
无性系种子园最小近交配置研究
2020-04-01 08:11齐建东买晶晶刘春霞
农业机械学报 2020年3期
齐建东 买晶晶 刘春霞 李 伟
(1.北京林业大学信息学院,北京 100083;2.中国科学院软件研究所,北京 100190;3.北京林业大学生物科学与技术学院,北京 100083)
0 引言
无性系种子园是以优良无性系个体为材料、用无性繁殖的方式建立的种子园。无性系种子园中的亲本来源清楚,有利于保持树源的优良品质,便于集约经营管理,但容易产生自交现象。因此,需要通过对种子园的无性系进行合理配置,以避免自交和近交现象。
20世纪60年代,我国试建了第1批初级无性系种子园。20世纪70年代末和80年代初,造林工作得到迅速发展。目前,很多初代林木树种的改良工作已经完成,正进入高世代改良阶段。在种子园设计方面,国内学者多采用传统的无性系配置方法进行配置设计,如贾乃光[1]、程祥等[2]选用顺序错位排列设计法,梁一池[3]利用随机完全区组设计方法,许鲁平[4]采用约束变换区组设计,申文辉等[5]使用约束的随机完全区组设计,郑仁华等[6]、谢汝根[7]、苏顺德等[8]均采用完全随机排列法进行种子园设计。现实中的种子园是一个庞大而复杂的交配系统,在进行设计工作时,以上学者没有考虑亲本的亲缘关系,仅有袁虎威等[9]从分子水平上获取优良单株之间的亲缘关系,并采用不平衡、不完全固定区组方法将实验分析得到的亲缘关系结果应用于第2代种子园的无性系配置设计;王晴等[10]引用无性系亲本间的遗传距离,设计了一种改进型自适应并行遗传算法,实现了田间设计。LSTIBREK等[11]在2010年提出了最小化近交(Minimum inbreeding, MI)设计方案,在实验中设计了5种不同场景实验,考虑了更复杂的亲缘结构(如无亲缘、半同胞和亲子关系等)。LSTIBREK等[12]在2015年进一步提出将扩展全局(遗传禁忌)算法(Extended global(genetic-tabu)algorithm, EGA)用于解决经营林业的现实问题,其在MI的基础上添加了半同胞约束条件。CHALOUPKOV等[13]将提出的最优近邻算法(Optimum neighborhood algorithm, ONA)应用于平衡和非平衡无性系规模的实验中。近几年来,在种子园设计方面的研究更侧重于无性系的亲缘关系,而其他的影响因素(如花期和花粉量等)考虑较少,仅王强金[14]提及的光泽华桥国有林场配置方案中考虑了物候期,但物候期的划分不够明确。LSTIBREK等[12]在2015年提出,可以使用假设情景的方式引入开花同步、育种值、花粉产量等因素,但并没有提供相关实验。
种子园中无性系的花期和花粉量会影响种子园子代际的遗传结构。其中,开花同步数据会影响无性系之间的杂交繁殖,如果无性系之间花期不遇,可能导致大多数无性系之间的授粉期和散粉期错开,从而严重影响种子的产量和品种[15]。花粉量只有达到有效值才能授粉成功,当花粉量传播不足时,会导致授粉失败,出种率降低,败育率升高[16]。可见,花期和花粉量是设计各世代种子园内无性系配置的关键因素,只有种子园内的花期基本一致或者相邻无性系花期一致,并且花粉量足够,才能授粉成功,进行正常繁殖。目前,尚未见同时引入花期和花粉量作为种子园设计约束条件的相关报道。
齐建东等[17]通过无性系之间的遗传距离作为亲缘关系的衡量标准,利用改进型果蝇算法实现了无性系种子园的遗传设计,本文在此基础上,加入花期和花粉量作为新的约束条件,并设计双种群改进型自适应步长的果蝇优化算法(Two-population improved adaptive step-length fruit fly optimization algorithm, TIASFOA)对无性系进行配置设计。
1 种子园设计问题
1.1 问题描述
依据T株亲本之间的遗传距离、花期和花粉传播量,合理选择亲本及其分株进行无性系遗传设计,在栽种过程中重点考虑近邻位置的近交繁殖现象、同一无性系不同分株的自交情况,以及花粉有效传播范围内的无性系花期同步性和花粉接收量。无性系之间的遗传距离越大,亲缘关系越远,更有利于杂交繁殖,配置时应该选择遗传距离较大的无性系作为近邻;此外,在配置过程中,需要优先考虑花期问题,只有当无性系的花期同步时,散粉和授粉才有意义,应该将同一花期的无性系栽种距离尽量缩小[15];其次考虑花粉量,根据经验易知花粉量传播与树的高度相关,花粉传播会随着距离增加而减少,当花粉量低于有效花粉传播量时,则无法成功授粉,因此,在有效传播距离内尽量接受更多的花粉量[18]。
无性系的具体花期时间与花粉量,会受当年的气候影响(如风、温度和湿度等),也会受当地的地形和花粉自身特征等影响[19],本文研究工作暂不考虑气候、地形和不同花粉自身特性等因素。
假设种子园是一个规模为M行×N列的规则的种子园,所有的树高均为h,行间距为s,花粉是在静风条件下进行传播,在有效范围的边缘处只能接受到10%的花粉量(即有效花粉量不能低于10%),花粉量在静风条件下呈线性递减。种子园栽种示意图如图1所示,每一个方格代表一个可以栽种的位置,如1-1表示第1行第1列的位置。

图1 种子园栽种示意图
1.2 目标函数
本文设计目标函数为
(1)
其中

R=nh
式中dmin——所有植株的近邻距离和同一无性系所有分株距离之和与所有植株有效花粉量倒数和相加的最小值
Gij——第i株无性系和第j株无性系之间的遗传距离,且第i株无性系和第j株无性系为正对近邻
Gik——第i株无性系和第k株无性系之间的遗传距离,且第i株无性系和第k株无性系为斜角近邻
dit——第i株无性系和第t株无性系之间的物理距离,第i株无性系和第t株无性系为同一无性系亲本的分株
Piq——第i株无性系与第q株无性系之间传播的花粉量
q——以第i株树为中心半径为R范围内的所有无性系的数量
w1、w2——限制因子
R——花粉传播半径
Pq——第q株树向第i株树传播的花粉量
h——树高s——行距
n——半径与树高的比值,本文设为3
Q——花粉传播半径为R的圆范围内的无性系数量
u——无性系数量
diq——第i株无性系与第q株无性系之间的物理距离
同时考虑花期的影响,添加以下约束条件
(2)
式中Pj——第j株树向第i株树传播的花粉量
Pj-self——第j株树的花粉量
2 材料与方法
2.1 数据来源
从内蒙古红花尔基樟子松国家良种基地1代种子园、1.5代种子园、2代种子园采集的当年生针叶3~5针的樟子松无性系材料,由于单核苷酸多态性(Single nucleotide polymorphism,SNP)分子标记技术成本较高、分型技术不太成熟,因此本文通过简单、成熟、成本低的SSR分子标记法提取樟子松基因组DNA,从15对SSR引物中选择多态性良好、稳定、清晰的11对SSR引物作为实验引物,利用Gene Marker V2.2软件对条带信息进行比对后,基于等位基因频率的Nei 1983距离计算得到樟子松无性系材料中不同无性系之间的遗传距离[12],作为本文的实验数据。
2.2 研究方法
王晴等[10]、LSTIBREK等[12]均采用改进的遗传算法对种子园内的无性系进行配置设计,齐建东等[17]利用改进型果蝇算法实现了种子园设计,结果均表明改进智能优化算法优于传统设计方法。与较成熟的智能算法(如遗传算法(Genetic algorithm,GA)、粒子群算法(Particle swarm optimization,PSO)等)相比,果蝇优化算法(Fruit fly optimization algorithm,FOA)作为新型仿生智能算法,具有简单、易于实现等优点,获得了国内外众多学者的广泛关注和研究,在医学、生物、工程和科学等领域得到了应用,并且相对于计算量较大的启发式智能优化算法,如人工蜂群算法(Artificial bee colony algorithm,ABC)、GA算法的多种群策略,FOA算法计算简单,这使得FOA算法所消耗的资源更少。
2.2.1标准果蝇算法
FOA算法利用果蝇(Drosophilamelanogaster)个体嗅觉优势获取食物的味道,并将自身获取的味道与其他果蝇个体共享;果蝇个体通过视觉比较得出种群中获得最优食物味道的果蝇个体,然后向具有最优食物味道的果蝇位置聚集,并按照该搜索方式继续搜索食物,直到找到食物为止[20]。FOA算法具有众多优点,但无法直接应用于离散问题,且算法稳定性较差[21]。针对种子园遗传设计问题,齐建东等[17]设计的IFOA算法可用于解决离散问题,但稳定性并没有得到提高。本文对FOA算法和IFOA算法的不足进行改进,设计了双种群改进型自适应步长果蝇优化算法(Two-population improved adaptive step-length fruit fly optimization algorithm, TIASFOA)。
2.2.2TIASFOA算法
在IFOA算法[17]的基础上,本文进行了以下改进。
(1)自适应步长
FOA算法的寻优过程中,步长是一个常量函数,从而导致迭代前期收敛速度慢,迭代后期其寻优精度低;IFOA算法步长变异因子的调节需要人为控制;参考文献[22-24],根据种子园特点,设计了一个自适应逐步递减的步长函数,计算公式为
(3)
其中
式中L——步长L0——初始步长
g——当前迭代次序
maxgen——最大迭代次数
Xorchard——种子园X轴方向可栽种位置数量
Yorchard——种子园Y轴方向可栽种位置数量
(2)多种群策略
在FOA算法和IFOA算法中均采用单种群寻优,种群多样性降低,算法易陷入局部最优。TIASFOA算法将整个种群划分为两个规模相同的子种群,分别对两个子种群进行独立寻优操作,利用种群之间的信息交流机制,增加精英个体,保留最优解和次优解,子种群的其他果蝇分别以最优解和次优解为标准值,形成两个新的子种群,按照该方法迭代寻优,直到满足最大迭代次数,合并两个子种群,输出最优解以及最优解位置上的其他信息。
(3)寻优过程
为了在保留算法较优的收敛速度的同时,加强算法的随机效果,提高果蝇个体跳出局部最优点的能力,在每次觅食时同时采用最优和随机两种觅食行为。增添一个觅食概率,通过多次实验将其设置为0.8,使得果蝇个体在每次觅食(即寻优)时按照一定的概率采用最优觅食或随机觅食。即在每次觅食过程中随机生成一个随机概率,当随机概率小于觅食概率时,寻找果蝇个体的最差浓度基因位,进行最优觅食;当随机概率大于觅食概率时,采用随机机制。
2.2.3TIASFOA算法流程
TIASFOA算法流程如下:
(1)轮盘赌法初始化种群。设置实验相关参数:种子园规模M行×N列、种群规模sizepop、最大迭代次数maxgen、觅食概率P。
(2)确定初始浓度和位置。初始化时保留最优解和次优解果蝇的浓度和位置,记为全局最优解和次优解个体浓度和位置。
(3)将种群划分成2个相同规模的子种群。
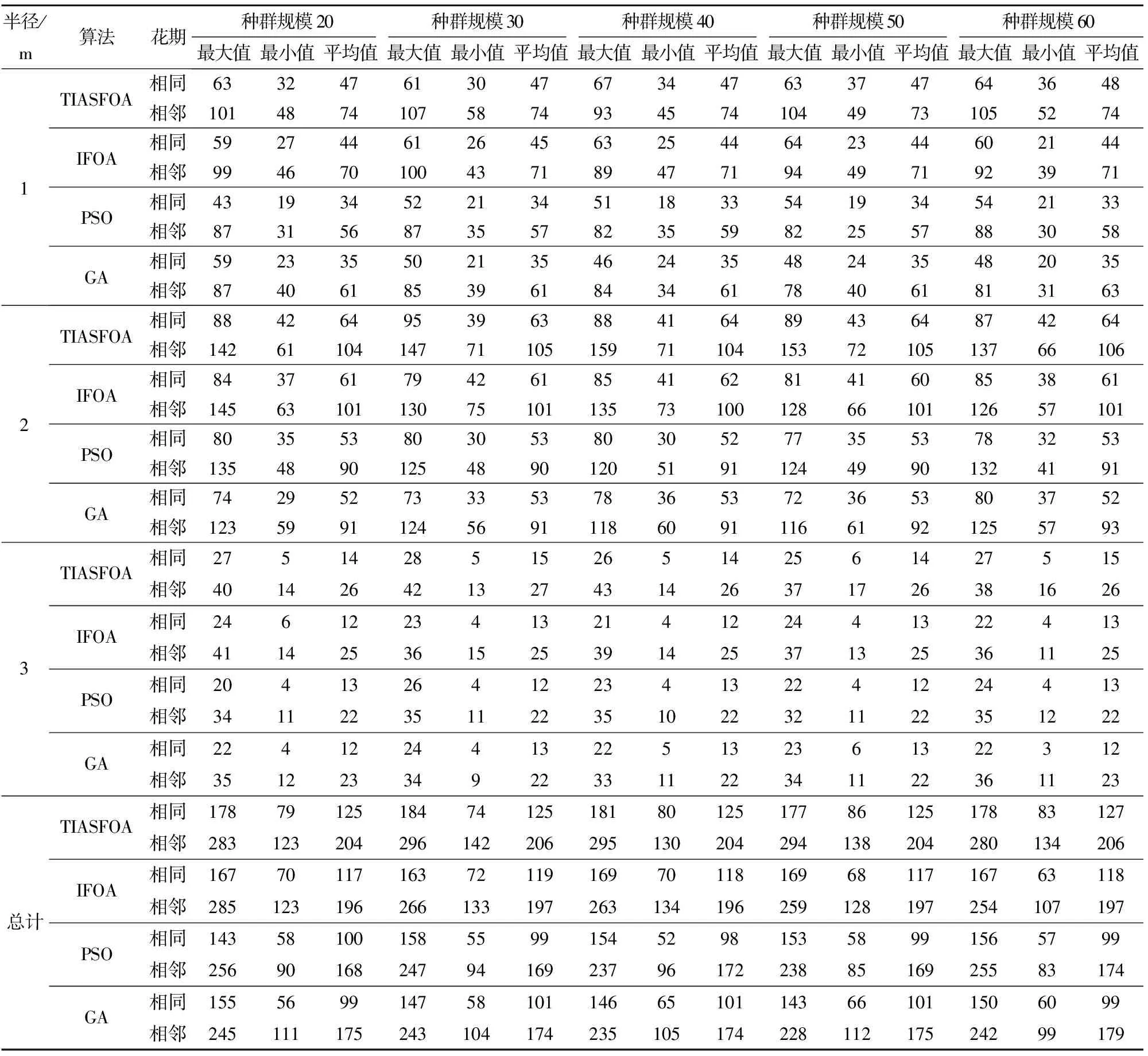
(4)动态调整步长,分别对2个子种群进行独立寻优操作。每次觅食开始前,先随机生成概率Pi,然后判断Pi和P的大小,当Pi (5)对比2个子种群的解,保存所有解中的最优解和次优解个体以及他们对应的位置。 (6)对当前迭代中的最优解、次优解、全局最优解、全局次优解进行比较,判断是否需要更新全局最优解和次优解个体浓度以及他们对应的位置。 (7)进入迭代寻优,如果迭代次数g小于最大迭代次数,则循环执行步骤(3)~(6);否则合并2个子种群输出最优种子园方案、该方案的最佳浓度以及其他相关信息。 TIASFOA算法的基本流程图见图2。 图2 双种群改进型自适应步长的果蝇优化算法流程图 种子园规模设定为9行×9列;TIASFOA算法最大迭代次数为1 000,行间距为1 m×1 m,树高为1 m(本文实验数据,可以自定义);将花期设定在5月15—20日,不同单株之间的相互接受花粉量的范围为50~500单位量之间,在此范围内,随机生成每株亲本的花期和花粉量;花粉最大的传播半径为3倍树高(即3 m),在此基础上与IFOA、GA、PSO算法进行对比,其中IFOA算法的参数设置:迭代前期变异因子为0.4,迭代后期变异因子为0.02;GA算法的参数设置:交配概率为0.8,变异概率为0.2;PSO算法的参数设置:学习因子为2,速度初始化为1。 3.2.1不同种群规模下的适应度对比 对TIASFOA、IFOA、PSO、GA算法在种群20~60范围内以式(1)为目标函数计算近似最优适应度dmin,并分别执行200次循环后对平均值、最大值、最小值和方差进行比较分析。 观察表1,在不同种群规模下,PSO、GA算法的最小值、最大值、平均值、方差均大于TIASFOA、IFOA算法的对应值,且PSO、GA算法的最小值始终大于TIASFOA的最大值,说明PSO、GA算法表现较差;随着种群规模的增加,IFOA算法的最大值减小,在种群规模为50的情况下IFOA算法取得最小值137.097,大于TIASFOA算法的最小值132.733,说明IFOA算法陷入了局部最优;在不同种群规模下,IFOA算法最小值、最大值、平均值、方差均大于TIASFOA算法,说明TIASFOA算法优于IFOA算法。在种群规模为60的情况下,TIASFOA算法取得了方差最小值1.288,小于其他算法。在种群规模为50的情况下,TIASFOA算法取得最小值132.733。TIASFOA算法从适应度和稳定性方面均优于其他3种算法。随着种群规模的增大,各算法的方差会有所减小,但时间代价更大,TIASFOA算法可以在种群规模20下得到较优值,时间消耗少。 表1 4种算法在不同种群规模下的适应度对比 3.2.2算法收敛比较 为在较短的时间内获取较优的适应度,本文从种群规模为20的200次实验中随机选用6次结果进行收敛速度和效果对比(图3)。从图3中可以看到,TIASFOA算法的收敛效果均优于其他算法。IFOA算法在迭代250次左右适应度达到最小值,而TISFOA算法在迭代700次左右达到最小值,说明IFOA算法收敛速度最快,但最优适应度仍大于TIASFOA算法,说明IFOA算法陷入局部最优,TIASFOA算法可以跳出局部最优,得到更优解。 3.2.3不同种群规模下的花期对比 表2给出了在种群规模20~60下,TIASFOA、IFOA、PSO、GA算法分别执行200次,得出的无性系种子园方案在距离中心位置的半径为1、2、3 m的传播范围内,种子园花期相同或相邻无性系数量的平均值、最大值和最小值。 图3 各算法收敛情况对比 表2 不同种群规模下4种算法分别执行200次的无性系数量对比 观察表2,在不同种群规模下距离中心位置半径为1、2、3 m的传播范围内,种子园内花期相同或相邻的无性系数量,PSO算法和GA算法始终劣于TIASFOA算法和IFOA算法;TIASFOA算法计算出来的无性系数量的平均值均优于IFOA算法,IFOA算法计算出来的无性系数量的最大值和最小值等于或略大于TIASFOA算法,例如表2总计中,TIASFOA算法和IFOA算法在种群规模为20时,种子园内花期相邻的情况下,无性系数量的最小值都为123;在种群规模为40时,种子园内花期相邻情况下,无性系数量的最小值IFOA算法结果为134,大于TIASFOA算法的结果130,这是受算法的随机性影响产生的偶然值。整体来看,TIASFOA算法在花期相同或相邻时平均值和最大值都更优,可以更好地使整个种子园维持较好的花期一致性。 (1)目标函数不仅考虑了无性系间的遗传距离,而且引入花期和花粉量作为约束条件,并考虑了花粉量在传播过程中不断减小的可能性,不局限于实验变量,灵活性较好。 (2)设计的TIASFOA算法扩大了搜索空间,引入了多种群的信息交流机制,可以进一步跳出局部最优,得到较优的适应度和较好的花期一致性。 (3)在实际应用中,可以根据现实种子园的树高规定花粉传播距离、设置真实行间距等,并使用种群规模为20的TIASFOA算法对无性系种子园进行设计。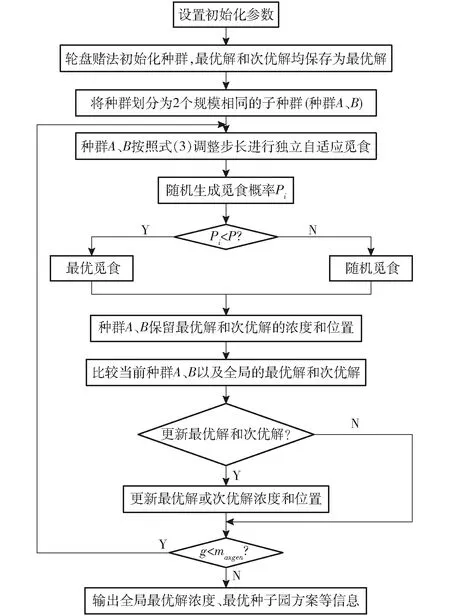
3 实验与结果分析
3.1 实验设置
3.2 结果分析


4 结论
猜你喜欢
学苑创造·A版(2022年3期)2022-03-29
成都信息工程大学学报(2021年5期)2021-12-30
烟台果树(2021年2期)2021-07-21
种子(2021年6期)2021-07-16
西安邮电大学学报(2021年1期)2021-04-19
山西水土保持科技(2020年2期)2020-12-22
无线互联科技(2020年12期)2020-09-03
学苑创造·A版(2019年6期)2019-07-11
无线电通信技术(2019年4期)2019-06-25
福建基础教育研究(2019年2期)2019-05-28
