
融合隶属度函数的自适应惯性权重模式的粒子群优化算法
2020-01-14 06:35毛焕宇王文东
计算机应用与软件 2020年1期
毛焕宇 王文东
1(浙江纺织服装职业技术学院信息媒体学院 浙江 宁波 315211)2(延安大学数学与计算机科学学院 陕西 延安 716000)
0 引 言
作为一种智能种群优化算法,PSO算法[1]与其他种群进化算法相似,是以随机解组成的种群进行初始化的。不同之处在于,传统的PSO并不仅仅是一次性的适者生存法则,它对于物种行为的模拟,其每一个候选解均与一个进化速率相关。PSO的优势取决于粒子朝着全局最优解进化的收敛速度[2]。粒子群进化算法不仅简单,且运行频率较高,适应性好,广泛应用于多目标最优化和路径规化问题研究中。然而,如何在当前空间的搜索与新搜索空间的开发上取得一定的平衡是粒子群进化的关键问题。对于传统的粒子群优化而言,搜索初期的粒子可以较快收敛至较优解周围,但搜索晚期会出现众多粒子密集聚焦同一区域的情况。文献[3]的研究结果证实,粒子搜索最优解过程中,若惯性权重值过大,则搜索过程近似全局搜索机制,对于新区域的不断搜索会导致粒子过度分散,无法聚焦和收敛,得不到最终稳定的种群;而过小的惯性权重则使得搜索近似局部搜索机制,粒子收敛过快,而陷入局部极值点中。
文献[4]提出通过一种模糊控制机制和随机化方法,实现对粒子迭代进化中的惯性权重调整,但是得到的粒子收敛性性能并不理想,原因在于其算法计算复杂度较高,计算时间过长。文献[5]引入一种收敛因子对种群进行迭代处理,以一种参数动态配置方法防止部分种群粒子的进化方向出现过大偏离,无法到达最优区域,可以实现控制收敛。文献[6]提出一种动态拓扑结构控制粒子移动,使初始阶段的进化过程中邻居粒子数量降低,随着迭代搜索的进行,再根据粒子间距更新粒子活动邻近区域,极大地提升了粒子种群的多样性,但算法收敛需要的迭代次数较大。文献[7]将集群化的粒子群中的中心粒子视为最优粒子,将聚类后得到的全局聚类中心作为全局最优粒子,进而以聚类的方式实现了最优粒子的邻近区域的更新规则。文献[8]设计一种动态聚簇的粒子群算法,使相近特点的粒子可组成群,以群体方式共同进化,以此改变粒子寻优性能。文献[9]则利用小世界网络思想改善粒子寻优能力,避免了种群早熟。
不同于以上工作,本文在每次迭代过程中更新粒子速度的同时,将当前的参考粒子与全局种群的最优粒子间的距离考虑到进化过程中,并根据该距离值,设计一种隶属度函数动态地为粒子调整其惯性权重。该自适应的调整方法使得离最优粒子较远的粒子可以拥有更大的惯性权重,从而提高全局搜索性能,而离最优粒子较近的粒子可以拥有更小的惯性权重,提高其局部搜索性能。
1 粒子群优化及其早熟分析
对于PSO,设m个粒子分布在d维度空间中,每个粒子的维度以速度和位置进行描述,在t次迭代时,分别表示为:
(1)
迭代过程中,单个粒子已搜索到的最优位置表示为Pi=(pi1,pi2,…,pid),将其称为pbest,即个体最优解。而所有粒子搜索到的最优位置为Pg=(pg1,pg2,…,pgd),即全局最优gbest。PSO即是所有粒子更新其粒子速度和位置的寻优过程,可表示为:
(2)
式中:t表示迭代次数;d表示搜索空间的维度;w表示惯性权重值,w∈[0.1,0.9];rand()表示随机数,rand()∈[0,1];c1和c2为常量,称为认知因子。
对于传统的粒子群而言,更小的惯性权重更利于局部搜索,惯性权重增加则利于全局搜索。因此,若w值在迭代过程中保持恒定不变会降低PSO的性能。文献[10-11]中的研究表明,w值在迭代过程中的线性降低可以明显地增强PSO的收敛性能。具体方式为:赋予迭代初期的粒子更优的全局搜索能力,而赋予迭代后期的粒子更优的局部搜索能力。换言之,在迭代过程早期,需要设置较大w值;在迭代过程晚期,需要设置较小w值。针对这一问题,文献[12]通过利用惯性权重最值wmax和wmin设计了一种线性递减机制对w值进行动态调整:
(3)
式中:tmax为种群迭代的最大次数。
式(3)中的惯性权重调整策略表明w值是线性递减的,而线性递减并不能表现粒子间的差异。为了反映每次迭代过程中粒子间的差异,根据粒子间距,本文利用隶属度函数的概念,设计了一种可对粒子惯性权重进行自适应更新的改进粒子群算法。并且,为了使得具有更高适应度的粒子被选择为全局最优粒子的概率更大,还设计了一种Roulette(轮盘赌)方法进行最优粒子的选择。
2 基于自适应惯性权重的粒子群算法
2.1 粒子间的距离度量
定义1以Xi=[xi1,xi2,…,xid]表示粒子i,f表示粒子的适应度,种群中粒子i与粒子j间的距离定义为:
(4)
根据定义1可知,对于任意粒子i、j和k,粒子间的距离将具备以下性质:
性质1非负性。粒子i和j间的距离是非负的,即D(i,j)≥0。
性质2粒子与本身间的距离为零值,即D(i,i)=0。
性质3对称性。粒子i到粒子j的距离等于粒子j和粒子i的距离,即D(i,j)=D(j,i)。
性质4粒子间的距离满足三角形边长性质,即D(i,j)≤D(i,k)+D(k,j)。
不同于其他粒子距离度量方法,式(4)利用曼哈坦距离(Manhattan Distance)[13]度量粒子间距,不仅考虑了无关参数间的距离,而且还考虑了目标函数间的距离。
定义2粒子间的最大距离定义为:
Dmax=max{D(i,j)}
(5)
定义3若N为粒子数量,粒子间的平均距离为所有粒子对的间距之和与粒子数量的商值,可定义为:
(6)
定义4粒子与种群中的最优粒子间的平均距离定义为:
(7)
2.2 隶属度函数及其自适应规则
对于PSO, 粒子速度的惯性权重更新仅与当前迭代的次数相关,并未考虑粒子本身的特点。现实情况是:粒子需要以自身与最优粒子间距离为依据,动态调整惯性权重值。当粒子与最优粒子相距较远时,粒子需要拥有更大的惯性权重,这有助于搜索全局最优,并更快地收敛。若粒子距离最优粒子较近,则应该赋予更小惯性权重。基于此,根据D(i,pg)和惯性权重w,算法设计以下模糊规则:
规则1:若D(i,pg)较小,则惯性权重w也较小;
规则2:若D(i,pg)中等,则惯性权重w也中等;
规则3:若D(i,pg)较大,则惯性权重w也较大。
PSO-AIWA算法中D(i,pg)与w的隶属度函数[14]如图1和图2所示,图中δ和θ表示隶属度因子。
进行粒子更新时,若仅考虑粒子最优位置pi和全局最优粒子Pg,可能导致最终得到局部最优。针对该问题,算法选择若干个最优粒子在确定距离内参与迭代过程。具体地,在每次迭代中,选择任意k个全局最优粒子为候选粒子,通过Roulette方法从k个粒子选择最终的全局最优粒子。
为了使单个具有更大适应度的粒子当选为全局最优粒子的概率更高,需要增加拥有更大适应度粒子的惯性权重。在k个全局最优粒子中,计算选择粒子m为全局最优粒子的概率为:
(8)
式中:fit(x)表示粒子x的适应度。
(9)
利用Roulette方法,对于任意的r∈[0,1],如果式(10)得到满足,则粒子m被选择为全局最优粒子。
(10)
本文提出的PSO-AIWA算法将根据粒子与最优粒子间距对惯性权重进行动态调整。当粒子与最优粒子间的距离大于门限值TH时,粒子则拥有更大的惯性权重;反之则赋予更小值。门限值TH设置为Daverage。粒子惯性权重的自适应调整方式为:
(11)
式中:pg表示通过Roulette方法选择的种群中的全局最优粒子;wmax和wmin分别表示惯性权重值的最大值与最小值。
算法1给出了PSO-AIWA算法的伪代码。
算法1PSO-AIWA算法
1. 输入:tmax,N,k,wmax,wmin,c1,c2,δ,θ
2. 输出:全局最优解pg
3. 初始化粒子种群
4. 计算最优粒子pi和pg
5. 当t≤tmax
6. 计算粒子距离Daverage
7. 计算距离的隶属度
8. 利用轮盘转选择规则计算w
9. 根据式(2)更新粒子速度和位置
10. 更新最优粒子pi和pg
11. 更新迭代次数t
12. 返回全局最优解pg
算法输入参数包括:最大迭代次数、粒子总数、候选粒子数量、惯性权重最大值和最小值、认知因子、隶属度因子,算法输出全局最优粒子,即步骤1和步骤2。步骤3初始化种群粒子,包括粒子位置和速率。步骤4获取初始种群的最优粒子。步骤5表明,若当前迭代次数小于或等于最大迭代次数。步骤6计算粒子间的平均距离。步骤7计算基于粒子距离的隶属度。步骤8利用Roulette方法与相应的模糊规则计算当前的惯性权重。步骤9利用式(2)对粒子速度和位置进行更新。步骤10更新当前粒子搜索到的最优位置和所有粒子的最优位置。步骤11更新迭代次数,返回步骤5继续搜索过程。最终在步骤12返回收敛的全局最优粒子,即最优解。
3 仿真实验
3.1 实验配置与基准函数
利用MATLAB平台实现了融合隶属度函数的自适应惯性权重粒子群算法的仿真测试。选取6种基准算法,包括:Sphere函数、Rastrigin函数、Rosenbrocks函数、Quadric函数、Griewank函数和Rotated Quadric函数,以上测试函数是广泛应用于粒子群进化问题测试的经典函数。6种基准函数中,Rosenbrocks函数、Rastrigin函数、Rotated Quadric函数和Griewank函数为多峰值函数,其他函数为单峰值函数。表1给出了以上6种基准函数的相关搜索参数声明。表2给出了算法中属于粒子群的相关参数设置。为了证明算法性能的有效性,使用随机惯性权重的经典PSO算法和线性惯性权重的PSO-LDIW算法[12]作为性能的对比算法。
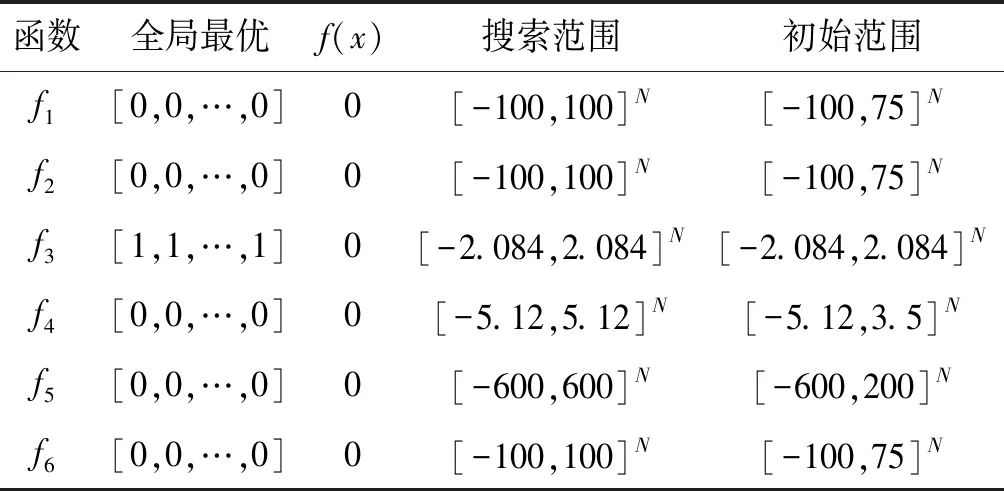
表1 测试函数声明

表2 参数设置
1) Sphere函数:
(12)
2) Quadric函数:
(13)
3) Rosenbrocks函数:
(14)
4) Rastrigin函数:
(15)
5) Griewank函数:
(16)
6) Rotated Quadric函数:
(17)
3.2 实验结果
1) 种群粒子分布情况。实验1观察了3种算法利用测试基准函数f5得到的迭代次数分别为50、100和200时的粒子分布情况,结果如图3所示。种群中粒子的分布可以一定程度地反映种群个体的多样性。PSO利用的是随机化的惯性权重值对粒子状态进行调整,所得到的种群粒子分布在不同的迭代次数下始终处于较为分散的状态,即图3(a)。在粒子进化的后期,部分粒子已经逐渐陷入一些局部极值点的区域内,即使继续进行状态进化与搜索,也无法有进一步改进。相比随机惯性权重PSO,PSO-LDIW算法在全局收敛性上表现更加优秀,其多数粒子均可以在迭代次数的后期逐渐进入到全局最优点的区域内,原因在于该算法利用惯性权重值是线性递减式改变的,寻优性能得到了提升。而本文提出的PSO-AIWA算法比较另外两种算法而言,其粒子具有更好的聚集性,粒子进化过程中并没有过早地使自身聚焦至局部极值点附近的区域,从而导致早熟,影响整体寻优结果。主要原因在于:PSO-AIWA算法可以根据设计隶属度函数动态的调整粒子惯性权重,而隶属度函数又是基于当前粒子与全局最优粒子间的距离得到的。

(a) 利用随机惯性权重的PSO粒子分布
(b) 利用线性递减惯性权重的PSO-LDIW粒子分布

(c) 利用隶属度的动态自适应惯性权重的PSO-AIWA粒子分布图3 种群粒子分布情况
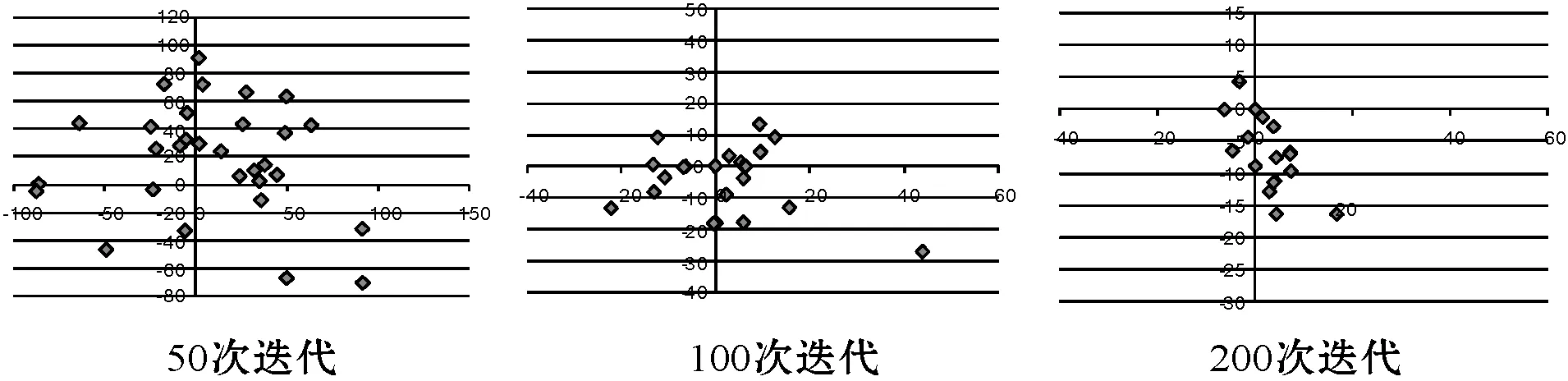
2) 算法收敛性。实验2观察了3种算法的收敛性性能,实验目的是比较3种算法在拥有相同初始数据情况下的收敛速度和效率。实验在完全相同的条件下测试了所有6种基准函数下的收敛性能,其他参数与实验1也是相同的。从图4的结果可以看到,无论是单峰值基准函数还是多峰值基准函数情况,PSO-AIWA算法在收敛速度和精确度上均要优于PSO算法和PSO-LDIW算法。测试中,在搜索能力上,PSO-LDIW算法要优于传统PSO算法。而PSO-AIWA算法比PSO-LDIW算法则表现出更好的性能,其搜索能力更佳。综合来看,采用自适应惯性权重调整机制的PSO-AIWA算法可以从根本上改善对比算法中对惯性权重的单一计算方式,降低搜索性能对于初始参数设置的过多依赖。
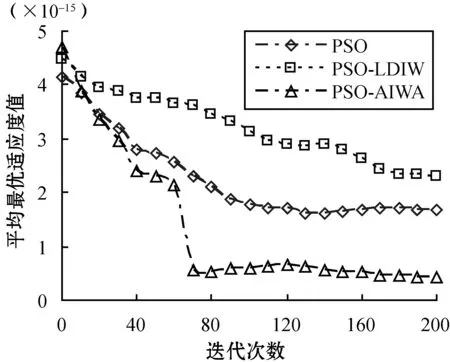
(a) Sphere函数
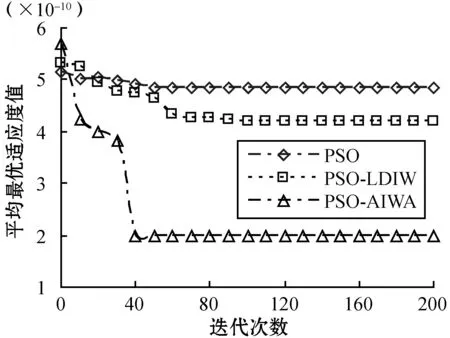
(b) Quadric函数

(c) Rosenbrocks函数
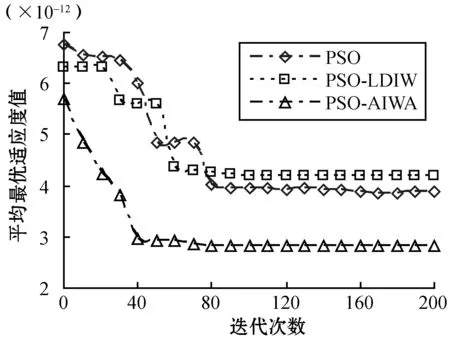
(d) Rastrigin函数
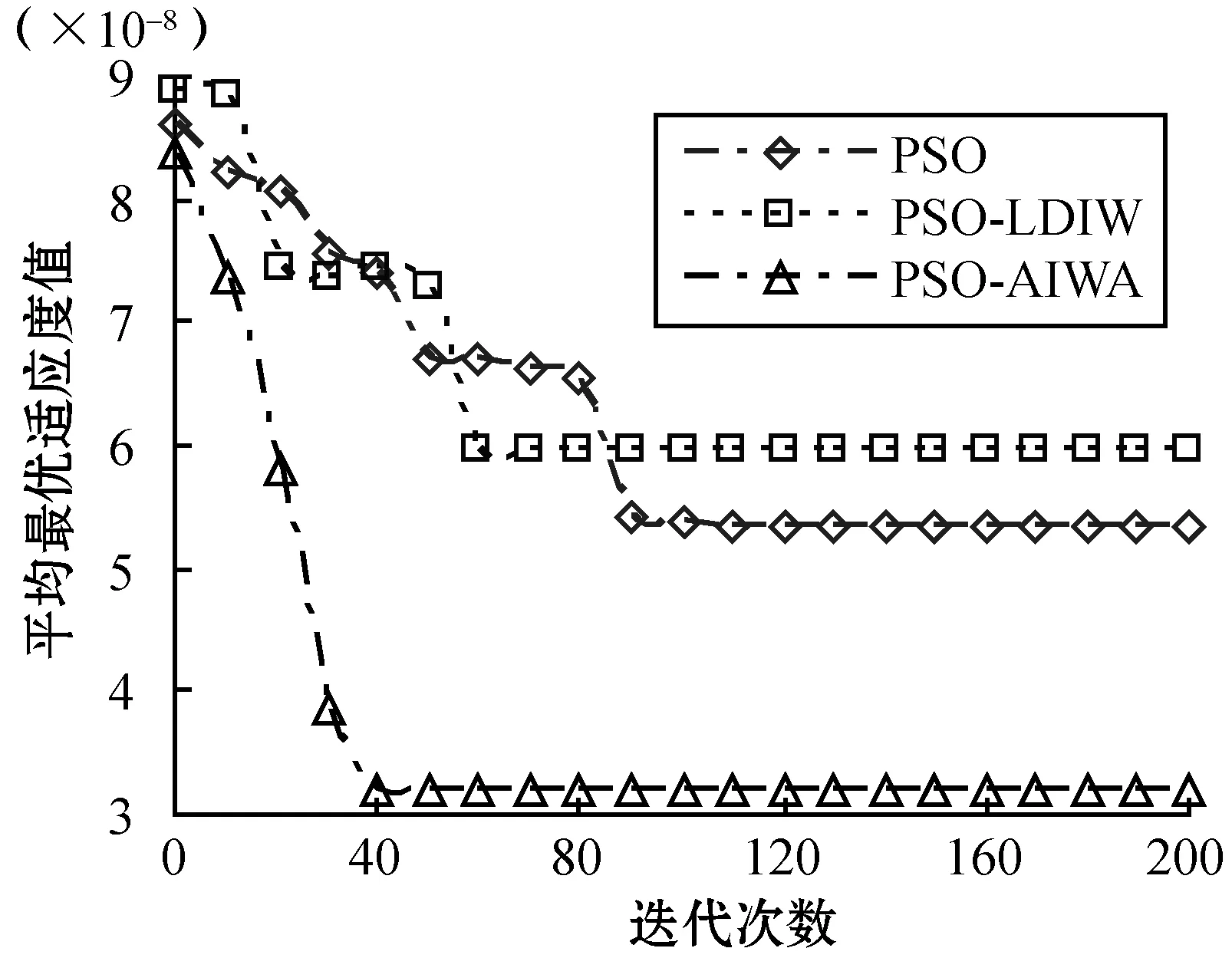
(e) Griewank函数
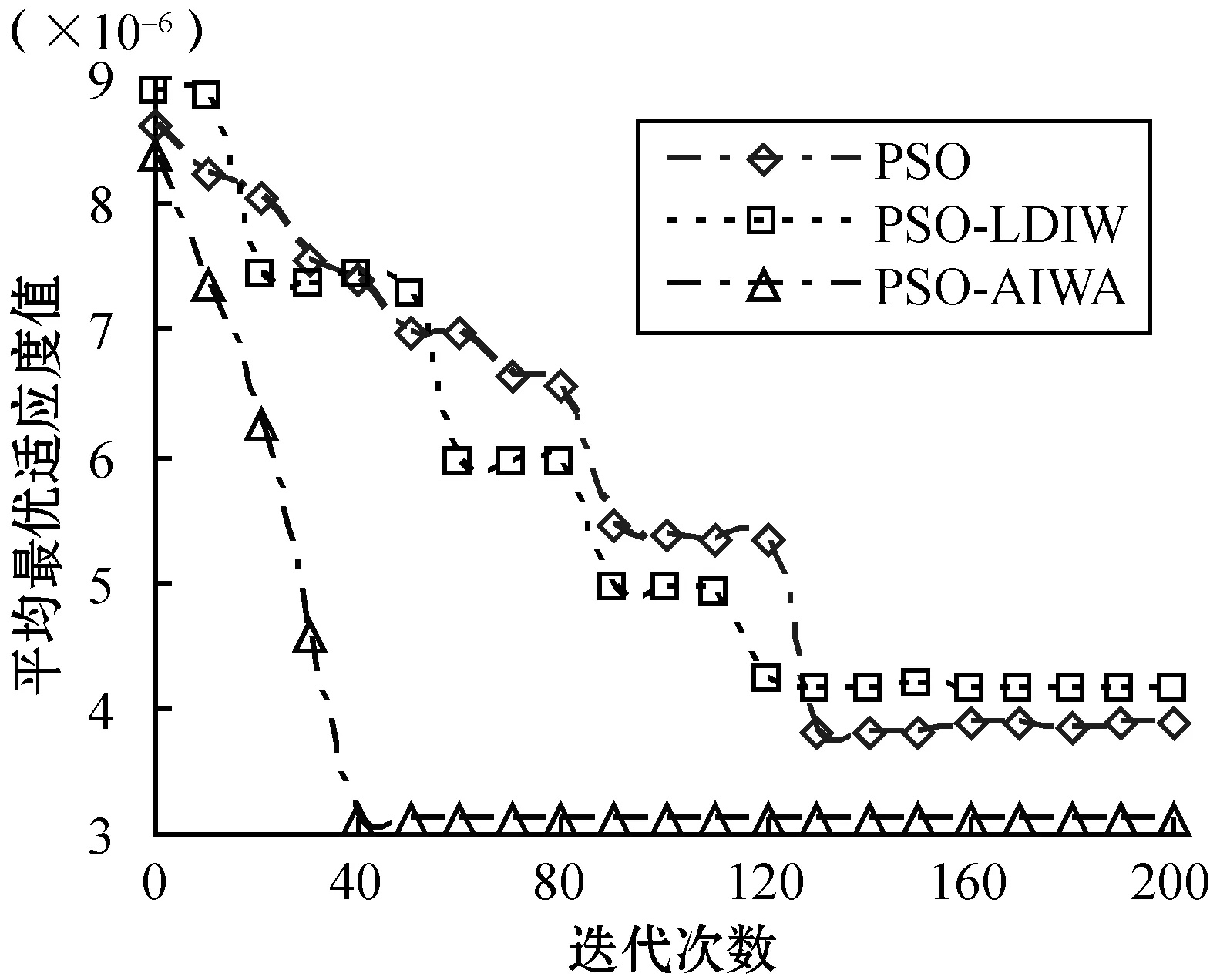
(f) Rotated Quadric函数图4 最优适应度收敛性
3) 性能的统计分析。实验3以统计方法观察算法得到的适应度值的变化,结果如表3所示。由于在可行区域中仅有一个全局极值点,且越接近极值点其变化越小,选择Sphere函数进行本实验的测试。结果表明,相同条件下,PSO-AIWA算法和PSO-LDIW算法得到的结果的准确性上明显优于随机惯性权重PSO,这表明惯性权重的调整策略在改进粒子个体多样性和维持迭代进化的性能上是有效可行的。相比PSO-LDIW算法,PSO-AIWA算法则拥有更佳的表现,在相同的配置条件下,其得到的最小值、最大值和平均最优值更接近于全局最优,这表明本文所设计的基于隶属度的惯性权重自适应调整策略是可以增强粒子个体的搜索能力的,在最优粒子的影响下,其粒子进化方向选择更优。另外,在多峰值测试基准函数下,PSO-AIWA算法同样优于PSO-LDIW和PSO算法。在20次的实验中,比较PSO、PSO-AIWA和PSO-LDIW算法得到的结果显然更加接近于全局最小值,这表明粒子惯性权重的自适应更改可以增加粒子的搜索能力。而本文在不同阶段中所应用的惯性权重自适应调整策略则有效地提升了粒子进化,更好地指导了粒子的寻优。
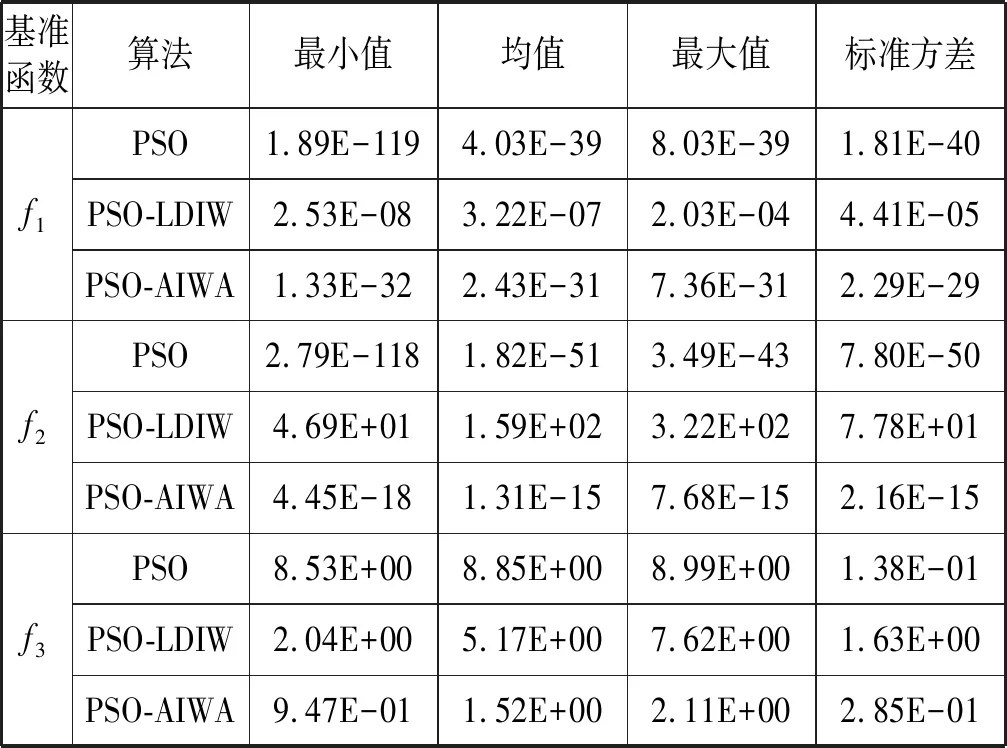
表3 统计结果
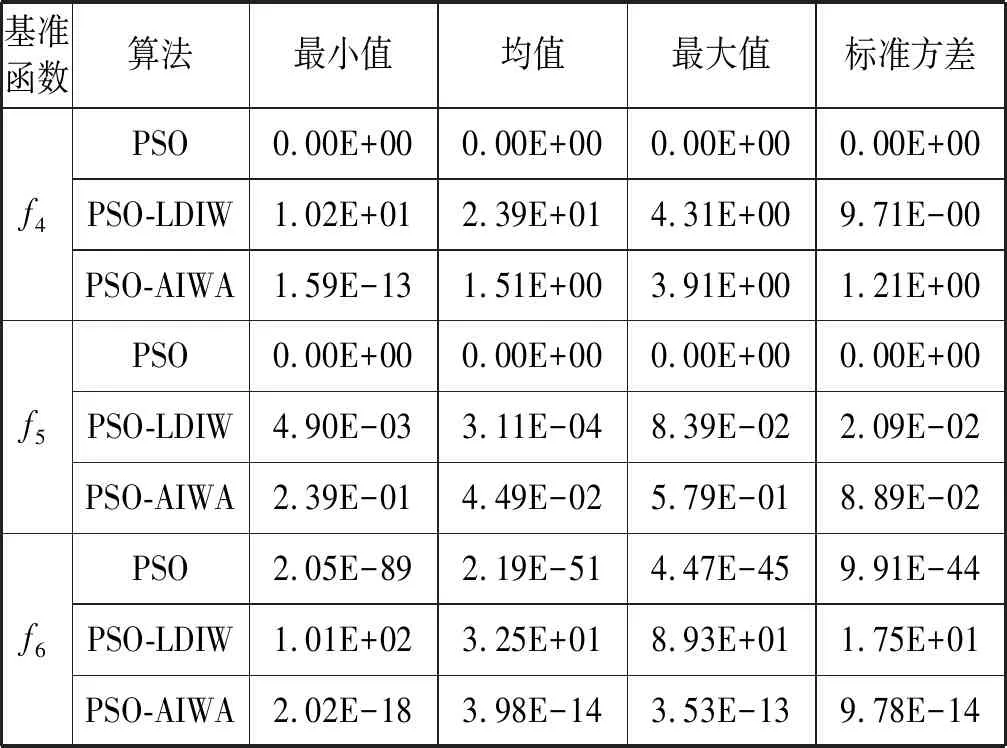
续表3
综合以上的分析,在算法得到的粒子分布性能方面,本文算法得到的粒子分布相对于其他算法可以更快地实现粒子的聚集。一方面证明了利用隶属度的动态自适应惯性权重调整机制是有效可行的,另一方面也证实了它对随机惯性权重和线性递减惯性权重能够更好地描述粒子的差异,给予不同粒子不同程度的寻优方向和寻优能力,有效避免了粒子陷入局部最优。粒子较好的聚焦性也显示出算法也将具有更好的收敛性,即图4的结果;更快地收敛可使得粒子得到的平均适应度会趋于稳定,即表明已搜索到全局最优解上。在粒子适应度值的统计分析上,本文算法得到的适应度值也是优于对比算法的,这表明惯性权重的调整策略在改进粒子个体多样性和维持迭代进化的性能上是有效可行的。同时,无论是利用多峰函数还是单峰函数进行测试,结果都比较稳定,这表明粒子惯性权重的自适应更改可以增加粒子的搜索能力,不会由于测试基准函数性质的改变而改变粒子的寻优性能。
4 结 语
本文为粒子群算法设计了一种新的惯性权重自适应调整策略,解决了传统粒子群算法忽略粒子间的差异,利用相同的惯性权重到所有种群粒子上的缺陷。算法的主要思想是可以根据与全局最优粒子间的(距离)不同,通过基于粒子间距的隶属度函数动态调整粒子的惯性权重,使得每次迭代中,粒子可以根据当前状态在每个维度上的搜索空间内选择合适的惯性权重进行状态更新。通过覆盖单峰函数和多峰函数的6组基准函数进行了大量仿真实验,结果表明,比较随机式惯性权重和线性递减式惯性权重的调整策略,本文算法在收敛速度、求解准确性及参数敏感性上均表现出了更好的效果。
猜你喜欢
计算机仿真(2022年8期)2022-09-28
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
北京航空航天大学学报(2022年6期)2022-07-02
现代计算机(2019年19期)2019-08-12
金桥(2018年4期)2018-09-26
当代旅游(2016年10期)2017-04-17
财经理论与实践(2015年2期)2015-04-16
中学生数理化·八年级物理人教版(2014年1期)2015-01-09
中学生数理化·八年级物理人教版(2014年1期)2015-01-09
