
面向教育大数据多尺度特征融合的成绩预测方法在眼科本科教学中的探索
2020-03-16 08:26石慧宋世涛肖扬
科技创新导报 2020年33期
石慧 宋世涛 肖扬
摘 要:伴随着我国教育大数据研究的全面开展,学生表现受多方面影响,传统方法面向单尺度、单方面对学生表现进行模型建立与预测分析具有一定片面性,由于影响因素往往来源于不同尺度不同特征因素,因此本文综合学生、教师、成绩等多方面进行特征融合提取,建立多尺度特征融合预测模型对学生表现进行预测,取得较好的效果。
关键词:教育大数据 眼科 成绩预测 学生行为特征
中图分类号:G642 文献标识码:A 文章编号:1674-098X(2020)11(c)-0214-05
Research on Big Data of Multiscale Feature Fusion for Student of Ophthalmology Performance Prediction in Education
SHI Hui1 SONG Shitao2 XIAO Yang2
(1. The First Hospital of Jilin University, Changchun, Jilin Province, 130021 China; 2.Jilin Jianzhu University, Changchun, Jilin Province, 130118 China)
Abstract: With the comprehensive development of education big data research in China, student performance is affected by many aspects, and the traditional method of modeling and prediction analysis of student performance on a single scale and unilaterally has a certain one-sidedness. As the influencing factors often come from different scale and different feature factors, this paper integrates the characteristics of students, teachers, grades and other aspects for feature fusion extraction, and establishes a multi-scale feature fusion prediction model to predict the performance of students, achieving good results.
Key Words: Big data on education; Ophthalmology; Performance prediction; The characteristics of students' behavior
近年來,随着信息产业的飞速发展,各行业数据量也成几何级数增长,在这些海量数据中蕴藏着无数宝贵的资源和价值信息,而人工分析、手动提取的方法已经逐步退出历史舞台,而随着机器学习、大数据挖掘技术的快速崛起,如何智能化、科学化、将这些信息资源进行有效的整合、提取、分析,并作为各种决策、改革的有效数据支撑已经成为各行业热门的研究方向,而作为各行业的基石-高等教育如何挖掘学生、教师、学科、成绩等方面的关联性成为教育改革、发展的重要需求和急需解决的首要问题。我国也早在2015年就提出要大力发展建设教育大数据平台,而其他发达国家也先后针对教育数据挖掘和分析提出了相关的要求和政策扶持,以致越来越多的高校和教育研究机构把教育大数据的分析成果引入到教学改革与教学管理之中[1-2]。
1 存在问题
教育行业关心的首要问题就是教学质量,而学生的学业表现是反映教学质量的首要指标,我校作为国内外知名大学近年来学生人数不断增多,课堂规模、授课形式逐步扩大,而作为一线教师,面向众多学生和教学任务、科研任务的情况下,除了在完成日常教学工作和科研任务很难做到追踪并了解每位学生的学习情况,甚至及时、有效、有针对性地调整授课计划,优化教学策略,配置教学资源、改进教学方法,以致于出现部分学生突然成绩下滑、留级、退学等现象,这在一定程度上影响了我校的教学质量,因此利用机器学习和大数据分析构建学生学习表现预测模型就尤为重要,通过预测模型提前对“风险学生”进行预警并关注,避免学生失去学习兴趣以致最终无法继续学业成为重要的研究课题[3-4]。
2 研究现状
针对学生成绩表现预测国内外众多学者已有一定成果,例如早期数据来源多采用调查问卷的形式,并且调查内容也主要从教育学和心理学角度,包括学生的学习动机、性别、年龄、家庭背景等方面,Poropat[5]提出的人格因素与学生表现的相关性。随着教学手段的不断发展,产生了众多的慕课、微课等教育平台,信息逐渐偏向收集学生的在线课堂表现如在线时间、在线次数、完成作业情况、在线讨论等数据特征提取,Ren、Macfady[6-7]等学者在这方面做出了一定的研究成果。随着机器学习的飞速发展很多学者如蒋卓轩[8]等采用机器学习分类方法预测学生是否能够顺利完成学业。Huang[9]等人综合90个学生信息采用决策树的分来方法预测学生后续课程的完成度,但此类研究多受数据体量和种类所限,很难将众多数据进行多尺度融合进行综合分析,这在一定程度上影响了预测结果的可信度,而本研究得到学校的支持,通过已经建立的大数据分析平台,很多复杂的工作得到简化,数据内容大量增加,数据格式统一减少了前期数据处理的巨大工作量,使得实验能够顺利进行。
3 学生表现模型构建
3.1 样本表达
由于教育大数据研究方向和研究内容较多,本文主要针对建立学生综合表现(GPA即平均成绩点数)建立学生表现预测模型,从而研究并预测学生的学习状态并为后续教学改革提供数据支撑。学生样本表示直接关系到模型的特征提取,是构建准确预测模型的重要前提,传统的学生表现预测方法只考虑本门课程或本学期课程的特征信息,没有考虑课程之间的关联性,以及课程、教师与学生行为之间的关联性忽略三者之间存在的内在联系,影响最终预测精度,而本文提出一种面向多角色、多角度的学习算法实现多种数据统一在同一模型框架下进行统一建模能够进一步提高预测的可信度。
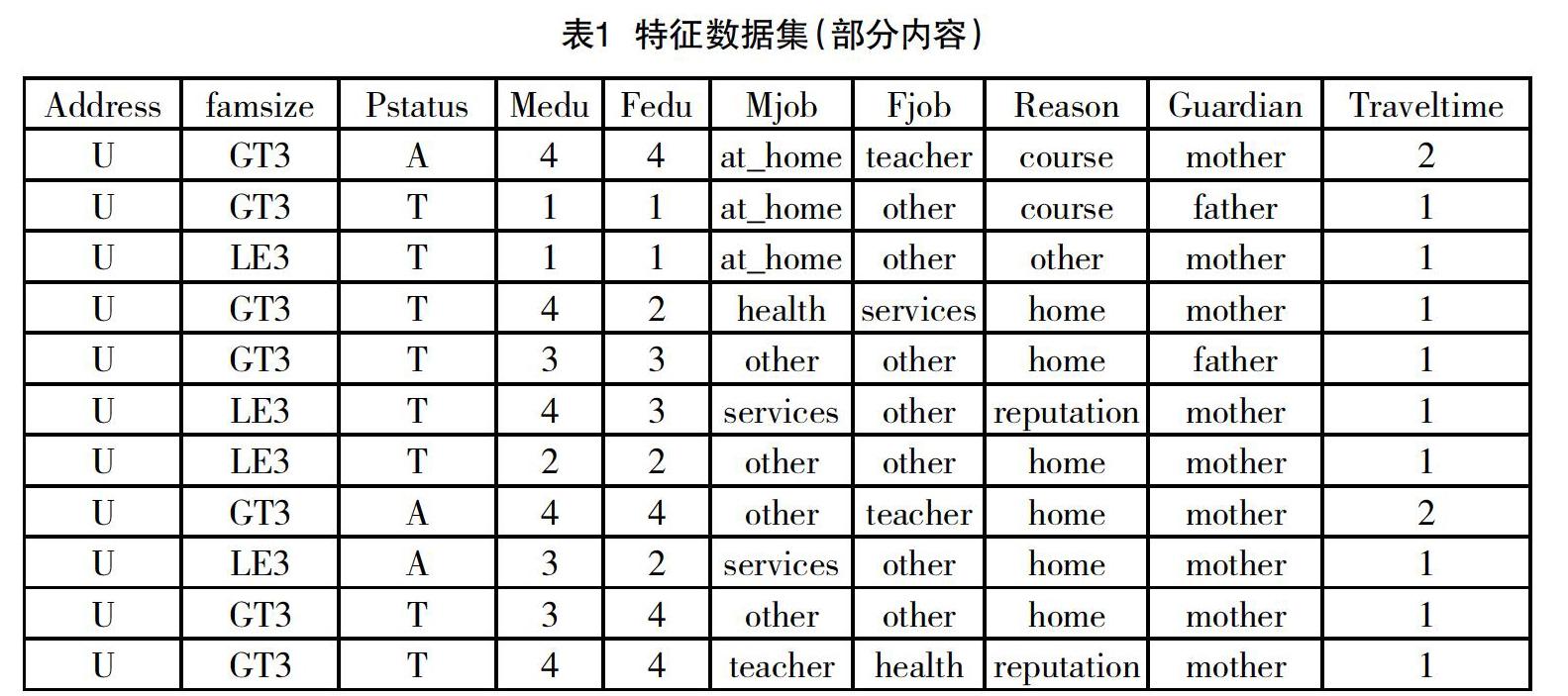
本研究以吉林大学白求恩医学部临床医学专业4届学生共980人作为研究对象,数据来源包括线上、线下、校园一卡通3部分构成,线下数据主要是多年积累的线下数据包括学生个人基本信息(包括性别、年龄、家庭情况、民族、生活收入水平、生源省份、学习动机、是否为第一志愿等)、课堂表现信息(包括出勤、课堂讨论、随堂测试等)、成绩信息(入学成绩、各学期单科平时成绩、期末成绩、英语等级考试成绩、计算机等级考试成绩等)、学生校园行为信息(主要图书借阅信息、图书管等场所的出入信息、食堂就餐信息、超市消费信息等)、专业课程信息(包括专业课程开设的学期、课程学分、课程性质、课程开设顺序等)、相关专业教师信息(包括教师学历、职称、年龄、性别、所学专业、科研情况、教龄等)。线上数据包括今年疫情期间进行的线上教学信息、多年来学生在吉林大学网课平台的学生活动日志等统计信息(包括视频观看时间、相关专业课程观看种类、观看次数、讨论数量、线上测验成绩、登录时长等),由于篇幅所限仅列出表1中部分数据。
本研究对象由于分析目标对象特征类型较多,所以首先采用皮尔森相关系数分析法从4类标签中分别提取对学生表现相关特征影响最大的,生成高相关特征的数据集,然后利用Kaggle平台上表现优异的Xgboost框架进行模型构建,最后结合特征工程处理,取得良好的训练预测效果。对照组中将学生、教师、课程等因素联动性影响因素融合原数据生成训练集,完成特征扩充。
3.2 特征提取
数据集由37个特征和4个标签构成,由于目标对象的复杂性导致很难用单标签的方式进行直接分类和解释,所以采用多标签分类原理模型。由于多标签问题的复杂性一般从待预测值关系可分为依赖关系和独立关系两类,本研究4个标签之间存在依赖关系,所以采用的策略转换为Classifier Chains,此方法的核心思想是将多标签分类问题进行分解,将其转换成一个二元分类链的形式,后一个分类是在前一个分类的基础上进行的,即后一个输入时前一个分类的输出,模型公式如下所示
X,Y=[y1,y2,y3,y4](1)
shuffle:X,Y=[y2,y3,y4](2)
然后在構建下一个模型
shuffle_sorted{1,2……,m} (3)
对m个分类进行打乱
(4)
(5)
评估标准与相关系数计算
本文利用Pandas中的corr()方法,其中常见的方法有图示法、Pearson相关系数Sperman相关系数法,由于样本数据不满足连续数据,正态分布,线性关系,所以本研究采用Sperman相关系数是最恰当,该算法通过衡量预测值和实际值的Spearman相关性,如果计算结果为[0,1]之间的值,值越大,表示越相关,预测就越准确。那么对于普通样本模型之间没有相同秩序采用如下公式
(6)
而对于有相同秩序存在,就需要计算秩序之间的Pearson的现行相关系数,公式如下所示。
(7)
4 实验过程
实验过程包括数据预处理、拆分、训练、预测与评估几个主要步骤。
4.1 数据预处理
(1)首先将采集的数据源结构化。对于简单的数据类型例如学生性别、学位英语等级、课程性质等直接采用0表示yes,1表示no将文本数据量化,例如课程性质为必修课表示为1,选修课表示为0;而对于一些多种类的文本型字段,如期末成绩、学分、教师职称、家庭收入等可以结合业务场景来抽象,比如说如果教师职称高级就表示为1,其他职称表示为0,抽象后这个特征的意义就是表示教师教学水平相关程度。对于部分复杂目标列,我们按照多等级抽象分为1,2,3….,拟通过训练找出相关度高的进行拟合训练。
(2)此外预处理还包括部分属性缺失,由于本文采用的是xgboost框架算法,可以有效地处理对特征影响不大的缺失值并自动进行填充,默认将缺失值设置成missing=-9999。
(3)通过人工筛查和describe方法对单个属性分析清洗部分非相关性属性数据,分析结果包括平均值,最值,标准差等。
4.2 数据归一化
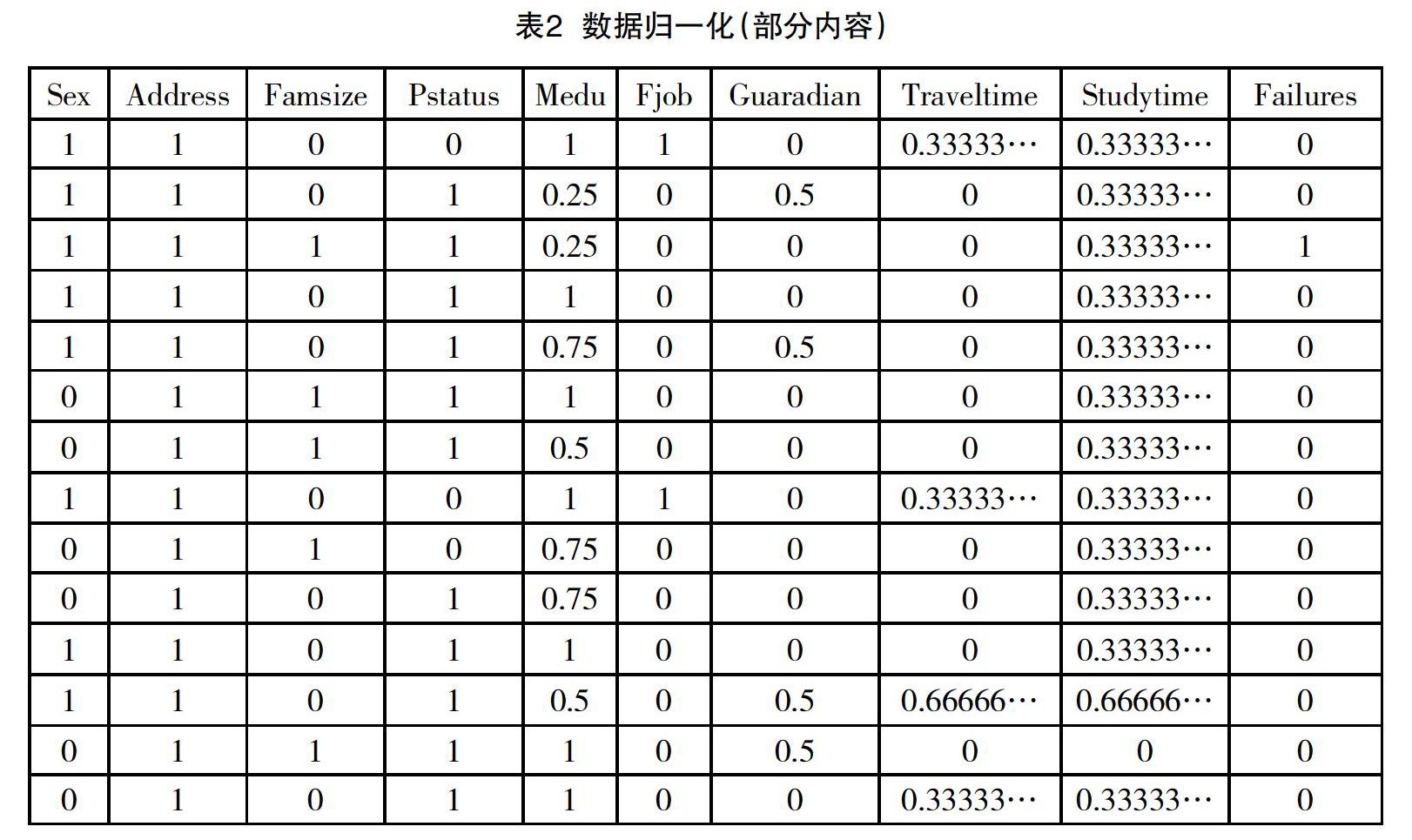
由于本研究对象属性众多内容复杂,需将已有数据进行归一化,将所有的字段都转换成0~1之间,去除字段间大小不均衡带来的影响,部分结果如表2所示。
4.3 训练集和验证集拆分
将数据集按照7:3拆分,70%用来训练模型,30%的用来预测。
4.4 各属性与成绩的相关性分析
常用的编码方式分为标签编码方式和独热编码,对于只有2个唯一值得特征采用标签编码,如果分类变量具有许多类多个值则采用独热编码方式,本研究采用后者,然后分别计算各个属性与最终预测值Y学生表现的相关性,将相关性高的属性进行保留作为模型训练的数据输入。
4.5 预测模型训练
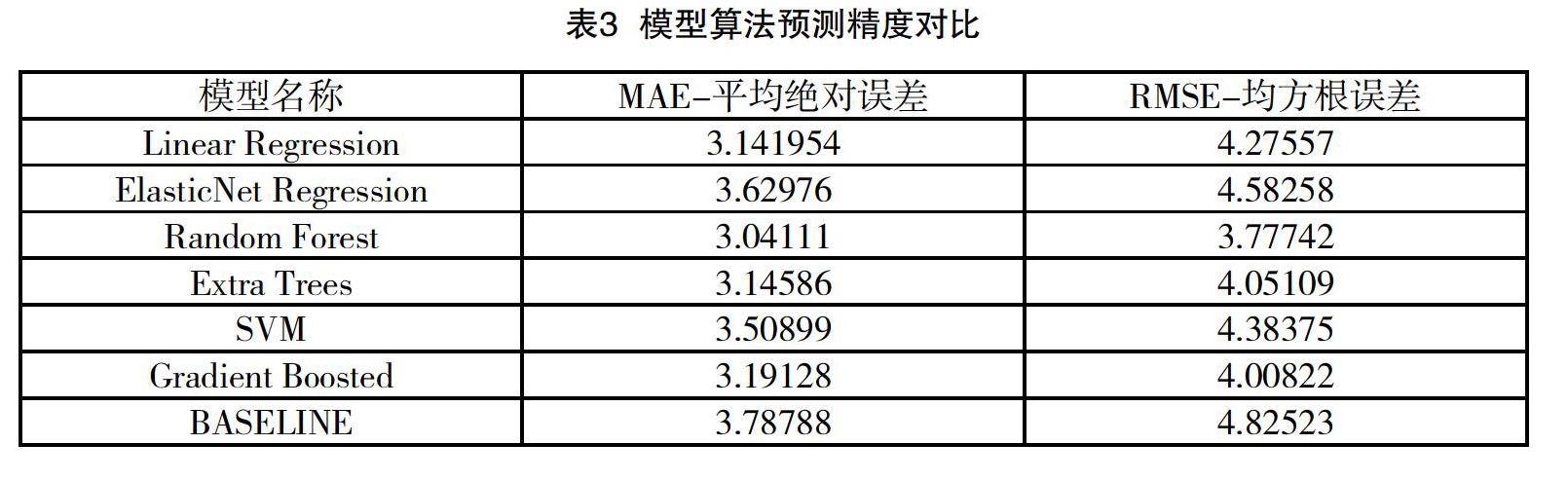
最终选取框架提供的六种模型,分别为:线性回归、ElasticNet回归、随机森林、极端随机数、支持向量机(SVM)、梯度提升树,进行预测模型训练对比效果如表3所示。
5 结语
本研究采集了线下学生信息、学生个人情况属性信息、线上学习统计信息、学生行为特征和教师行为特征等数据作为研究对象的特征,运用特征分析和特征选择,选取了37个特征构成的特征子集表示每一个研究对象。最终利用xgboost框架算法,采用6种机器学习算法,构造了不同的学习成绩预测模型。通过比较模型的准确度、召回率、F值,误分类样本数量和精确度,通过分析,发现影响学习成绩的主要因素是学生行为特征、教师行为特征、基础课程的成绩表现,为提高学生表现GPA,教学过程中应该随时关注学生行为特征相关属性的变化,并配合教师行为特征进行适当的授课计划调整,激发学生教师的内在动力,积极关注基础课程的学生成绩变化,预测学生的学习表现,并针对预测结果实施相应的授课计划调整,为教学改革提供参考。
参考文献
[1] 苏国曦.基于特征表示的终身机器学习算法研究[D].广州:华南理工大学,2018.
[2] 肖逸枫.数据挖掘技术用于高校学生留级预警的研究[D].重庆:重庆大学,2018.
[3] 谢娟英,张宜,陈恩红. 学生成绩关键因素挖掘与成绩预测[J].南京信息工程大学学报:自然科学版, 2019,11(3):316-325.
[4] 马玉玲.基于机器学习的高校学生成绩预测方法研究[D].济南:山东大学,2020.
[5] Arthur E Poropat. A meta-analysis of the five-factor model of personality and academic performance[J]. Psychological Bulletin, 2009, 135(2): 322.
[6] Leah P. Macfadyen,Shane Dawson. Mining lms data to develop an early warning system for educators: A proof of concept[J]. Computers & Education, 2010, 52(2):588-599.
[7] Zhiyun Ren,Huzefa Rangwala,Aditya Johri, Predicting performance on mooc assessments using multi-regression models[C].//In Proceedings of the 9th International Conference on Educatinal Data Mining, 2016.
[8] 蔣卓轩,张岩,李晓明. 基于mooc数据的学习行为分析与预测[J].计算机研究与发展,2015,52(3):614-628.
[9] Shaobo Huang,Ning Fang. Predicting student academic performance in an engineering dynamics course :A comparison fo four types of predictive mathematical models[J]. Computers &Education, 2013,61(1):133-145.
猜你喜欢
中国眼镜科技杂志(2022年9期)2022-09-07
国际眼科杂志(2022年7期)2022-07-13
国际眼科杂志(2022年6期)2022-06-05
中医眼耳鼻喉杂志(2019年3期)2019-04-13
中国眼镜科技杂志(2017年10期)2017-07-10
现代交际(2016年24期)2017-04-14
云南中医学院学报(2012年3期)2012-07-31
