
基于自适应随机森林的数据流分类算法*
2020-03-26 11:08张馨予安建成
计算机工程与科学 2020年3期
张馨予,安建成,曹 锐
(太原理工大学软件学院,山西 晋中 030600)
1 引言
处理源源不断的数据流的需求越来越多,应用场景无处不在,如信用卡欺诈监测、网络流量监控和在线金融交易等场景,这些数据流中往往蕴含着巨大的信息量。为了获取并掌握这些信息,人们开启了对数据流分析方法的探索。
传统的机器学习算法大多针对离线数据反复训练模型,而数据流[1]中的数据具有高速到达、变化多样以及规模庞大等特点,这些特点对传统的机器学习算法提出了新的挑战。
大多数数据流都具有概念漂移[2]的特点,“概念漂移”是指随着时间的推移,目标变量的统计特性以不可预见的方式发生变化的现象。对具有概念漂移的数据流进行预测的模型,如果不采取适当的应对概念漂移的措施,预测精度会随着时间的推移而降低。
数据流分类研究领域的专家们已经证明了相对于单分类器,集成分类器具有更优的学习性能[3],这是由于集成分类器不需要复杂的优化过程且能灵活处理概念漂移的问题。现有的典型的分类器集成方法大多分为3类,分别是基于bagging、基于boosting和基于随机森林的集成方法。Bifet等人[4]介绍的leveraging bagging是基于bagging的集成方法。Chen等人[5]提出的online smooth-boost是基于boosting的集成方法的典型代表。国内对数据流分类器集成过程的一些研究是通过结合bagging和boosting的部分特点进行的。比如文献[6]依据不同数据特征对分类的影响程度不同的理论,提出基于特征漂移的数据流集成分类方法。文献[7]在经典的精度加权集成AWE(Accuracy Weighted Ensemble)算法[8]的基础上提出概念自适应快速决策树更新集成算法。而基于随机森林的算法在处理具有概念漂移的数据流分类时性能较优,主要是由于该算法对输入数据的预处理以及对超参数设置的要求较低。利用随机森林算法对数据流分类的代表是Abdulsalam等人[9]2008年提出的动态流随机森林算法。但是,该算法缺少重采样方法,使用的漂移探测算法缺少可靠的理论依据,且该算法提出时仅在合成数据集上被评估,缺乏普适性。2017年Gomes等人[10]在已有算法基础上提出了自适应随机森林分类ARF(Adaptive Random Forest)算法,该算法的优势在于结合在线bagging的重采样方法生成训练集,在每棵基础树上增加概念漂移探测器、背景树训练等机制自适应更新集成器来应对概念漂移。但是,该算法在有效提高分类性能的同时,消耗的时间和内存空间较大。
本文针对具有概念漂移的较平衡数据流提出了一种改进的自适应随机森林集成分类算法RARF(Revised Adaptive Random Forest),算法将探测器设置在集成器上,增加了移除基础树机制和统一训练背景树机制,不仅使得算法具有较高的准确率,还有效降低了运行时间和内存消耗。
2 自适应随机森林分类算法
ARF将批处理算法的特点与动态更新方法结合起来用于处理不断变化的数据流。创新优势及存在的问题如下所示:
2.1 创新优势
ARF的主要目标是处理带有概念漂移的数据流。当有新数据流进来时,每棵基础树都会对新数据流进行预测,根据预测结果更新基础树权重。ARF为每棵基础树设置了漂移探测器,漂移探测器有2个超参数:警告阈值δw和漂移阈值δd。当漂移探测器的探测结果达到δw时,开始在背景上同步训练1棵全新的基础树(称为背景树),当漂移探测器的探测结果达到δd时,背景树代替原基础树作为集成器的一份子。背景树是提前接受过训练的,这种替换机制有效克服了传统直接替代法中新基础树没有受过任何实例训练,无法对集成器产生积极影响的问题。
2.2 存在的问题
ARF在每棵基础树上分别配置漂移探测器,运行过程中经常会同时触发多个探测器,引起多棵背景树同时开始训练,导致运行时间较长,运行资源占用较多。
3 改进的自适应随机森林集成分类器
RARF是本文提出的一种基于自适应随机森林的数据流分类算法,该算法主要包含基础树的训练过程和集成器的更新过程。
3.1 基础树的训练过程
RARF算法根据式(1)对实例进行重采样,为同一实例分配不同权重用于训练不同基础树。
Poisson(λ=6)
(1)
对Hoeffding树[11]进行改进得到基础树。首先,基础树在训练之前不会进行任何形式的预剪枝。其次,基础树的任何1个节点在分裂的过程中都会从所有的M个特征中随机选取m个特征作为分裂的依据。m的计算如式(2)所示:
(2)
基础树在对实例进行训练之前首先根据预测结果更新基础树在集成器中的权重,在没有发生概念漂移前通过削弱表现不好的基础树的权重减少其对集成器的影响;当发生概念漂移时,通过使用背景树集替换的方式移除表现差的基础树,两者结合可消除历史数据对集成器的消极影响。
3.2 集成器的更新过程
RARF在集成器上设置1个探测器,对实例的集成预测结果的变化进行探测,当发生概念漂移警告时,根据式(3)确定需要同时训练的背景树个数b。该改进使得探测器的个数由n降为1,由于集成预测结果相较于基础树的预测结果更为准确全面,所以在集成器上设置探测器能更准确地捕获概念漂移。
b=n(1-ln(1+AccE(e-1)))+n/10
(3)
文献[12]提出了一种根据准确率计算替换基础树个数的公式,考虑到文献[12]中的公式会引入2个超参数,所以对其进行改进得到式(3)。其中,n为集成器中基础树的总数量,AccE为集成器的准确率,e为自然底数,准确率越高,1+AccE(e-1)的值越趋近于e。集成器的准确率越高,背景树数量b越小,可以通过替换少量基础树来保持性能;当集成器的准确率较低时,可以通过替换更多的基础树来快速恢复准确率。
若探测器的结果达到漂移阈值,此时的背景树集已是同步经过训练后的候选树集。由于基础树的权重是实时更新的,且权重的大小反映基础树表现的优劣,RARF将与背景树集中树数量一致的权重较小的基础树集移除,用背景树集替换。这种机制使得当发生概念漂移时,迅速用背景树集替换1组基础树,集成器性能可更快地从概念漂移中恢复,同时增强了算法在准确性和内存消耗方面的自主性。
3.3 算法流程
算法参数:集成器中的基础树集T;集成器中基础树的数量n=|T|;用于评估每个分裂节点的最大特征数α;数据流S;警告阈值δw;漂移阈值δd;漂移探测器C(·);背景树数量b;背景树集合B;移除树集合R;树t的权重W(t);学习性能评估器P(·);集成器E(T);具体实例(x,y),其中,x为特征,y为类别。
算法1RARF算法
输入:S,m,n,δw,δd。
输出:S的分类结果。
1.T=CreateTrees(n);
2.W=InitWeights(n);
3.B=∅;
4. whileHasNext(S) do
5. (x,y)=Next(S);
6. for allt∈Tdo
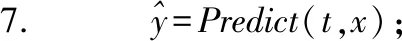
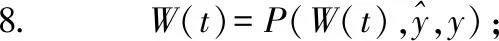
9.RFTreeTrain(α,t,x,y);
10: end for
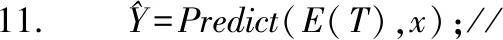
12. ifC(δw,E(T),x,y) then
13.B=CreateTree(b);//创建背景树集
14. for allt∈Bdo
15.RFTreeTrain(α,t,x,y);/*训练背景树集中的每棵树*/
16: end for
17. end if
18. ifC(δd,E(T),x,y) then
19.E(T)=E(T)-R(b)+B(b);/*用背景树集替换效果差的树集*/
20. end if
21. end while
4 实验及结果分析
为验证RARF算法的有效性,选用LED、“森林覆盖类型”和SEA(Streaming Ensemble Algorithm)3个数据集进行仿真实验,在每个数据集上分别使用ARF和RARF 2种模型进行对比实验。
4.1 训练数据集描述
LED显示域数据集[13]属于合成数据集,共包含1 000 000个实例,每个实例有24个布尔类型的特征,其中17个是不相关的,具有逐渐漂移的特性。分类目标是预测在7段LED显示屏上显示的数字,共有10个类别,每个类别的样本数基本均匀。
“森林覆盖类型”数据集[14]来源于美国地质调查局和美国森林服务中心的原始数据。数据包含定性自变量(荒野地区和土壤类型)的二进制(0或1)列数据。整个数据集共包含分属于7个不均匀等级的581 012个样例,每个样例由 54个特征组成,包括 10个数量变量,4个二进制自然保护区,40个二进制土壤类型变量。
SEA数据集是合成数据集,在数据挖掘中经常用到,它包含3个随机生成的实数特征和2个正负类别,区分类别的边界由f1+f2 ≤θ给出,通过改变θ的值来引入概念漂移。SEA数据集首先被用于数据流集成算法 SEA[15]的实验部分。
4.2 实验环境
实验环境使用Windows 10操作系统,CPU为Intel 4核,内存为8 GB,开发语言使用Python 3.6,开发工具使用PyCharm 2018,实验框架为大规模在线分析平台MOA(Massive Online Analysis)[16]。
4.3 评价策略
实验采用prequential评价策略[17],即每条实例先作为测试实例而后作为训练实例,准确率增量更新。采用这种评价策略不用为了测试而保留数据集,从而保证了最大化地利用每个实例的信息,也保证准确率随时间具有平滑性。
4.4 实验分析
2个算法的参数设置如表1所示。实验主要从时间消耗、内存消耗、准确率和Kappa值对比3方面进行分析。

Table 1 Default experimental parameter Settings表1 默认实验参数设置
4.4.1 参数影响
对待分类的实例进行分类需要选择合适数量的基础树,在此过程中,RARF需要根据基础树数量决定背景树个数和移除基础树的个数,而ARF需要根据基础树数量配置相同数量的探测器。对2个算法而言,基础树的数量不能过大。通过实验得出,设置20棵基础树可以保证较高的准确率,同时加强了时间和空间消耗的对比性。因此,在以下实验中,均取基础树数量n=20。
4.4.2 时间效率
图1~图3所示为ARF算法和RARF算法分别在LED、“森林覆盖类型”、SEA 3个数据集上的时间消耗。如图1~图3所示,RARF算法的时间消耗在各数据集上均少于ARF算法的。这是因为RARF算法的每棵基础树只负责实例的训练和预测,在集成器端对实例预测结果进行1次探测检查,而ARF算法每棵基础树在训练和预测结束后要对实例进行k次探测检查。因此,RARF算法消耗的时间更短,性能更高。
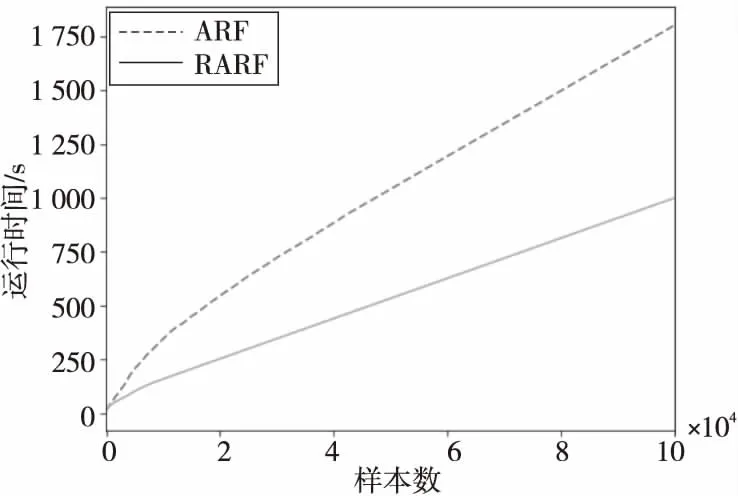
Figure 1 Time consumption comparison on LED data set图1 LED数据集上的时间消耗对比
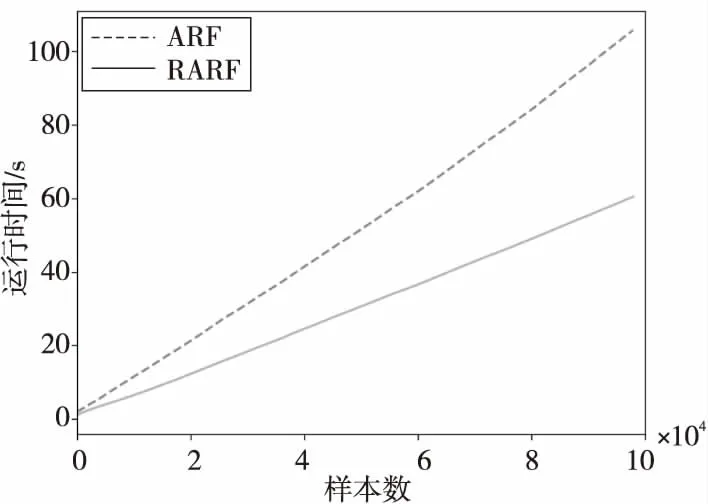
Figure 2 Time consumption comparison on “Forest cover” type data set图2 “森林覆盖类型”数据集上时间消耗对比
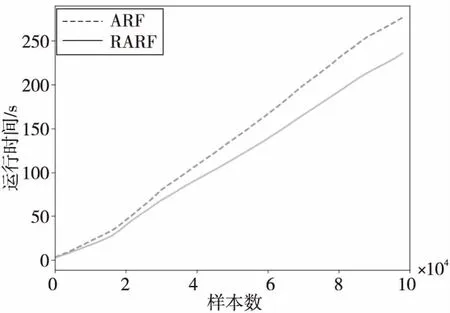
Figure 3 Time consumption comparison on SEA data set图3 SEA数据集上时间消耗对比
4.4.3 内存消耗情况
2种算法内存消耗对比情况如图4~图6所示。由图4~图6可以看出,RARF算法的内存消耗在LED和SEA数据集上少于ARF算法的,在“森林覆盖类型”数据集上大于ARF算法的。这是因为“森林覆盖类型”数据集是1个不平衡的数据集,正负样本比例悬殊,当出现正样本时,准确率迅速下降,集成端探测器发现漂移,触发一批背景树同步训练,空间消耗较大。在LED和SEA这种基本平衡的数据流上,2种算法的准确率不会出现骤变,RARF算法所需的内存远小于ARF算法的。这是由于ARF中的各基础树选取的特征不同,同一实例在不同基础树上的权重也不同,预测结果出现多样化,更容易在一些并未发生漂移的情况下检测出漂移,进而触发训练背景树的动作,使得内存占用增大。而RARF算法克服了该问题,仅在漂移真正出现时训练背景树,因此对于比较平衡的数据流而言,RARF算法消耗的内存更少。

Figure 4 Memory consumption comparison on LED data set图4 LED数据集上的内存消耗对比
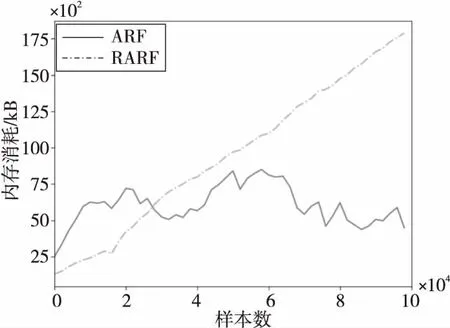
Figure 5 Memory consumption comparison on “Forest cover type” data set图5 “森林覆盖类型”数据集上的内存消耗对比
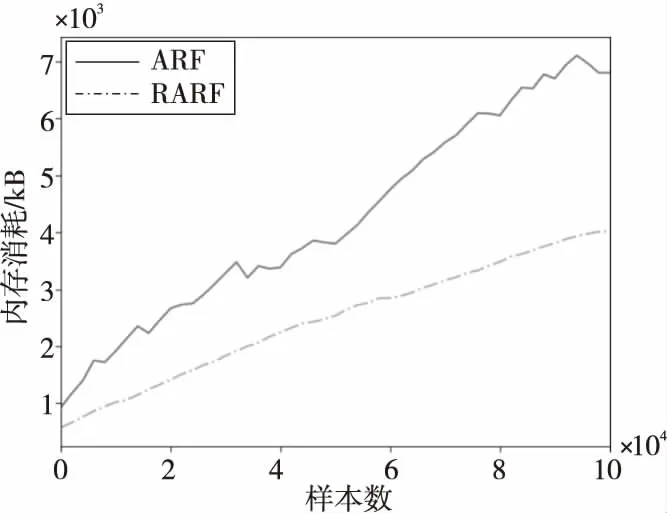
Figure 6 Memory consumption comparison on SEA data set图6 SEA数据集上的内存消耗对比
4.4.4 准确率和Kappa值
图7~图9显示的是2种算法在3个数据集上准确率和Kappa值的变化过程,表2记录了2种算法在3个数据集上当前和平均的准确率、Kappa值。从图7~图9以及表2可以看出,2种算法的平均准确率和Kappa值十分接近,这是因为RARF算法虽然只在集成器端探测1次漂移情况,但相较于ARF在各个基础树上设置探测器更加准确全面,不会出现漏测情况。
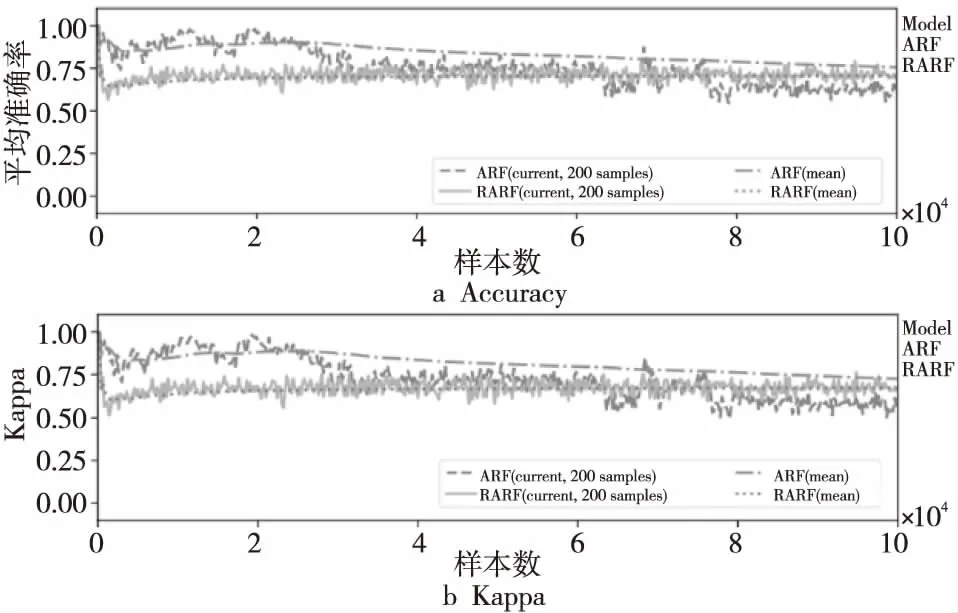
Figure 7 Accuracy and Kappa comparison on LED data set图7 “森林覆盖类型”数据集上的准确率和Kappa值对比
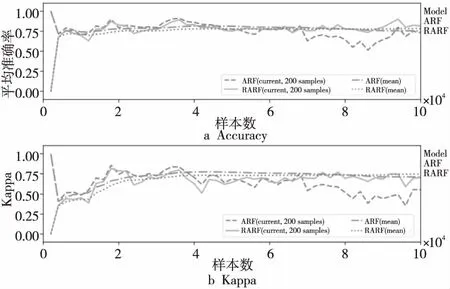
Figure 8 Accuracy and Kappa comparison on “Forest cover type” data set图8 “森林覆盖类型”数据集上的准确率和Kappa值对比
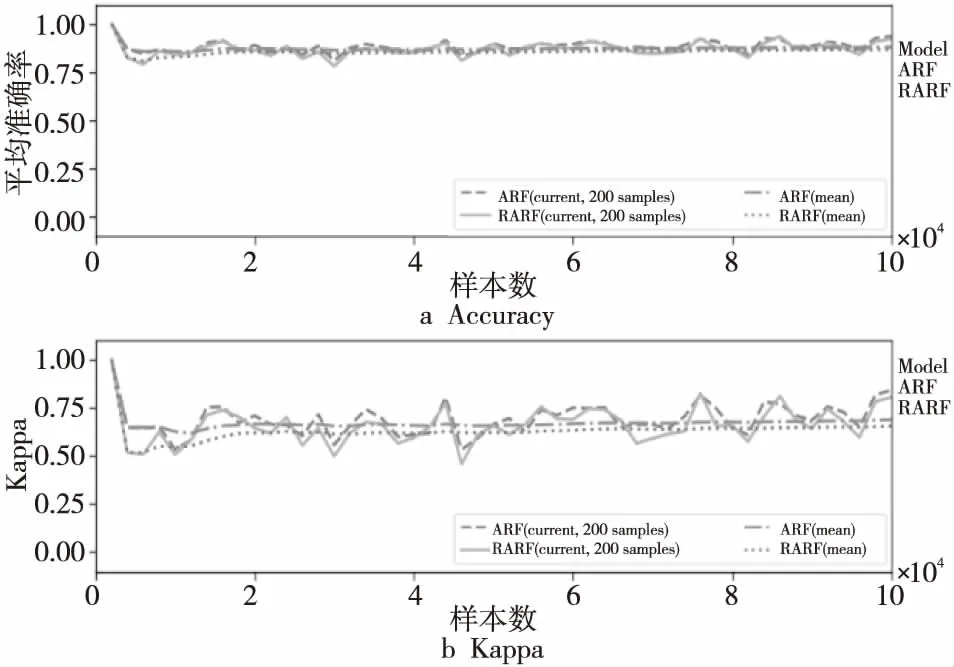
Figure 9 Accuracy and Kappa comparison on SEA data set图9 SEA数据集上准确率和Kappa值对比
Table 2 Current and average accuracy,Kappa
表2 当前和平均准确率与kappa值
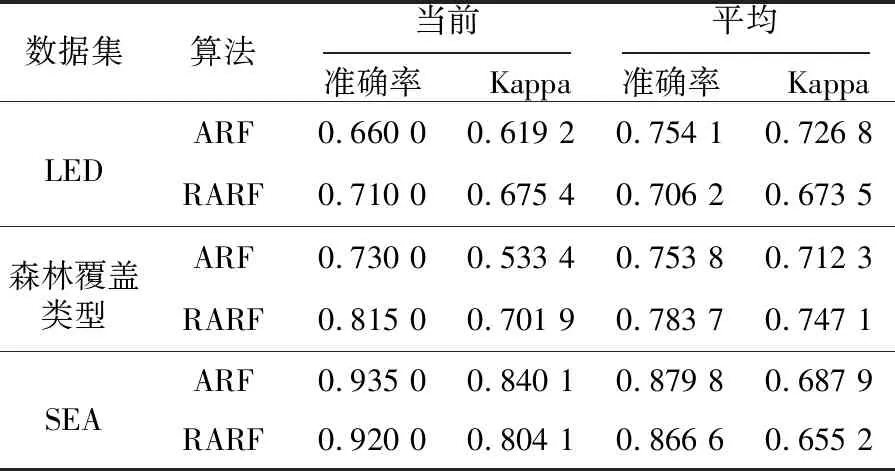
数据集算法当前准确率 Kappa平均准确率 KappaLEDARF0.660 00.619 20.754 10.726 8RARF0.710 00.675 40.706 20.673 5森林覆盖类型ARF0.730 00.533 40.753 80.712 3RARF0.815 00.701 90.783 70.747 1SEAARF0.935 00.840 10.879 80.687 9RARF0.920 00.804 10.866 60.655 2
当发生概念漂移需要替换基础树时,ARF用背景树根据基础树预测准确率的变化情况替换检测到漂移的基础树,RARF是根据递增的基础树的预测准确率用提前训练好的基础树集替换部分基础树集,所以在2种算法中表现差的基础树都可以被及时替换掉。而RARF可以同时用背景树替换一批表现差的基础树,能更快速地更新集成器的信息而不受到历史数据的影响,使得准确率变化相对更稳定,且能快速从概念漂移中恢复。
4.4.5 实验结论
通过实验对比分析可得出以下结论:RARF算法在类别分布较为平衡的数据集上能保证较高准确率,时间和内存消耗更少。
5 结束语
使用集成器对数据流分类是当前数据挖掘领域的一个热点,实时预测并有效应对概念漂移是数据流处理过程中的难点之一。本文在ARF算法基础上加以改进,提出了一种改进的随机森林自适应集成分类算法,该集成算法通过在集成器上增加漂移探测器,设置警告阈值,并在发出警告后,根据集成器准确率训练适当数目的背景树;设置漂移阈值,在发生漂移后,用训练好的背景树替换集成器中表现不好的基础树,在保证了准确率的前提下,尽可能地减少了运行所耗时间和内存。通过分析和实验仿真,验证了RARF算法相较于ARF算法,在处理概念漂移问题中整体表现更稳定,内存和时间消耗更少。而如何进一步提升自适应随机森林集成模型对不平衡以及不确定数据流[18]分类的预测效果,是下一步研究的方向。
猜你喜欢
汽车维修与保养(2020年10期)2021-01-22
数学年刊A辑(中文版)(2020年2期)2020-07-25
汽车维修与保养(2020年11期)2020-06-09
数学物理学报(2019年6期)2020-01-13
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
唐山师范学院学报(2018年6期)2018-12-25
西北工业大学学报(2015年3期)2015-12-14
电脑爱好者(2015年21期)2015-09-10
中国卫生(2014年7期)2014-11-10
