
生成式对抗网络的图像超分辨率重建*
2020-03-07 03:52王志强
西安工业大学学报 2020年1期
王志强,赵 莉,肖 锋
(西安工业大学 计算机科学与工程学院,西安710021)
图像超分辨率技术是计算机视觉领域中的一项重要的研究课题,具有较大的研究价值和意义。图像超分辨率主要通过低分辨率(Low Resolution,LR)图像实现高分辨率(High Resolution,HR)图像的转化,它应用于广泛的领域,如医疗、卫星遥感和公共安防等领域。早期的超分辨率图像处理方法是基于单帧图像的Harris-Goodman频谱外推法[1],该方法使用单幅图像实现超分辨率任务,由于单幅图像超分辨率引入先验知识的不足,生成图像的效果难以提升,使得单幅图像超分辨率技术的发展受到限制。此后提出了基于序列或多帧图像[2]的超分辨率重建问题,并给出了基于频域逼近的重建图像方法,这些图像复原技术通过改变截止频率提高图像质量,缺点是截止频率以外的信息未得到较好地恢复。随后学者提出采用信号处理的方法恢复成像过程中丢失的高频信息,从而获取更好的分辨率图像,促进超分辨率恢复技术在图像处理领域的不断发展。
目前超分辨率技术主要有3大类:基于插值的方法、基于重建的方法和基于学习的方法。其中基于插值的方法中典型的方法有:最近邻插值、双线性插值和双线性插值,这类方法的优点是快速易行和运行复杂度低,但由于不能引入额外有用的高频信息,低分辨率图像的采样值并不是理想值,使得形成的图片模糊、质量不高。基于重建的方法[3]是利用多幅低分辨率图像的互补信息重构一副高分辨率图像,该类方法主要是构建高分辨图像与低分辨率图像关系的观察模型,根据观察模型,利用多幅低分辨率图像获得高分辨率的图像,生成的图像质量最后主要取决于配准效果、模糊参数的估计和先验知识的定义,该类方法的缺陷是由于人为定义的先验知识和观测模型所提供的高分辨率的信息越来越少,使得信息大部分丢失,影响了生成的高分辨率图像的效果。针对这一不足,文献[4-5]提出基于学习的超分辨率复原方法,通过学习得到高分辨率图像和低分辨率图像之间的映射关系,对特征进行提取并建立学习模型,通过低分辨率块建立最匹配的高分辨率块,实现了低分辨率到高分辨率的转化,其中的先验知识不再人为设定。基于学习的方法较多,例如:基于示例的方法[6]和基于稀疏字典的图像超分辨率复原方法[7],其主要是进行特征提取、模型学习和重建的过程,但它们与基于重建的方法一样有着各自的不足,如基于示例的学习,由于需要对重复区域的高频信息求均值,使得图像边缘过于平滑;基于稀疏字典的图像超分辨率方法在稀疏编码和重建过程运算量大、迭代次数多和计算效率低。近年来,随着科技发展,获取大量数据变得相对容易,促进了深度学习的不断发展,其在特征提取上相较浅层学习能获得更多的信息,用深度学习生成的模型效果总体来说优于浅层学习。很多学者通过借鉴深度学习在图像目标检测、图像分类和图像分割的经验,提取精细的图像特征和建立更好的学习模型来实现图片从低分变率到高分辨率的更好的纹理转化,主要方法有基于卷积神经网络的方法[8-9]、基于递归卷积网络的方法[10]和基于生成式对抗网络[11]等。
文中基于生成式对抗网络实现低分辨率到高分辨率图像的转化,在文献[12]基础上,对生成式对抗网络模型结构进行改进,加深网络层次、修改残差网络结构和网络参数。
1 生成式对抗网络结构
本文利用深度学习的生成式对抗方法来实现图像的高分辨率转化,通过创建一个鉴别网络和一个生成网络,利用对抗竞争性思想进行网络结构的训练,其网络结构如图1所示。
图1中,生成器网络通过输入低分辨率图像生成高分辨率图像,鉴别器网络用来鉴别图片是真实的图片还是生成器生成的图片,若判断是假则返回零。根据损失情况和优化算法对生成网络中的权重和偏移量进行调整,实现在下一次训练中生成更加接近真实图片的高分辨率图像,训练鉴别器网络,通过输入高分辨率图像不断提高鉴别网络的鉴别能力,用来鉴别出更加真实的生成图片。基于对抗式学习思想,使用大量的实验数据图像不断更新网络中的细节参数,生成更好的学习模型,利用训练好的学习模型对要处理的低分辨率图像进行卷积生成高分辨率图像,通过主观方法和客观方法进行对比,确定优点和不足,进一步修改,最终形成整体的网络模型结构。
1.1 生成网络式结构
生成式对抗网络实现输入低分辨率图像生成高分辨率的图像。文献[13]的方法表明网络层次越深卷积核越多能获取到更多的细节信息,所以为了减少细节损失,本方法在生成网络结构上加深了网络结构,设置24个结构相同的残差块。借鉴EDSR[14]方法网络结构上去掉批量归一化层(BN层),图像超分辨率要求输出的图像在色彩、对比度、亮度上和输入一致,但通过BN层的处理会破坏原有的对比度,而且BN层会和卷积层一样占用内存,去掉可节省内存的消耗,为了节省内存、提高性能和获得更好的效果,本文在整体的生成网络中去掉原先卷积模块和残差模块里的批量归一化层。生成网络结构如图2所示。
图2中,生成网络训练通过输入低分辨率图片经过第一层卷积网络进行特征提取,卷积层参数为64个3×3的卷积核,步长为1,利用激活函数Relu进行非线性映射提升性能,随后经过24个残差块,每个残差块的工作包括用64个3×3的卷积核以步长1进行卷积和Relu操作,相较原先的残差结构,文中去除了批量归一化层,残差网络后接一层卷积层其中包含64个3×3的卷积核,通过跳跃连接进行卷积求均值求和,2个相同的以卷积层、上采样层和Relu层组成的卷积模块对结果进行放大处理,其中卷积层由256个3×3卷积核组成,上采样层利用Pixel Shuffle[15]算法来扩大图像,最终经过3个1×1的卷积核进行步长为1的卷积层和tanh激活层,生成高分辨率图像。
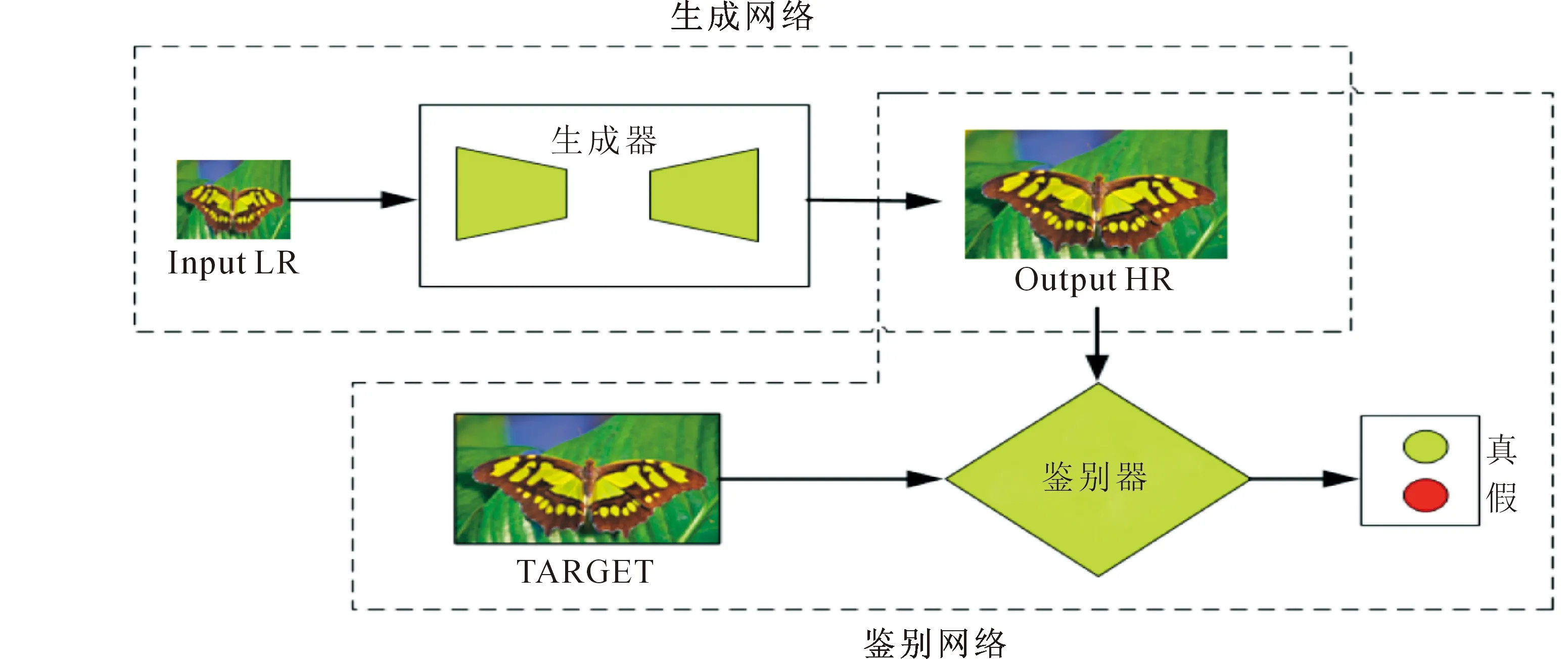
图1 网络结构图Fig.1 Neural network structure
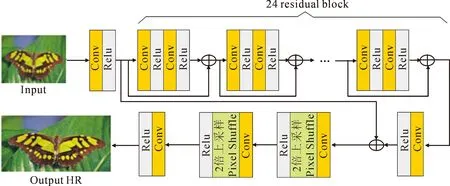
图2 生成网络结构图Fig.2 Generative network structure
1.2 鉴别网络结构
鉴别网络判断输入的图片是生成网络生成的图片还是真实的图片,通过对鉴别网络进行训练,不断提高鉴别网络的判别能力。利用优化算法Adam和根据损失函数判断损失,反向修改生成网络和鉴别网络的权重等各项参数,减小生成图像与真实图像的差距,提高生成网络的生成能力,提高图片的清晰度和细节纹理,实现更高质量的图像的生成。在鉴别网络中,各项参数如卷积核的大小、Feature Map的个数和Stride的大小对于网络的判别能力和实验效果都有很大影响,为提高感知野获取更多的信息文中用4×4的卷积核进行卷积操作,通过多层的卷积、LRelu、全连接层和Sigmoid的操作输出判别结果。鉴别网络的参数见表1。
鉴别网络结构中前6层使用4×4的卷积核进行特征提取,通过增加特征图个数来增加提取的特征信息, 7~9层利用1×1的卷积层降低输入通道数和卷积核参数来减少运算复杂度和实现降维,进行3×3的卷积和跳跃连接对不同阶段的特征信息处理以获取更多有用的特征信息,经过FlattenLayer进行数据一维化、全连接和Sigmoid层输出判断结果,根据判别结果分析真实数据与实验数据差距,通过反向传播算法修改内部网络参数值,增强模型的预测能力,减小实验结果差距,提高网络鉴别能力,进而提高网络的生成能力。鉴别网络模型结构如图3所示。
1.3 代价函数
损失函数通过衡量预测值和真实值的差距判断网络的性能,而且在反向传播中损失函数有助于修改参数来实现网络的优化。
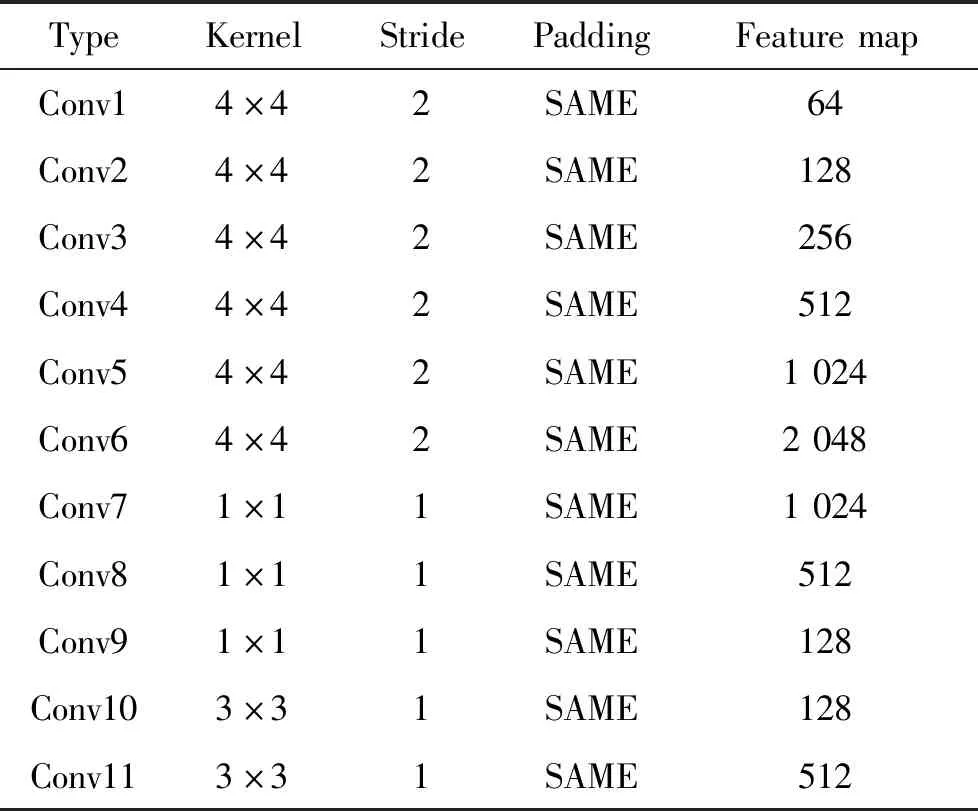
表1 卷积参数表Tab.1 Convolution parameter table

图3 鉴别网络结构图Fig.3 Distinguishing network structure
由于整体网络结构采用生成式对抗思想,鉴别模型的目标是实现判别准确率最大化,生成模型的目的是使鉴别模型的准确率最小化,即鉴别网络希望最大化判断出图片真实性,生成网络则希望鉴别网络辨别不出图像真伪。所以为了优化网络,解决对抗性最大-最小问题,最小化生成网络G和最大化鉴别网络D,定义目标函数为
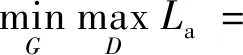
ETLR~PG(TLR)[log (1-D(G(TLR)))]。
(1)
式中:E为真实数据THR和TLR的数学期望;THR为高分辨率图像;TLR为低分辨率图像;D(THR)为鉴别网络判断真实高分辨率图片是否真实的概率;G(TLR)为低分辨率通过生成网络生成的高分辨率图像;D(G(TLR))为鉴别网络判断生成网络生成的图片的是否真实的概率。
为了减少图像在卷积过程中的像素损失,定义了生成网络的损失函数LG,通过判断生成的高分辨率图片的特征表示和真实图片的特征之间的差距,通过优化权重和偏移量尽可能地减少高频细节损失,生成在视觉上和高频细节更好的高分辨率图像。LG损失函数为
LG=Lg+Lvgg+Lmse。
(2)
式中:Lg为生成的图片通过鉴别网络的判别结果与真实值的交叉熵;Lvgg为生成图片经过vgg19网络与真实图片经过vgg19网络的像素之间的损失;Lmse为真实高分辨图像与生成的高分辨率图片像素之间的损失。
在鉴别网路中鉴别器判别出是真实图片还是生成器生成的高分辨率图片,为了提高鉴别能力,分析鉴别损失情况,定义鉴别损失函数为
LD=Ldr+Ldh。
(3)
式中:Ldr为生成网络生成的高分辨率图像在判别网络判别结果与真实值0的交叉熵;Ldh为真实高分辨率图像在判别网络判别结果与真实值1的交叉熵。
在整个实现过程中,由于图片进行卷积特征提取和采样的过程中难免造成图像信息的丢失,如图像的一些纹理特征、高频细节和颜色等。为尽可能减少这些损失,定义的损失函数在进行优化过程中起到重要作用。通过损失函数得到网络的损失情况,判断网络的性能,然后通过修改各层参数优化生成网络和鉴别网络,提高生成网络的生成能力和鉴别网络的鉴别能力,进而提高图像的生成质量。
2 实验与分析
通过网络的交替式训练,实现图像从低分辨率到高分辨率的转化,本文采用Tensorflow深度学习框架,数据集来源于DIV2K上的双三次降采样×4的高分辨率图片和低分辨率图片。DIV2K提供1 000张高清图(2 K分辨率)和对应的下采样的低分辨率图像,其中800张高清图和对应的低分辨率图作为训练,100张高清图和对应的低分辨图用于验证,剩余的图用于测试。实验结果主要通过主观评价和客观评价2种方式验证,其中主观评价通过多种方法实验结果观察对比,主要是根据图像的清晰度、纹理细节和直观感受判断方法的优劣;客观评价通过使用峰值信噪比和结构相识性2种算法,运算原始高分辨率图像和生成的图像的比较值客观评价方法的优劣。图4为生成的对应高分辨率图的比较结果,通过图4观察到,文中方法得到的高分辨率图相较Bicubic方法更加清晰,相较于SRGAN图像颜色更加接近真实高分辨率图像,虽然相较于HR高分辨率图像还有一些差距,但在一些纹理特征、高频细节和颜色上均有较好的转化表现。

图4 实验对比结果Fig.4 Comparison of experimental results
主观评价方法可直观地发现实验结果的优缺点,但个人的视觉感受存在差异,为了更好地评价实验结果,文中利用客观评价标准峰值信噪比(PSRN)和结构相似性(SSIM)对部分实验结果进行评价。PSRN越高,说明图片转化过程失真越小,图片生成的越好,SSIM用来衡量2幅图像的相似程度,数值越高表示2幅图像越相似,最大为1。图4实验结果客观评价值见表2,Set14数据结果的客观评价值见表3。
表2为文中给出实验结果图4的2种客观评价值,数据说明文中方法得到图1和图3的PSRN和SSIM值相比于Bicubic的方法有所提高,图2的两种客观评价值略低于Bicubic,但从主观观察中本文方法的得到的结果更加清晰。表3为用Set14数据集的测试结果比,从表3可以看出,本文方法的大部分测试结果值相对另外2种方法有一定的提高。总体而言该方法相对另外2种方法在客观评价值上有更好的实验结果。
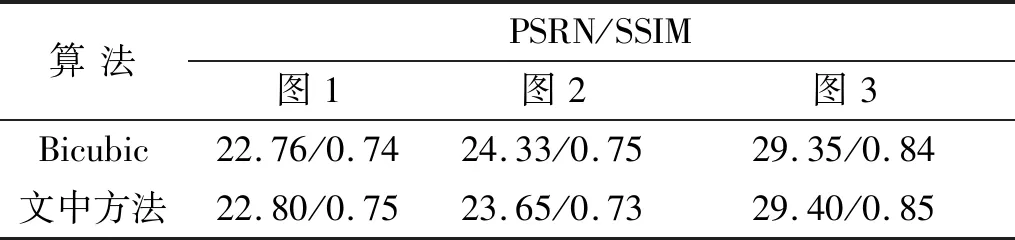
表2 客观评价值Tab.2 Objective evaluation values

表3 Set14客观评价值Tab.3 Set14 objective evaluation values
3 结 论
本文利用深度学习的生成式对抗网络的学习方法,创建生成式对抗网络模型,建立生成网络和鉴别网络,其中生成网络在SRGAN网络的基础上修改了网络层次,更改了残差结构和网络参数,鉴别网络由多层卷积、全连接层和Sigmoid层组成。低分辨率图片通过生成模型生成高分辨率图片,鉴别模型用来鉴别生成图片是原始自然图片还是生成的图片,通过生成网络和鉴别网络的交替式训练学习,优化生成模型和鉴别模型。实验结果从主观方面可看出,文中方法生成的图像较清晰,在纹理色彩方面更接近于高分辨率图像,从客观评价上峰值信噪比和结构相似性的值相较圴有一定的提高。但同时也存在不足之处,如在转化过程中对于色彩纹理复杂的图片转化的效果不佳,与真实的高分辨率图片相较还有差距,在以后的工作中将进一步优化网络结构,减少细节损失,实现更好的生成能力,提高生成图片与原图的结构相似性。
猜你喜欢
健康体检与管理(2021年10期)2021-01-03
计算机应用(2020年7期)2020-08-06
雷达学报(2020年3期)2020-07-13
计算机系统应用(2019年9期)2019-09-24
艺术科技(2018年2期)2018-07-23
北京航空航天大学学报(2018年1期)2018-04-20
发明与创新·中学生(2017年1期)2017-01-20
科技视界(2016年18期)2016-11-03
太空探索(2016年3期)2016-07-12
软科学(2014年8期)2015-01-20
