
基于改进粒子群算法的测试用例优先排序
2020-03-16 10:50袁光辉
陕西理工大学学报(自然科学版) 2020年1期
袁光辉
(安徽大学 江淮学院 理工部, 安徽 合肥 230031)
在大规模软件演化进程中,频繁使用回归测试可保证软件质量,但测试开销巨大[1]。测试用例优化技术可有效降低回归测试成本,提高测试用例使用效率。测试用例优先排序(Test Case Prioritization,TCP)作为一种高效实用的回归测试优化技术,受到广泛关注。李征等[2]证实TCP问题是一个NP完全问题,并验证了遗传算法和额外贪婪算法求解TCP问题的有效性。Walcott等[3]采用遗传算法求解资源约束下复用测试用例子集,通过对该子集按平均代码覆盖率排序,有效提高了时间限制下的测试用例缺陷检测率。李龙澍等[4]提出采用3个不同进化规律的多种群遗传算法处理测试用例排序问题,实验结果较标准遗传算法具有更强的性能和更好的效率。陈云飞等[5]提出了基于粒子群优化多目标问题方法,采用遗传算法中的交叉操作,设计了粒子的表示和状态更新方式,选取多个优化目标,提高软件测试效率。张卫祥等[6]提出基于离散粒子群算法的TCP,重新定义粒子速度和位置,引入变异算子,动态调整粒子惯性权重,提高算法性能。张娜等[7]提出基于Tent混沌的TCP,采用惯性权重改进学习因子,通过混沌搜索跳出局部最优,从而得到最优解。将智能优化算法应用于测试用例优先排序已被众多学者证明是一种有效的方法,可大幅提高排序搜索的速度和效果。其中粒子群算法因收敛速度快、参数少、易于实现等特点在求解TCP问题时表现出较好的效果。但标准粒子群算法在求解TCP问题时,求解过程存在易早熟收敛、寻优精度低、算法稳定性不强等问题。
针对上述问题,本文以标准粒子群优化算法(Standard Particle Swarm Optimization,SPSO)为基础,结合混沌思想,通过对惯性权重、学习因子等参数调整,提出了改进的粒子群优化算法(Improved Particle Swarm Optimization,IPSO),将该算法应用于测试用例优先排序。通过实验对比分析,验证本文所提测试用例优先排序方法的可行性和有效性。
1 测试用例优先排序建模
1.1 问题描述
TCP是指对测试用例集按照某种特定顺序进行排序,进而找到一个最优的排列,使其能在更短的时间发现更多的软件缺陷,并以此来降低测试成本。Rothermel等[8]对TCP问题给出了具体定义,其形式为:令T为测试用例集,PT为T的全排列集,即T中所有可能的测试用例执行次序集合,f为优先排序目标函数(其中定义域为PT,值域为实数)。测试用例优先排序就是寻找一个T′∈PT,使得对于任意T″(T″∈PT且T″≠T′),均满足f(T′)≥f(T″)。
由上述定义知,目标函数f输入某个测试用例特定执行次序,输出与排序目标相关的判定值,其值越大说明该次序的排序效果越好,检测软件缺陷的能力越强。
1.2 度量准则
软件测试目的是通过设计、使用测试用例来尽可能多地发现被测软件的缺陷。为了评估软件测试的完整性和有效性,需要某些指标来度量给定测试用例集系统测试的满足程度,在设计TCP技术评测指标时,通常使用测试用例序列尽早发现软件内部存在的缺陷,以此作为测试用例优先排序的目标。目前,研究人员采用最广泛的评价指标是由Rothermel等率先提出的APFD,即缺陷检测平均百分比(Average Percentage of Fault Detection,APFD),能有效评估TCP的平均缺陷检测效率。Elbaum等[9]给出其计算公式为
(1)
其中n表示测试用例集T中参与评估测试的有效测试用例个数,m表示已检测出的缺陷个数,TFi(1≤i≤m)表示首个检测到缺陷i的测试用例在本次执行序列中的位置编号。APFD评价指标的取值范围均是0~100%,其值越高表示对应测试用例集检测缺陷的速度越快,排序效率相对越好。
在测试用例执行前,测试者无法事前预知测试用例执行中将发现的待测程序缺陷个数。测试覆盖率可在测试用例执行前通过覆盖率分析工具得出,因此,可使用覆盖率信息指导测试用例的优先排序。测试用例序列通常通过块覆盖率(APBC)、分支覆盖率(APDC)和语句覆盖率(APSC)等评价指标来量化待测程序实体的覆盖率,其评价指标的计算公式与APFD类似。以APSC为例,计算公式为
(2)
其中TSi表示首个检测到语句i的测试用例在本次执行序列中的位置编号。
有效执行时间(Effective Execution Time,EET)用于计算首次达到最大语句覆盖率时执行测试用例所需的总时间,其计算公式为
(3)
其中ETi表示执行第i个测试用例时所需时间。
2 基于改进粒子群算法的测试用例优先排序设计
2.1 标准粒子群优化算法(SPSO)
粒子群优化算法是一种生物启发式的群体智能优化算法,最早由Kennedy和Eberhart提出[10],模拟了自然界中鸟群飞行及觅食的个体行为与群体行为。
SPSO基本思想为:算法将每只鸟看作一个粒子,把优化问题在搜索空间中的潜在解表示为粒子在D维空间中的位置,各粒子根据个体最优解和群体最优解的大小,通过速度来调整其飞行方向和位置,以此寻找问题的最优解。
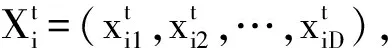
(4)
(5)
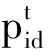
从公式(4)中可知,粒子的更新速度由3项组成:第一项是粒子自身的速度,是维持粒子运动的基本;第二项是粒子的认知分量,即在搜索过程中积累的自身经验;第三项是粒子的社会分量,即粒子在搜索过程中种群的全体经验。通过3项的有机拟合,粒子可以在本身运动的基础上,通过学习自身经验与群体经验来调整运动状态,以进行全局最优的搜索。
SPSO结构简单、参数少、交互机制容易、全局搜索能力强等特点,相较于其他群体智能算法而言,其在解决连续或离散多目标优化问题上都有很大优势。但随着算法的不断迭代,粒子种群的多样性也会在进化中随之降低,容易出现早熟收敛现象,进而导致算法陷入局部最优。
2.2 改进的粒子群优化算法(IPSO)
2.2.1 粒子编码及种群初始化
测试用例优先排序输入为若干测试用例组成的测试用例集,输出结果为测试用例执行序列,其排序过程只是交换测试用例的排列位置,因此,本文采用实数编码方式表示测试用例集中每个测试用例的序号,而每个粒子则表示一种测试用例排列方案。
为提高粒子群算法初始解的质量,使粒子最大程度地对搜索空间的每个方位进行遍历,本文算法使用混沌优化思想初始化粒子群。经混沌化的粒子序列能均匀地分布在搜索空间,提高粒子群的多样性,便于算法求解。研究表明,Tent映射比Logistic映射产生的混沌序列更具有全局遍历性、分布较均匀等特点,所以本文在初始化粒子种群时引入Tent映射,其公式定义为
(6)
2.2.2 适应度函数设计
适应度函数用来指导算法寻优方向,可依据适应度值的大小来淘汰种群中的劣质解,以便算法快速收敛、精确寻找最优解。在对测试用例排序时,对于较早达到较高代码覆盖率的测试用例序列而言,其发现错误的能力较强,即在尽短时间内发现更多缺陷。因此,可用程序实体覆盖率来构造IPSO的适应度函数。本文选取公式(2)定义的平均代码覆盖率(APSC)和公式(3)定义的有效执行时间(EET)作为优化目标,选取公式(1)定义的缺陷检测率(APFD)作为测试用例排序的评测指标。
2.2.3 自适应调整惯性权重及学习因子
公式(4)中ω为惯性权重,表示粒子在问题空间中的历史搜索速度对当前速度的影响,在SPSO算法中,惯性权重一般设为固定值。如权重设置过大,有利于算法的全局搜索,易陷入局部最优,不易得到精确解;如其设置过小,虽有利于局部搜索,但会导致种群收敛速度变慢。
随着算法迭代次数的不断增加,粒子是否需要调整搜索范围应与粒子自身的适应度值紧密相关,因此,适应度值不同粒子的惯性权重也应有所不同。根据分析惯性权重与适应度之间的关系,本文提出自适应调节的惯性权值策略,惯性权重公式如下:
(7)
其中fiti表示适应度函数值,gBest表示全局极值。由公式(7)可知,当粒子的适应度值较小时,对应的ω越大,粒子需要以较快的速度进行全局搜索,提高算法收敛效率;反之,当粒子的适应度值较大时,越接近最优解,对应的ω越小,粒子应降低搜索速度,并在局部区域精细探索,进而寻找最优解。自适应惯性权重可保证粒子群在算法初期具有较好的探索能力,而在晚期具有较好的开发能力。
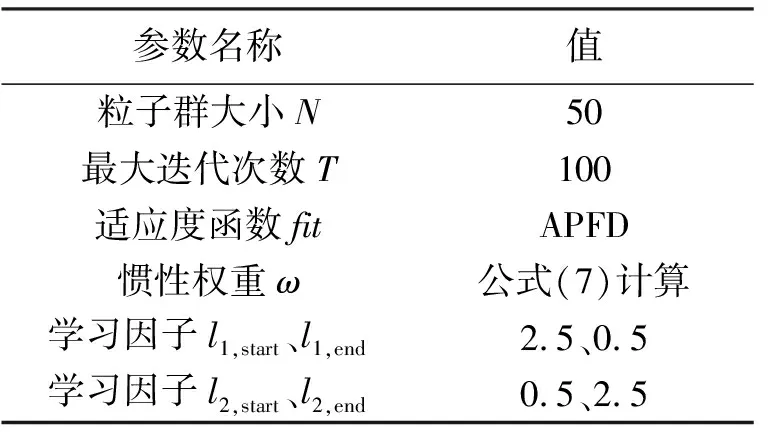
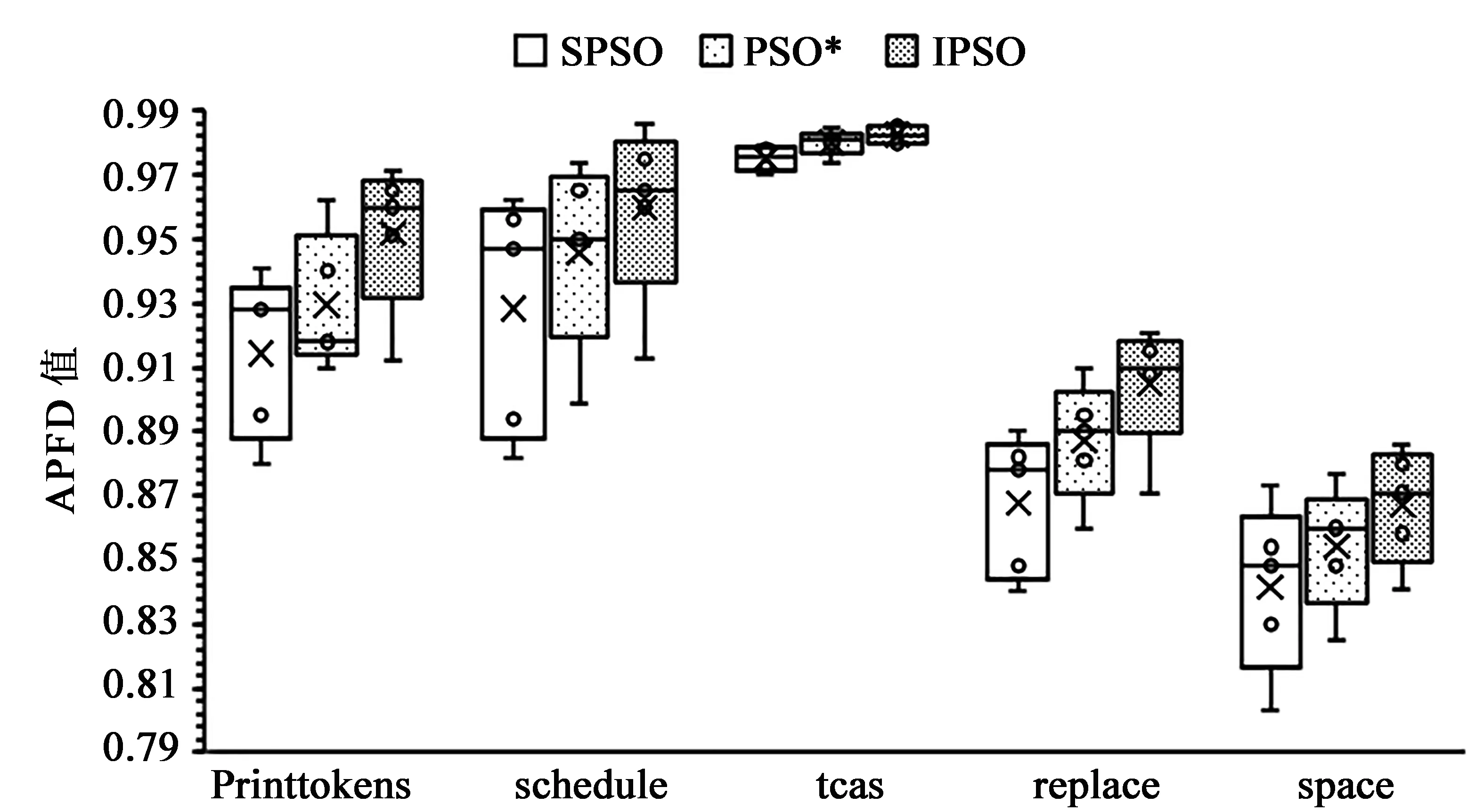
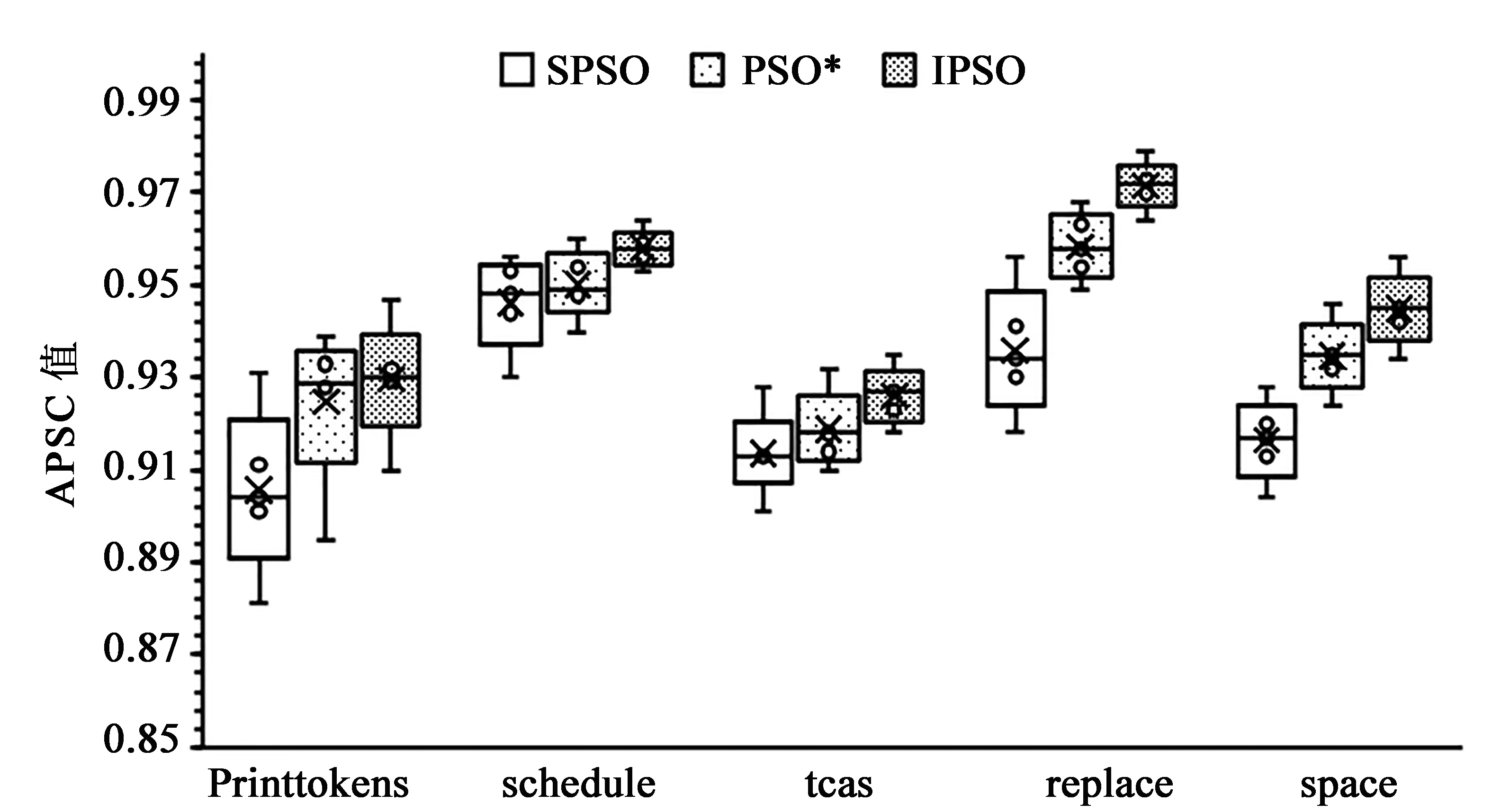
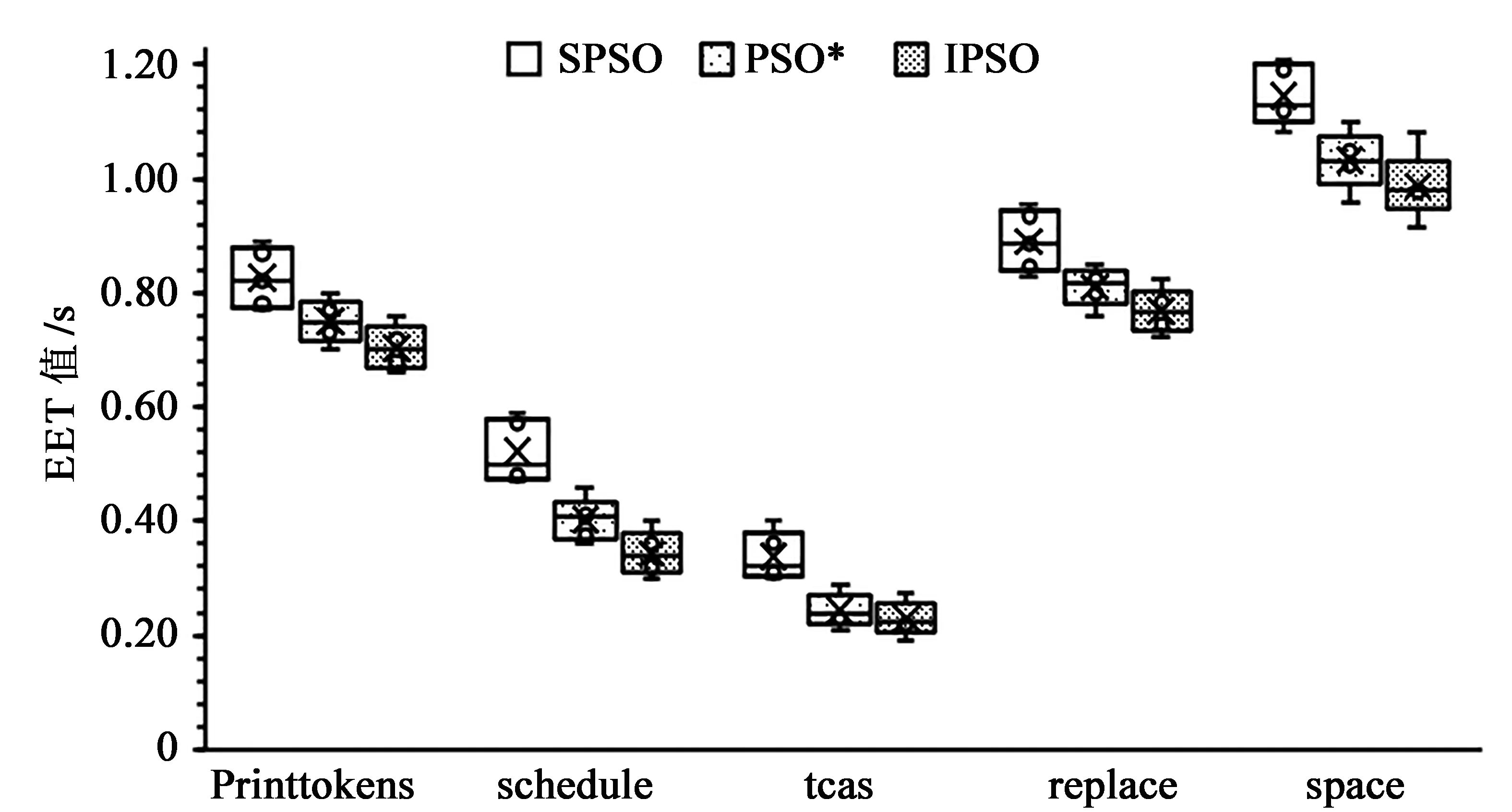
公式(4)中l1和l2为学习因子,分别表示粒子对自身历史最优和整体历史最优的学习认知能力,一般取l1=l2=2。在算法初期,l1>l2,其较大的l1值便于粒子更多地依靠自身的认知搜索,避免早熟;较小的l2值可弱化其他粒子的影响,加快算法收敛速度。在算法晚期,l1 根据上述分析,本文提出了随惯性权重变化而动态调整的学习因子公式: (8) 其中l1,start、l1,end分别表示学习因子l1的初始值和终止值;l2,start、l2,end分别表示学习因子l2的初始值和终止值。由公式(8)可知,此学习因子可保证算法前期自我认知能力强,后期社会认知能力强,达到更快的收敛速度和更好的寻优精度。 2.2.4 混沌搜索 混沌是非线性确定系统中出现的类似随机的不规则运动,具有随机性、遍历性及规律性三大特性。结合混沌运动的特性,利用混沌映射完成优化变量从解空间到混沌空间的转换,进行混沌搜索,可帮助算法跳出局部极小点,保证种群多样性,并快速找到全局最优解。 本文算法利用Tent混沌模型进行混沌搜索,对公式(6)中Tent映射进行贝努利移位变换,变换后的公式为 (9) 混沌搜索优化的具体步骤如下: 步骤1 将当前全局最优值Pg按式(10)由取值区间[pmin,pmax]映射至混沌变量的取值区间[0,1], (10) (11) 步骤4 选取最优解向量P*,替换掉在迭代中不是全局最优且所有个体极值亦未发生变化的粒子个体。 在SPSO中引入混沌搜索方法生成新粒子,并用新粒子代替原种群的惰性粒子,帮助算法跳出某个小范围,进而使算法摆脱早熟收敛。 通过前文对TCP问题建模分析及对SPSO相关参数的改进与调整,将改进的粒子群算法用于求解测试用例优先排序,基本流程如下: (1)设定粒子种群大小N、搜索维数D、最大迭代次数T、速度上限vmax、搜索范围、学习因子的初始值和终止值等相关参数; (2)使用Tent映射粒子种群的位置和速度,即随机生成测试用例优先级序列; (3)根据公式(2)、(3)计算每个粒子的适应度值; (4)如粒子适应度值优于个体极值,则更新它; (5)如粒子适应度值优于全局极值,则更新它; (6)进行混沌搜索,性能最好的可行解代替原种群的惰性粒子; (7)根据公式(7)计算惯性权重ω,根据公式(8)计算学习因子l1和l2; (9)获得新测试用例优先级序列; (10)判断是否满足终止条件,若是,则输出测试用例优先级序列,算法停止,否则,迭代次数增1,转至步骤(3)。 为了验证本文所改进的粒子群算法(IPSO)的优越性及在测试用例排序中的有效性,通过两组实验进行测试,将其测试的结果与标准粒子群算法(SPSO)、文献[5]的粒子群算法(PSO*)的测试结果进行对比。 实验1 采用平均适应度值作为评价指标,使用两个典型测试函数进行对比实验,以验证算法性能。各算法的参数设置为:在SPSO和PSO*算法中,惯性权重ω为0.7,学习因子l1=l2=2;在IPSO算法中,惯性权重ω由公式(7)计算,学习因子l1和l2由公式(8)计算。实验时粒子群规模N为40,维数D为30,最大迭代次数T为500,测试函数如表1所示。 表1 测试函数及相关参数 实验2 为检测本文所提的IPSO在解决测试用例优先排序问题时的有效性,实验从软件工件基础设施库(Software-artifact Infrastructure Repository,SIR)中选择printtokens、schedule、tcas、replace、space等5个程序作为实验待测程序,5个待测程序统计信息如表2所示。因待测程序的用例集合中含有许多冗余测试用例,为保障测试结果的可靠性,在实验开始前应先从用例池中选取冗余度较小的目标测试用例集,其语句覆盖率达到用例池的最大语句覆盖率即可。 表2 待测程序统计信息 表3 IPSO主要参数配置 本文程序使用MATLAB2012a实现,实验主要参数配置如表3所示。其运行环境为:Intel Core i5-4590 CPU,主频3.3 GHz,内存4 GB,Windows 7操作系统。 为避免不确定因素带来的影响,保证3种算法比较的科学性、公平性,对3种算法各评价指标分别独立运行100次,取平均。通过对实验1的仿真测验,3种算法在两个测试函数上的平均适应度值如表4所示。 表4 两个测试函数的平均适应度值 从表4可以看出,在求解F1和F2函数最优时,本文所提的IPSO算法,平均适应度值明显小于其他两个算法,其搜索精度相较于SPSO和PSO*算法均提高了5倍以上。实验结果表明,IPSO算法在求解单峰函数(Sphere)和多峰函数(Griewank)上均有优势,能达到较好的寻优精度并找到全局最优解。 实验2使用3种算法对表2中的5个待测程序进行实验比较,从缺陷检测率、测试用例语句覆盖率和有效执行时间等方面评价优劣。实验结果如箱形图1、2、3所示。 图1 SPSO、PSO*、IPSO针对各测试程序的APFD值 图2 SPSO、PSO*、IPSO针对各测试程序的APSC值 图3 SPSO、PSO*、IPSO针对各测试程序的EET值 通过图1的箱形图对比可知,IPSO算法在缺陷检测率上明显优于SPSO和PSO*算法,其中tcas程序数值较集中。通过图2的箱形图对比可知,IPSO算法在语句检测率上也优于SPSO和PSO*算法,取值区间波动较小,优化效果更加稳定,其中replace程序优化最为明显。通过图3的箱形图对比可知,IPSO算法的EET值比SPSO和PSO*算法大幅降低,总时间基本在0.8 s以内,由于space程序规模稍大,所用时间较长。IPSO算法通过Tent映射初始化粒子群,防止其落入小周期,并引入随适应度值自适应调节的惯性权重及学习因子,平衡算法的全局搜索和局部开发能力,并对惰性粒子进行混沌搜索优化,使其跳出局部最优,实验结果表明,本文所提方法较SPSO和文献[5]的粒子群算法(PSO*)收敛速度快、寻优精度高。综上所述,IPSO在测试用例优先排序问题上效果显著,在缺陷检测率、测试用例语句覆盖率和有效执行时间等方面均有优势。 本文基于标准粒子优化算法,引入Tent混沌映射初始粒子种群,通过非线性自适应调节因子方式来平衡算法性能,对惰性粒子进行混沌搜索优化,以提高种群的多样性,使改进的算法具有较快的收敛速度及较强的寻优能力。采用5个待测程序对优先级排序进行实验验证,结果表明,该方法对TCP问题在缺陷检测率、测试用例语句覆盖率和有效执行时间等方面均有优势,大幅提高了软件测试效率。下一步将就其他群体智能算法在软件测试中的应用做进一步的研究。
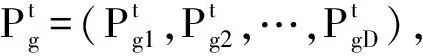
2.3 改进粒子群算法求解测试用例优先排序框架
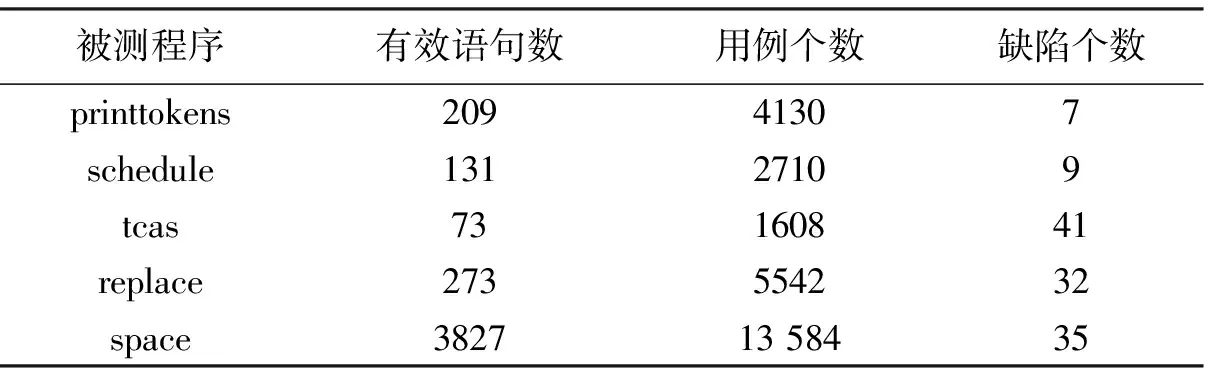
3 实验分析
3.1 实验设计

3.2 结果与分析

4 结 语
猜你喜欢
今日农业(2022年15期)2022-09-20
中学生数理化·八年级物理人教版(2022年3期)2022-03-16
今日农业(2021年21期)2021-11-26
科教导刊·电子版(2021年1期)2021-03-26
铁道通信信号(2020年6期)2020-09-21
中学生数理化·八年级物理人教版(2017年3期)2017-11-09
西南交通大学学报(2016年6期)2016-05-04
林业与生态(2016年2期)2016-02-27
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
中学生数理化·八年级物理人教版(2014年1期)2015-01-09
