
移动图书馆词典构建与应用
2019-12-16 06:14朱婷婷郑德俊
图书馆理论与实践 2019年11期
朱婷婷,郑德俊
(1.宁波职业技术学院图书馆;2.南京农业大学信息管理系)
1 引言
移动图书馆研究如火如荼,已有研究主要关注服务模式、平台建设推广、用户体验、用户需求等方面,尤其重视对用户的研究,近年来,移动图书馆用户评论挖掘也成为研究热点。[1]对于移动图书馆用户评论挖掘,评论数据的预处理工作尤为重要,预处理将影响到后续的评论数据处理效果,其中,中文分词是最关键的一步。分词词典是机械分词的基础,通用的分词词典主要收集的是日常用语及中华大辞海的词汇。但是通用词典不能满足特定领域语料的分词要求,且通用词典中生僻字数量庞大,影响了分词的准确性、合理性和时间性能。
对移动图书馆用户评论进行预处理需要用到分词词典,但目前国内还没有一部完善的大规模移动图书馆词典。移动图书馆词典是进行移动图书馆用户评论预处理的前提,如何多渠道获取移动图书馆相关词条,构建移动图书馆词典,并将其应用到分词中来,已成为移动图书馆研究亟需解决的问题。
2 国内外研究现状
目前,有三种构造分词词典的方法:① 人工输入词条信息为主、机器操作为辅的方式;② 从印刷版的词典里获取词条并手动录入的方式;③ 对大规模文本采用简单的语言模型和概率统计,并分析有关词汇信息的方式。前两种方法主要是从印刷版文本中获取信息,利用人工参与的方式去描述词条信息,已有的很多语言信息库、语义词库和词典都是利用前两种方法实现的。但前两种方法存在明显缺点:费时、费力、成本高,相较而言,第三种方法更为实用。[2]
在为构建词典收集词条时,可以采用基于现有词库资源的方法、基于语料库的方法、两者结合的方法。[3]①基于现有词库资源的方法主要利用现有词库资源(如,英文的WordNet、GI,中文的HowNet、同义词词林)来进行词条扩展。Hu 和Liu 选取了一些褒义和贬义的形容词作为种子集,利用WordNet 的同义词和反义词联系对种子集进行扩展,建立情感词典;[4]路斌等利用同义词词林中的同义词词群,根据褒贬义种子词进行扩展,建立情感词典;[5]张启宇等利用网络词库设置了农业词汇的词性编码,以 MySQL 数据库为例设计了农业领域专用的分词词典。[6]②基于语料库的方法是指通过对相关语料库进行抽词获得词条信息,从而构建词典。Huang 等使用句法分析和主观线索字典抽取情感词,根据PMI 建立情感词之间的联系图,并以语言学规则以及语料中的并列、转折关系作为限制条件;[7]孙霞等对领域生语料进行分词处理,提出了基于切分单元的最大匹配算法得到候选词串集,并最终生成领域词典。[8]
经过文献调研,笔者发现,面向移动图书馆领域的词典研究几乎空白。移动图书馆服务既包含传统图书馆服务的数字化、信息化,又包含信息化、电子化时代用户新需求所带来的新型的图书馆服务,不断更新、不断拓展是移动图书馆服务的一大特点。移动图书馆用户在评论语言的表达上具有一定的随意性,口语化程度高,单一的收集词条的方法难以保证收词的全面性与可靠性。因此,本文提出一种移动图书馆词典构建的收词方法,并构建了一部移动图书馆词典,为后续移动图书馆用户评论的分词研究提供便利。
3 词典构建思路与方法
本研究以机器操作为主、人工判别为辅的方式构建移动图书馆词典,旨在为移动图书馆用户评论分析提供依据和基础。移动图书馆词典构建的词条收集框架见图1:①对移动图书馆用户评论进行切分、词频统计,构造基础词典;②应用CiteSpace 分析中国知网期刊数据库中与“移动图书馆”相关的文章的摘要与关键词,并将其添加到基础词典中;③ 借鉴图情领域相关词典扩展词条;④ 考虑到用户评论语言口语化特点,融合输入法词库;⑤基于《同义词词林》进行同义词扩展,保证移动图书馆词典全面而实用。

图1 词条收集框架图
3.1 基于评论语料的基础词库的构建
笔者将结巴分词包导入Python 2.7 平台,并对移动图书馆用户评论进行分词及词频统计。词频分析法利用关键词或主题词在领域文献中出现的频次来确定该领域的研究热点和发展动向,其依据的基本理论为齐普夫定律(Zip’s law)。[9]依据关键词频次的高低排序,笔者去除专指度低、无法反映出具体研究内容的词(如价值、越来越好等),最终得到符合集中分散“二八定律”的1,431 个关键词,其中频次top30 的关键词样例见表1。

表1 词频统计结果样例
3.2 基于“中国知网”语料的词汇扩展
本文选择中国知网的中国学术期刊网络出版总库为数据源,检索时间截至2018 年12 月31 日。为了保证检索质量,笔者对检索工作做了要求:① 以“移动图书馆”为中心词,检索篇名包括“移动图书馆”“数字图书馆”“移动信息服务”“手机图书馆”“掌上图书馆”的文献;②选择核心期刊和CSSCI 来源刊里的文献作研究,其余的不作考虑;③ 将会议通知、简讯、稿约、征文通知、编者序等不相关的文献排除在外。笔者在Note-Express 里建立了题录,题录包括年份、标题、作者、刊名、关键词、摘要等字段,题录里共收录了4,987 篇相关文献。
以CiteSpace Ⅱ为分析工具,将文献数据导入CiteSpaceII 中进行分析,设置相关参数:时间为1998-2018 年;主题词来源选择为标题(Title)、摘要(Abstract) 和关键词(Author Keywords),最终得到13,409 个主题词,其中top20 见表2。

表2 词频统计样例表(部分)
3.3 基于图情领域已有词库的借鉴
国家图书馆的图书情报纸本词典收藏全面,可通过各馆馆藏目录或联合目录进行检索。20 世纪90 年代以来,随着网络和信息技术的发展,基于互联网开发的数字化参考源及其检索系统有了迅速发展,图书情报词典也如其他参考工具书一样有了新的发展平台,出现了网络版,如《图书情报词典》(1990 年)、《英汉-汉英文献信息词典》(1996 年)、《英汉图书馆学情报学词汇》(2006 年)等。[10]本文借鉴已有的图书情报相关词典和图书馆词典,在人工大致判别后将其加入基础词库,共收集到18,416 个关键词。
3.4 网络词语扩展
移动图书馆的用户评论属于在线评论,用户输入多采用拼音输入法。考虑到词条收集的完整性与全面性,笔者借助网络上的词库进行词条扩展。输入法提供的词库都有其固定格式,笔者下载搜狗拼音输入法、百度输入法、紫光输入法等相关词库,并利用深蓝词库转换工具将其转换成无拼音格式的txt 文件。通过借鉴各输入法的相关词库,整理合并得到7,152个关键词,将其加入基础词库。
3.5 基于《同义词词林》的词汇扩展
汉语言博大精深,一词多义、一义多词,把名称不同但表达意思相同的词条叫做同义词。哈尔滨工业大学信息检索研究中心同义词词林扩展版[HIT-CIR Tongyici Cilin(Extended)] 是一部比较完善的同义词的参考词典,共收录了77,343 条词语,不仅包括同义词,还包括同类词,即广义的相关词。《同义词词林》为了明显区分每个词的分类,在每行词的前边用编码标记(见图3)。编码的第八位有3 种不同的表示符号,分别是:“=”“#”“@”,其中,“=”代表相等且同义,“#”代表不等但同类,“@”代表自我独立、封闭(该类词在词典中既没有同义词也没有相关词)。

图3 《同义词词林》样例
本文中用到的只有同义词,因此要先对《同义词词林》进行筛选整理。从《同义词词林》的编码规则可以判断出,只有末尾是“=”组词是同义词。
Step1:把整个《同义词词林》读入list,循环对每个编码的第八位进行识别,选出第八位为“=”的编码组放在list_U 中,即list_U 中存放的就是同义词;
Step2:按空格对list_U 中每个元素进行分词,存入s_Word[]中,再比对s_Word[]中的词汇与词典中已有的词汇;
Step3:把 Step2 中找到的情感词与词典进行比对,除了词典中已经有的词之外的所有的词按照:“词” “属性” “值”的形式写入到词典中。
通过以上流程,笔者筛选出《同义词词林(扩展版)》中符合条件的扩展词汇17,632 个。
最终,在对基础词典中的关键词进行去重处理后,共得到51,930 个关键词。至此,已完成了移动图书馆词典的构建工作。
4 自定义词典分词测评
目前,国内移动图书馆主要有两种形式,一是购买商业公司的移动图书馆App 服务,二是自建移动图书馆服务平台。受限于图书馆自有的技术团队和后期维护水平,国内绝大多数图书馆的移动图书馆服务以购买为主,因此,用户评论数据也在商业公司服务器上,一般很难被公开查询。2017 年以来,在国内某著名商业公司移动图书馆服务平台的支持下,本研究获取了26,976 条数据,笔者随机抽取1,850 条有效评论作为实验数据进行分词,分词结果的部分样例见表3。
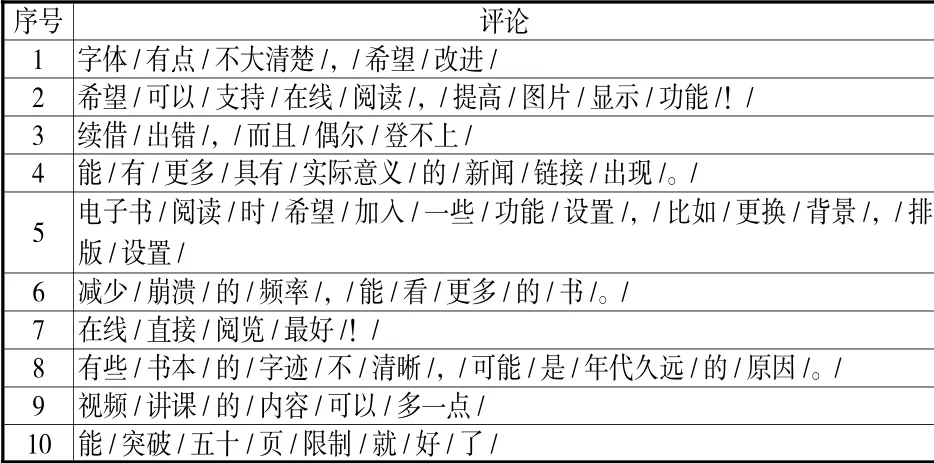
表3 分词结果样例(部分)
评判分词效果的指标主要包括分词的正确率和分词速度。[11,12]移动图书馆词典和结巴自带词典的分词效果对比见表4。本文以P 为分词正确率,N 为参与实验的用户评论数,n 为分词错误的评论数,定义P=(N-n)/N;人工判别分词结果,发现有17 条用户评论分词错误,分词准确率为P=94.08%。在时间性能上,使用结巴自带词典耗时6 秒01,使用自定义专属词典耗时1 秒77,显然使用自定义专属词典更高效。

表4 分词效果对比
在分词合理性上,使用自定义专属词典明显优于结巴自带词典。由表5 可以看出,结巴自带词典分词对于很多双字词识别不了,如“连接”“平台”“及时”“字体”“改进”等,所以只能拆分成单字词,而使用自定义专属词典则可大大减少此类分词错误。

表5 分词合理性对比(部分)
自定义词典并不能实现100%的正确率。人工判别分词结果时,发现有一些词结巴自带词典和自定义词典均不能识别,一共有17 条用户评论出现错误(见表6),如“学号”“予人方便”“触控系统”“越办越好”“音量键”等。可见,自定义词典还有很大的改进完善空间。

表6 分词错误样例(部分)
综上,将自定义的移动图书馆词典运用到移动图书馆用户评论分词中,其准确率、合理性和时间性能得到了明显提升,可见本文一系列收集词条的方法构建出的移动图书馆词典具有较高的可靠性与有效性。
猜你喜欢
校园英语·月末(2021年13期)2021-03-15
动漫界·幼教365(大班)(2020年7期)2020-06-26
电脑知识与技术·经验技巧(2020年3期)2020-05-07
现代计算机(2019年30期)2019-12-11
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
电脑爱好者(2017年5期)2017-05-04
网友世界(2009年12期)2009-03-05
中学生英语·外语教学与研究(2008年4期)2008-03-18
