
基于Web日志的性格预测与群体画像方法研究
2020-02-08 08:16康海燕
郑州大学学报(理学版) 2020年1期
康海燕, 李 昊
(1.北京信息科技大学 信息管理学院 北京 100192; 2.北京信息科技大学 计算机学院 北京 100192)
0 引言
用户画像[1]是通过对用户的社会属性、日常生活习惯和消费行为等数据信息进行分析和挖掘,从而抽象出用标签形式进行表示的用户模型。贴“标签”是组织构建用户画像系统的核心任务,标签就是经过对数据分析后用户信息高度精练的特征标识。
目前,用户画像技术飞速发展,正逐渐被应用到社交媒体、电商、移动等多个领域。Mueller等[2]通过Twitter用户的用户名信息和识别用户性别,构建了多种词语结构特征和Twitter用户画像,但是没有提取用户访问Twitter的主题。Marquardt等[3]以文本为基础,提出了通过多种标签的分类方法来构建用户的性别及年龄画像,但是没有融合用户访问文本的兴趣属性。Zhu等[4]利用用户情景日志,构建了一种在情境感知背景下的移动用户画像构建方法,但是没有对可能存在危险的用户进行行为预测。虽然用户画像已成为当前的一个热门话题,但是目前针对群体用户性格属性的画像及行为预测的研究还很缺乏[5]。
Web日志挖掘属于Web挖掘的一部分,目前基于文本内容的检索和文本分类技术是Web内容挖掘研究的主要方向。随着对Web日志数据挖掘的深入研究,国内外的很多学者发现Web日志数据的研究将会在很大程度上反映及预测用户的浏览趋势和兴趣爱好。Guerbas[6]等提出了一种有效的在线预测的新方法,对Web日志挖掘过程和在线导航模式预测进行增强,但是没有对词频-逆文本率(term frequency-inverse document frequency,TF-IDF)的计算方式进行改进。郭俊霞[7]等提出了一种针对用户网页浏览日志数据的查询和行为分析方法,但是没有挖掘出用户查询访问网页的主题。张宏鑫[8]等提出一种基于移动应用程序日志数据的人群特征分析与画像方法,有效提取了移动终端用户的特征,但是没有深层次地预测聚类人群的代表性格属性特征。Zhou[9]等通过对社交网络中数据的分析,将人格作为用户属性的一个特征维度进行推测,但是建模通过众包的方式填写问卷取得,没有提出一种自动化的人格预测方法。Golbeck[10]等通过关注Twitter用户的推文,利用机器学习算法对用户的人格进行预测,但是没有将用户的人格、访问推文的主题和关键词进行综合建模。Gao[11]等通过提取新浪用户访问的文本内容,对用户微博的内容总数和情感词等特征进行分析,获取其大五人格分数,但是没有提出基于单一用户的群体画像方法,如何对具有潜在危险型人格的用户进行行为预测。根据以上文献对日志挖掘或用户性格预测存在的问题,提出一种基于大五人格的用户性格深度挖掘和预测方法。
本文主要贡献:1) 改进传统TF-IDF方法没有考虑文章结构的问题。在挖掘网页关键词时考虑文章结构对结果的影响,为不同位置的词配以权重提高算法挖掘的准确率。 2) 首次提出“性格-主题-关键词”模型。根据大五人格理论将心理学与画像技术相结合,建立用户性格画像知识库。 3) 首次将Web日志的挖掘引入到深层次的用户性格挖掘,对其性格属性特征进行预测。 4) 提出了基于单一用户画像技术的群体用户画像技术。使用K-means方法将拥有相同属性特征和性格的人群进行聚类并可视化,达到描绘在社会中拥有相似特征群体的面貌。
1 日志数据与用户画像建模
1.1 日志数据的介绍
日志数据通常用纯文本文件记录用户的访问记录。每条日志文件记录的格式通常为: date time/c-ip/cs-username/s-ip/s-port/cs-method/cs-uri-stem/cs-uri-query/sc-staus cs(user-agent)。
本文选取日志挖掘用到的7个数据进行分析,分别为date time(日期时间)、c-ip(用户IP)、s-port(服务器端口)、cs-method(请求方法)、cs-uri-stem(访问的URL)、sc-staus(应答状态)和cs-uri-stem(用户代理)。
1.2 用户画像技术建模
用户画像技术模型分为数据采集、数据预处理、数据挖掘、用户画像和群体画像5个模块。系统总流程如图1所示。
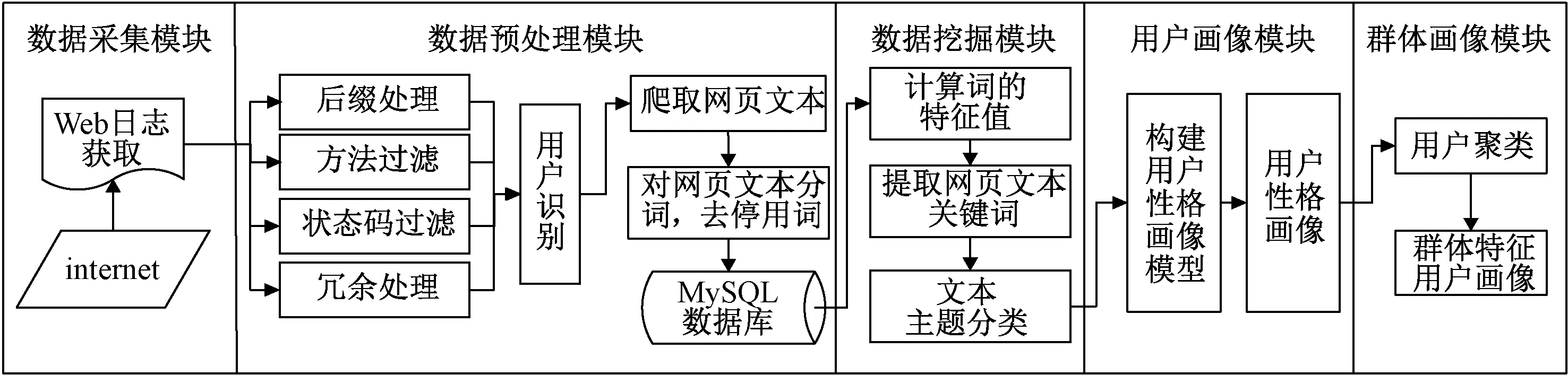
图1 系统流程图Figure 1 System flow chart
系统实现的具体步骤如下。
第1步:数据源获取。通过下载互联网中用户的Web日志建立原始数据库。
第2步:数据预处理。首先通过后缀处理、方法过滤、状态码过滤和冗余处理等方法对日志数据进行清洗。进而通过日志中IP的识别和操作系统的识别来辨别用户身份的唯一性。然后使用网络爬虫获取每条URL所对应的网页文本,并对获取的原始文本进行分词、去停用词等预处理操作。
第3步:提取用户的属性特征。本文通过改进后的TF-IDF算法计算词特征值,将特征值最高的词作为网页文本的关键词。通过K近邻(Knearest neighbor,KNN)文本分类算法对网页文本进行主题归类。
第4步:用户画像。通过大五类性格进行“性格-主题-关键词”模型构建,对拥有不同关键词和主题的用户进行性格分类及预测。把用户的属性特征抽象成标签形式,从而可以更加直观、方便地对用户的性格及属性进行可视化,并且对拥有危险性格倾向用户进行预测[12]。
第5步:群体画像。通过对用户兴趣特征和性格特征进行结合,使用K-means方法将拥有相同属性特征的人群进行聚类。观察算法收敛后聚类中心点的属性特征,从而达到描绘在社会中拥有相似特征群体的面貌。
2 Web日志的挖掘
2.1 日志数据预处理
通过数据清洗、用户识别、网页文本获取和分词、去停用词和词性标注等网页文本预处理后将日志数据统一格式标准存入用户数据库。
2.2 日志数据挖掘
2.2.1基于TF-IDF的关键词提取技术 TF-IDF算法是一种应用非常广泛的关键词提取方法[13]。TF-IDF 算法的核心是通过统计文档中词的词频达到计算词权重的目的,其算法包括:
1) 词频(term frequency)。某个词项在一个文本中出现的次数越多,它和文本的主题越相关。
2) 逆文本频率(inverse document frequency)。某个词在文本集合的多篇文本中出现次数越多,该词的区分能力越差。利用上述概念计算每一个词wi的TF-IDF值, 通常采用公式
TF-IDF(wi)=tf(wi)·idf(wi)=tfj(wi)·log(N/df(wi)),
(1)
式中:tfj(wi)表示当前词wi在文本j中出现的频率;N表示文本集合中所有文本的总数;df(wi)表示文本集合中有多少篇文本出现了当前词wi。将文本集合中的每一个词进行上述分析后,得到每一篇文本中每一个词的TF-IDF值,即为该词的特征值。然后将所有词的特征值从高到低排序,选择特征值最高的作为文本的关键词[14]。
2.2.2改进的TF-IDF算法 为了提高Web内容挖掘[15]的准确度,本文考虑了文章结构对抽取关键词的作用,对传统TF-IDF算法进行改进,算法描述如下。
输入:文本集合D={d1,d2, …,dn};输出:文本的关键词。
步骤1 首先从数据库中取出经过分词、去停用词和词性标注等文本预处理过的Web文本内容。
步骤2 经研究发现,文本标题和首段中的词很大程度上可以代表文章的中心主题。因此为了提高挖掘Web文本内容的关键词的精确度,给处于文章标题和首段位置的词配以更高的权重,在提取不同长度文章的关键词时,使用动态权重α来适应长短文本对关键词的影响。通过实验统计权重对关键词提取的影响,得出当标题和首段词系数分别为3和1.5时,对短文本有较好提取效果。进而手动设置300字以下短文本的标题和首段词的基础系数为3和1.5,同时每超出基础文本300字,基础系数分别加1,从而达到动态适应长短文本对算法提取关键词的影响。
对公式(1)中tfj(wi)改进为tf′j(wi),
tf′j(wi)=tfj(wi)+(3+α)·tfjh(wi)+(1.5+α)·tfjf(wi),
(2)
式中:tf′j(wi)表示当前词wi在文本j中配以权重后出现的频率;tfjh(wi)表示当前词在文章标题中出现的频率;tfjf(wi)表示当前词在文章首段出现的频率。
步骤3 由于公式(2)对TF值进行改进,为了减轻算法对词频的过度依赖,加入IDF值的平方来优化算法。使用公式(3)计算Web文本中词的TF-IDF值,并选出其中特征值最高的词,作为当前文章关键词候选项。
TF-IDF′(wi)=tf′j(wi)·log(N/df(wi))·log(N/df(wi))。
(3)
步骤4 重复步骤3对每个URL的Web文本内容进行关键词的提取,存入数据库。
2.2.3文本主题分类 文本分类是让计算机按照一定的分类标准自动对文本集合进行分类的过程。KNN[16]文本分类算法基于向量空间模型,利用文本向量间相似度划分文本类别。该算法的核心思想为在训练集中分别计算待分类文本与设定好的每个标准分类样本的相似度后,找到相似度最高的K个样本。最后,根据待分类文本的相似度权值和相似样本的类别,判定待分类文本的类别。
本文使用KNN文本分类算法对Web网页文本内容进行主题分类。预先设定主题类别为一定程度上可以覆盖网络的20个主题。在训练集中,每个主题设置能突出反映当前主题特征的多篇文本作为标准主题向量集。为了去除数据中的噪声词,对特征空间进行降维并减少运算复杂度,选取特征值前20个特征向量作为当前文本特征向量集,与标准主题向量集进行相似度计算,从而达到对Web网页文本进行分类的目的。算法描述如下。
输入:待分类文本集合K={vi{wi1,wi2, …,win},1≤i≤n},Ds={ds1,ds2, …,ds20};输出:分类的结果。
步骤1 首先,对训练集中代表20个主题的标准主题文本集Ds进行预处理和特征词向量化,抽取每个主题特征向量值最高的20个特征向量{vs{ws1,ws2, …,ws20},作为该主题的标准主题向量集。
步骤2 从数据库中取出经过特征向量化的文本集合K,计算待分类文本v和标准分类vs相似度,计算公式为

步骤4 最后使用分类决策函数来判定类别,计算公式f=arg maxcj(p(v,cj))。
3 用户性格画像模型
3.1 人物性格分类
在心理学领域,大五人格[17]是最为广泛接受的理论框架。此前,有学者[18]证实主题特征与用户人格之间的相关性,但并未给出具体的知识建模,结合本文对用户性格画像的需求,本文选用西方心理学界公认的人格特质模型大五人格[19]作为用户性格分类[20]。
在这五种人格分类中,拥有外倾性、开放性、宜人性和尽责性的人认为是心理健康且对社会有益的人,预测拥有这些性格特征的人很少会有对社会造成危害的行为,并给这些性格良好的人贴上“优良人格”的标签。神经质性格的人拥有充满烦恼和不安全感、焦虑、冲动和脆弱等特征,预测这些充满负面性格特征的人很可能因为冲动等原因会有危害社会的行为,给这些性格上有缺陷的人贴上“危险人格”的标签。
3.2 “性格-主题-关键词”模型
本文通过深入理解分析大五人格的特点,并结合领域知识中对大五类性格特点的描述,为每个人格赋予最能表现性格特点的主题,达到从用户访问的主题深度预测用户性格的目的,生成用户性格标签。通过训练集收集各类主题中高频且具有代表性的特征关键词进行人工筛选,用于对提取到的未知关键词进行规范化处理。构建“性格-主题-关键词”知识库,如表1。

表1 “性格-主题-关键词”知识库Table 1 “Personality-topic-key words” knowledge base
3.3 个人用户画像
通过提取用户访问页面后的关键词,获得网页的内容主题,进而作为用户的兴趣属性标签。并根据“性格-主题-关键词”模型对用户的性格进行深度预测,获得用户性格属性标签。结合用户识别,对用户进行画像。拥有外倾性、开放性、宜人性和尽责性的用户将被贴上“优良人格”的性格属性标签,对拥有神经质和不良关键词的用户将被贴上“危险人格”的性格属性标签。例如:
输入:111.192.165.229—[19/Sep/2013∶06:06:39+0000]“GET/js/google.jsHTTP/1.1“3040” http:∥blog.fens.me/?p=2445&preview=true“”Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/28.0.1500.95 Safari/537.36”。
输出:ID:111.192.165.229;兴趣属性标签:科技;性格属性标签:开放性人格(优良人格)。
3.4 群体画像
为了挖掘群体用户的属性特征,找出拥有相似特征的用户群体,提出一种建立在个人用户画像基础上的群体用户画像的概念。提取所有用户的个人属性特征之后,根据主题及性格标签向量进行用户聚类。用户的特征是用向量的集合表示的,相较于其他聚类算法,虽然K-means方法比较依赖初始聚类中心的选取,但是通过选取用户属性特征明显的中心数据点,可以达到良好的聚类效果。因此,本文采用K-means聚类[21]算法进行用户相似度的计算。群体用户画像流程图如图2所示。

图2 群体画像流程图Figure 2 Flow chart of group profiling
在本文所构建的标签体系中,主要分为5种性格类别。为了用户聚类的过程中发现具有不同属性特征的用户群体,在使用K-means进行用户聚类的过程中,将划分的聚类个数设定为5个。用户聚类完成之后,在数据库中记录每个簇的用户ID及包含的用户数量。通过分析聚类节点中心的属性特征,从而得知在某种特定属性前提下,拥有指定属性的用户群体的特征[22]。
4 系统实验
4.1 数据集的采集和预处理
本文采用的数据集为北京信息科技大学校园网中约10 000个用户的上网日志记录。将数据集分为训练数据集和测试数据集两部分,选取7 000个用户的Web日志作为训练模型的训练集;选取3 000个用户的Web日志作为测试训练结果的测试集。 在对数据进行采集和预处理后,本文将从两个方面对实验内容的性能进行分析:通过Web网页内容挖掘实验测试提取网页主题的准确率;通过大五类性格预测实验测试性格预测的有效性及准确性。
4.2 Web网页内容挖掘实验
本文为了评价Web网页内容挖掘的准确率,设计了挖掘的准确率对挖掘的结果进行衡量,
Maccuracy=Dc/Dt,
(4)
其中:Maccuracy表示模型挖掘的准确率;Dc表示提取文档中关键词正确的次数;Dt表示提取文档的全部数量。根据式(4),本文设计了4个对比试验:① 使用TF-IDF算法提取Web内容的实验;② 基于隐含狄利克雷分布 (latent Dirichlet allocation,LDA)主题模型提取Web内容主题的实验;③ 使用改进后的TF-IDF算法提取Web内容的实验;④ 基于比特主题模型(Biterm topic model,BTM)的主题提取Web内容主题的实验。在LDA模型中,设置其参数α=50/T(T为主题数),β为0.01,设置T值为15、20、25。实验结果如表2所示。
由表2可以看出,当T=20时,Web内容挖掘的挖掘效果最好,准确率最高。其原因为在T=20时,即主题数为20的时候,知识库的建立对Web内容挖掘起到辅助作用。随着T值的增加,挖掘的效果先升高后降低,因为只有最接近用户主题分类需求的T值,才能更好地提高挖掘的准确性,数据的稀疏性影响了挖掘的准确率。
选择挖掘效果最好的T=20时进行对比实验,根据公式(4)计算准确率,实验结果如图3所示。

表2 T值对准确率的影响Table 2 The effect of T value on accuracy

图3 Web内容挖掘准确率Figure 3 Web content mining accuracy
由图3对Web内容挖掘的准确率可知,使用传统TF-IDF算法对Web内容挖掘的准确率为71%,基于LDA主题模型的Web内容挖掘准确率在62%左右,基于BTM主题模型的Web内容挖掘准确率在70%左右,本文使用的配以权重的TF-IDF算法在准确率上要优于上述3种算法,准确率为74%。原因为LDA主题模型提取的主题主要依靠“主题-文档”和“词-主题”的概率相乘,所以数据集在一般情况下提取主题过于稀疏;BTM模型针对长文本的网页文本适应能力不强;传统的TF-IDF又过于依赖词频,没有考虑文章的结构;改进后的TF-IDF一定程度上弥补了上述几种算法的缺点。
4.3 大五类性格预测实验
为了验证用户性格画像系统的准确率,通过训练数据得到的决策树模型,分别对100~600条日志数据预测的准确率(Precision)、召回率(Recall)和F1值进行计算,
实验结果如图4所示。由图4可知,随着实验测试数据集的增加,用户画像系统对用户性格预测的准确率逐渐收敛,最终收敛在72%附近。这说明该系统可以稳定有效地对用户性格进行预测,但是召回率随着准确率的增加而降低。其原因可能是随着数据集的增多,噪声数据及错误访问网页的用户逐步增加,对所有用户进行精确画像的难度上升,因此F1值呈现出先上升后下降的趋势。
在测量用户画像系统对用户拥有的大五类性格属性的准确率后,通过线性回归模型测量每种性格占用户总数的百分比。通过预测误差的绝对值的平均值来衡量预测的准确度,预测误差是指计算值与实际值间的误差,平均误差是指在0~99之间随机给定一个值,这个值和正确值之间的误差的期望值。由于每种性格所占百分比变量均是在0至99之间均匀分布的,因此预测平均误差为37.5。实验结果如图5所示。
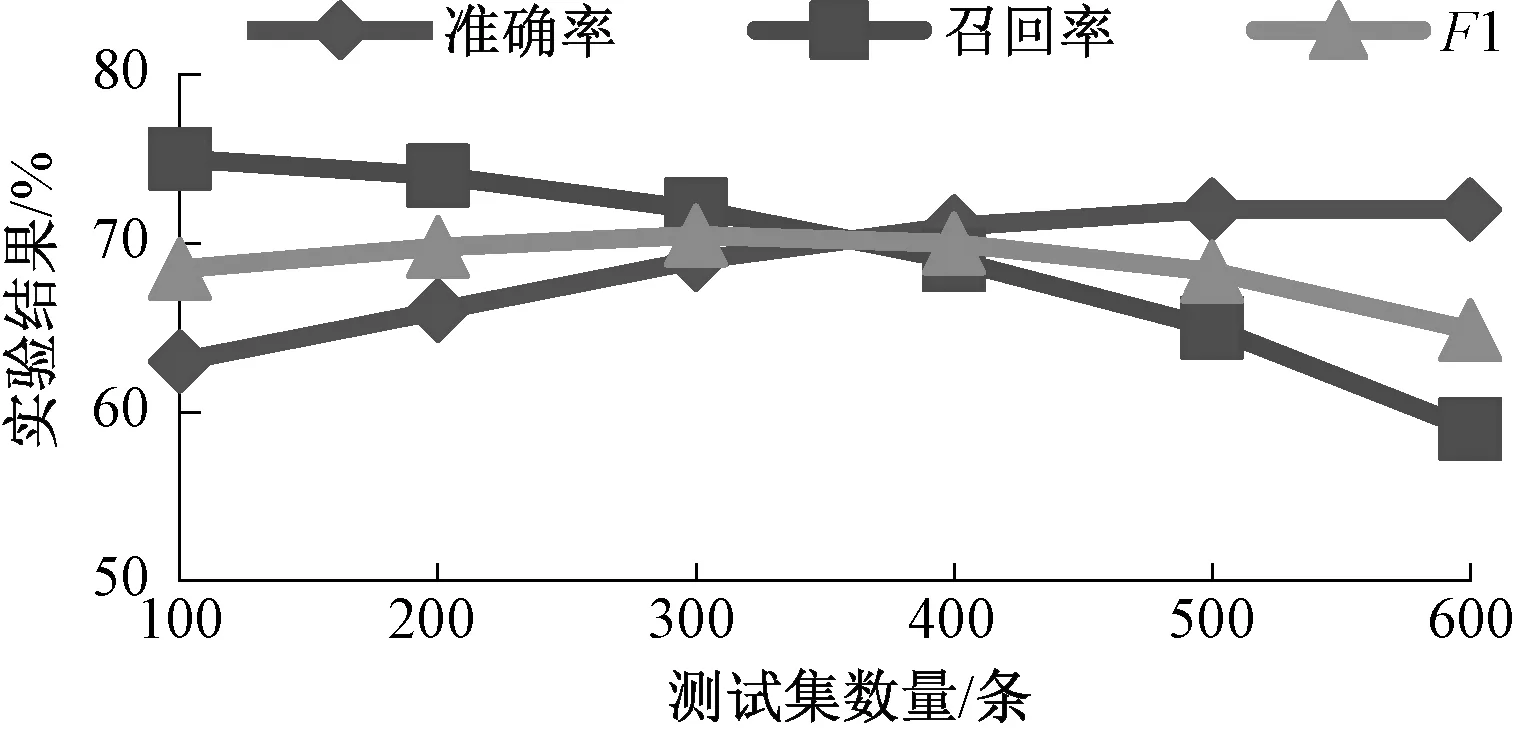
图4 性格预测准确率、召回率和F1值Figure 4 Personality prediction of precision, recall and F1

图5 群体性格预测Figure 5 Group personality prediction
从图5中可以看到,用户大五类性格占有比例的预测误差均小于平均误差。说明用户画像系统能有效挖掘出用户在访问网络时的性格属性特征。其中外倾性人格画像最为精确,原因可能为测试集中用户上网购物或搜索娱乐资源的数量较多。对神经质人格的画像相对较差,原因可能为测试集中用户访问网络推送的广告或不良资源造成的。
5 结束语
本文针对传统的日志挖掘没有直观体现用户的兴趣度,对用户性格等属性没有进行深度挖掘等问题,设计了用户行为预测与性格画像方法。该方法通过标签形式,更加直观准确地反映了用户的特有属性,通过对性格刻画主动对网络用户进行行为预测[23]和安全预警[24]。今后的研究方向为结合多种用户数据的融合画像,对群体用户的多维属性特征挖掘等方面进行进一步研究。
猜你喜欢
小哥白尼(神奇星球)(2022年3期)2022-06-06
华人时刊(2021年13期)2021-11-27
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
新世纪智能(高一语文)(2020年9期)2021-01-04
健康体检与管理(2021年10期)2021-01-03
非公有制企业党建(2020年10期)2020-10-27
心声歌刊(2020年4期)2020-09-07
思维与智慧·上半月(2018年10期)2018-11-30
