
机器学习算法用于乳腺癌检测的性能研究①
2020-02-28 05:08
佳木斯大学学报(自然科学版) 2020年1期
(安徽国防科技职业学院,安徽 六安 237011)
0 引 言
据国家癌症中心和卫生部疾病预防控制局调查表明,乳腺癌排在女性恶性肿瘤的首位。因为乳腺癌在早期没有典型的症状,不容易引起注意。因此定期体检排查,在早期发现是治疗的关键[1]。通过读取乳房X光造影的测量指标,用机器学习算法来检测乳腺癌,是目前人工智能和医学领域交叉的研究热点[2-3]。主要是将几种重要的机器学习算法用于乳腺癌检测的测试,从而分析它们用于此领域的性能,为今后的研究提供指导。
1 数据集和预处理
所使用的数据集来源于对女性乳房造影图片的特征提取,如图1所示。此数据集一共有569个样本,其中阳性样本357个,阴性样本212个,每个样本使用10个关键特征:肿块半径、周长、面积、纹理、平滑度、密实度、凹度、凹点、对称性和分型维度。在用机器学习算法训练数据集之前,将样本分成了训练数据集和测试数据集。主要使用了三种机器学习算法:K-近邻、逻辑回归和支持向量机来对数据集进行训练,在训练中绘制学习曲线,通过学习曲线来评价训练算法的好坏。
2 机器学习算法原理和训练效果
2.1 K-近邻(KNN)算法的原理和训练效果
KNN算法最基本的思想是对未知样本的分类,是由其距离最近的K个近邻数据来投票决定。其算法步骤为:

图1 疑似病变的乳房肿块
(1)求测试数据与训练数据之间的距离;
(2)按照距离的大小进行排序;
(3)选取距离最近的K个点;
(4)返回前K个点中出现的最多类别作为预测的类别。
现有两种类别的样本分别用正方形和三角形表示,那么未知的圆形样本到底属于哪一类,是由K的值决定的。当K=3时,圆形样本跟三角形同类别;当K=5时,圆形样本类别跟正方形一致。为了避免K的随意选取对结果造成的重大影响,一般采用交叉验证来选取最优的K值,如图2所示。
使用KNN算法对乳腺癌数据集进行了训练,并绘制了学习曲线如图3所示:

图2 K值的选取对类别的影响示意图

图3 KNN算法训练乳腺癌数据集的学习曲线
2.2 逻辑回归算法的原理和训练效果
逻辑回归算法输出的是离散值,它是一种分类算法,使用的预测函数是Sigmoid函数,公式如下:
(1)
结合线性回归的预测函数:
hθ(x)=g(θTx)
(2)
可以得到逻辑回归的预测函数如下:
(3)
逻辑回归的成本函数要选择自然对数函数,因为Sigmoid函数有e的n次方运算,自然对数正好是其逆运算。逻辑回归的成本函数公式为:
(1-y(i)log(1-hθ(x(i)))]
(4)
使用梯度下降法来求解模型的参数,最终可以得到梯度下降的算法公式为:
(5)
对于较为复杂的模型来说,训练过程容易出现过拟合现象,为了解决过拟合问题,需要在模型中引入正则化,也就是在逻辑回归的成本函数上加上正则项,得到:
(6)
最常用的正则项有L1范数和L2范数。L1作正则项时,可以使得模型参数θ稀疏化;L2作正则项时,可以使得模型参数尽可能的小,每个特征都会对预测有贡献。
使用逻辑回归对乳腺癌数据进行训练时,绘制了使用L1范数在一阶和二阶多项式下的学习曲线(图4)和使用L2范数在一阶和二阶多项式下的学习曲线(图5)。
2.3 支持向量机的原理和训练效果
支持向量机(SVM)是一种机器学习的分类算法[4]。假如我们要对两类样本数据进行分类,SVM的原理就是要找到一个最合适的分割超平面,它能正确分类数据集,并且间距最大。在高维空间里,可以使用公式wTx+b=0来表示,画出与超平面平行的另外两个超平面wTx+b=1和wTx+b=-1,如图6所示。
图6中红色的圆点S到分割超平面的距离为:
(7)

(8)
假如有样本x(i)和类别标签y(i),只需在满足约束条件:
y(i)(wTx(i)+b)≥1
(9)
的情况下,使得‖w‖2最小。对于线性不可分的数据集,需要引入松弛系数ε,求解
(10)
引入非负系数α作为约束条件的权重,使用拉格朗日乘子法来求函数极值,公式如下:
(11)
此公式中的x(i)Tx(j)被称为核函数。
使用了三种核函数对数据集进行了训练,这三种核函数分别是高斯核函数、多项式核函数和线性和函数。
线性核函数的公式为:
K(x(i),x(j))=x(i)Tx(j)
(12)
线性核函数直接计算两个特征向量的內积,运算效率高,但是对线性不可分的数据集效果很差。
多项式核函数公式为:
K(x(i),x(j))=(γx(i)Tx(j)+c)n
(13)
它的优点是可以拟合出复杂的超平面,缺点是参数太多。
高斯核函数公式为:
(14)
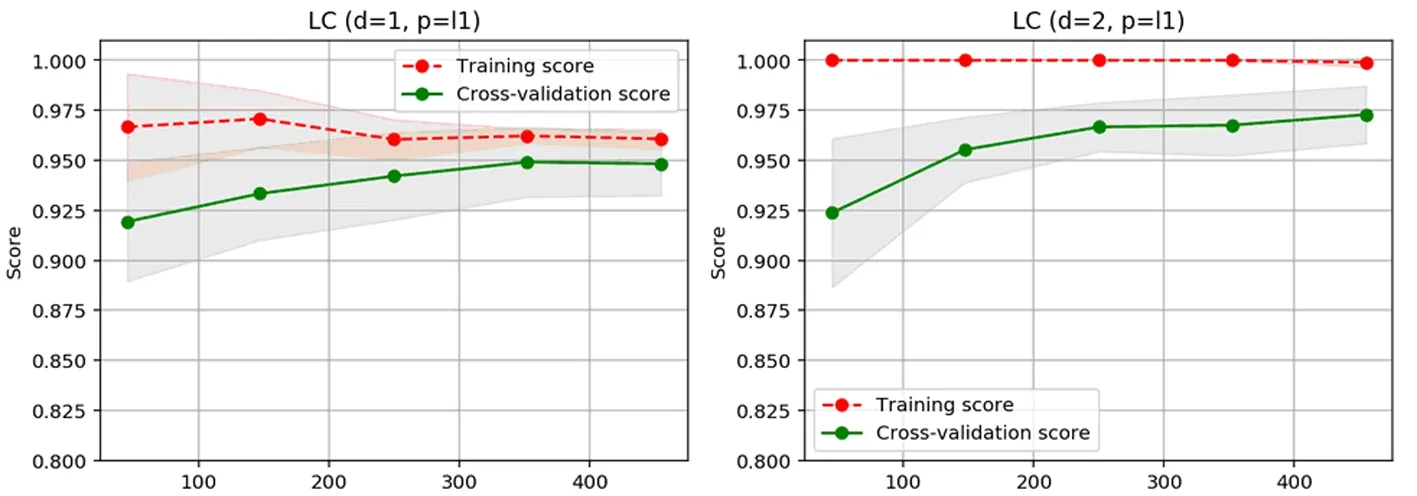
图4 逻辑回归(1阶和2阶,L1正则化)训练乳腺癌数据集的学习曲线

图5 逻辑回归(1阶和2阶,L2正则化)训练乳腺癌数据集的学习曲线

图6 支持向量机原理
它可以将输入特征映射到无限维,但由于模型太复杂,容易引起过拟合。
用这三种类型的核函数的SVM去训练数据集,并绘制了它们训练过程中的学习曲线如图7所示,可以看出用高斯核函数的SVM效果非常差,明显是过拟合了。
3 数据分析与性能比较
通过分析学习曲线,可以看到二阶多项式逻辑回归在使用L1正则化的情况下识别率最高[5],效果也最好。三种机器学习算法的训练和测试分数如表1所示:

表1 机器学习算法的训练分数和测试分数对比
4 结 语
通过使用几种传统的主流机器学习算法对从乳房X光片测量的数据集进行训练和测试,并对测试数据的分析和比较,可以看到逻辑回归算法比较适用于此任务的检测。从测试结果来看,成绩也相当不错。但是这些数据是由手工从X光片测量得到的,传统机器学习有赖于人为的特征提取,分类性能也受限于人为选取特征的表征能力,因此还达不到自动化诊断的程度。



图7 三种类型核函数SVM训练乳腺癌数据集的学习曲线
目前,国内外已有研究机构和世界顶尖的医院合作,采用深度学习技术对乳房造影图像进行自动化的标注[6],对乳腺癌发展风险的评估,以及乳腺癌诊断,诊断的准确率已达到一流医生的水准。人工智能技术在未来,一定可以在医学诊断上越来越智能化和高效化。
猜你喜欢
中华骨与关节外科杂志(2022年1期)2022-08-31
环球时报(2022-07-13)2022-07-13
环球时报(2022-03-14)2022-03-14
怀化学院学报(2021年5期)2021-12-01
兰州理工大学学报(2021年3期)2021-07-05
兰州理工大学学报(2021年3期)2021-07-05
文苑·感悟(2019年12期)2019-12-23
文苑(2019年23期)2019-12-05
读者·校园版(2019年17期)2019-08-13
电影(2018年8期)2018-09-21
