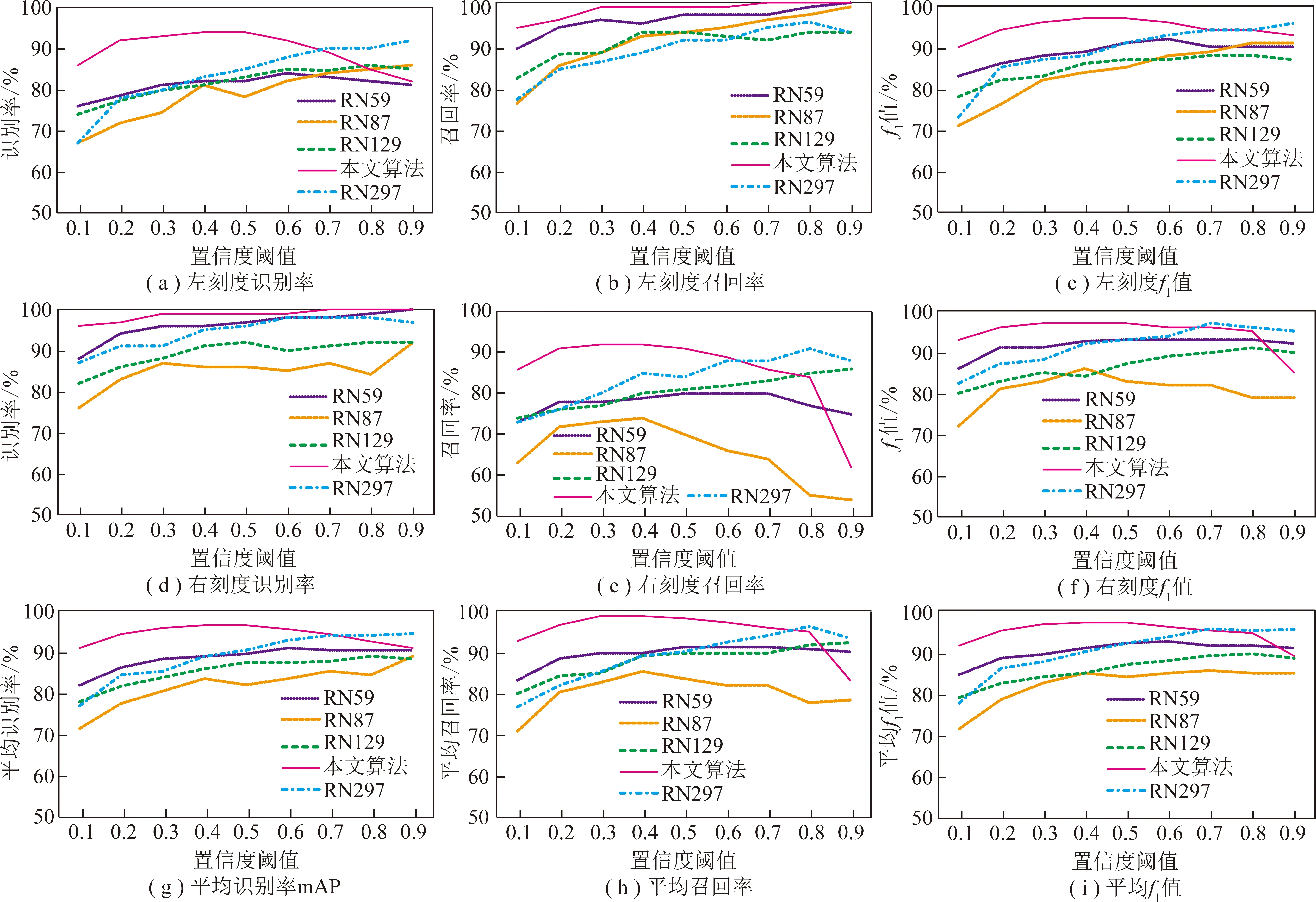
图9 不同网络深度的识别率
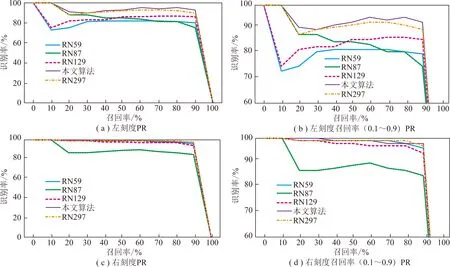
图10 不同网络深度的PR曲线分析
3.3.2ROC曲线分析
图11为本文采用的网络深度的算法和其他几种网络深度的ROC(受试者工作特征曲线,Receiver Operating Characteristic Curve,简称ROC曲线)曲线对比,横轴为FPR(False Positive Rate),纵轴为TPR(True Positive Rate),越靠近左上角的ROC曲线性能越好,此时,假阳性和假阴性的总数最少。可以看出本文网络深度算法的ROC曲线的性能均优于其他曲线的性能,表现最好,其次为RN87,RN129表现最差。
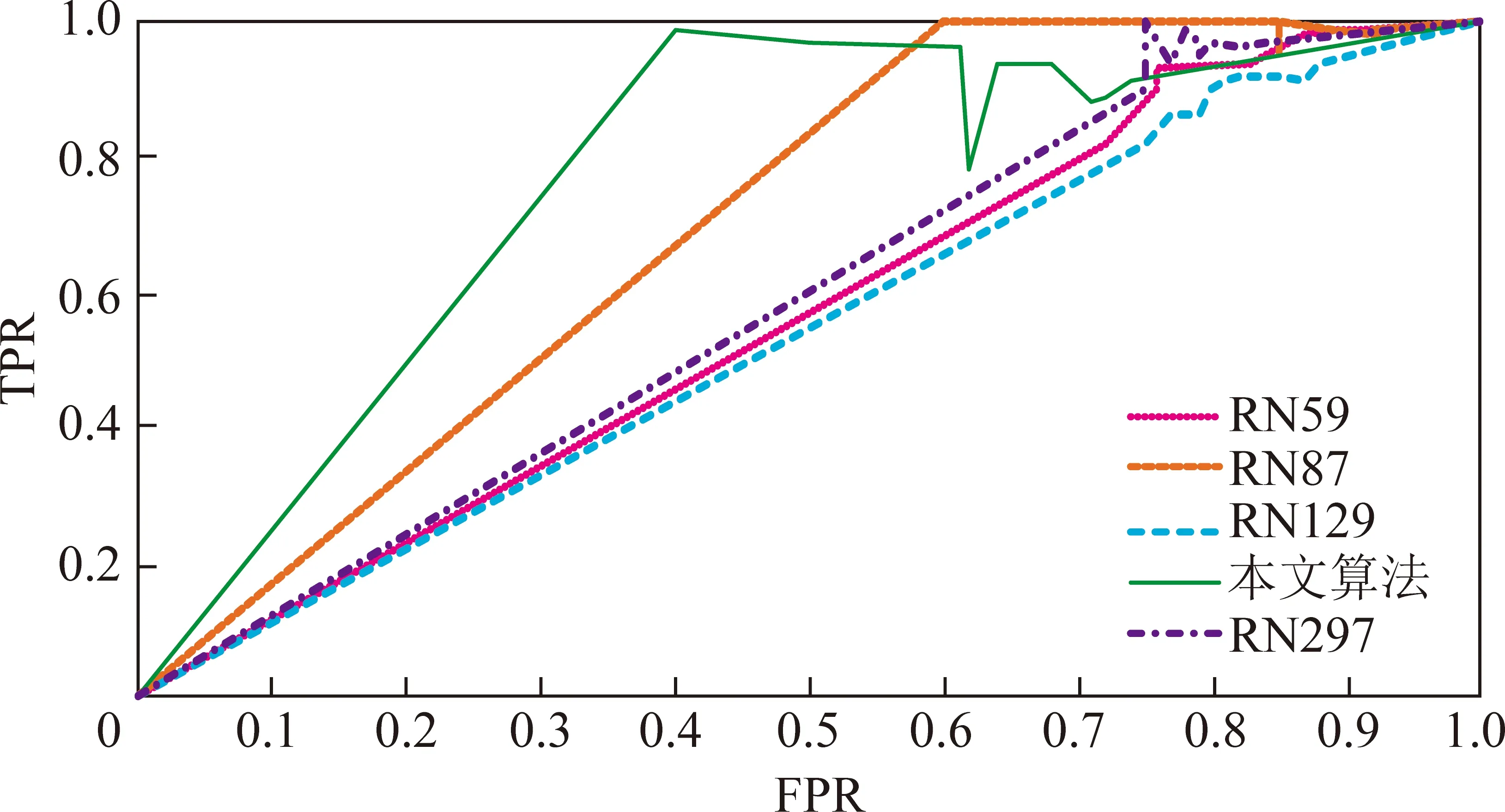
图11 不同网络深度的ROC分析
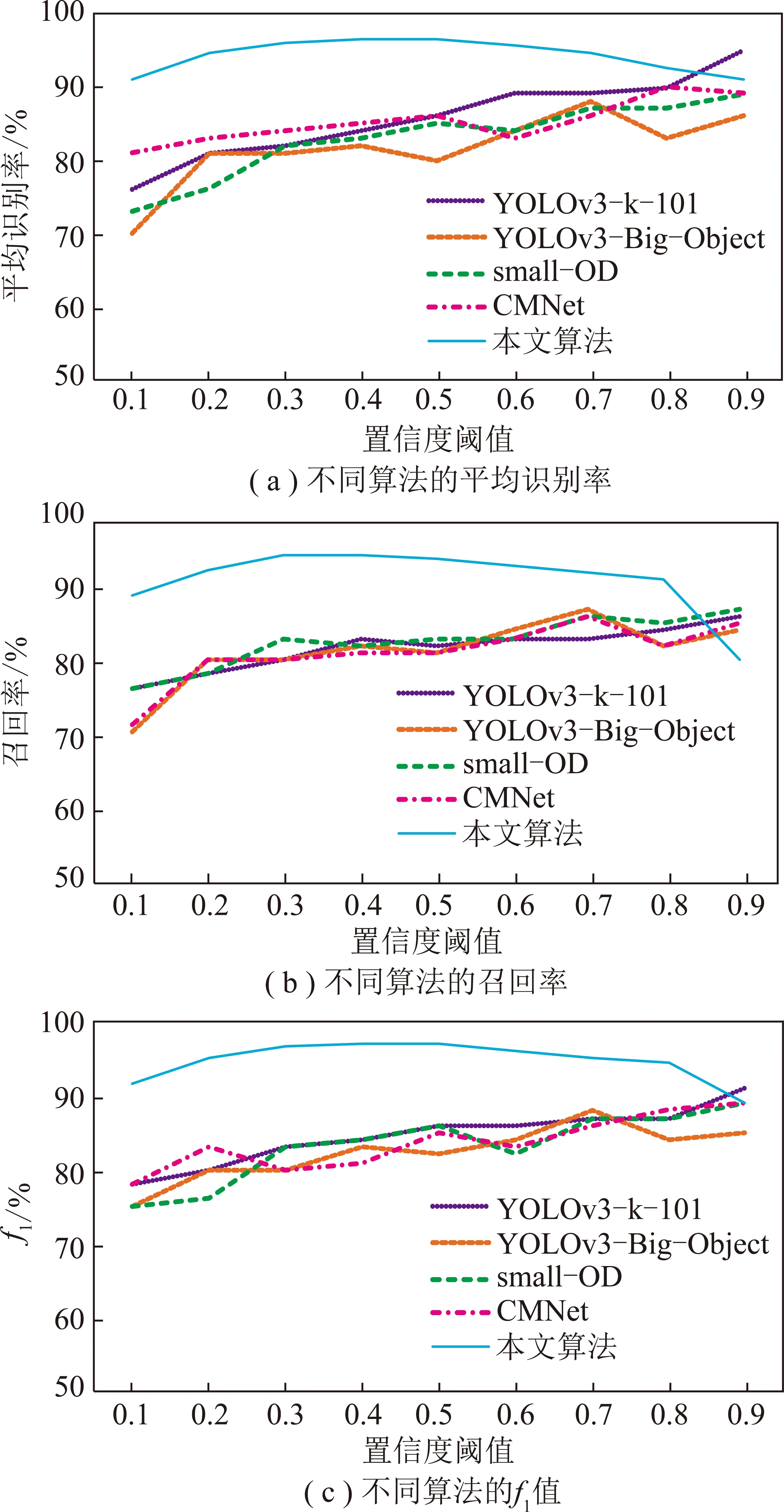
图12 不同算法的性能比较
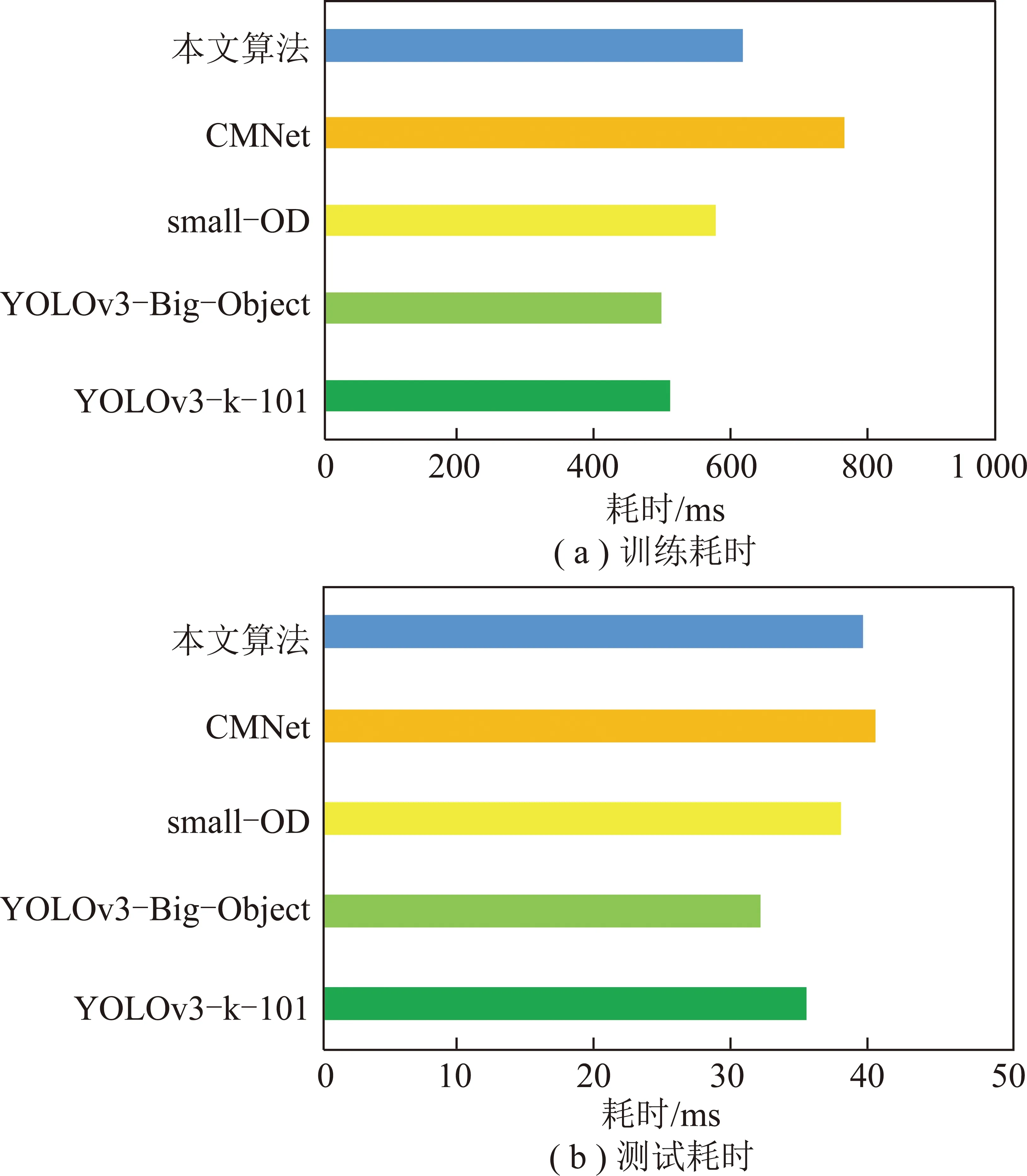
图13 耗时对比
3.4 其他不同算法的平均识别率
为了分析算法的性能,笔者选取了其他几种常见的算法进行比较,参与比较的算法有YOLOv3-k-101[25],YOLOv3-Big-Object[26],small-OD[27],CMNet[28],如图12所示,本文算法在置信度阈值0.4时的识别率最高为97%,召回率为96%,f1值为97%,均优于其他算法。
3.5 其他不同算法的时间分析
图13为本文算法与其他算法的时间比较,可以看出整个的训练时间要比测试时间高出1个数量级,这是因为在训练阶段需要计算Loss值,并利用反向传播更新卷积层的权值参数,所以耗费时间较大。而网络结构的增大会相应的增大训练时间,但是相对于性能的提升,时间的开销可以容忍。图13(a),(b)分别为本文算法相对于其他算法的训练时间和测试时间比较,可以看到本文算法在训练时间开销上仅次于CMNet,测试时间比较长大约为47 ms。
4 结 论
(1)建立了一种基于残差神经网络的矿井水位标尺刻度识别方法,采集工作面和巷道水位标尺图像,将图像刻度中心位置参数,形状大小参数,刻度分类提取为特征向量,通过残差神经网络进行训练,当网络训练稳定后,将待检测图像进行相同的操作得到特征向量,将特征向量解析为图像刻度目标的关键信息,实现水位标尺的刻度检测。
(2)针对不同的网络深度进行了实验,比较了不同深度下训练阶段的损失值下降速率和稳定性、平均识别率、f1值、PR曲线、ROC曲线、训练耗时、测试耗时。
(3)实验验证了不同的置信度阈值对识别率的影响,低阈值情况下,张量预测有效边界框变多,同时判断为负样本概率增加,导致识别率较低。随着阈值增高,处理张量有效边界框变少,整体预测样本数量变少,判断为负样本的概率降低,识别率增加。置信度到达一定阈值,负样本数量开始对识别率影响加大,导致识别率降低。本文实验在置信度0.4阈值处具有最高识别率97%。
(4)通过与YOLOv3-k-101,YOLOv3-Big-Object,small-OD,CMNet算法进行比较,本文在时间开销略多情况下,性能明显提升。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
小型微型计算机系统(2022年4期)2022-05-09
学苑创造·A版(2019年9期)2019-11-07
计算机应用(2018年5期)2018-07-25
中国高新技术企业(2017年5期)2017-05-05
学苑创造·B版(2017年1期)2017-02-21
学苑创造·B版(2017年1期)2017-02-21
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
中国科技纵横(2016年20期)2016-12-28
