
基于因子图的不一致记录对消歧方法
2020-01-09 03:48徐耀丽李战怀王艳艳樊峰峰
计算机研究与发展 2020年1期
徐耀丽 李战怀 陈 群 王艳艳 樊峰峰
(西北工业大学计算机学院 西安 710072) (大数据存储与管理工业和信息化部重点实验室(西北工业大学) 西安 710129)
大数据时代,信息化进程的迅猛发展促使各行各业都累积了大量的数据.但真实的数据存在各种各样的数据质量问题如数据不完整、不一致、和不满足实体同一性等,使得直接基于这些脏数据的分析和预测不能满足应用场景的需求.为此,大量的研究工作针对这些问题提出一系列清洗算法.其中,针对数据无法满足实体同一性现象,学术界和工业界研究了实体解析问题[1-3].实体解析也称实体匹配,是通过识别出所有描述真实世界同一个实体的记录对,来保证数据的实体同一性.它是数据集成或清洗系统的一个首要问题.
自实体解析问题第1次[4]被提出后,有大量实体解析方法被提出.部分实体解析方法[3,5-6]假设训练数据事先给定.文献[5-6]首先从训练数据中学习实体匹配规则,然后用这些规则来解析记录对是否匹配.文献[3]首先使用embedding技术如fastText[7]将每个属性的单词序列转换为相同维度的向量序列;然后训练双向序列模型Bi_RNN[8](bidirectional recurrent neural network)和序列比对模型来生成属性摘要向量;接着用比较函数构建出记录对的一系列特征;最后使用分类模型如多层感知器模型,训练一个二分类模型,进而进行实体解析.然而,现实场景中,面临一个新的实体解析任务时,事先标记好的数据集并不一定总是可用,而且某些领域数据需要由经验丰富的专家来标记.考虑到依赖专家来标记数据集会带来高昂的成本,本文所提的方法无需标注数据,因而具有更广泛的应用场景.
一些学者[2,9]从数据统计角度分析匹配特征,提出了无监督的实体解析方法.如文献[2]使用离群距离来估算记录对的匹配可能性;文献[9]使用机器学习的聚类算法,把具有类似特征的记录划分到匹配或不匹配组中.由于各种实体解析技术有特定的假设,以及解析任务的复杂性,对同一个实体解析任务处理的结果,存在大量的不一致记录对.例如在文献数据集Cora上,使用11种方法(如Rule,Distance,Cluster等)得到的解析结果中,一致匹配对的数目仅有1 013;而不一致记录对的数目则高达44 909.所谓一致匹配对是指所有的方法一致认为该记录对是匹配的;而不一致记录对是指部分方法(如Rule)认为该记录对是匹配的,而其余方法(如Distance)认为不匹配.本文的工作侧重于解决这些不一致的记录对.
对不一致记录对进行消歧处理面临很大挑战.一方面,在没有标签数据情况下,直接选出所有方法中最好的是不现实的.另一方面,假设能够选出综合表现最好的方法,某些记录对(如已选中的方法无法有效处理,而其他方法可以处理的匹配记录对)的信息就不能够得到充分利用.鉴于此,我们利用因子图把各类匹配特征统一且有效地利用起来,并提出了基于因子图的不一致记录对消歧方法.
与记录对是否匹配相关的信息大致可分为3类:1)记录对自身匹配特征.例如使用字符串相似度,度量记录对属性值的相似程度.2)匹配传递特征.例如一个记录对(r1,r2)匹配后,对其他记录对(r1,r3)是否匹配的影响.3)外部匹配特征.例如个体方法的解析结果.为便于陈述,本文把现存的实体解析方法称为个体方法.概率图模型[10]的因子图能够利用因子函数灵活地为变量之间的关系建模.它首先把记录对pi,j是否匹配视为待推断变量m(pi,j),而把与m(pi,j)相关的其他匹配特征看成是已知变量,m(pi,j)为二元变量.当m(pi,j)=1时,表示ri和rj是匹配的;当m(pi,j)=0时,ri和rj是不匹配的.接着,使用核密度估计和图的连通性来拟合出已知变量和未知变量之间的关系,并形式化为因子图的因子函数.这样,我们就能把不一致记录对消歧问题,建模为一个随机变量概率推断问题,其中因子图中因子的权重使用最大似然估计来推算.
本文的主要贡献有3个方面:
1) 首次提出了一个基于因子图的不一致记录对消歧框架FG-RIP.该框架不依赖标记数据,能通过因子图汇总各种异构匹配特征,如记录对自身匹配特征、匹配传递特征和现存实体解析技术的外部匹配特征,来估算不一致记录对的匹配可能性.
2) 设计并实现了基于最大似然估计的因子权重学习算法.该算法可以自动组合匹配特征的权重,并输出最优的匹配特征权重组合.
3) 在真实的数据集上,大量的实验结果表明该算法能明显提升个体方法的解析效果.
1 不一致记录对消歧问题
实体解析(entity resolution, ER)就是给定记录集合D,识别出所有表示真实世界同一实体的记录对p=(ri,rj),i≠j,其中,ri∈D且rj∈D.如表1所示,文献数据集Cora包括记录的唯一标识rID、论文的作者信息author、标题title和页码信息pages.实体解析就是找出所有表示同一个实体的记录对如p2,3.给定一个实体解析方法M,它的输入是候选记录对的特征,输出是所有预测为匹配的记录对,记为P(M).为了与消歧算法相互区分,本文把现存的实体解析方法称为个体方法.假定一系列个体方法的输出结果如表2所示,pID是记录对的唯一标识符,Mk列为第k个方法的预测结果,其中1≤k≤10,P(positive)(或N(negative))代表记录对的预测状态为匹配(或不匹配);GT(ground truth)列是记录对的真实状态.不一致记录对pinc是只被部分个体方法预测为匹配的记录对,如p2,3.一致记录对pc是被个体方法统一预测为匹配的或者不匹配的记录对.pc包括一致匹配对pcp如p4,5,和一致不匹配对pcn如p7,8.

Table 1 Dataset表1 数据集
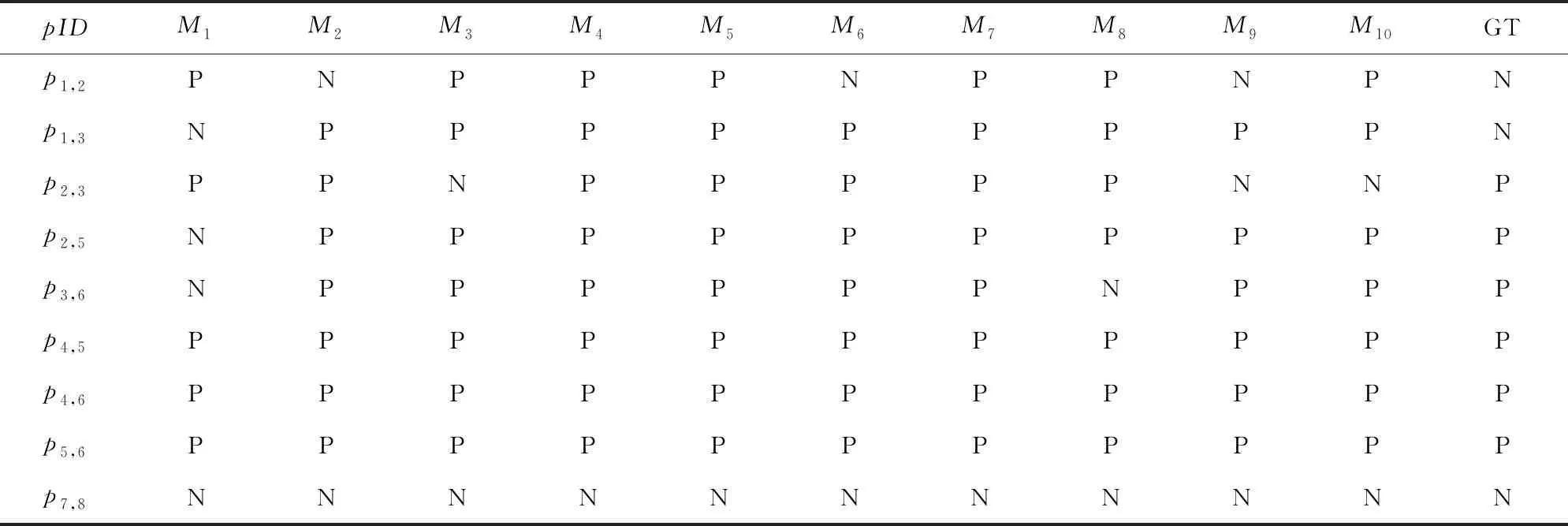
Table 2 Output of Individual Methods表2 个体方法的解析结果
Notes:Mk(k=1,2,…,10) represents the predicted label by thek-th method, GT represents the ground truth label of each record pair,N represents the predicated label of a pair is matching, P represents the predicated label of a pair is non-matching.
所谓不一致记录对的消歧问题,就是给定一系列个体方法和一致记录对集合Pc,推断Pinc中不一致记录对是否匹配.例如表2中不一致记录对的消歧问题就是已知个体方法的解析结果M1,M2,…,M10和一致记录对集合Pc={p4,5,p4,6,p5,6,p7,8},推断Pinc={p1,2,p1,3,p2,3,p2,5,p3,6}中不一致记录对的匹配状态.
2 不一致记录对消歧框架
本节首先概述基于因子图的不一致记录对消歧框架FG-RIP,接着详细介绍它的2个关键模块:基于因子图的异构信息融合(heterogeneous informa-tion fusion based on factor graph)和基于最大似然估计的因子权重学习(learning factor weights based on maximum likelihood estimation).
FG-RIP的处理流程如图1所示:
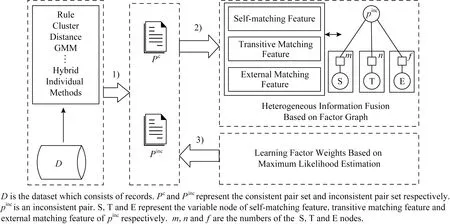
Fig. 1 A workflow for reconciling inconsistent pairs图1 不一致记录对消歧流程图
1) 利用现存的个体方法(individual methods)解析数据集D,并得到Pc和Pinc.
2) 构建自身匹配特征(self-matching feature,缩写为S),即计算记录对的属性值相似度和使用核密度估计来量化不一致记录对的匹配可能性;利用图的连通性构建一致匹配记录对和不一致记录对之间的匹配传递特征(transitive matching feature,缩写为T);利用个体方法的解析结果构建外部匹配特征(external matching feature,缩写为E),进而构建与不一致记录对相关的因子图.
3) 用最大似然估计方法计算因子图中因子的权重.最后使用这些权重估计不一致记录对的边缘概率密度,并判断不一致记录对是否匹配.
2.1 基于因子图的异构信息融合
在概率图模型中,因子图G=(V,E)类似于二部图,其中V(vertices)是顶点集合,E(edges)是顶点之间边的集合.它的顶点集合包括2类节点:因子节点f和变量节点v.边只存在于因子节点和变量节点之间,而因子节点(或变量节点)之间没有边.因子节点定义了与它相连的变量节点的联合概率分布.与二部图的不同点是因子图的因子节点定义了一个概率分布,而二部图没有概率分布的含义.
本文利用因子图把与记录对是否匹配相关的异构信息综合起来,以便量化记录对匹配的概率和不匹配的概率.与不一致记录对是否匹配相关的异构特征有3类:记录对的自身匹配特征、匹配传递特征和外部匹配特征.因子图模型首先把不一致记录对是否匹配,以及与不一致记录对是否匹配的相关特征看成是随机变量,然后构建这些随机变量的联合概率分布.它的处理过程是:1)把不一致记录对(如pi,j)是否匹配m(pi,j)看成是一个二元随机变量,把与m(pi,j)相关的3类特征看成是随机变量集合V,这些随机变量构成因子图的变量节点或因子节点;2)使用指数函数exp(·)来构建V中变量与m(pi,j)之间的函数关系,并作为因子节点的因子函数;3)借鉴最大似然估计的思想计算出各个因子的权重;4)计算pi,j匹配的概率p(m(pi,j)=1|V)和pi,j不匹配的概率p(m(pi,j)=0|V).如果p(m(pi,j)=1|V)大于p(m(pi,j)=0|V),那么pi,j匹配,反之不匹配.为减少不必要的计算,本文所指的概率分布都是未经归一化的概率分布,因为对于某不一致记录对pinc而言,pinc的匹配状态只取决于匹配概率和不匹配概率的相对大小.对未归一化的pinc匹配概率和不匹配概率而言,它们的归一化因子是相同的,使用未归一化的概率值不影响匹配状态的预测结果.
2.1.1 自身匹配特征
记录对的自身匹配特征,主要考虑:1)不一致记录对pinc中相应属性值之间的相似度sim(pinc,nattr);2)使用核密度估计拟合出属性值的相似度sim(pinc,nattr)与记录对是否匹配m(pinc)之间的概率分布.nattr(attribute name)是属性名,sim(·)可以是任意相似度度量.本文使用Jaccard相似系数来度量2个属性值的相似度.
我们把属性值相似度建模为因子节点.该类因子节点的因子函数fS,是m(pinc)与sim(pinc,nattr)之间的分布律,具体数学描述为
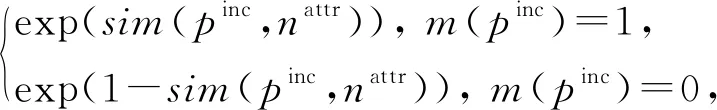
(1)
其中,S(self-matching)代表基于相似度的自身匹配特征;nattr是属性名;sim(pinc,nattr)是pinc的nattr属性值相似度;exp(·)是指数函数;m(pinc)是一个布尔变量,如果m(pinc)=1,那么pinc匹配,否则m(pinc)=0,pinc不匹配.例如表2中p2,3的title属性,有sim(p2,3,title)=1,那么p2,3的因子图包含一个因子节点,且该因子节点的因子函数定义为
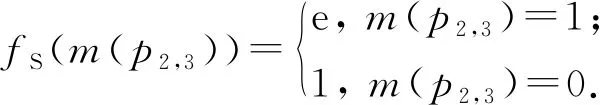
(2)
核密度估计(kernel density estimation, KDE)是一种无参数的密度估计技术,它能够依据样本拟合出属性值相似度和记录对是否匹配之间的概率密度函数.对每个属性nattr,我们使用了所有的一致匹配对集合Pcp和一致不匹配对集合Pcn的子集(也就是在nattr上与Pinc相似的)作为核密度估计的输入样本.对于任意pinc和nattr,依据拟合出的密度函数和属性值相似度sim(pinc,nattr),我们就可以计算pinc匹配不匹配的概率值.匹配的概率值越高,表明pinc匹配的可能性越大.
本文使用scikit-learn提供的核密度估计算法KernelDensity[11].它的核心思想是以给定的一系列样本值作为观察值集合,以一个非线性函数作为核函数,对于某待判断的样本xq,它的概率密度值由观察值集合X的样本与xq的差值决定,具体计算为
(3)
其中,N是样本的数目;n(·)是一个归一化函数,保证p(xq)∈[0,1].h是一个平滑因子,用来权衡偏差和方差.h越大,密度函数p(xq)具有高的偏差,也越光滑;反之,h越小,p(x)具有高的方差,即越不光滑.为了避免核密度估计遇到不连续性问题,本文采用平滑的高斯函数作为核函数:
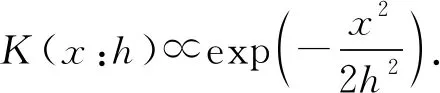
(4)
类似属性值相似度特征,我们把由KDE拟合的记录匹配特征看成是另一种自身匹配特征.这类因子节点的因子函数fSKDE定义为
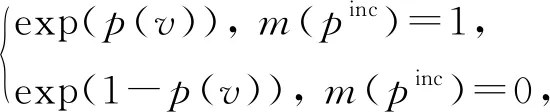
(5)
p(v)=p(sim(pinc,nattr)).
(6)
式(6)是把sim(pinc,nattr)作为式(3)的输入得到的,SKDE(self-matching KDE)代表基于核密度估计的自身匹配特征.
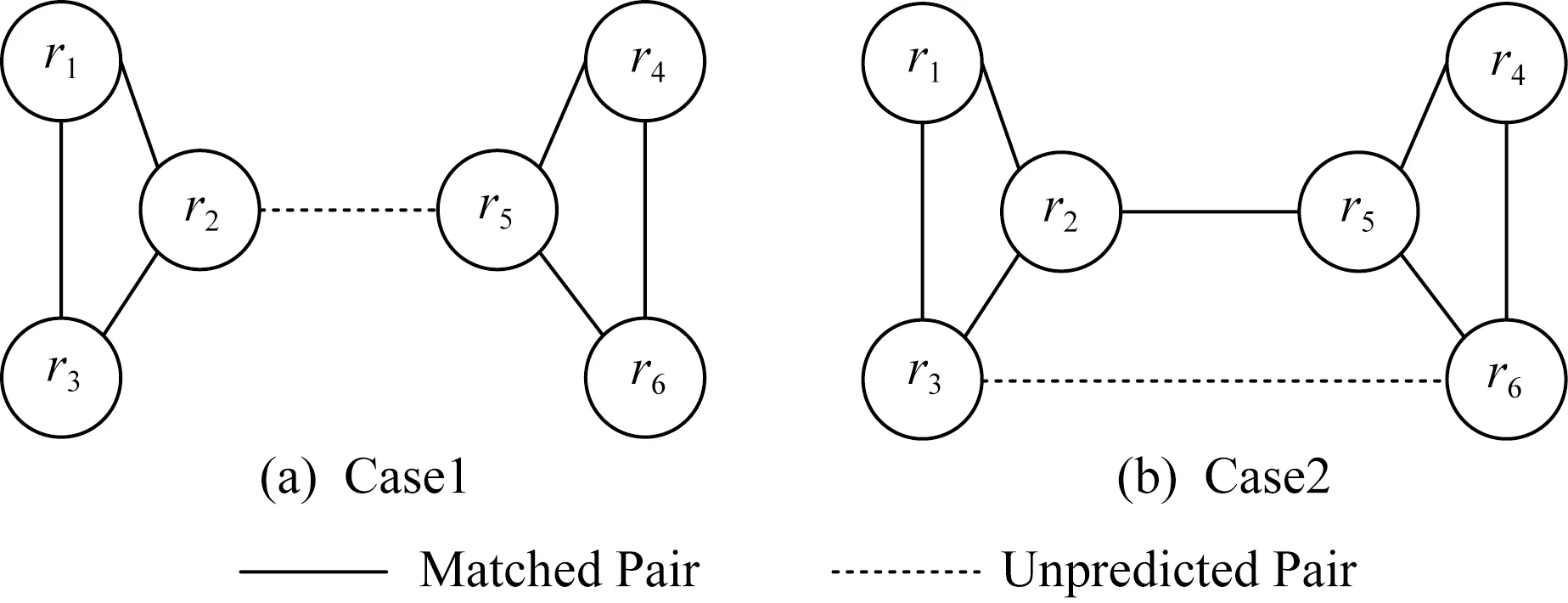
Fig. 2 Relationships among matched pairs and unpredicted pairs图2 匹配的记录对与待预测的记录对之间的关系
2.1.2 匹配传递特征
假设把每个记录看成是无向图的顶点,如果某个记录对被预测为匹配,那么相关的记录之间存在1条实线边,如图2(a)中r1和r2所示.对于待判断记录对如p2,5,该记录对的相关记录之间存在1条虚线边,表示待预测状态.在消歧过程中,处于待预测状态的记录对pi,j可分为2种情况:
情况1.ri和rj分别属于不同的连通图,记为c=1,如图2(a)的r2和r5,c表示记录对所属情况.
情况2.ri和rj属于同一个连通图,记为c=2,如图2(b)的r3和r6.
情况1如图2(a)所示.假设已知记录对p1,2,p1,3,p2,3,p4,5,p4,6,p5,6处于匹配状态,那么记录对p2,5是否匹配的信息可以从r2和r5各自所在的连通图中得到.由实体解析的定义可知,处于匹配状态的记录对p2,3,表明r2和r3是现实世界中同一个实体erec的2个不同描述.对某个属性nattr来说,r2[nattr]和r3[nattr]是erec[nattr]的近似描述.当判断r2和r5是否匹配时,可以用sim(r3[nattr],r5[nattr])作为匹配传递特征.传递特征的因子函数定义与自身匹配特征的因子函数定义类似.
情况2如图2(b)所示.由于p2,5处于匹配状态,待预测记录对p3,6的r3和r6处于同一个连通图.我们在因子图中添加传递变量节点vT和传递因子节点fT.fT的因子函数为
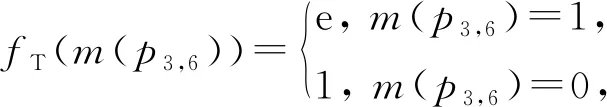
(7)
其中,m(p3,6)是待预测的变量节点,且m(p3,6)=1表示p3,6匹配,而m(p3,6)=0表示p3,6不匹配.为便于陈述,本文把与匹配传递特征相关的节点称为传递变量节点或传递因子节点,并用T(transitive)表示匹配传递特征.
综上所述,对于匹配传递特征,我们按照算法1构建与pinc相关的传递变量节点和传递因子节点.
算法1.匹配传递特征的因子节点和变量节点的构建.
输入:不一致记录对pinc和一致匹配对集合Pcp;
输出:pinc的变量节点、传递变量节点集VT和传递因子节点集FT.
① 根据Pcp构建无向图.
② 对于待预测状态的记录对pinc,利用图的连通性,判断pinc是属于情况1还是情况2.
③ 若pinc属于情况1,首先构建一个待预测变量节点m(pinc),并为它的每个属性nattr构建一个传递变量节点vT∈VT和一个传递因子节点fT∈FT.考虑到某些待预测状态的记录对,会产生较多的匹配传递特征.例如在图2(a)中,p2,5的nattr属性的匹配传递特征包括sim(r3[nattr],r5[nattr]),sim(r1[nattr],r5[nattr]),sim(r2[nattr],r4[nattr]),sim(r2[nattr],r6[nattr]).鉴于此,对于每个属性nattr,本文只选择这些匹配特征中sim(·)最小的,记为ms(pinc,nattr),作为pinc在nattr上传递变量节点vT的变量值.fT的因子函数定义为
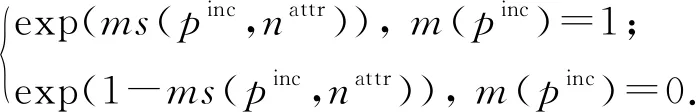
(8)
④ 若pinc属于情况2,首先构建变量节点m(pinc),并为它的每个属性构建一个传递变量节点vT∈VT和一个传递因子节点fT∈FT,其中fT的因子函数定义为
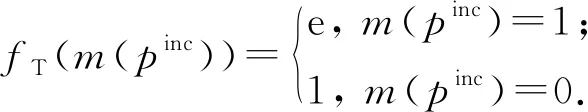
(9)
2.1.3 外部匹配特征
与传统的实体解析方法不同,本文的消歧方法是对传统实体解析方法的结果中不一致记录对进行预测.这些不一致记录对具有个体方法的投票信息.本文把这些投票信息归类为外部匹配特征,并用E(external)表示外部匹配特征.pinc的外部匹配特征包括:1)pinc获得的投票比例;2)个体方法关于pinc的投票信息.
依据pinc获得的投票比例,可构建与源自投票比例的外部匹配特征相关的因子节点和变量节点.假设使用k(k>1)个不同的个体方法,且有Npinc个方法预测pinc为匹配的,那么在因子图中添加因子节点fE、变量节点vE和待预测变量节点m(pinc).其中vE=Npinck,fE(m(pinc),vE)是fE的因子函数,其数学形式为
fE(m(pinc),Npinck)=
(10)

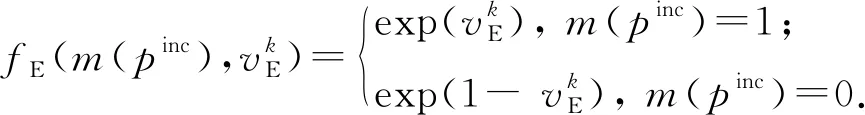
(11)
2.2 基于最大似然估计的因子权重学习
对于某不一致记录对pinc,假设已经得到与它相关的所有因子函数如f1,f2,…,fl,其中l是因子节点的数目,那么pinc是否匹配的变量m(pinc)与所有相关的变量V={v1,v2,…,vl}之间的联合概率密度可定义为
p(m(pinc),v1,v2,…,vl;w1,w2,…,wl)= exp(w1)×f1×exp(w2)×f2×…× exp(wl)×fl,
(12)
其中wi是因子fi的权重.
最大似然估计是一种估计总体分布中未知参数的方法,它的核心思想是概率最大的事件最有可能出现.由于因子节点的权重是未知的,为了估计这些权重,我们采用最大似然估计的思想,极大化观察数据,也就是最大化变量V关于参数W的对数似然函数:
(13)
其中V={v1,v2,…,vl}是除了m(pinc)以外的所有变量集合;W={w1,w2,…,wl}是所有权重的集合;n是待消歧的不一致记录对的数目|Pinc|.
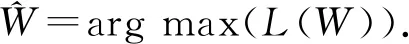
我们使用scipy提供的信任区域约束算法(trust region constrained algorithm)[12]求解有约束的最优化问题.
3 实验与结果
本节概述了实验的运行环境,并在真实数据集Cora和Song上验证算法的有效性.所有实验的运行环境配置为 Intel®CoreTMi7-4710MQ 2.50 GHz处理器、16 GB内存和Ubuntu 16.04 64位的操作系统.编程语言是Python 3.服务器端数据库是MongoDB.
3.1 度量标准
本文采用实体解析文献[5,13-14]广泛使用的查准率、查全率和F1来评价算法的有效性.由于个体方法是从候选记录对开始处理,所以,在与个体方法的对比中,使用的是全部候选记录对的查全率、查准率和F1,而其他实验使用不一致记录对集合的查全率、查准率和F1.所谓查准率是指预测为匹配且真正匹配的记录对数目,与预测为匹配的记录对数目的比值,记为Ppre.查全率是指预测为匹配且真正匹配的记录对数目,与所有真正匹配的记录对数目的比值,记为Rrec.F1是查准率和查全率的调和平均值,具体定义为
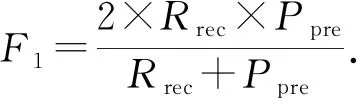
(14)
3.2 数据集
本文在Cora和Song数据集上测试提出的方法.下面我们从数据集特点和记录对方面介绍这2个数据集.
数据集Cora[15]是一个文献数据.它包含1 295个记录,而这些记录隶属于112个实体的某一个.每个记录由12个属性描述如文献的作者列表和标题等.我们将这些记录对两两比较,得到的候选记录对数目为837 865.本文处理的对象是不一致记录对.对Cora数据而言,不一致记录对的数目为44 909,一致匹配对的数目是1 013,而一致不匹配对的数目是791 943.
数据集Song[16]是一个歌曲数据.它包含100 000个记录,每个记录由7个属性描述,例如歌曲的专辑名和发布时间等.我们抽取了其中的20 744个记录进行实验.这些记录对经过blocking技术过滤后,得到的候选记录对的数目是260 181,其中不一致记录对的数目为115 258,一致匹配对的数目为651,一致不匹配对的数目为144 272.
3.3 对比方法概述
本文采用的个体方法总共有11个,包括:1)5个无监督的解析方法,分别是基于RR规则[6]的方法Rule、基于离群距离的方法Distance[2]、基于k-means的Cluster[9]、基于高斯混合模型的GMM[10]、基于狄利克雷过程的变分贝叶斯高斯混合模型DPBGM[17];2)6个基于学习的解析方法,分别是基于支持向量机的SVM[18]、基于决策树模型的CART[19]、基于随机森林的ERT[20]、基于高斯朴素贝叶斯模型的GNB[11]、基于多层感知器的MLP[8]和基于深度学习技术的Hybrid[3].
各个无监督方法的解析过程逐一概述为:Rule方法是使用事先给定的匹配规则来判断记录对是否匹配,其规则形式与文献[6]提出的RR规则相同.Distance方法[2]首先计算离群距离,然后依据离群距离和匹配约束来判断记录对是否匹配.Cluster方法是使用开源的机器学习库scikit-learn来复现文献[9]中提到的k-means聚类解析方法.GMM和DPBGM方法是把实体解析问题等价于将候选记录对划分为匹配组和不匹配组的聚类问题.GMM即高斯混合模型[10],假设匹配记录对和不匹配记录对分别服从2个参数未知的高斯分布,而观测数据来自这2个高斯分布的混合模型.GMM通过EM算法[18]学习该模型的未知参数,进而使用训练好的模型将记录对划分为匹配组和不匹配组.DPBGM是高斯混合模型的一种变体,即高斯混合的变分贝叶斯估计模型.DPBGM与GMM的不同点是,DPBGM使用变分推断估计模型的参数.
基于学习的解析方法SVM,CART,ERT,GNB,MLP是机器学习领域的分类模型.这些模型的主要思想是构建样本特征,训练二分类模型,并预测记录对是否匹配,其中样本的特征是记录对的相应属性值的相似度构成的向量.这些模型的不同点在于模型构建原理.本实验的SVM是非线性支持向量机,其模型构建原理是在特征空间中搜索一个超平面,用来把记录对集合划分为匹配组和不匹配组.CART的模型构建原理是使用特征和阈值构建二叉树,其中每个树节点都具有最大的信息收益.ERT的模型构建原理是首先使用训练集的子样本构建一系列随机决策树,然后使用这些决策树的解析结果均值来进行最终的判断.GNB算法与朴素贝叶斯算法的相同点是基于贝叶斯定理和类条件独立性假设;两者的不同点是GNB假设在给定类标签后,每个特征服从高斯分布.MLP模型是一个二分类的前馈神经网络,本实验中MLP的输入层是记录对的属性相似度特征,输出层是记录对的匹配状态.隐藏层包括2层:第1层的神经元数目是5;第2层的神经元数目是2.它的损失函数是交叉熵损失函数,优化算法是拟牛顿方法L-BFGS.本实验调用scikit-learn库中这些算法的API实现接口[11].本实验的Hybrid算法,首先使用预训练的embedding模型把每个属性的单词序列转换为固定维度的向量序列;然后训练并融合双向序列模型Bi_RNN和序列比对模型来构建属性摘要向量;接着用比较函数计算记录对的属性相似度描述向量;最后多层感知器以训练集的属性相似度描述向量为输入,训练出二分类模型进行实体解析.所有监督或无监督的现存实体解析方法,都可以作为消歧框架的个体方法,但必须有至少2个不依赖标签数据,且有差异的个体方法.这样基于学习的解析方法就可以用有差异的无监督方法的输出结果中的一致的部分作为训练集.有差异的无监督个体方法越多,训练集的纯度越高.所谓训练集的纯度是指训练集中标签正确的记录对所占的比例.
消歧方法GL-RF[21]是针对Clean-Clean ER场景[22]下消歧算法.本文将该算法的匹配约束去掉,修改为可以处理Dirty-Dirty ER场景下的消歧算法,并进行了对比实验.
3.4 实验和结果
本节中,我们进行4组实验来验证FG-RIP的有效性.
实验1.与个体方法进行了对比,验证了FG-RIP算法能自动组合出在F1指标上最好的方法.这些个体方法的实验结果如表3,4所示,最大值已用黑体标出.
Note: The maximum values are in bold.
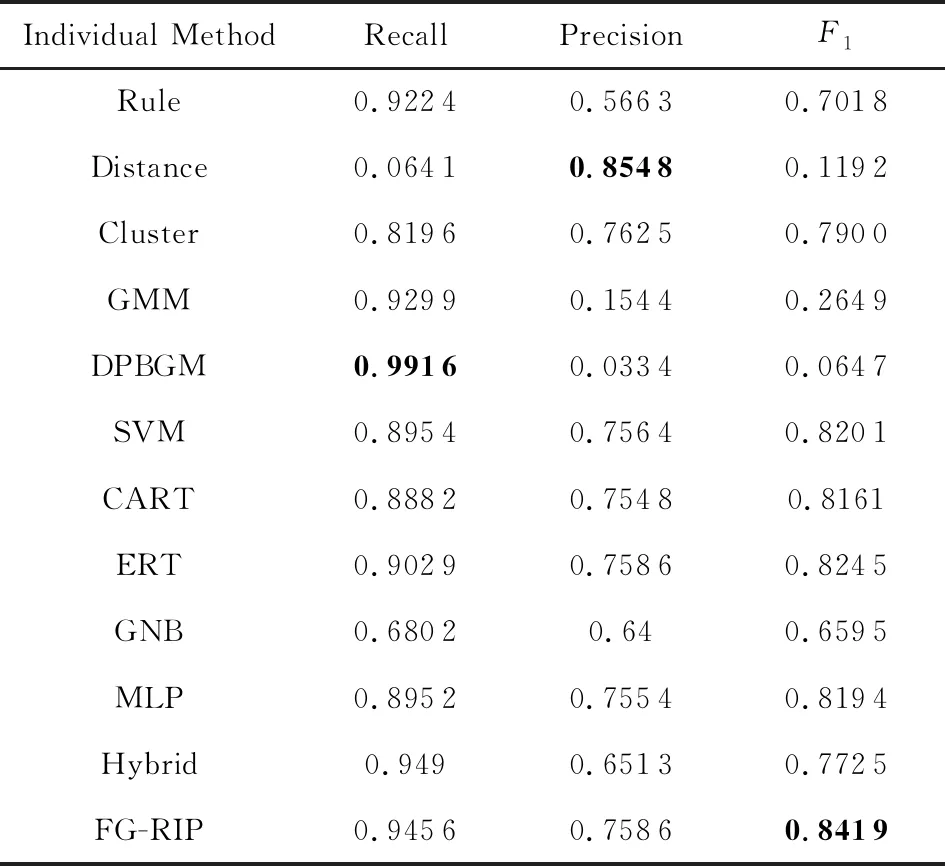
Table 4 Comparison with Individual Methods on Cora表4 Cora数据集上与个体方法的对比
Note: The maximum values are in bold.
由表3,4可以得出:
1) 在相同的数据集上,个体方法各有所长.①对Song数据而言,在所有的个体方法中,Rule具有最高的查全率和相对较高的查准率,这说明了基于属性值相似度和阈值的领域规则能够有效识别出记录对,但存在准确率欠缺的不足.这也表明,查全率高而查准率低的个体方法如Rule,GMM等,有助于过滤掉不匹配的记录对,同时保障真正匹配的记录对以较高的概率落入不一致记录对集合中.另外,尽管GNB具有最高的查准率,但查全率较低.这表明被GNB预测为匹配的记录对,具有较高的可信性.这也表明对于查准率高而查全率低的方法如GNB,可有效保证真正匹配记录对以较高概率落入一致匹配记录对集合中.CART和MLP算法的查准率、查全率和F1均达到90%以上.这表明属性值相似度特征和较少的模型参数就能够为Song数据集训练较好的解析模型.②对Cora数据而言,Distance具有最高的查准率和极低的查全率.这是由于樊峰峰等人[2]提出了一个基于主成分分析的离群距离.对某个记录ri,该离群距离能够找到与该记录匹配概率最高的记录对rj,其中i≠j.对于数据集中某实体erec,假设只有2个记录ri和ri描述该实体erec,那么Distance的解析结果较好.而Cora数据集中erec对应多个记录,使得Distance识别为匹配的记录对,有较高概率是真正匹配的.而其他匹配的记录对被解析为不匹配的,导致了极低的查全率.DPBGM具有最高的查全率,且GMM具有较高的查全率.这些说明在没有标签数据的情况下,选择一个适合所有数据集的方法具有很大的挑战.
2) 在不同的数据集上,大部分个体方法的查准率、查全率和F1有差异.例如SVM在Cora数据上F1值与最高的F1值相差2.18%,却在Song数据上相差43.98%.这是由于SVM模型依赖于来自数据集的支持向量,若这些支持向量无法有效分类样本,则模型的分类效果较差.Hybrid在Cora数据上有较高的查全率,而在Song数据集上有较高的查准率.这是由于文献[3]融合了embedding技术、双向序列模型、序列比对模型和多层感知器来训练出一个二分类模型.由于该模型的参数多(如在Song和Cora数据集上,需要训练的参数数目分别为9 210 006和26 545 814),但训练样本集合(即一致记录对集合)有限,且训练样本集合(一致记录对集合)和测试样本集合(不一致记录对集合)属于不同的分布,导致训练的模型过拟合即在训练数据集上查准率、查全率和F1高达90%以上,而在Song数据集的测试集合上,仅查准率较高;而在Cora数据集上,仅查全率最高.另外,某些个体方法不受数据集差异的影响.比如GMM在Cora和Song数据上均有高达90%以上的查全率和较低的查准率,这说明混合高斯模型对数据的差异不敏感,具有较好的健壮性.
3) 平均来看,监督模型的解析效果优于无监督的.例如对Song数据而言,6个监督模型的平均查全率、查准率和F1,依次为0.674 7,0.911 9,0.756 9;而5个无监督模型的平均查全率、查准率和F1依次为0.735 3,0.367 3,0.423 8.对Cora数据而言,6个监督模型的平均查全率、查准率和F1依次为0.868 5,0.719 4,0.785 4;而5个无监督模型的平均查全率、查准率和F1依次为0.745 5,0.474 3,0.388 1.这表明,尽管在消歧问题上,训练集(一致记录对集合)和测试集(不一致记录对集合)不满足独立同分布,且在理论上,当训练样本和测试样本是独立同分布时,监督模型才有最好的效果,但由于部分监督模型如CART和MLP,具有较好的健壮性,能在非独立同分布场景下,训练出较好的二分类模型.如在Song数据的消歧问题上,CART和MLP的查准率、查全率和F1高达90%.这也表明通过分析一致记录对的特征有助于更好地预测不一致记录对的匹配状态.
4) FG-RIP 能够更准确地解析出更多的匹配记录,具有最好的综合指标F1.由表3,4可知,与其他个体方法相比,FG-RIP具有较高的查准率和查全率.这是由于FG-RIP把个体方法的解析结果作为外部匹配特征,并综合记录对的自身匹配特征和匹配传递特征来进行消歧.在Cora数据集上,虽然FG-RIP的查准率没有Distance高,但它具有最好的综合指标F1.类似地,在Song数据集上,FG-RIP也具有最高的F1值.这些表明,基于因子图的消歧算法FG-RIP能自动组合各类特征,获得最优的综合指标.
实验2.与已存在的消歧方法GL-RF进行了对比.我们分别从Song和Cora数据集的不一致记录对集合中抽取了1 000个和2 000个进行对比实验.如表5,6所示:
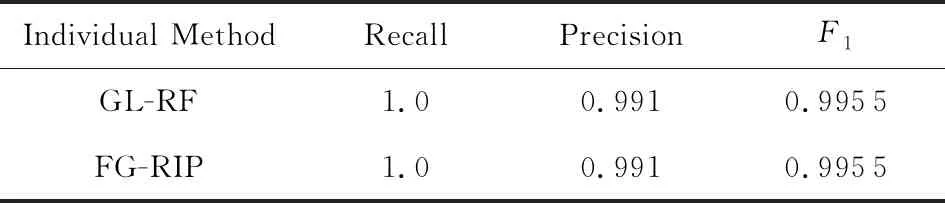
Table 5 Comparison with GL-RF on Song表5 Song数据集上与GL-RF的对比
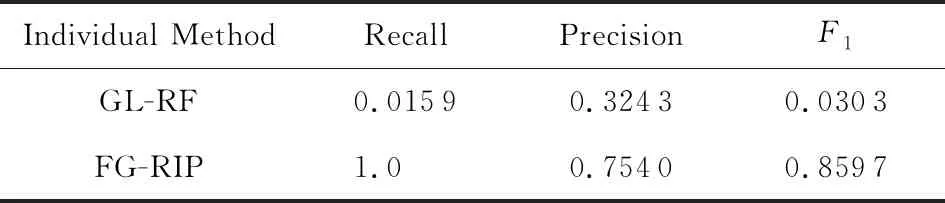
Table 6 Comparison with GL-RF on Cora表6 Cora数据集上与GL-RF的对比
表5,6所示的实验对比结果可得出:
1) 改造后的GL-RF可以有效处理部分Dirty-Dirty ER场景下的不一致记录对消歧问题.由表5可知,在Song数据集上,GL-RF和FG-RIP的实验结果相同.这是由于虽然Song数据属于Dirty-Dirty ER场景,但Song的不一致记录对集中匹配记录对与Clean-Clean ER场景的大体吻合.具体来说,在Clean-Clean ER场景下,某个记录最多有1个与之相匹配的记录.Song数据上,92.81%的记录最多有1个与之匹配的记录;7.19%的记录与2个以上的其他记录相匹配,因而GL-RF能有效地处理这类消歧问题.
2) FG-RIP算法在Cora数据集上优于GL-RF.这是由于:①从数据集的角度看,Cora的不一致记录对集中匹配记录对与Clean-Clean ER场景差异较大.具体来说,Cora数据中,仅6.88%的记录最多有1个与之匹配的记录;93.12%的记录与2个以上的记录相匹配;有的记录甚至有83个与之匹配的记录.这导致改进后的GL-RF在Cora数据中消歧效果有限.②从方法的角度看,GL-RF只考虑了一致记录对和不一致记录对之间的距离关系,适合识别与某个记录最匹配的记录.而FG-RIP把各类匹配特征建模为特征因子,自动组合最优消歧模型,因而能更准确地识别匹配记录对.
实验3.本文使用查准率、查全率和F1指标,分析了不同的因子特征对Cora和Song数据的消歧结果的影响.在图3(a)(b)中,如第2节所述,S,T,E分别代表记录对自身匹配特征、匹配传递特征、外部匹配特征.我们可以观察到:1)匹配传递特征T在2个数据集上均具有较高的查全率.这表明特征T有助于识别更多的匹配记录对.2)记录对自身匹配特征S消歧效果表现不稳定.在Cora数据上,S具有较高的F1,而在Song数据上具有较低的F1.3)外部匹配特征E具有较好的消歧效果.如E的查全率在Cora数据上最高,且F1值高于记录对自身匹配特征S和匹配传递特征T.这表明融合个体方法的特征能有效地发挥个体方法识别匹配记录对的能力.4)所有特征表现稳定,在所有数据集上均能取得较好的效果.以F1指标为例,所有特征的解析效果在Song和Cora数据上达到最高.
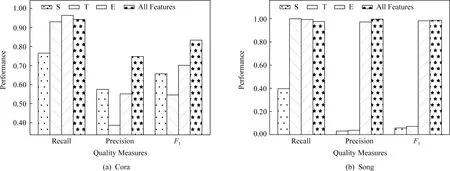
Fig. 3 Performance comparison on different factors图3 不同因子的消歧效果对比
实验4.分析基于相似度的核密度估计技术对FG-RIP方法的影响.如图4所示,KDE代表FG-RIP算法只使用基于相似度的核密度估计特征;-KDE代表FG-RIP算法使用去掉核密度估计特征后所有其他特征.本质上,在相似度值的基础上,用核密度估计技术计算概率值,相当于把原来的相似度特征从线性空间变换到非线性空间.变化后的特征对非线性可分的数据集有效,而对线性可分的数据集效果不明显.由图4的实验结果可知:1)当变化后的特征空间能有效划分候选记录对集合的匹配记录对和不匹配记录对时,基于核密度估计技术的特征可获得较好的消歧效果.如对于Cora而言,与-KDE相比,变化后的特征空间(KDE)有较高的查全率、查准率和F1值,即能提供更好的分类效果;而对于Song而言,原有特征空间(-KDE)的消歧质量指标均高于KDE的消歧质量.2)基于全部特征的消歧算法具有一定的鲁棒性.在核密度估计特征有效时,它的消歧效果略低于核密度估计特征的效果;在核密度估计特征无效时,它受其消歧效果的影响小.①当变化后的特征空间能有效区分匹配对和不匹配对时,仅仅使用基于相似度的核密度估计特征,FG-RIP就能获得最好的消歧效果,甚至在某些质量指标上略高于所有特征.如在Cora数据集上,KDE的查全率和F1值最高.所有特征的查全率和F1值低于KDE的相应值,表明在Cora数据中增加非KDE特征后,质量指标有所下降,但降低的幅度不大,如所有特征的F1值仅减低了0.49%.②当变化后的特征空间不能有效地区分匹配对和不匹配对时,KDE的消歧效果较差.如在Song数据集上,KDE的所有质量指标最低.但所有特征的消歧质量受KDE特征的影响小.由于缺少标签数据,事先评估KDE的消歧效果不可行.鉴于此,在实际应用场景中,建议使用全部的特征,以便消歧算法具有较好的鲁棒性.
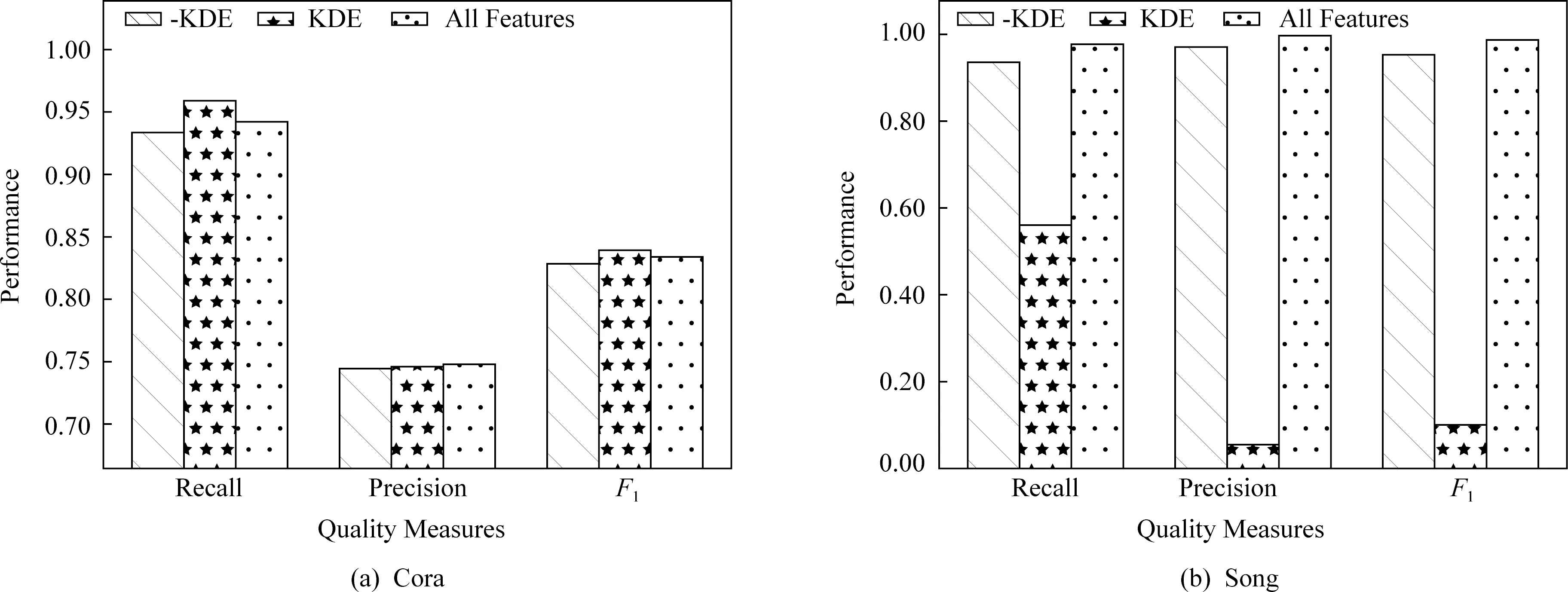
Fig. 4 Performance comparison on kernel density estimation图4 核密度估计的消歧效果对比
4 相关工作
由于实体解析问题是数据集成和清洗系统的核心基础问题,且在很多领域有广泛的应用,领域专家和学者提出了一系列的解析技术.这些相关的工作可划分为三大类:基于学习的[3,5-6]、基于统计的[2,9,23-25]、和基于人机配合的[26-27].
基于学习的实体解析方法[3,5-6]首先使用训练数据集来学习实体匹配的模式或者规则,接着用训练好的模式或规则判定记录对是否匹配.文献[3]提出了4种属性级摘要表示方法(分别是聚合模型(SIF)、基于循环神经网络的序列模型(RNN)、注意力模型(Attention)和基于序列和注意力的混合模型(Hybrid)),并使用神经网络来训练实体解析模型.文献[6]从已知的匹配(和不匹配)记录对集合中学习属性级别的匹配规则集(ARs),并组合这些规则成一系列记录级别的规则集(RRs).文献[5]提出了一种描述记录和实体之间匹配关系的规则(ER-rule),并设计了从训练集中自动学习ER-rule的算法和高效的在线实体解析算法.这些方法都依赖标签数据,且不能解决不一致记录对消歧问题,而我们的方法假设标签数据不存在,侧重于标签数据缺失场景下消歧问题.
基于统计的实体解析方法[2,9,23-25]是通过统计分析记录对的匹配特征,并形式化为某个合适度量,进而选取合适的阈值来将记录对划分为匹配的或者不匹配的.比如文献[23]分别从单词的简写和全写,前缀关系和字符近似匹配方面提出了3种字段匹配度量算法.文献[24]提出了Footrule Distance,用来输出与给定元组最相关的topk个记录值.针对大多数算法未体现关键属性重要性的不足,文献[25]利用信息增益或统计概率的方法计算属性权重,并提出了基于这些属性权重的最终相似度来提升实体解析的准确率.文献[2]提出了离群距离,并证明了离群距离与记录对匹配的可能性是正相关的.这类方法的优点是不需要训练数据集和额外的训练过程,只需要估算出合适的匹配度量和阈值.但由于实体解析应用场景的复杂性,匹配度量和阈值的确定很难做到适用于所有的场景.文献[9]使用统计机器学习的聚类算法如k-means方法,把候选记录对分成两组:匹配组和不匹配组.这类不依赖标签数据的方法都可以作为消歧框架的个体方法,用来对数据集进行预先处理,以得到一致或不一致记录对.
针对全自动的实体解析方法不能彻底解决实体解析问题,基于人机配合的实体解析方法[26-27]提出借用用户的知识以人机配合的方式进行解析.文献[26]将实体解析过程分为设计阶段和执行阶段.设计阶段就是用户在样本数据上使用现成的工具灵活地构建出一个实体解析工作流;在执行阶段,用户可调用支持大数据处理的工具来执行设计好的工作流.文献[27]提出了基于规则的候选记录对生成阶段和基于crowd细化匹配记录对2个阶段.这2个阶段都有人和自动算法的共同参与,这类方法需要人的参与,无法自动完成不一致记录对的消歧处理.
与本文的消歧算法最相关的是GL-RF[21].该算法的核心思想是首先基于TF.IDF计算记录对的向量表示;接着分析与每个不一致记录对距离最近的前k个一致匹配对和一致不匹配对,对于该不一致记录对的影响;最后当前k个一致匹配对的影响大于前k个一致不匹配对时,该不一致记录对为匹配,反之为不匹配.文献[22]依据数据集是否存在重复记录,把实体识别问题区分为3种场景:Clean-Clean ER,Dirty-Clean ER,Dirty-Dirty ER.其中Clean-Clean ER是指左数据源和右数据源都没有重复记录.FG-RIP与GL-RF的区别有2点:1)GL-RF是针对Clean-Clean ER场景,而FG-RIP则是针对Dirty-Dirty ER场景;2)GL-RF没有考虑个体方法的解析结果的可信程度,而FG-RIP使用因子权重来区分个体方法的解析结果.
5 总结和展望
本文研究了在没有标签数据场景下不一致记录对消歧问题,并首次提出了基于因子图的不一致记录对消歧框架.该框架利用因子图融合与不一致记录对相关的特征(包括自身匹配特征、匹配传递特征和外部匹配特征),并使用最大似然估计计算因子图中因子的权重.实验结果表明:该算法能够有效地学习到合适的权重,并自动组合出最优的消歧方案.在没有标签的场景下,自动估计不同特征的解析效果很有挑战性,也具有深远的现实意义.因为自动估计不同特征的解析结果,并选择最优的特征组合,可进一步提升解析的效果.比如在Cora数据集上只使用记录对的基于相似度的核密度估计特征就能获得更好的解析效果.鉴于此,我们把无标签场景下,不同特征消歧结果的质量估计问题作为将来的研究问题.
猜你喜欢
西北林学院学报(2022年5期)2022-10-04
计算机应用与软件(2021年10期)2021-10-15
中学生数理化(高中版.高一使用)(2021年4期)2021-07-19
中等数学(2020年1期)2020-08-24
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
火力与指挥控制(2020年1期)2020-03-27
华人时刊(2018年17期)2018-11-19
语文世界(小学版)(2018年3期)2018-03-22
中学生理科应试(2017年4期)2017-07-08
